如何優(yōu)雅地回答面試官關(guān)于MySQL索引的拷問(wèn)
-
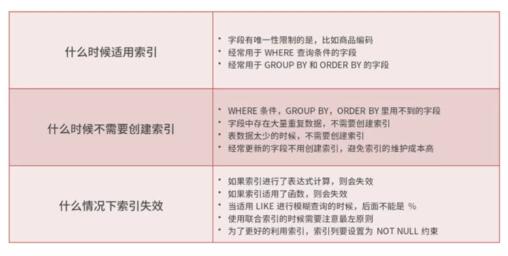
案例背景
-
案例分析
-
案例解答
-
MySQL InnoDB 的索引原理
-
索引類型
-
通過(guò)主鍵查詢(主鍵索引)商品數(shù)據(jù)的過(guò)程
-
通過(guò)非主鍵(輔助索引)查詢商品數(shù)據(jù)的過(guò)程
-
-
B+Tree 索引的優(yōu)勢(shì)
-
B+Tree 相對(duì)于 B 樹(shù) 索引結(jié)構(gòu)的優(yōu)勢(shì)
-
B+Tree 相對(duì)于二叉樹(shù)索引結(jié)構(gòu)的優(yōu)勢(shì)
-
B+Tree 相對(duì)于 Hash 表存儲(chǔ)結(jié)構(gòu)的優(yōu)勢(shì)
-
執(zhí)行計(jì)劃
-
索引失效的常見(jiàn)情況
-
常見(jiàn)優(yōu)化索引的方法
-
前綴索引優(yōu)化
-
覆蓋索引優(yōu)化
-
聯(lián)合索引
-
-
總結(jié)
案例背景
假設(shè)面試官問(wèn)你:在電商平臺(tái)的訂單中心系統(tǒng)中,通常要根據(jù)商品類型、訂單狀態(tài)篩選出需要的訂單,并按照訂單創(chuàng)建的時(shí)間進(jìn)行排序,那針對(duì)下面這條 SQL,你怎么通過(guò)索引來(lái)提高查詢效率呢?
select * from order where status = 1 order by create_time asc
有的同學(xué)會(huì)認(rèn)為,單獨(dú)給 status 建立一個(gè)索引就可以了。
但是更優(yōu)的方式是建立一個(gè) status 和 create_time 組合索引,這是為了避免 MySQL 數(shù)據(jù)庫(kù)發(fā)生文件排序。
因?yàn)樵诓樵儠r(shí),你只能用到 status 的索引,但如果要對(duì) create_time 排序,就要用文件排序 filesort,也就是在 SQL 執(zhí)行計(jì)劃中,Extra 列會(huì)出現(xiàn) Using filesort 。
所以你要利用索引的有序性,在 status 和 create_time 列建立聯(lián)合索引,這樣根據(jù) status 篩選后的數(shù)據(jù)就是按照 create_time 排好序的,避免在文件排序。
案例分析
通過(guò)這個(gè)案例,你可以發(fā)現(xiàn)“索引知識(shí)”的重要性,
數(shù)據(jù)庫(kù)索引底層使用的是什么數(shù)據(jù)結(jié)構(gòu)和算法呢?
-
為什么 MySQL InnoDB 選擇 B+Tree 當(dāng)默認(rèn)的索引數(shù)據(jù)結(jié)構(gòu)?
-
如何通過(guò)執(zhí)行計(jì)劃查看索引使用詳情?
-
有哪些情況會(huì)導(dǎo)致索引失效?
-
平時(shí)有哪些常見(jiàn)的優(yōu)化索引的方法?
