如何應用數據模型?
????一 前言
Vmo 是我在 18 年發布的一個工具庫,用于快速創建數據模型,當時我寫了一篇文章《Vmo 前端數據模型設計》得到過一段時間的關注,當時我從事三維裝修相關的項目。在圖形學的背景基礎及海量復雜的數據的情況下,自然而然在前端則會衍生出一種數據處理、解析、消費的技術方案,也種下了我對數據模型概念的種子。
簡單舉個例子:需要解析一個三維裝修的房子的數據會有哪些呢?
- 房子(Hourse),樓層(Layer),房間(Room),墻體(Wall),墻面(WallSpace),墻角(Corner),吊頂(Ceiling),踢腳線(Skirting),地(Floor,帶厚度),地面(FloorSpace),門(Door),窗(Window)。
- 以及會延伸出來大量的變體,比如飄窗,直角飄窗,弧形窗,墻洞,樓梯等等。
在解析這些數據中存在非常多的相互關聯和計算,比如 房間需要和墻面,墻面需要和墻體關聯,墻體和最多 2 個房間關聯,墻角和多個房間關聯,墻角和多個墻體關聯等等
面對這樣海量、復雜的數據,如果只靠著一個 API 請求的結果消費顯然是非常不可取的方案,先不說這些數據能不能正確的解析出來,就說這些數據如何維護,保存時如何收集到所有數據反向序列化給后端都是些頭疼的問題。
當然這些問題在當時我們抽象的各個數據模型中得到了解決,如果想了解具體細節可以查看我之前的文章。
今天我想講的是,在我加入阿里后,一直在思考的關于數據模型的兩個問題:
- 是不是數據模型這種事情對于常規項目沒有使用場景或者價值呢?常規的,像一些數據查詢,或者填寫一些數據提交。這種需求里面有必要使用什么抽象類,什么數據模型嗎?
- 為什么在前端圈子里面,很少有看到這方面的內容,現在前端圈子里大多都是在走向函數化,Composition等等,是不是這條路子走的有問題?
在尋覓了 2 年后,主導 Lazada 商家端的商品發布頁面重構時,仿佛找到了一些答案。
二 商品模型
首先在新增一個商品的過程中,實際上是用戶在以客戶端的形式制作一組商品數據,常規的前端視角來看就是提交一份“JSON”。
而編輯就是通過 API 拉取這份“JSON”解析到 Form 表單中,讓用戶進行編輯后,再將這份“JSON”提交。
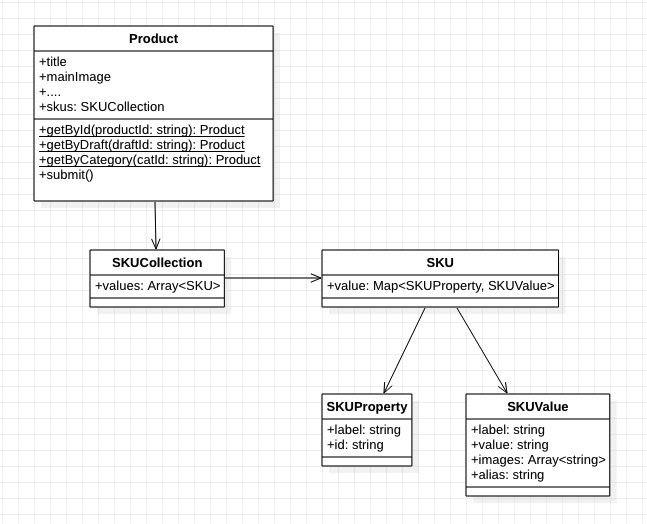
那么粗略的將數據抽象為模型將會成為這樣:
?? 
