大數據分析工程師入門4-SQL進階

數據分析工作中,免不了與SQL數據庫打交道,尤其是對庫表的使用,所以如何對庫表進行創建、修改和刪除,是一項基礎技能。
DDL(DataDefinition Language的簡寫形式)是SQL語言集中負責數據結構定義與數據庫對象定義的語言,由CREATE、ALTER與DROP三個語法所組成。
接下來分為庫、表兩部分給出示例代碼供讀者學習了解。
- 庫相關操作
- # 創建數據庫
- CREATE DATABASE testdatabase;
- # 選擇數據庫
- USE testdatabase;
- # 刪除數據庫
- DROP DATABASE testdatabase;
- # 列出已有數據庫
- SHOW DATABASES;
以上操作語句如果是在命令行中執行,需注意要以分號結束。
CREATE DATABASE關鍵字后面的testdatabase就是新創建的庫名,庫名需要是唯一的,也就意味著不能和已經存在的庫重名。USE testdatabase命令的作用就是切換到testdatabase庫下進行后續操作。SHOW DATABASES會列出所有當前用戶能訪問到的數據庫庫名。
- 表相關操作
- # 創建表
- CREATE TABLE test1 (
- id INT unsigned NOT NULL AUTO_INCREMENT,
- name VARCHAR(225),
- price DECIMAL(10,2),
- PRIMARY KEY (id)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- # 刪除表
- DROP TABLE test1;
- # 修改表字段類型
- ALTER TABLE test1 MODIFY name VARCHAR(100);
- # 添加表字段
- ALTER TABLE test1 ADD COLUMN age INT(3) FIRST;
- # 刪除表字段
- ALTER TABLE test1 DROP age;
- # 修改表字段名稱
- ALTER TABLE test1 CHANGE age age2 INT(20);
- # 表重命名
- ALTER TABLE test1 RENAME test2;
- # 查看表結構
- DESC test2;
同樣,以上操作語句如果是在命令行中執行,需注意要以分號結束。
CREATE TABLE 的時候,要求新指定的表名必須不存在,否則會出錯,這主要是為了防止意外覆蓋已有的表。
ALTER TABLE后面給出的要更改信息的表名必須存在,否則將報錯。使用ALTERTABLE要極為小心,應該在進行改動前做完整的備份(表結構和數據的備份),增加列會對數據存儲造成影響,因此要盡量避免此類操作。
類似地,如果刪除了不應該刪除的列,可能會丟失該列中的所有數據。刪除表操作同樣無法撤銷,所以執行該操作之前需十分謹慎小心。
另外和大家分享下,工作中常用的建表小技巧:
1. 創建表時,盡量使用一個自增的整型字段做主鍵。這樣做,如果后續需要使用spark等框架分析這個表時,是非常方便的。
2. 創建表時,可以增加兩個字段create_time和update_time。create_time存儲記錄的創建時間,update_time存儲記錄的最后一次變更時間,方便后續排查數據的變更情況。如果是使用MySQL,需要5.7及以上版本,具體語法示例如下:
- CREATE TABLE test1 (
- id INT unsigned NOT NULL AUTO_INCREMENT,
- name VARCHAR(225),
- price DECIMAL(10,2),
- create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
- update_time TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
- PRIMARY KEY (id)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3. 可以考慮增加一個邏輯刪除列,存儲記錄的生效狀態。這樣在刪除數據時,可以進行邏輯刪除,即把狀態為改為失效,而不是真的把數據刪掉。

