無需向量監督的矢量圖生成算法,入選CVPR 2021

本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
說起圖像生成算法,大家也許并不陌生。
不過,大多數算法都針對柵格圖像,也就是位圖,而不支持矢量圖。
雖然也有一些生成矢量圖形的算法,但是在監督訓練中,又受限于矢量圖數據集有限的質量和規模。
為此,來自倫敦大學學院和Adobe Research的研究人員提出了一個新方法——Im2Vec,只需利用柵格訓練圖像進行間接監督,就可以生成復雜的矢量圖形。

△Im2Vec的插值效果
原理架構
為建立無需向量監督的矢量圖形生成模型,研究人員使用了可微的柵格化管線,該管線可以渲染生成的矢量形狀,并將其合成到柵格畫布上。

△架構概覽1
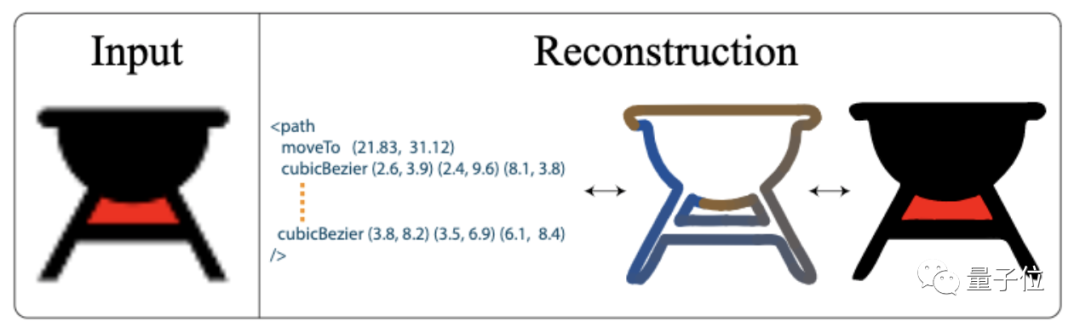
具體而言,首先要訓練一個端到端的變分自動編碼器,作為矢量圖形解碼器,用它將光柵圖像編碼為隱代碼 z ,然后將其解碼為一組有序的封閉向量路徑。
對于具有多個組件的圖形,模型則利用RNN為每條路徑生成一個隱代碼。