Well,到目前為止,我們做的事情都感覺像是在脫褲子放屁,多此一舉。哈哈哈,各位看官暫且勿噴,稍安勿躁 。
那么為什么需要把這些數據抽象為一個類呢?我拿一下幾個 Case 來說明:
1 請求數據 & 單元測試
很多時候,前端把對數據的請求和處理是寫在組件中的,更優一點可能會封裝在某個聚類里面,或者某個 Hook 里面,調用時輕巧的拿到狀態和數據。
像商品這樣的數據請求方式會存在多種:草稿中獲取,編輯中獲取,某個類目中獲取(不同類目下,商品屬性不同)。
每種獲取方式請求的接口和參數組合方式可能不同,但最后前端消費的產物卻是相同的。按照策略模式來說,對于一個商品模型的獲取只是使用了不同的策略,但產物卻是一致的,消費端無論調用何種方式,獲取到的結果都是可靠的 Product 模型類。
有經驗的前端都知道,很多時候,在一個項目在一輪輪的迭代后,我們的接口數據往往會存在部分數據需要前端做一定處理或者轉換。
面對這樣的數據處理,如果放在一個組件或者 Hook 中,是不太合適的,在做單元測試或者數據消費的時候都可能會給我們帶來一些阻力。
在我看來,調試一個數據問題最好的辦法,就是寫一個單元測試,對單元測試預期的結果進行調試,往往比我們在瀏覽器中 Mock 一份數據調試數據更高效,對將來的穩定性也更有幫助。
安全感,數據消費起來,一個類和一份 JSON 給開發者帶來的安全感和爽感是完全不同的。消費過數據模型 或者 次一點 消費過Interface的小伙伴,我相信對這一點是非常認同的。
哈哈,說到這里有些小伙伴可能要問了,你說的這個我們用Interface也能達到同樣的效果呀。好,咱們繼續...
2 計算性消費數據
什么叫計算性消費數據的,說的簡單點,就比如:
上面這個例子非常經典且清晰,元數據中可能只是些基本數據,但是很多時候前端需要根據不同場景來進行元數據組裝,以往這些數據往往會被封裝為各個方法,或者被當做 template 寫在組件中,散落在各個角落,每當用到這份數據時可能又會重新按照場景組裝一遍。往往這種時候就會存在 需求缺失,比如某情況下需要將之前所有消費到 fullName 的地方改為小寫。
拿到商品發布來說,計算性消費數據到底有哪些應用場景呢?
在此之前,我想先解釋一下SKU這個數據模型,它其中最核心的元數據是:value: Map
?? 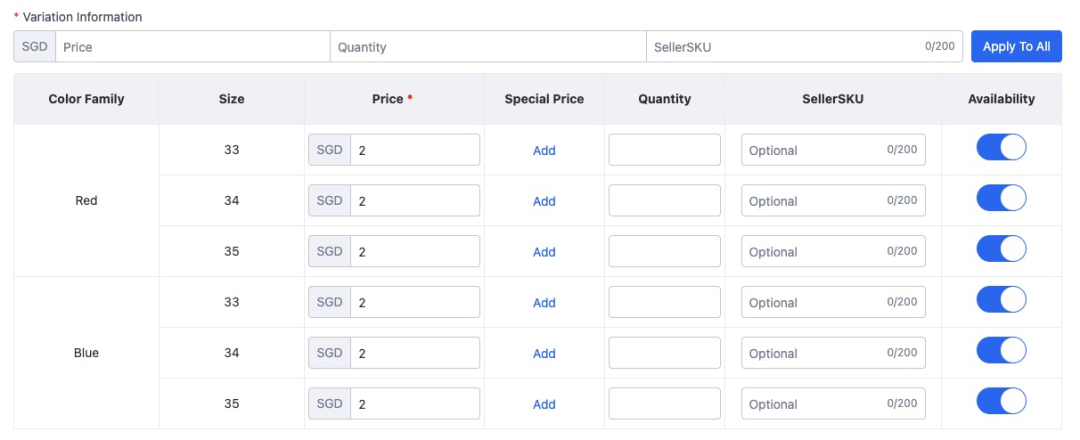
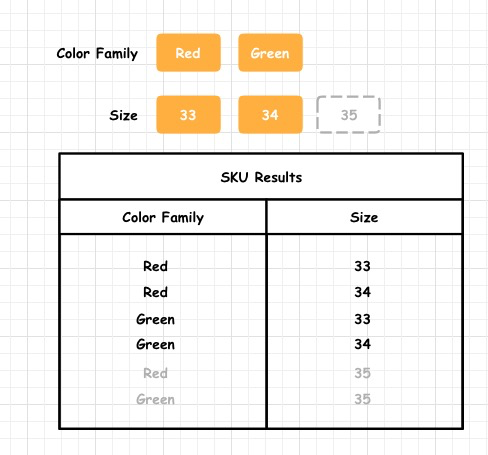
按照上圖這個表格中所示,可以看到該商品共有 6 個 SKU,第一個 SKU 所對應的SKU模型數據應為:
?? 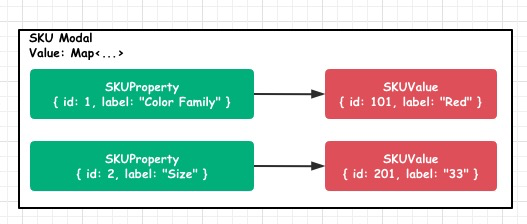
