NLP 訓練及推理一體化工具(TurboNLPExp)
作者:TurboNLP,騰訊 TEG 后臺工程師
導語
NLP 任務(序列標注、分類、句子關系判斷、生成式)訓練時,通常使用機器學習框架 Pytorch 或 Tensorflow,在其之上定義模型以及自定義模型的數據預處理,這種方式很難做到模型沉淀、復用和共享,而對于模型上線同樣也面臨:上線難、延遲高、成本高等問題,TEG-AI 平臺部-搜索業務中心從 2019 年底開始,前期經過大量調研,在 AllenNLP 基礎上自研了推理及訓練一體化工具 TurboNLP, 涵蓋了訓練框架 TurboNLP-exp 和推理框架 TuboNLP-inference,TurboNLP-exp 訓練框架具備可配置、簡單、多框架、多任務、可復用等特點,在其之上能夠快速、高效的進行 NLP 實驗.
TurboNLP-inference 推理框架底層支持高效的模型推理庫 BertInference,集成了常用的 NLP 模型, 具備無縫兼容 TurboNLP-exp、推理性能高(在 BERT-base 文檔分類業務模型上實測,FP6 精度在 batch_size=64、seq_len=64 的情況下達到了 0.275ms/query,INT8 精度在 batch_size=64、seq_len=64 的情況下達到了 0.126ms/query 性能)等特點,NLP 訓練和推理一體化工具極大的簡化了訓練到推理的流程,降低了任務訓練、模型上線等人力成本,本文將主要介紹 NLP 訓練和推理一體化工具。
背景
- NLP 任務通常是算法研究者自定義模型和數據預處理在機器學習框架Pytorch或Tensorflow進行訓練,并手動部署到 libtorch 或 tensorflow 上,這一過程存在如下問題:
- NLP 任務已有的模型結構和數據預處理重新定義,重復性高。
- 手動修改模型結構和數據預處理代碼,不斷調整訓練參數,反復試驗,造成代碼混亂。