MySQL索引的建立對于MySQL的高效運行是很重要的,索引可以大大提高MySQL的檢索速度。主要分為兩種類型,單列索引和組合索引。
接下來,我們一起來看下如何創建不同類型的索引:
- 建表時創建
語法:
- CREATE TABLE 表名(
- 字段名 數據類型 [完整性約束條件],
- ……,
- [UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
- [索引名](字段名1 [(長度)] [ASC | DESC]) [USING 索引方法]
- );
- 說明:
- UNIQUE:可選。表示索引為唯一性索引。
- FULLTEXT:可選。表示索引為全文索引。
- SPATIAL:可選。表示索引為空間索引。
- INDEX和KEY:用于指定字段為索引,兩者作用是一樣的。
- 索引名:可選。給創建的索引取一個新名稱。
- 字段名1:指定索引對應的字段的名稱,該字段必須是前面定義好的字段。
- 長度:可選。指索引的長度,必須是字符串類型才可以使用。
- ASC:可選。表示升序排列。
- DESC:可選。表示降序排列。
- BTree是最常見的索引方法,所有值(被索引的列)都是排過序的,每個葉節點到根節點距離相等。所以BTree適合用來查找某一范圍內的數據,而且可以直接支持數據排序(ORDER BY)。還有其他幾種索引方法,讀者可自行百度了解一下。
建表時創建單列索引和組合索引示例:
- CREATE TABLE classInfo(
- id INT AUTO_INCREMENT COMMENT 'id',
- classname VARCHAR(128) COMMENT '課程名稱',
- classid INT COMMENT '課程id',
- classtype VARCHAR(128) COMMENT '課程類型',
- classcode VARCHAR(128) COMMENT '課程代碼',
- -- 主鍵本身也是一種索引
- PRIMARY KEY (id),
- -- 給classid字段創建了唯一索引(注:也可以在上面創建字段時使用unique來創建唯一索引)
- UNIQUE INDEX (classid),
- -- 給classname字段創建普通索引
- INDEX (classname),
- -- 創建組合索引
- INDEX (classtype,classcode)
- -- 指定使用INNODB存儲引擎(該引擎支持事務)、utf8字符編碼
- ) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT '課程明細表';
- 建表后創建
語法:
- ALTER TABLE 表名 ADD [UNIQUE| FULLTEXT | SPATIAL] INDEX | KEY [索引名] (字段名1 [(長度)] [ASC | DESC]) [USING 索引方法];
- 或
- CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX 索引名 ON 表名(字段名) [USING 索引方法]
建表后創建單列索引和組合索引示例:
- --將id列設置為主鍵
- ALTER TABLE classInfo ADD PRIMARY KEY(id) ;
- --給classInfo表中的classid創建唯一索引
- ALTER TABLE classInfo ADD UNIQUE INDEX (classid);
- --給classInfo表中的classname創建普通索引
- ALTER TABLE classInfo ADD INDEX (classname);
- --給classInfo表中的classtype和classcode創建組合索引
- ALTER TABLE classInfo ADD INDEX (classtype,classcode);
索引建立以后,來看下如何對索引進行查看和刪除操作。
查看:
- show index from classInfo;
結果:

刪除:
- DROP INDEX 索引名 ON 表名
- 或
- ALTER TABLE 表名 DROPINDEX 索引名
示例:
- drop index classname on classInfo;
- alter table classInfo drop index classid;
索引的優點:
- 大大加快數據的查詢速度
- 使用索引字段分組和排序進行數據查詢時,可以顯著減少查詢時分組和排序的時間
- 創建唯一索引,能夠保證數據庫表中每一行數據的唯一性
- 在實現數據的參考完整性方面,可以加速表和表之間的連接
索引的缺點:
- 創建索引和維護索引需要消耗時間,并且隨著數據量的增加,時間也會增加
- 索引需要占據磁盤空間
- 對數據表中的數據進行增加,修改,刪除時,索引也要動態的維護,降低了維護的速度
創建索引的原則:
- 更新頻繁的列不應設置索引
- 數據量小的表不要使用索引(畢竟總共2頁的文檔,還要目錄嗎?)
- 重復數據多的字段不應設為索引(比如性別,只有男和女,一般來說:重復的數據超過百分之十五就不適合建索引)
- 首先應該考慮對where 和 order by 使用的列上建立索引

如果一個SQL執行緩慢,遠低于預期,我們該怎么去優化它呢?
關于這個問題,MySQL提供了一個explain命令,它可以對select語句進行分析,并輸出SQL執行的詳細過程和細節信息,以供開發人員進行針對性的優化。
explain的語法很簡單,首先我們通過一個簡單的sql查詢來了解一下:
- explain select * from user_info where id = 2
其返回結果如下:

返回的每一個字段代表什么意思呢?
簡單總結一下:
- id: SELECT 查詢的標識符. 每個 SELECT 都會自動分配一個唯一的標識符.
- select_type: SELECT 查詢的類型.
- table: 查詢的是哪個表.
- type: 訪問類型.
- possible_keys: 此次查詢中可能選用的索引.
- key: 此次查詢中確切使用到的索引,如果沒有選擇索引,鍵是NULL.
- key_len:表示查詢優化器使用了索引的字節數. 這個字段可以評估組合索引是否完全被使用, 或只有最左部分字段被使用到,如果鍵是NULL,則長度為NULL。
- ref: 哪個字段或常數與key一起被使用.
- rows: 顯示此查詢一共掃描了多少行. 這個是一個估計值.
- extra: 額外的信息.
以上各個字段中,我們來重點講解下select_type、type和extra,其他字段通過以上注釋相信大家已經基本能夠理解其含義了。
- select_type
表示查詢的類型,它的常用取值有:
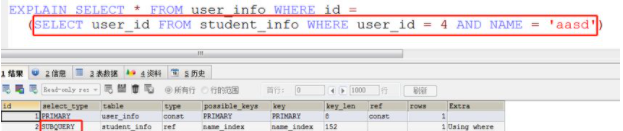
(1)SIMPLE,表示此查詢不包含 UNION 查詢或子查詢。示例見上文。
(2)PRIMARY,表示此查詢是最外層的查詢;
DEPENDENT UNION,子查詢UNION語句的第二個或后面的SELECT,取決于外面的查詢, 即子查詢依賴于外層查詢的結果;
DEPENDENT SUBQUERY,子查詢中的第一個 SELECT,取決于外面的查詢,即子查詢依賴于外層查詢的結果;
UNION RESULT, UNION 語句的結果集;
示例代碼如下,相同顏色標示sql語句與select_type值的相對應。
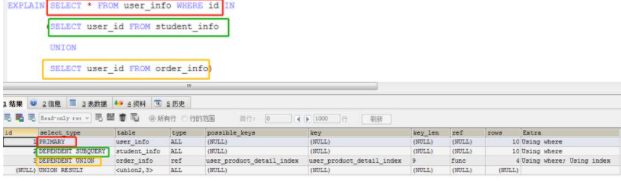
(3)UNION, 表示此查詢是使用UNION語句的第二個或后面的SELECT
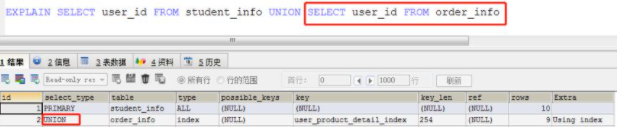
(4)SUBQUERY, 子查詢中的第一個 SELECT
那么DEPENDENT UNION和UNION, DEPENDENT SUBQUERY與SUBQUERY之間有什么區別呢?
顧名思義,關鍵點就在于DEPENDENT了,它的作用在于標示子查詢依賴于外層查詢的結果。
在以上第(2)點示例中,內部“student_info.user_id=user_info.id” 與“order_info.user_id=user_info.id”條件會自動添加到UNION所使用的SELECT查詢的WHERE條件,然后再執行。
由于外部定義的user_info數據表的id數據列要在子查詢中使用,所以DEPENDENT UNION和DEPENDENT SUBQUERY關鍵字出現在select_type中。
- type
type表示的是訪問類型,以上示例中,已經出現了幾種type,接下來將常見type值及含義匯總一下:
|
Null >system > const > eq_ref > ref > range > index > ALL ,一般來說,得保證查詢至少達到range級別,最好能達到ref。結果值從好到壞依次是:
- extra
EXPLAIN 中的很多額外的信息會在 Extra 字段顯示, 常見的是以下四種:
|
本章節之前給出的示例中,有出現Using index和Using where,關于另外兩種的使用示例讀者感興趣的話可上網百度了解一下,這里就不再繼續舉例說明了。
能夠看懂explain的輸出,是對SQL或表結構進行優化的前提。所以,大家需要首先看懂并理解explain輸出內容所包含的信息,進而優化實現更加高效的查詢。