……
總結(jié)起來(lái)就是如下幾點(diǎn):
-
理解 MySQL InnoDB 的索引原理;
-
掌握 B+Tree 相比于其他索引數(shù)據(jù)結(jié)構(gòu)(如 B-Tree、二叉樹(shù),以及 Hash 表)的優(yōu)勢(shì);
-
掌握 MySQL 執(zhí)行計(jì)劃的方法;
-
掌握導(dǎo)致索引失效的常見(jiàn)情況;
-
掌握實(shí)際工作中常用的建立高效索引的技巧(如前綴索引、建立覆蓋索引等)。
如果你曾經(jīng)被問(wèn)到其中某一個(gè)問(wèn)題,那你就有必要認(rèn)真夯實(shí) MySQL 索引及優(yōu)化的內(nèi)容了。
案例解答
MySQL InnoDB 的索引原理
從數(shù)據(jù)結(jié)構(gòu)的角度來(lái)看, MySQL 常見(jiàn)索引有 B+Tree 索引、HASH 索引、Full-Text 索引 。MySQL 常見(jiàn)的存儲(chǔ)引擎 InnoDB、MyISAM 和 Memory 分別支持的索引類型。(后兩個(gè)存儲(chǔ)引擎在實(shí)際工作和面試中很少提及,因此只講 InnoDB) 。
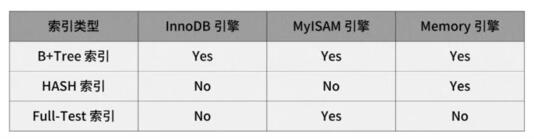
索引類型
在實(shí)際應(yīng)用中,InnoDB 是 MySQL 建表時(shí)默認(rèn)的存儲(chǔ)引擎,B+Tree 索引類型也是 MySQL 存儲(chǔ)引擎采用最多的索引類型。
在創(chuàng)建表時(shí),InnoDB 存儲(chǔ)引擎默認(rèn)使用表的主鍵作為主鍵索引,該主鍵索引就是聚簇索引(Clustered Index),如果表沒(méi)有定義主鍵,InnoDB 就自己產(chǎn)生一個(gè)隱藏的 6 個(gè)字節(jié)的主鍵 ID 值作為主鍵索引, 而創(chuàng)建的主鍵索引默認(rèn)使用的是 B+Tree 索引 。
接下來(lái)我們通過(guò)一個(gè)簡(jiǎn)單的例子,說(shuō)明一下 B+Tree 索引在存儲(chǔ)數(shù)據(jù)中的具體實(shí)現(xiàn),為的是讓你理解通過(guò) B+Tree 做索引的原理。
首先,我們創(chuàng)建一張商品表:
- CREATE TABLE `product` (
- `id` int(11) NOT NULL,
- `product_no` varchar(20) DEFAULT NULL,
- `name` varchar(255) DEFAULT NULL,
- `price` decimal(10, 2) DEFAULT NULL,
- PRIMARY KEY (`id`) USING BTREE
- ) CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
然后新增幾行數(shù)據(jù):
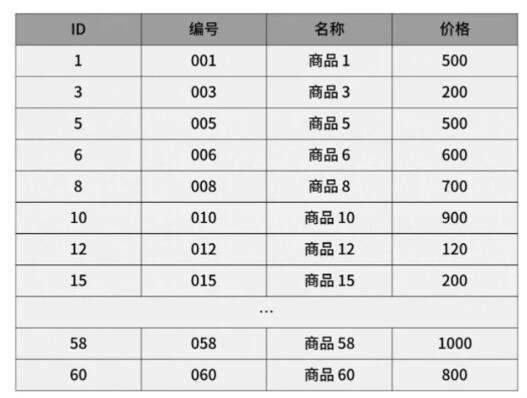
通過(guò)主鍵查詢(主鍵索引)商品數(shù)據(jù)的過(guò)程
此時(shí)當(dāng)我們使用主鍵索引查詢商品 15 的時(shí)候,那么按照 B+Tree 索引原理,是如何找到對(duì)應(yīng)數(shù)據(jù)的呢?
- select * from product where id = 15
我們可以通過(guò)數(shù)據(jù)手動(dòng)構(gòu)建一個(gè) B+Tree,它的每個(gè)節(jié)點(diǎn)包含 3 個(gè)子節(jié)點(diǎn)(B+Tree 每個(gè)節(jié)點(diǎn)允許有 M 個(gè)子節(jié)點(diǎn),且 M>2),根節(jié)點(diǎn)中的數(shù)據(jù)值 1、18、36 分別是子節(jié)點(diǎn)(1,6,12),(18,24,30)和(36,41,52)中的最小值。
每一層父節(jié)點(diǎn)的數(shù)據(jù)值都會(huì)出現(xiàn)在下層子節(jié)點(diǎn)的數(shù)據(jù)值中,因此在葉子節(jié)點(diǎn)中,包括了所有的數(shù)據(jù)值信息,并且每一個(gè)葉子節(jié)點(diǎn)都指向下一個(gè)葉子節(jié)點(diǎn),形成一個(gè)鏈表。如圖所示:
我們舉例講解一下 B+Tree 的查詢流程,比如想要查找數(shù)據(jù)值 15,B+Tree 會(huì)自頂向下逐層進(jìn)行查找:
-
將 15 與根節(jié)點(diǎn)的數(shù)據(jù) (1,18,36) 比較,15 在 1 和 18 之間,所以根據(jù) B+Tree的搜索邏輯,找到第二層的數(shù)據(jù)塊 (1,6,12);
-
在第二層的數(shù)據(jù)塊 (1,6,12) 中進(jìn)行查找,因?yàn)?15 大于 12,所以找到第三層的數(shù)據(jù)塊 (12,15,17);
-
在葉子節(jié)點(diǎn)的數(shù)據(jù)塊 (12,15,17) 中進(jìn)行查找,然后我們找到了數(shù)據(jù)值 15;
最終根據(jù)數(shù)據(jù)值 15 找到葉子節(jié)點(diǎn)中存儲(chǔ)的數(shù)據(jù)。
整個(gè)過(guò)程一共進(jìn)行了 3 次 I/O 操作,所以 B+Tree 相比于 B 樹(shù)和二叉樹(shù)來(lái)說(shuō),最大的優(yōu)勢(shì)在于查詢效率。
那么問(wèn)題來(lái)了,如果你當(dāng)前查詢數(shù)據(jù)時(shí)候,不是通過(guò)主鍵 ID,而是用商品編碼查詢商品,那么查詢過(guò)程又是怎樣的呢?