- 模型復雜度(多模型多任務)高或需要對現有模型進行優化改進時,如不熟悉模型結構,就需要重頭梳理 Python 定義的模型和數據預處理代碼。
- 知識沉淀、模型復用及共享困難。
- 上線難、數據預處理 C++化復雜、推理延遲高。
- 流程化提升 NLP 任務的離線訓練及效果實驗效率困難,試錯成本高。
為了解決以上存在的痛點,在此背景下,我們打通了 NLP 訓練端到推理端、自研了訓練框架TurboNLP-exp及推理框架TuboNLP-inference,以下是框架的整體架構圖:
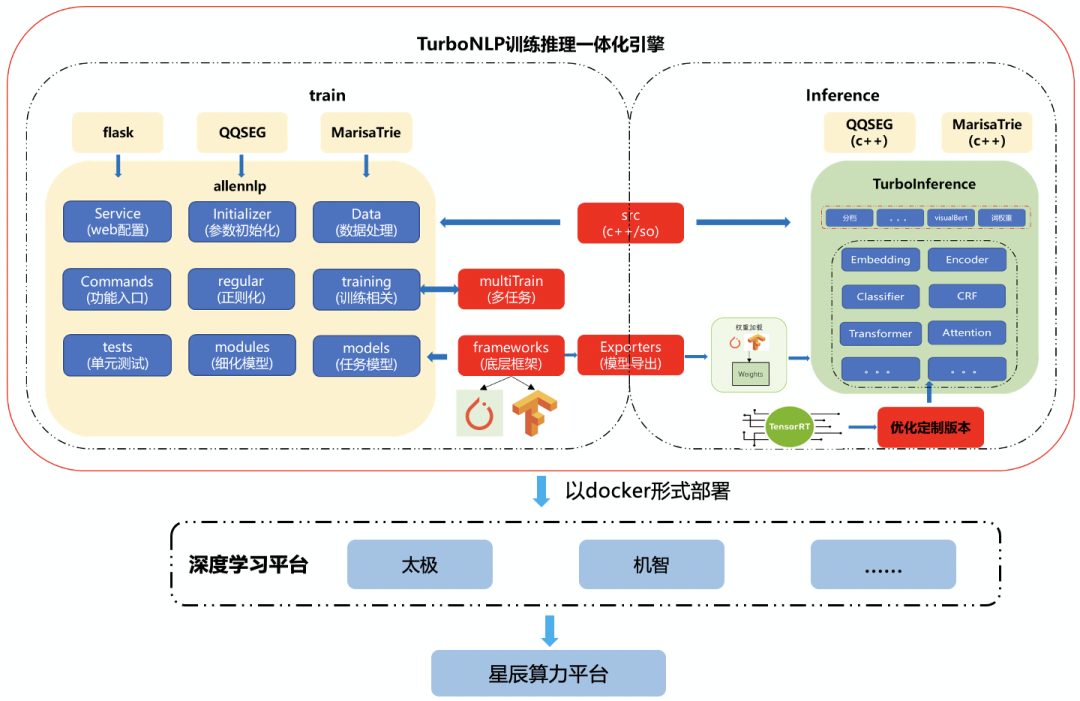
簡介
- 訓練框架 TurboNLP-exp
- TurboNLP-exp 具備模塊化、可配置、多平臺支持、多任務支持、多模型格式導出、C++數據預處理等特點、既能滿足研究者快速實驗、也能將模型通過配置沉淀到框架上,后續研究者通過配置來復用和共享知識。
- TuboNLP-exp 對模型和數據預處理進行了模塊化設計,對于數據預處理,針對同一類 NLP 任務(序列標注、分類、句子關系判斷、生成式)數據預處理基本一樣,通過復用配置即可復用已有的數據預處理;對于模型,TurboNLP-exp 集成了豐富的子模塊:embedder、seq2seq_encoder、seq2vec_encoder、decoder、attention 等,通過配置隨意的構建模型,達到快速實驗目的。
- TuboNLP-exp 對底層機器學習平臺(Pytorch 和 Tensorflow)進行了統一的封裝,熟悉不同的機器學習平臺絲毫不影響模型的復用、共享和知識沉淀。
- TurboNLP-exp 支持 C++和 Python 數據預處理,Python 數據預處理具備快速實驗調試的特點主要服務于訓練端,C++數據預處理具備性能高的特點主要服務于推理端,C++數據預處理和 Python 具有相同 API 接口,研究者在訓練階段能夠隨意切換 C++和 Python 數據預處理,保證訓練端和推理端的數據一致性。
- 推理框架 TurboNLP-inference