主從同步,簡單來說就是將一個服務器上的數據同步到另一個服務器上。
數據所在的服務器被稱為主服務器(Master),接受數據拷貝的服務器被稱為從服務器(Slave)。
主從同步主要有以下好處:
- 數據備份:主服務器上的數據出現問題后,可通過從服務器數據進行恢復;
- 提高主服務器的性能:在主服務器上生成實時數據,而在從服務器上分析這些數據;
- 提高整個數據庫服務的性能:在主服務器上執行寫入和更新,在從服務器上向外提供讀功能,可以動態地調整從服務器的數量,從而提升整個數據庫的性能;
為什么要單獨強調一下mysql的主從同步機制,那是因為在實際數據分析工作中,當我們通過hive、spark等分布式框架去訪問mysql數據庫的時候,此時的分布式讀取會對服務器產生很大的壓力,如果直接讀取主庫的話,極可能會導致正在運行的主庫線上任務暫停幾分鐘,進而對線上業務造成不良影響。
所以,一般建議盡量通過從庫進行數據讀取,避免對線上服務造成損害。
由于主從同步相關操作平時都是運維或者DBA他們在維護,作為數據分析人員很少會需要直接實現這些,所以這里對如何實現主從同步等相關知識點就不展開細講,感興趣的小伙伴,可參考一下鏈接,了解一下。
https://blog.csdn.net/qq_15092079/article/details/81672920
上面提到主從同步是一種實時的數據備份方案,通常我們還會定時去對數據庫做數據備份。
其目的,是為了防止執行一些災難性操作后,數據仍然可以恢復。
比如說,刪庫刪表。這是因為主從同步,通常是采用同步操作語句的方式,進行庫表結構和數據拷貝的。因此,如果主庫執行刪除數據庫或表的操作,從庫也會同步刪除。如果有定時備份的數據文件,出現這種情況,只需要把數據反向導入到數據庫中,就可以恢復。
mysql提供的數據備份的命令為mysqldump,通常是由DBA或者運維來進行備份操作,大家只需要知道這個知識點即可,方面平時溝通交流。
另外大家要有備份的意識,備份操作是十分必要的,相當于后悔藥。在筆者的公司,就發生過幾次數據誤刪的問題,都是通過備份完成恢復的。

show [full] processlist 能顯示用戶正在運行的線程,這在數據分析工作中對于協助故障診斷非常有幫助。
full關鍵字,可以不寫,如果加上后,會把正在執行的SQL語句完整打印出來。
我們來直接執行一下看看能返回哪些信息:
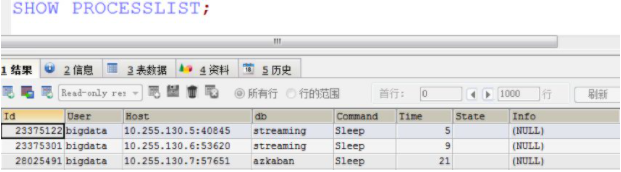
結果中的每個字段含義總結如下:
|
有一種情況,需要大家重點注意下,就是Command中出現Waiting for ... lock字眼時,表示有語句把庫或表給鎖住了。
通常這個時候,相關的操作庫或表的程序就會處于假死狀態,表現為程序卡住不動。這時就需要聯系DBA或運維看下是什么原因導致鎖庫或鎖表。所以,在你排查程序假死的問題時,如果程序有使用數據庫,可以考慮是不是這個因素導致的。
注:show processlist 顯示的信息都是來自MySQL系統庫 information_schema 中的 processlist 表。所以使用下面的查詢語句可以獲得相同的結果:
- select * from information_schema.processlist
數據分析工作中的常用操作:
1.按客戶端 IP 分組,看哪個客戶端的鏈接數最多
- select client_ip,count(client_ip) as client_num
- from (
- selectsubstring_index(host,':' ,1) as client_ip
- fromprocesslist ) as connect_info
- group by client_ip
- order by client_num desc;
2.查看正在執行的線程,并按 Time 倒排序,看看有沒有執行時間特別長的線程
- select *
- from information_schema.processlist
- where Command != 'Sleep'
- order by Time desc;
3.找出所有執行時間超過 5 分鐘的線程,拼湊出 kill 語句,方便后面查殺
- select concat('kill ', id, ';')
- from information_schema.processlist
- where Command != 'Sleep' and Time > 300
- order by Time desc;