通過(guò)非主鍵(輔助索引)查詢商品數(shù)據(jù)的過(guò)程
如果你用商品編碼查詢商品(即使用輔助索引進(jìn)行查詢),會(huì)先檢索輔助索引中的 B+Tree 的 商品編碼,找到對(duì)應(yīng)的葉子節(jié)點(diǎn),獲取主鍵值,然后再通過(guò)主鍵索引中的 B+Tree 樹(shù)查詢到對(duì)應(yīng)的葉子節(jié)點(diǎn),然后獲取整行數(shù)據(jù)。 這個(gè)過(guò)程叫回表 。
以上就是索引的實(shí)現(xiàn)原理。
在面試時(shí),面試官一般不會(huì)讓你直接描述查詢索引的過(guò)程,但是會(huì)通過(guò)考察你對(duì)索引優(yōu)化方法的理解,來(lái)評(píng)估你對(duì)索引原理的掌握程度,比如為什么 MySQL InnoDB 選擇 B+Tree 作為默認(rèn)的索引數(shù)據(jù)結(jié)構(gòu)?MySQL 常見(jiàn)的優(yōu)化索引的方法有哪些?
所以接下來(lái),我們就詳細(xì)了解一下在面試中如何回答索引優(yōu)化的問(wèn)題。
B+Tree 索引的優(yōu)勢(shì)
如果你被問(wèn)到“為什么 MySQL 會(huì)選擇 B+Tree 當(dāng)索引數(shù)據(jù)結(jié)構(gòu)?”其實(shí)在考察你兩個(gè)方面:B+Tree 的索引原理;B+Tree 索引相比于其他索引類型的優(yōu)勢(shì)。
我們剛剛已經(jīng)講了 B+Tree 的索引原理,現(xiàn)在就來(lái)回答一下 B+Tree 相比于其他常見(jiàn)索引結(jié)構(gòu),如 B 樹(shù)、二叉樹(shù)或 Hash 索引結(jié)構(gòu)的優(yōu)勢(shì)在哪兒?
B+Tree 相對(duì)于 B 樹(shù) 索引結(jié)構(gòu)的優(yōu)勢(shì)
B+Tree 只在葉子節(jié)點(diǎn)存儲(chǔ)數(shù)據(jù),而 B 樹(shù) 的非葉子節(jié)點(diǎn)也要存儲(chǔ)數(shù)據(jù),所以 B+Tree 的單個(gè)節(jié)點(diǎn)的數(shù)據(jù)量更小,在相同的磁盤 I/O 次數(shù)下,就能查詢更多的節(jié)點(diǎn)。
另外,B+Tree 葉子節(jié)點(diǎn)采用的是雙鏈表連接,適合 MySQL 中常見(jiàn)的基于范圍的順序查找,而 B 樹(shù)無(wú)法做到這一點(diǎn)。
B+Tree 相對(duì)于二叉樹(shù)索引結(jié)構(gòu)的優(yōu)勢(shì)
對(duì)于有 N 個(gè)葉子節(jié)點(diǎn)的 B+Tree,其搜索復(fù)雜度為O(logdN),其中 d 表示節(jié)點(diǎn)允許的最大子節(jié)點(diǎn)個(gè)數(shù)為 d 個(gè)。
在實(shí)際的應(yīng)用當(dāng)中, d 值是大于100的,這樣就保證了,即使數(shù)據(jù)達(dá)到千萬(wàn)級(jí)別時(shí),B+Tree 的高度依然維持在 3~4 層左右,也就是說(shuō)一次數(shù)據(jù)查詢操作只需要做 3~4 次的磁盤 I/O 操作就能查詢到目標(biāo)數(shù)據(jù)(這里的查詢參考上面 B+Tree 的聚簇索引的查詢過(guò)程)。
而二叉樹(shù)的每個(gè)父節(jié)點(diǎn)的兒子節(jié)點(diǎn)個(gè)數(shù)只能是 2 個(gè),意味著其搜索復(fù)雜度為 O(logN),這已經(jīng)比 B+Tree 高出不少,因此二叉樹(shù)檢索到目標(biāo)數(shù)據(jù)所經(jīng)歷的磁盤 I/O 次數(shù)要更多。
B+Tree 相對(duì)于 Hash 表存儲(chǔ)結(jié)構(gòu)的優(yōu)勢(shì)