- TurboNLP-inference 能夠直接加載 TuboNLP-exp 導出的模型,根據配置來實例化數據預處理。
- TurboNLP-inference 提供統一的 API、完善的文檔和 examples,通過 examples 快速實現模型推理代碼,業務代碼通過 API 接口和 so 包調用推理庫。
- TurboNLP-inference 推理框架集成了 NLP 常用的模型:lstm、encoder-decoder、crf、esim、BERT,底層支持五種推理庫:BertInference(BERT 推理加速庫)、libtorch、tensorflow、TurboTransformers(WXG 開源的 BERT 推理加速庫)、BertInference-cpu(BERT 在 CPU 上推理加速庫)。
TurboNLP-exp 訓練框架
TurboNLP-exp 訓練框架是基于 AllenNLP 研發,為了滿足算法研究者和推理的業務需求,TurboNLP-exp 不斷優化,具備了業界框架不具備的特性,下表是 TurboNLP-exp 于業界其他框架的對比:
| 框架 | 難度 | 模塊化 | 可配置 | Pytorch | Tensorflow | 多任務訓練 | 多模型格式導出 | 數據預處理 | 推理 |
|---|---|---|---|---|---|---|---|---|---|
| PyText | 難 | T | T | T | F | F | F | Python | Caffe2 執行引擎 |
| AllenNLP | 簡單 | T | T | T | F | F | F | Python | 簡單的 Python 服務 |
| TurboNLP-exp | 簡單 | T | T | T | T | T | T | Python、C++ | 高效的 TurboNLP-inference |
以下會詳細介紹我們對 TurboNLP-exp 上所做的優化。
模塊化及可配置