然后利用DiffVG對這些路徑進行柵格化處理,并使用DiffComp將它們組合在一起,獲得柵格化的矢量圖形輸出。
最后將柵格化的矢量圖形與原本的矢量圖形進行比較,計算二者之間的損失——多分辨率光柵損失,并利用誤差反向傳播和梯度下降方法來訓練模型。
其中,編碼的過程是這樣的:
△架構概覽2
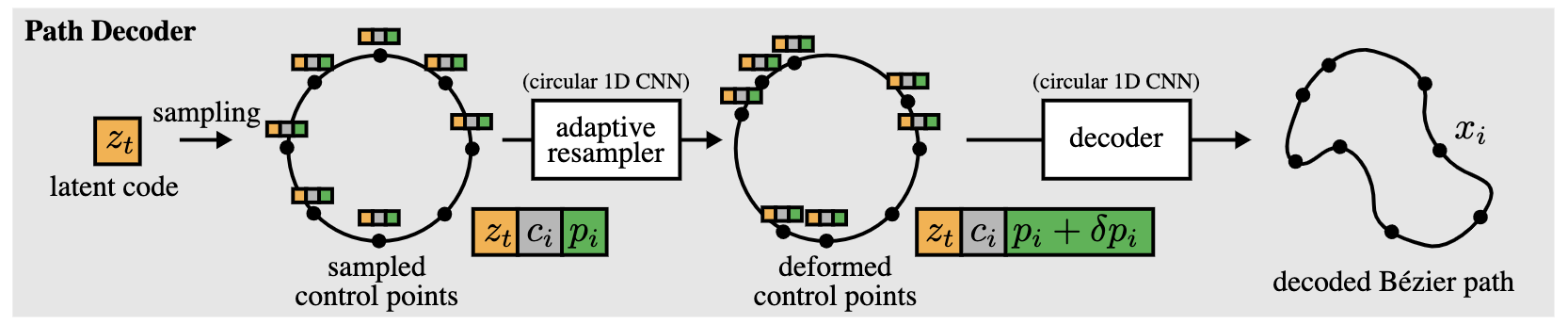
使用路徑解碼器,將路徑代碼解碼為封閉的貝塞爾路徑,在單位圓上均勻地抽取路徑控制點,以確保路徑的封閉性。
接著,用具有圓形邊界條件的一維卷積神經網絡(CNN),對這些控制位置進行變形,以實現對點密度的自適應控制。
相比于控制點的均勻分布與段數相同,自適應方案調整采樣密度,提高了重建精度。
同時利用訓練的輔助模型,以復雜度-保真度進行權衡,確定路徑的最佳分段數和路徑控制點的數量。
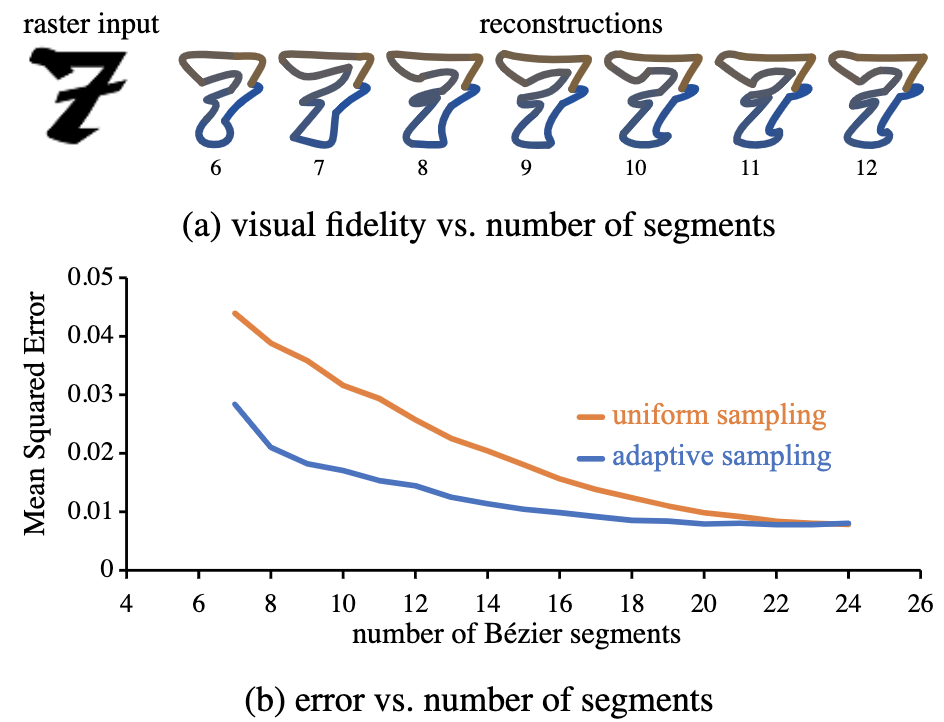
△統一采樣與自適應采樣:(a)保真度vs片段數 (b)誤差與片段數
最后,使用另一個一維圓形CNN對調整點進行調整,在繪圖畫布的絕對坐標系中輸出最終的路徑控制點。
與現有技術對比
為評估Im2Vec在重構、生成和插值3個任務中的定量性能,研究人員將其與基于柵格的ImageVAE和基于矢量的SVG-VAE、DeepSVG進行對比。
重構性能評估
首先,計算各種方法和數據集的重建損失:
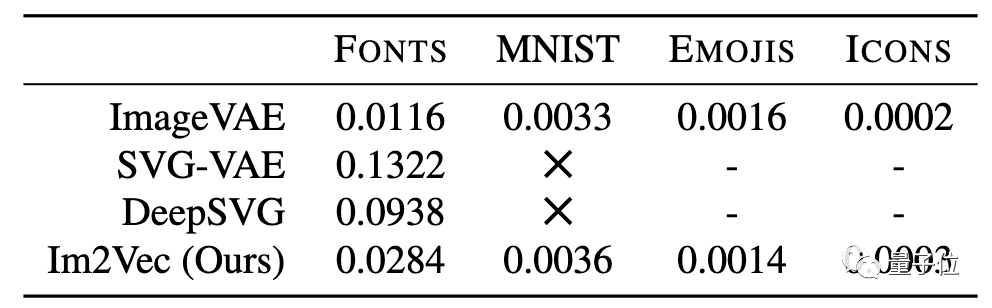
值得注意的是,在沒有向量監督的情況下,SVG-VAE和DeepSVG均無法在數據集上運行。
同時,研究人員在不同數據集中,對各個方法的圖形重構性能,進行了定性比較。