我們知道范圍查詢是 MySQL 中常見(jiàn)的場(chǎng)景,但是 Hash 表不適合做范圍查詢,它更適合做等值的查詢,這也是 B+Tree 索引要比 Hash 表索引有著更廣泛的適用場(chǎng)景的原因。
至此,你就知道“為什么 MySQL 會(huì)選擇 B+Tree 來(lái)做索引”了。在回答時(shí),你要著眼于 B+Tree 的優(yōu)勢(shì),然后再引入索引原理的查詢過(guò)程(掌握這些知識(shí)點(diǎn),這個(gè)問(wèn)題其實(shí)比較容易回答)。
接下來(lái),我們進(jìn)入下一個(gè)問(wèn)題:在實(shí)際工作中如何查看索引的執(zhí)行計(jì)劃。
通過(guò)執(zhí)行計(jì)劃查看索引使用詳情 我這里有一張存儲(chǔ)商品信息的演示表 product:
- CREATE TABLE `product` (
- `id` int(11) NOT NULL,
- `product_no` varchar(20) DEFAULT NULL,
- `name` varchar(255) DEFAULT NULL,
- `price` decimal(10, 2) DEFAULT NULL,
- PRIMARY KEY (`id`) USING BTREE,
- KEY 'index_name' ('name').
- KEY 'index_id_name' ('id', 'name')
- ) CHARACTER SET = utf8 COLLATE = utf8_general_ci
表中包含了主鍵索引、name 字段上的普通索引,以及 id 和 name 兩個(gè)字段的聯(lián)合索引。現(xiàn)在我們來(lái)看一條簡(jiǎn)單查詢語(yǔ)句的執(zhí)行計(jì)劃:

執(zhí)行計(jì)劃
對(duì)于執(zhí)行計(jì)劃,參數(shù)有 possible_keys 字段表示可能用到的索引,key 字段表示實(shí)際用的索引,key_len 表示索引的長(zhǎng)度,rows 表示掃描的數(shù)據(jù)行數(shù)。
這其中需要你重點(diǎn)關(guān)注 type 字段, 表示數(shù)據(jù)掃描類型,也就是描述了找到所需數(shù)據(jù)時(shí)使用的掃描方式是什么,常見(jiàn)掃描類型的執(zhí)行效率從低到高的順序?yàn)椋紤]到查詢效率問(wèn)題,全表掃描和全索引掃描要盡量避免):
ALL(全表掃描);
index(全索引掃描);
range(索引范圍掃描);
ref(非唯一索引掃描);
eq_ref(唯一索引掃描);
const(結(jié)果只有一條的主鍵或唯一索引掃描)。
總的來(lái)說(shuō),執(zhí)行計(jì)劃是研發(fā)工程師分析索引詳情必會(huì)的技能(很多大廠公司招聘 JD 上寫(xiě)著“SQL 語(yǔ)句調(diào)優(yōu)” ),所以你在面試時(shí)也要知道執(zhí)行計(jì)劃核心參數(shù)的含義,如 type。在回答時(shí),也要以重點(diǎn)參數(shù)為切入點(diǎn),再擴(kuò)展到其他參數(shù),然后再說(shuō)自己是怎么做 SQL 優(yōu)化工作的。
索引失效的常見(jiàn)情況
在工作中,我們經(jīng)常會(huì)碰到 SQL 語(yǔ)句不適用已有索引的情況,來(lái)看一個(gè)索引失效的例子:
這條帶有 like 查詢的 SQL 語(yǔ)句,沒(méi)有用到 product 表中的 index_name 索引。