TurboNLP-exp 的可配置程度高,源于其合理的模塊設計,通過模塊化封裝,TurboNLP-exp 支持隨意組合模型、擴展子模塊等,對于剛接觸的研究者 TurboNLP-exp 提供了界面化配置,通過可視化界面生成數據預處理和模型配置,大大降低了上手難度。
數據預處理模塊化及可配置
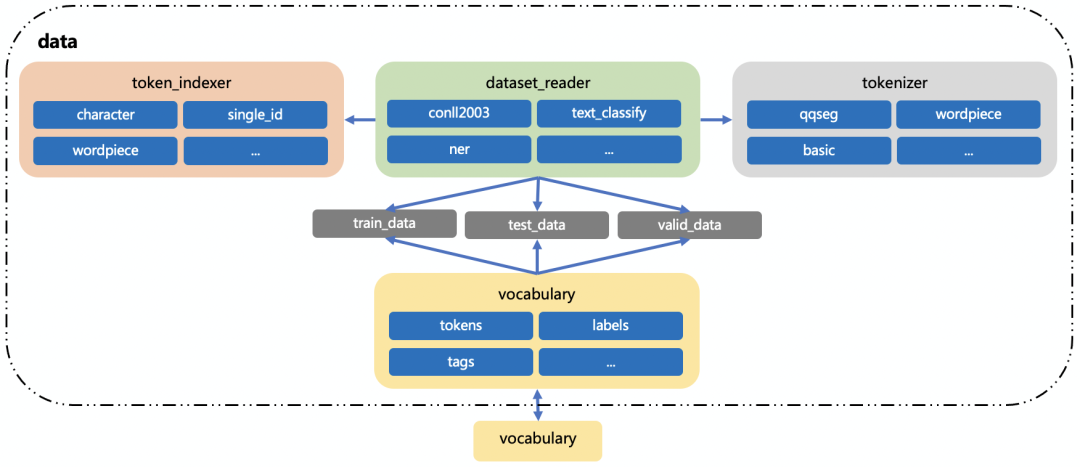
數據預處理粗略可分為dataset_reader、token_indexer、tokenizer、vocabulary四個模塊。
- dataset_reader:負責讀取訓練數據,使用分詞器進行分詞、索引器來進行 id 轉化;集成了多種數據格式讀取:文本分類數據格式、NER 數據格式、BERT 數據格式等,支持自定義擴展。
- token_indexer:負責對 token 進行索引(根據詞典轉化 id),集成了多種索引器:根據單字索引、根據詞索引、根據詞的屬性索引等,支持自定義擴展。
- tokenizer:負責對文本進行分詞,集成了 NLP 任務常用的分詞器:qqseg、wordpiece、whitespace、character 等,支持自定義擴展。
- vocabulary:數據詞典,支持從訓練數據中自動生成,并在訓練結束后保存到本地,或從本地已有的詞典文件中生成,vocabulary 會以命名空間的形式同時保存多個詞典(tokens 詞典、labels 詞典等)。
模型模塊化及可配置
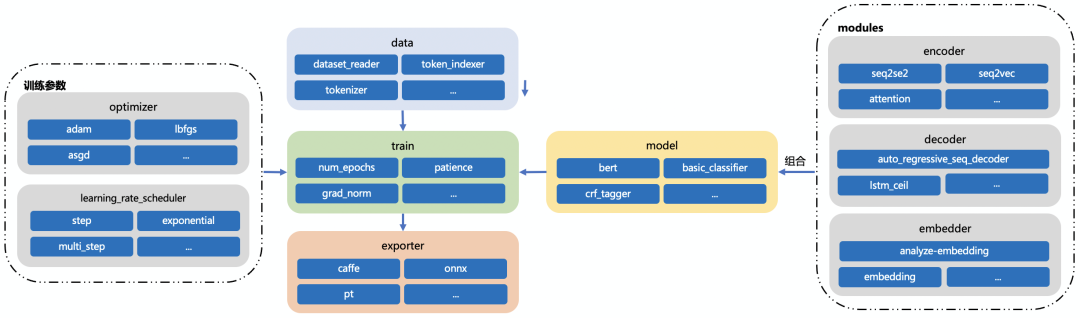
模型的模塊化設計可以分為三大塊:model、trainer、exporter。
- model:該模塊集成了 NLP 任務常見的模型:encoder、decoder、embedder 等,每一個子模型又有其他模型構成,這種組合式的模塊化設計,能夠很方便的根據配置來定義模型,對于同一類 NLP 任務,模型結構基本大同小異,研究者可以通過修改配置快速的調整模型結構,自定義擴展子模型。