像這樣一個 SKU Model,它所具備的元數據已經可以清晰描述當前 SKU,而且可以通過 SKU 的擴展方法做到很多有用的數據,比如:
- getProperties() 獲取該 SKU 有所有屬性,如:Color Family,Size。
- getValues() 獲取該 SKU 所有Value,如:Red,33。
- isEqual(anotherSKU: SKU): boolean 比較一個 SKU 是否和當前 SKU 完全相同,這在后續的數據合并中非常有用。
- getValueByPropertyId(id: string) 通過 PropertyId,獲取一個 SKUValue。
相比與只是一個 Object 對象來說,數據模型能夠帶來非常多的數據處理和數據擴展能力,當某種情況下需要消費由該數據產生的計算性消費數據時,可以很輕易的進行擴展使用,對于數據結構也有更好的預期和掌控力。
結合對該數據模型的單元測試,就可以清晰快速的開發數據層,當數據層可靠后,在視圖層消費就會變得行云流水,得心應手了。
舉個單元測試的例子:
這種SKU,是一種類型較為特殊的SKU,它其中會存在 alias 字段,當有這種字段時,在做SKU比對時,不但要對 SKUProperty,SKUValue 的ID做比對,還需要對 alias 字段做比對。
所以按照上面的單測來看,結果應該是 false,因為這兩份數據中的alias是不同的。沒辦法,這是一個業務需求。
如果在視圖層做數據比對時,使用的是純數據進行比對,很有可能漏掉這部分邏輯,這就會導致項目變得捉襟見肘,拆東墻補西墻。
反正,在消費層遇到很多的需要對數據處理或判斷時,大可以將這部分能力交給數據模型來處理,由數據模型來保證數據的穩定性。
3 數據關系
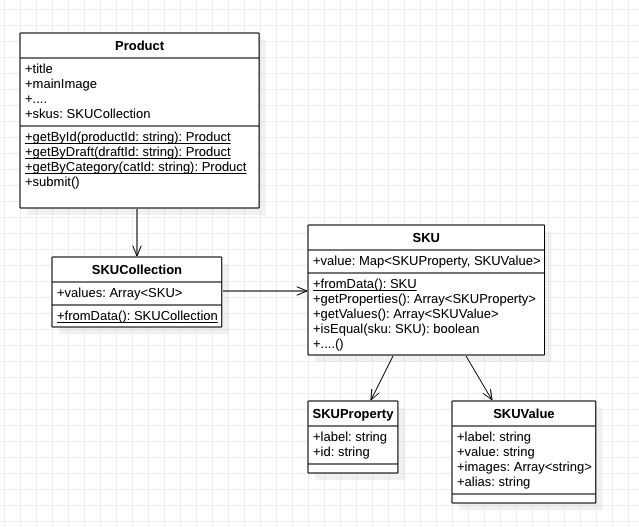
使用數據模型,還可以幫你清晰管理數據關系,比如商品和SKU之間,SKU和SKUProperty,SKUValue 之間的關系。
我舉個具體案例:
?? 
這是一個商品編輯時組 笛卡爾積(Cartesian product) 的過程,當我們的SKU屬性被用戶添加或者修改時,將會觸發笛卡爾積的重新計算出最新的排列組合結果。
比如當用戶新增一個尺碼為35時,笛卡爾積將會多出兩項組合結果。同理,如果當維度增加一列時,比如添加材質維度,將會產生更多SKU結果。
以往,前端開發者總會將這部分計算過程封裝成為一個數學方法,放在utils中隨時調用,這看起沒什么問題。
如果將這個過程看做是,一個 SKUCollection 數據模型的構建過程的話,一切就會將變得順理成章:
有了這樣一個數據模型結構后,就可以清晰的通過數據模型來調用其相關的數據和計算性數據。
另外,不同的數據模型雖然相互依賴,但對數據解析和計算性數據缺相互獨立,可以做到獨立使用和單元測試。
?? 