從字體重構的實驗結果,可以看出:
Im2Vec可以捕獲復雜的拓撲結構并輸出矢量圖形;
ImageVAE具有良好的保真度,但輸出的柵格圖像分辨率有限;
SVG-VAE和DeepSVG能產生矢量輸出,但往往不能準確再現復雜的字體。
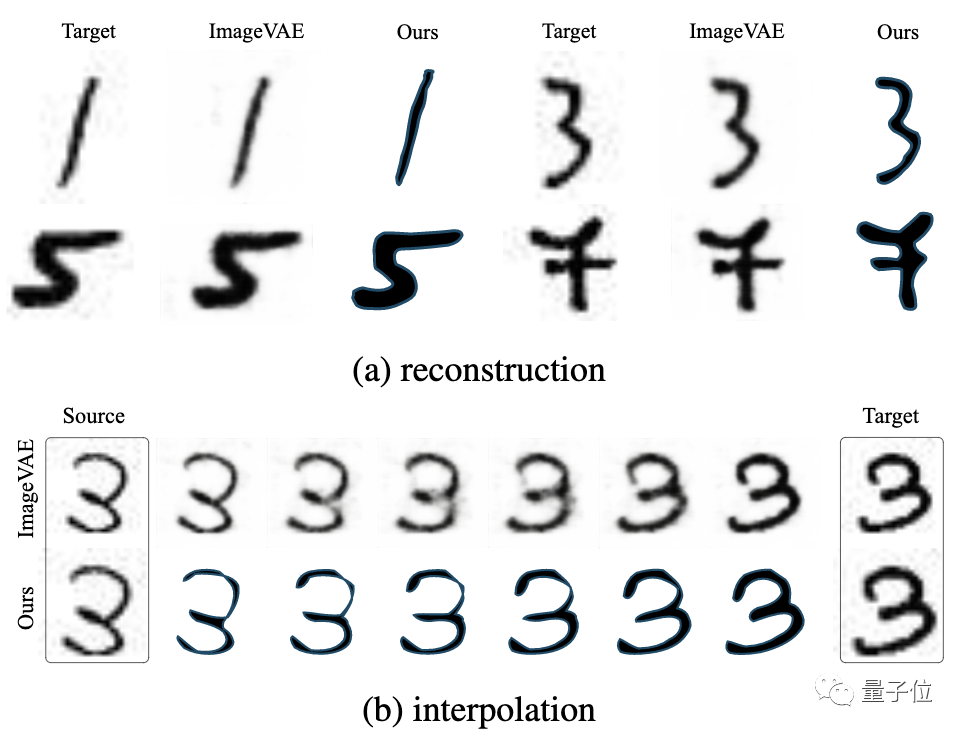
在MNIST數據集上訓練的結果顯示:
由于只有柵格數據,沒有矢量圖形基準,SVG-VAE和DeepSVG都不能在這個數據集上訓練;
對于ImageVAE和Im2Vec,在沒有數字類專門化或條件化的情況下,ImageVAE則受到低分辨率柵格圖像的限制(圖a),而Im2Vec能夠生成矢量輸出,因此具有相關的可編輯性和緊湊性優勢;二者在生成插值上也都實現了較好的效果(圖b)。
在Emojis和Icons數據集測試模型的重建性能,可以看到Im2Vec模型可以在任意分辨率下進行光柵化。
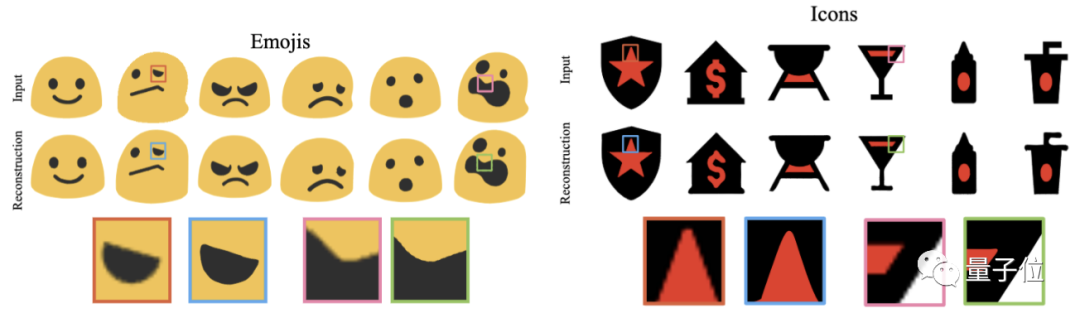
通過對不同方法的重構性能進行對比,研究團隊得到結論:
雖然基于矢量的方法具有能夠重現精確的矢量參數的優點,但它們受到矢量參數和圖像清晰度之間非線性關系的不利影響。
SVG-VAE和DeepSVG所估計的矢量參數看似很小的誤差,卻可能導致圖像外觀的巨大變化。
而Im2Vec不會受到矢量參數和像素空間之間目標不匹配的影響,因而在重構任務中有顯著的改進。
生成和插值性能評估
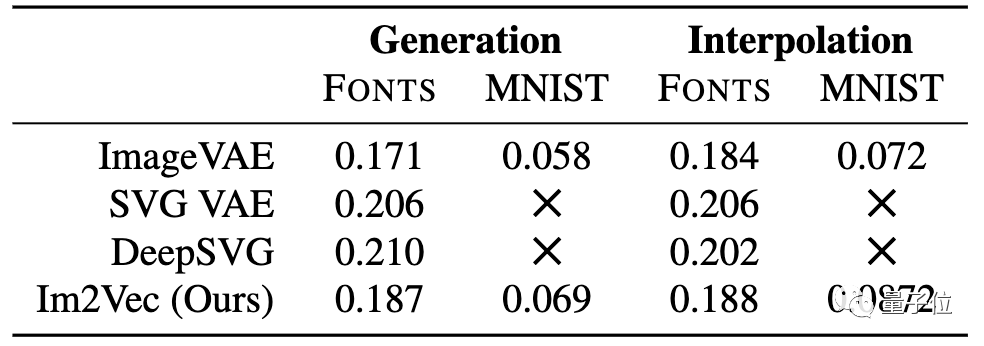
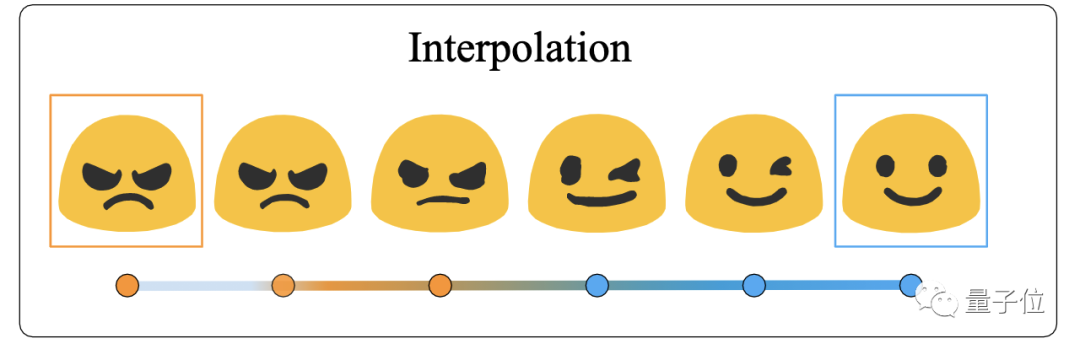