- trainer:TurboNLP-exp 對訓練過程中用到的優化器、學習率、評價指標等都進行了封裝,通過配置來修改訓練參數,達到快速實驗的目的。
- exporter:該模塊集成了導出各種模型格式:caffe、onnx、pt格式,通過配置來定義導出的格式。
多平臺支持
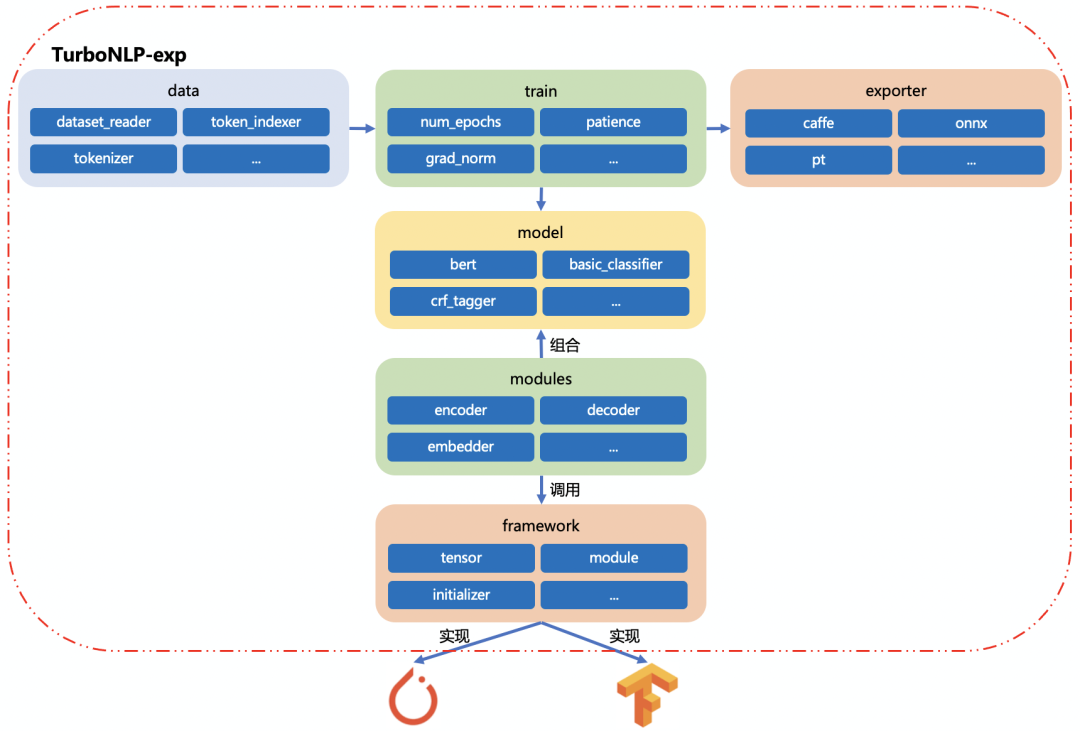
TurboNLP-exp 對底層機器學習平臺進行了抽象,實現統一的 framework 接口對底層的 pytorch 和 tensorflow 調用(如下圖所示),framework 根據配置來選擇 pytorch 或 tensorflow 來實現接口。目前以 pytorch 的格式為標準。
多任務訓練
多任務學習通過模擬人類認知過程的多任務特性,將不同類型的任務如實體識別、緊密度等集成在一個模型中,在共用的預訓練語言模型上,訓練各自的 tagger 層,在訓練中,通過各個任務領域知識和目標的相互補充,共同提升任務模型效果,在上線時,使用同一個底層模型,從而達到節省存儲及計算資源;目前,多任務的需求日漸增大,TurboNLP-exp 支持多任務多種組合方式及訓練調度方式(如下圖所示)
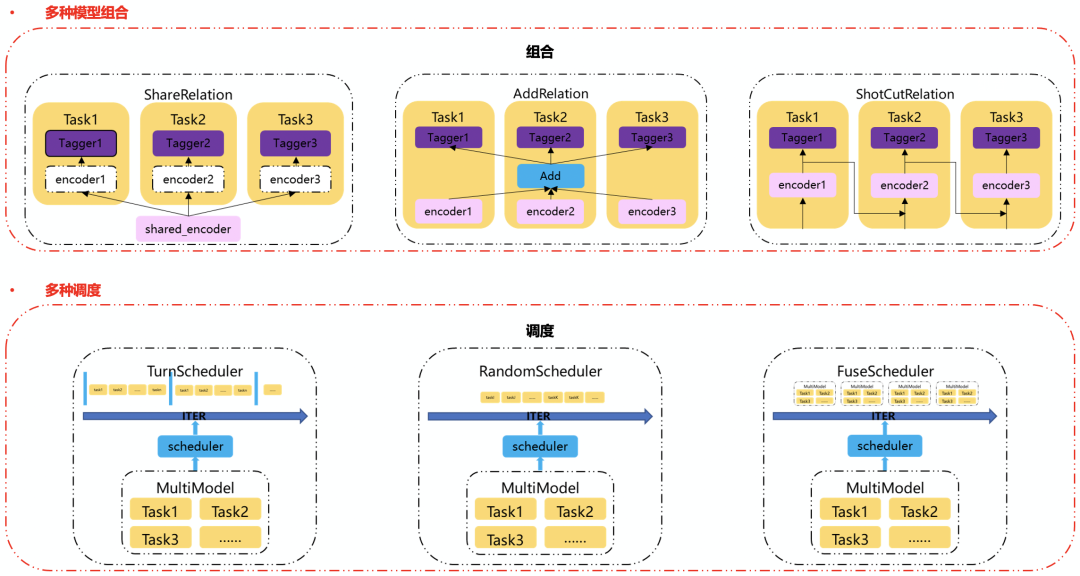
TurboNLP-exp 的多任務模型具備以下幾個特點:
- 能通過現有單任務模型快速組合多任務模型。
- 支持多種組合規則,包括:共享、累加、shotcut。
- 共享:多個模型共享同一個 encoder 輸出。
- 累加:每個任務的 encoder 累加后輸出到每個任務的 tagger 層上。
- shotcut:每個任務的 encoder 輸出將作為下個任務的 encoder 輸入。
- 支持多種訓練調度方式,包括:依次調度、隨機調度、共同調度。
- 依次及隨機調度屬于交替訓練,可以在多任務的基礎上獲取各自任務的最優解,且不需要構造統一輸入,更加簡單。