我們結(jié)合普通索引的 B+Tree 結(jié)構(gòu)看一下索引失效的原因:當(dāng) MySQL 優(yōu)化器根據(jù) name like ‘%路由器’ 這個(gè)條件,到索引 index_name 的 B+Tree 結(jié)構(gòu)上進(jìn)行查詢?cè)u(píng)估時(shí),發(fā)現(xiàn)當(dāng)前節(jié)點(diǎn)的左右子節(jié)點(diǎn)上的值都有可能符合 '%路由器' 這個(gè)條件,于是優(yōu)化器判定當(dāng)前索引需要掃描整個(gè)索引,并且還要回表查詢,不如直接全表掃描。
當(dāng)然,還有其他類似的索引失效的情況:
索引列上做了計(jì)算、函數(shù)、類型轉(zhuǎn)換操作,這些情況下索引失效是因?yàn)椴樵冞^(guò)程需要掃描整個(gè)索引并回表,代價(jià)高于直接全表掃描;
like 匹配使用了前綴匹配符 '%abc';
字符串不加引號(hào)導(dǎo)致類型轉(zhuǎn)換;
我給你的建議是, 如果 MySQL 查詢優(yōu)化器預(yù)估走索引的代價(jià)比全表掃描的代價(jià)還要大,則不走對(duì)應(yīng)的索引,直接全表掃描,如果走索引比全表掃描代價(jià)小,則使用索引。
常見(jiàn)優(yōu)化索引的方法
前綴索引優(yōu)化
前綴索引就是用某個(gè)字段中,字符串的前幾個(gè)字符建立索引,比如我們可以在訂單表上對(duì)商品名稱字段的前 5 個(gè)字符建立索引。使用前綴索引是為了減小索引字段大小,可以增加一個(gè)索引頁(yè)中存儲(chǔ)的索引值,有效提高索引的查詢速度。在一些大字符串的字段作為索引時(shí),使用前綴索引可以幫助我們減小索引項(xiàng)的大小。
但是,前綴索引有一定的局限性,例如 order by 就無(wú)法使用前綴索引,無(wú)法把前綴索引用作覆蓋索引。
覆蓋索引優(yōu)化
覆蓋索引是指 SQL 中 query 的所有字段,在索引 B+tree 的葉子節(jié)點(diǎn)上都能找得到的那些索引,從輔助索引中查詢得到記錄,而不需要通過(guò)聚簇索引查詢獲得。
假設(shè)我們只需要查詢商品的名稱、價(jià)格,有什么方式可以避免回表呢?
我們可以建立一個(gè)組合索引,即商品ID、名稱、價(jià)格作為一個(gè)組合索引。如果索引中存在這些數(shù)據(jù),查詢將不會(huì)再次檢索主鍵索引,從而避免回表。所以,使用覆蓋索引的好處很明顯,即不需要查詢出包含整行記錄的所有信息,也就減少了大量的 I/O 操作。
聯(lián)合索引
聯(lián)合索引時(shí),存在最左匹配原則,也就是按照最左優(yōu)先的方式進(jìn)行索引的匹配。
比如聯(lián)合索引 (userpin, username),如果查詢條件是 WHERE userpin=1 AND username=2,就可以匹配上聯(lián)合索引;或者查詢條件是 WHERE userpin=1,也能匹配上聯(lián)合索引,但是如果查詢條件是 WHERE username=2,就無(wú)法匹配上聯(lián)合索引。
另外,建立聯(lián)合索引時(shí)的字段順序,對(duì)索引效率也有很大影響。越靠前的字段被用于索引過(guò)濾的概率越高,實(shí)際開(kāi)發(fā)工作中建立聯(lián)合索引時(shí),要把區(qū)分度大的字段排在前面,這樣區(qū)分度大的字段越有可能被更多的 SQL 使用到。
區(qū)分度就是某個(gè)字段 column 不同值的個(gè)數(shù)除以表的總行數(shù),比如性別的區(qū)分度就很小,不適合建立索引或不適合排在聯(lián)合索引列的靠前的位置,而 uuid 這類字段就比較適合做索引或排在聯(lián)合索引列的靠前的位置。
總結(jié)
主要講了 MySQL 的索引原理,介紹了 InnoDB 為什么會(huì)采用 B+Tree 結(jié)構(gòu)。因?yàn)?B+Tree 能夠減少單次查詢的磁盤訪問(wèn)次數(shù),做到查詢效率最大化。另外,我們還講了如何查看 SQL 的執(zhí)行計(jì)劃,從而找到索引失效的問(wèn)題,并有針對(duì)性的做索引優(yōu)化。