△Im2Vec插值性能的測試效果
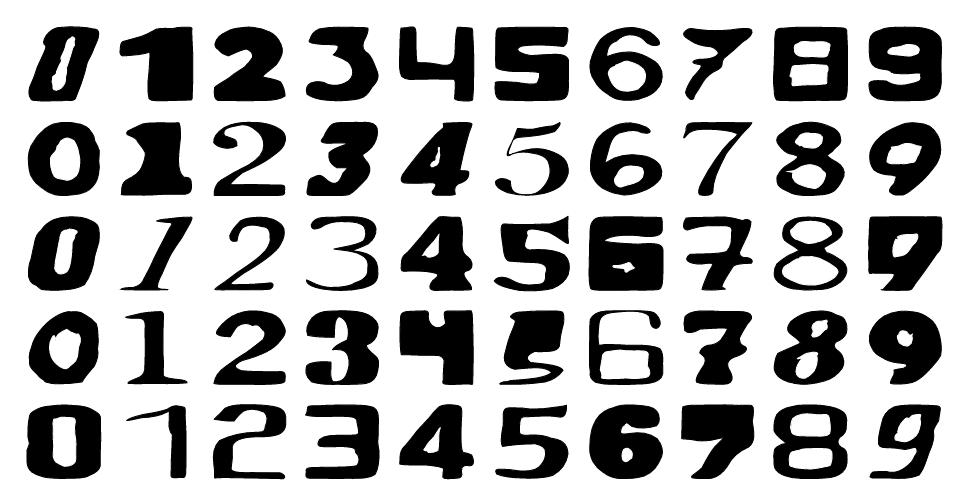
△Im2Vec生成的隨機樣本
從實驗數據可以看出,在FONTS和MNIST上,Im2Vec結果比其他方法都要準確,Im2Vec生成的隨機樣本,具有顯著拓撲變化。
局限
不過,Im2Vec也存在一些局限。

基于柵格的訓練性質給Im2Vec帶來了一定的限制,可能造成一些細微特征的丟失。這一問題可以通過犧牲計算效率提高分辨率,或者通過開發更復雜的圖像空間損失來解決。
此外,由于缺乏向量監督,在特殊情況下,Im2Vec可能會采用包含退化特征的近似最優值,或者考慮語義上無意義的部分來生成形狀。
結論
Im2Vec的生成性設置支持投影(將圖像轉換為矢量序列)、生成(直接以矢量形式生成新的形狀),以及插值(從矢量序列到另一個矢量序列的變形甚至拓撲變化),并且與需要向量監督的方法相比,Im2Vec實現了更好的重建保真度。
根據研究團隊主頁介紹,這篇論文已經入選CVPR 2021。