- 共同調度屬于聯合訓練,使用統一的輸入,由于 loss 最后會累加,因此查找的是多任務綜合最優解。
- 用戶可根據實際任務場景自由配置對應的組合方式和調度方式,以此來讓多任務能達到最優的效果。
多模型格式導出
TurboNLP-exp 能夠導出格式:caffe、onnx、pt,支持直接導出 TurboNLP-inference 推理框架支持的格式,直接推理端加載,無需再經過復雜的模型轉換。
數據預處理
TurboNLP-exp 的數據預處理能夠同時支持 Python、C++,Python 數據預處理主要服務于訓練端,C++數據預處理主要服務于推理端,也能服務于訓練端(如下圖所示)
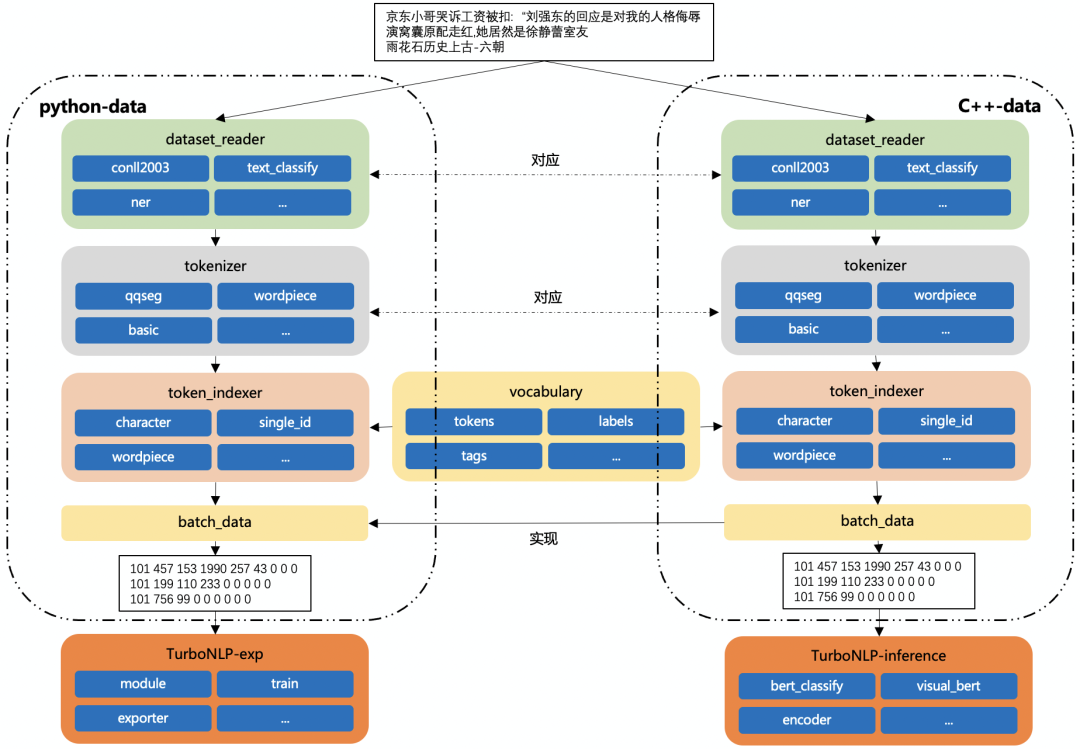
在訓練端,當數據預處理還處在修改、調試時,使用 Python 數據預處理能夠快速實驗,當 Python 數據預處理固定后,通過配置切換為 C++數據預處理來驗證數據預處理結果,從而保證訓練端和推理端數據一致性。
在推理端,使用與訓練端相同的配置,C++數據預處理輸出將作為模型輸入,C++數據預處理——TurboNLP-data采用多線程、預處理隊列來保證數據預處理的低延遲,在 BERT-base 五分類模型上實測,在 batch_size=64、seq_len=64 的情況下達到了0.05ms/query的性能。
TurboNLP-inference 推理框架
TurboNLP-inference 推理框架能夠無縫兼容TurboNLP-exp、具備低延遲、可配置等特點,TurboNLP-inference 底層支持五種推理庫:BertInference(BERT 推理加速庫)、libtorch、tensorflow、TurboTransformers(WXG 開源的 BERT 推理加速庫)、BertInference-cpu(BERT 在 CPU 上推理加速庫),其中,BertInference是我們基于TensorRT研發的一款高效能 BERT 推理庫,BertInference-cpu是和 intel 合作開發的一款在 CPU 上進行 BERT 推理加速庫。