三 異常模型
商品發布本質上是一個較為復雜的表單提交頁面。由于字段多,交互復雜等原因,在產品設計過程中,就已經將很多字段先拆分為不同模塊,來減輕用戶心理負擔。
比如會存在:基礎信息,商品屬性,詳描,運費等。
在填寫過程中,會存在部分 前端校驗 + 后端校驗 的場景。
在數據提交或者其他數據寫入過程中,后端同時會處理字段校驗,當后端發現某個字段填寫錯誤時,服務端將返回錯誤信息及錯誤字段信息。
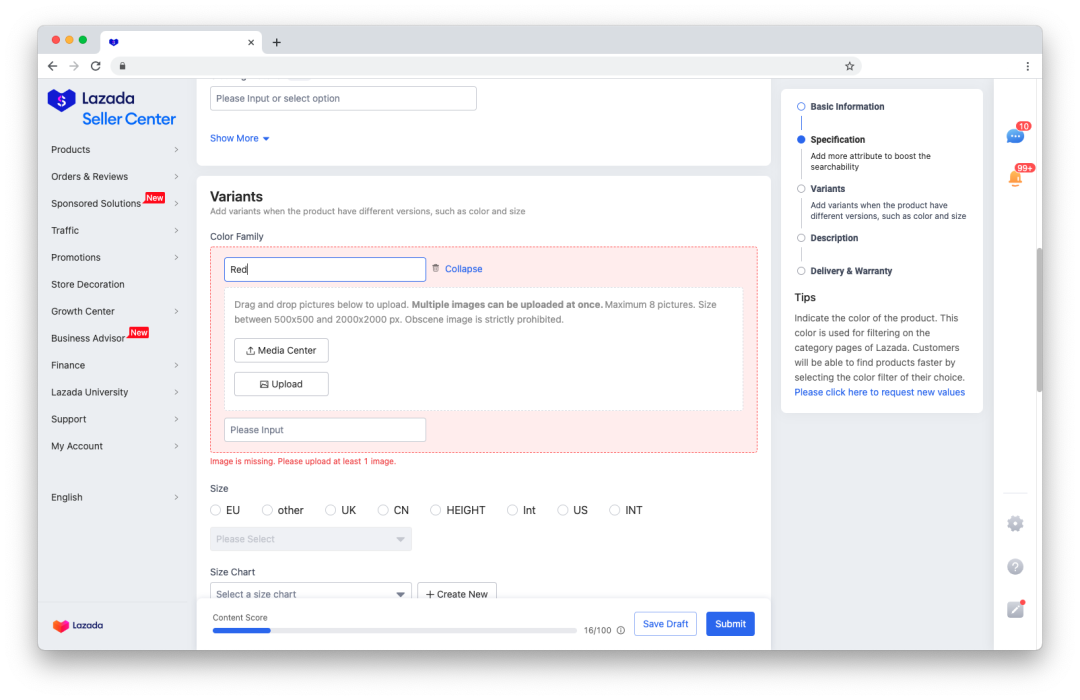
為了更好的交互體驗,前端將會根據返回獲取到字段信息,定位到對應的字段位置,顯示錯誤信息并報紅,另外還需要根據當前字段判斷其所歸屬的模塊進行報錯。
?? 
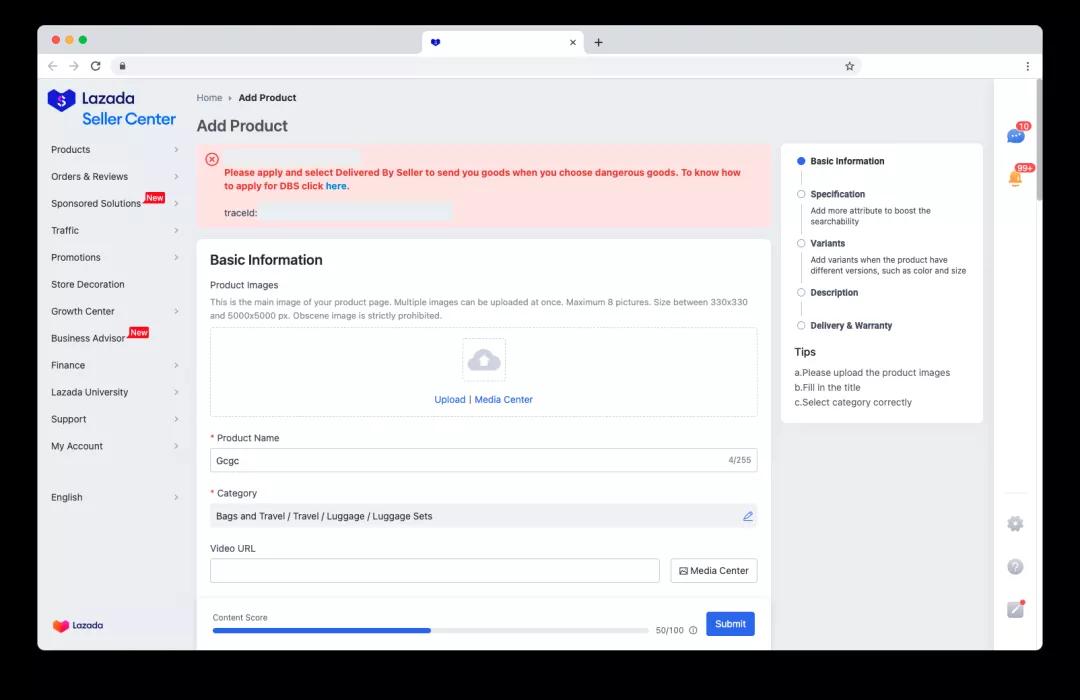
還有一種情況是:服務端的第一層校驗通過,調用其他商品上游鏈路時拋出異常,此時上游鏈路可能已經丟失字段信息,面對這樣的異常數據,前端需要展示在表單頂部,并且提供traceId,以便追蹤定位異常。
?? 
就商品發布來說,顯而易見的"保存"的動作是一個需要處理異常的情況,所以我們會在提交的地方寫上很多后端返回異常時的處理邏輯。
當有一天,有另外一個迭代需要寫入操作時,同樣也會產生異常的情況,這些的異常情況再次處理時又會有很多數據轉換和錯誤顯示的邏輯。
如果收到這份后端返回數據,將他轉換為異常數據模型,然后交由視圖層消費,這樣會讓所有異常模型下需要處理的邏輯復用避免交互邏輯丟失。
當然,視圖層如何更巧妙的消費該數據模型又是另外一個有意思的設計,此處暫且不表,后面我還會寫一篇專門介紹商品發布的視圖層狀態管理設計。
四 總結
在商品發布中,除了上述提到的幾個數據模型以外,其實還構建了一些其他類型的數據模型,如:運費模型,商品質量分模型,類目推薦模型等... 然后由這些多個子模型共同組合成為一個商品的模型。