MySQL默認設置下,一個連接最長等待時間為8小時,如果8小時都處于空閑狀態,就會出現連接超時問題,在使用MySQL時相信大家或多或少都會遇到這種狀況,這里跟大家分享下在遇到這種情況時,通常采取的措施和解決辦法。
首先,查看問題,看下wait_timeout的取值。
打開MySQL的控制臺,運行showvariables like '%timeout%',查看和連接時間有關的MySQL系統變量。
然后,解決問題,解決方式常用的有三種。
1. 增加 MySQL 的 wait_timeout 屬性的值
- //修改mysql配置文件,重啟后生效
- wait_timeout = 31536000
- or
- //通過mysql命令修改
- mysql> set wait_timeout= 31536000;
2. 減少連接池內連接的生存周期
通過代碼配置,讓線程在mysql提示超時前回收,并重新連接。以下舉例為c3p0連接池的配置,其他連接池(如Druid、Dbcp)原理類似。
修改 c3p0 的配置文件,在 Spring 的配置文件中設置:
- <beanid="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
- <property name="maxIdleTime"value="1800"/>
- <!--other properties -->
- </bean>
3. 定期使用連接池內的連接
定期使用連接池內的連接,使得它們不會因為閑置超時而被 MySQL 斷開。
修改 c3p0 的配置文件,在 Spring的配置文件中設置:
- <beanid="dataSource"class="com.mchange.v2.c3p0.ComboPooledDataSource">
- <propertyname="preferredTestQuery" value="SELECT 1"/>
- <propertyname="idleConnectionTestPeriod" value="18000"/>
- <propertyname="testConnectionOnCheckout" value="true"/>
- </bean>

普通語言里的布爾型只有 true 和 false 兩個值,這種邏輯體系被稱為二值邏輯。而 SQL 語言里,除此之外還有第三個值NULL,因此這種邏輯體系被稱為三值邏輯。
本章節對于NULL值這部分的講解重點在于提醒大家對NULL 使用比較謂詞后得到的結果總是 NULL 。
這是因為,NULL 既不是值也不是變量。NULL 只是一個表示“沒有值”的標記,而比較謂詞只適用于值。因此,對并非值的 NULL 使用比較謂詞本來就是沒有意義的。比如如下幾種比較,返回的結果均是NULL 。
- 1 = NULL
- 2 > NULL
- 3 < NULL
- 4 <> NULL
- NULL = NULL
所以,當SQL語句的where條件里有一個字段(比如age)有NULL值,用該字段用于謂詞比較判斷的時候,比如 age <> 30,表面上理解起來age字段中的NULL值跟30不等,那這個where條件返回的應該是true,從而age字段為NULL的記錄應該會被保留下來,實際上不是的,它們比較后返回的結果是NULL ,age字段為NULL的記錄會被過濾掉。
因此,要想留下NULL值,正確的寫法為,age <> 30 or age is null。在沒有學到這個知識點之前,這樣進行數據過濾容易導致提取出來的數據結果與預期有偏差。

作為上一篇sql基礎的補充,結合實際工作經驗,給大家分享一下經常用到的更深層一點的sql技能,包括有DDL、索引、EXPLAIN、主從同步、數據備份、show processlist、wait_timeout和NULL值判斷,希望大家有所收獲哦!