以下是推理框架 TurboNLP-inference 和訓練框架 TurboNLP-exp 一體化架構圖:
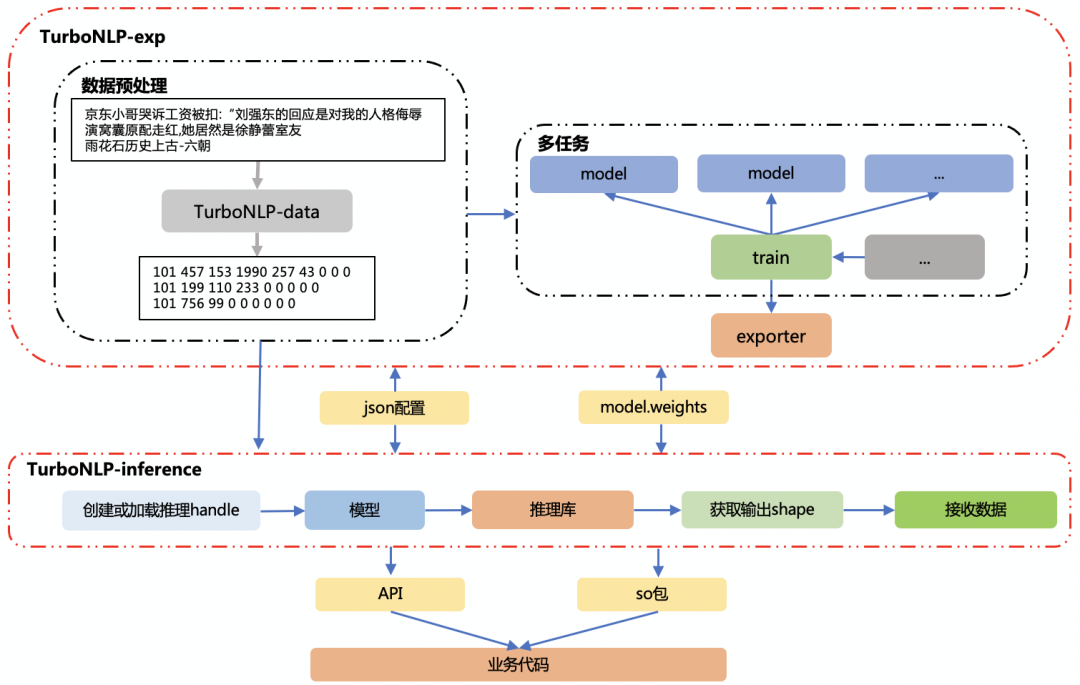
TurboNLP-inference 具備以下特性:
- 集成了 NLP 任務常用的模型:lstm、esim、seq2seq_encoder、attention、transformer等,根據配置構造模型結構及模型輸入。
- 能夠直接加載TurboNLP-exp的 exporter 導出model.weights模型格式。
- 使用 C++數據預處理——TurboNLP-data,并將數據預處理輸出自動的喂入模型輸入。
- 推理代碼將會以 C++ so 包和 API 的形式嵌入業務代碼中,盡量少的侵入業務代碼,修改靈活方便。
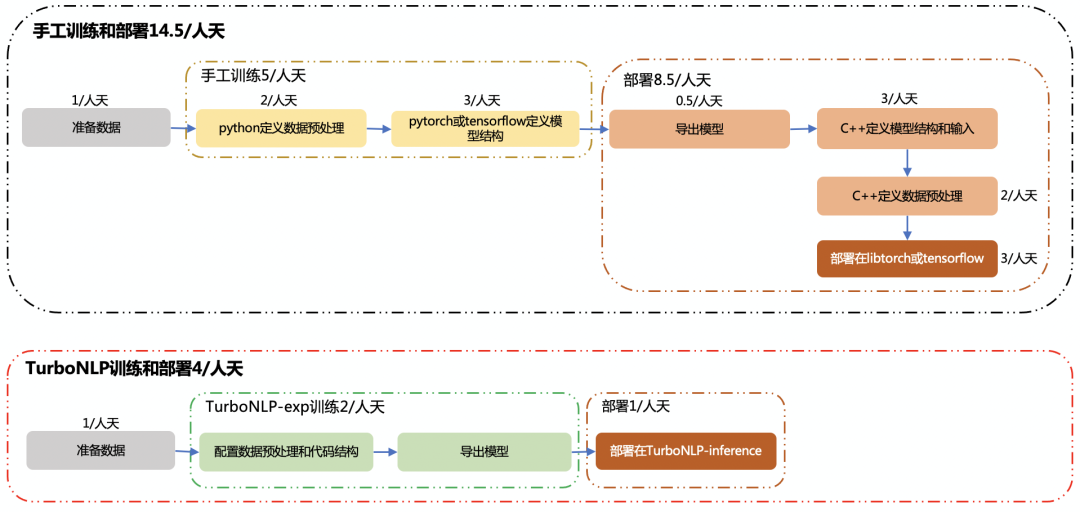
業務應用
NLP 一體化工具(TurboNLP-exp 訓練框架和 TurboNLP-inference 推理框架)極大的簡化了模型從訓練到上線的流程(如下圖所示),依據業務模型的實際上線流程,手工訓練和部署需要 14.5/人天,而使用 NLP 一體化工具僅需 4/人天,整體節省了**72.4%**人力成本。
TurboNLP-inference 目前已成功支持了 TEG-AI 平臺部-搜索業務中心的 5 個業務:
- 某業務的文檔分類 BERT 模型,FP16 精度在 batch_size=64、seq_len=64 的情況下達到了0.290ms/query的性能,機器資源節省了97%,上線周期縮短了近50%,極大的降低了機器和人力成本。
- 某業務的文本視頻關系判斷 BERT 模型,響應延遲減少為原來的 2/3,設備資源節省了92.8%。
- 某業務的 query 改寫 BERT-base 模型,相比于以前,極大的降低了上線周期及人力成本。