這樣的數據模型在消費起來,開發者其實不會太過關心究竟需要請求什么API,返回的數據究竟是什么樣的,他們的返回是否要處理、轉換、兼容等問題。
同時,這樣高質量的數據模型其實不依賴于視圖層的框架,它可以被抽離作為一個獨立的包來管理維護,然后在其他頁面引入使用,比如商品域可能遇到的:商品管理,商品選擇,運費編輯,商品質量分預覽等等...
回到開頭,我提到的問題:
- 是不是數據模型這種事情對于常規項目沒有使用場景或者價值呢?常規的,像一些數據查詢,或者填寫一些數據提交。這種需求里面有必要使用什么抽象類,什么數據模型嗎?
- 為什么在前端圈子里面,很少有看到這方面的內容,現在前端圈子里大多都是在走向函數化,Composition等等,是不是這條路子走的有問題?
首先肯定的是,在我所使用的過程中,數據模型確實非常清晰,有力,牢固的解決了我所面到的業務問題,所以它是有價值的。
至于和常規的需求,到底應該用什么好呢?哈哈,這個問題有個比較無賴的回答,小孩子才考慮什么要什么不要,成年人什么都要,沒有什么技術是非黑即白的。
Vite 就只能在 Vue 的項目里面使用嗎?
什么合適用什么,簡單的數據查詢展示不需要這么精細的數據處理,當然可以直接拿來即用咯,解決業務問題的方法就是好方法!
至于Composition API,其實在商品發布的重構過程中,基本絕大多數都是使用這種設計思路來實現的,這樣的設計確實能讓我們清晰的分辨每個方法是干什么的,是否會影響交互,以及這樣的交互是在做什么,每個交互都在一個位置維護和處理,后面我會單獨寫一篇介紹。
實踐過程中發現,數據模型和Composition API并不沖突,一個是用來處理數據層,一個是用來處理視圖層,它們相輔相成結合一些訂閱模式的設計,就會讓整個項目的劃分異常清晰,我十分建議大家在以后遇到單點項目較為復雜時能夠使用這一套思路來解決業務問題!