- 某業務多任務(encoder 為 BERT,decoder 為 GRU)模型,在 FP16 精度情況下,達到了2ms/query的性能。
- 某業務的 query 非必留 BERT-base 模型,上線周期極大縮短,在 FP16 精度情況下,達到了1.1ms/query的性能。
TurboNLP-inference 在業務上的表現,離不開對訓練框架的無縫支持以及底層高效推理庫的支持。
最新進展
TurboNLP-inference 的底層高效推理庫之一——BertInference 目前已具備支持 INT8 推理,優化了 Attention 計算,我們使用 BERT-base 文本分類業務模型和真實的線上數據進行了性能測試,效果如下:
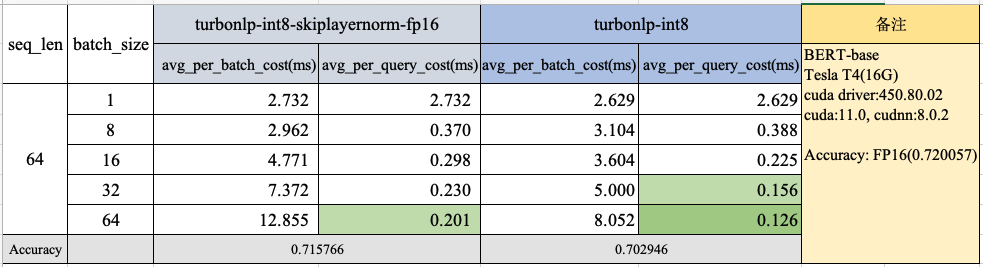
在 batch_size=64,、seq_len=64 的情況下,性能達到了0.126ms/query,INT8 相比于 FP16 提升了**54.2%**左右。
TurboNLP-inference 支持 INT8 校準,能夠使用已有的模型直接校準,通過配置調整校準過程,校準過程簡單,校準后可以直接使用 INT8 精度進行模型推理。
總結和展望
NLP 一體化工具(TurboNLP-exp 訓練框架和 TurboNLP-inference 推理框架)目前已經在 TEG AI 工作組內部演進,在預訓練模型方面也有一些合作應用,同時我們也正在積極與 AI 工作組的算力和太極機器學習平臺團隊積極合作,把訓練端能力在平臺上更好的開放出來。接下來訓練及推理框架也會在 TencentNLP 的公司統一協同 oteam 里面去演進,也期待在公司內更多團隊的合作。
TurboNLP-inference 的 BERT 推理加速在 INT8 精度模型效果上仍有進一步的提升空間,目前著力于 QAT 以及知識蒸餾、QAT 目前在五分類 BERT-base 模型上實測,Accuracy 僅降低了0.8%,加入知識蒸餾有望達到 Accuracy 不掉。