詳解堆排序解決TopK問題
上次介紹了堆排序,這次介紹堆排序常見的應用場景TopK問題。
利用堆求TopK問題TopK問題是一個堆排序典型的應用場景。
題目是這樣的:假設,我們想在大量的數據,如 100 億個整型數據中,找到值最大的 K 個元素,K 小于 10000。對此,你會怎么做呢?
對標的是Leetcode第215題:「數組中的第K個最大元素。」
具體鏈接:https://leetcode-cn.com/problems/kth-largest-element-in-an-array/
在未排序的數組中找到第 k 個最大的元素。請注意,你需要找的是數組排序后的第 k 個最大的元素,而不是第 k 個不同的元素。
- 示例 1:
- 輸入: [3,2,1,5,6,4] 和 k = 2
- 輸出: 5
- 示例 2:
- 輸入: [3,2,3,1,2,4,5,5,6] 和 k = 4
- 輸出: 4
經典的TopK問題還有:最大(小) K 個數、前 K 個高頻元素、第 K 個最大(小)元素
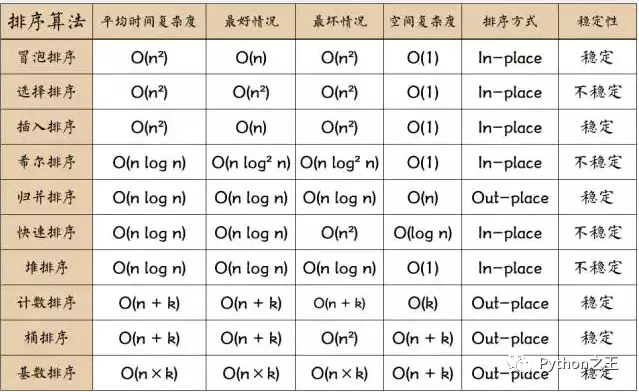
對此TopK問題本質上是一個排序問題,排序算法一共有十個,這個還有很多排序算法沒有介紹過。
至于為什么TopK問題最佳的答案是堆排序?其實在空間和時間的復雜度來考量,雖說快排是最好的排序算法,但是對于100億個元素從大到小排序,然后輸出前 K 個元素值。
可是,無論我們掌握的是快速排序算法還是堆排序算法,在排序的時候,都需要將全部的元素讀入到內存中。也就是說,100億個整型元素大約需要占用40GB的內存空間,這聽起來就不像是普通民用電腦能干的事情,(一般的民用電腦內存比這個小,比如我寫文章用的電腦內存是 32GB)。
眾所周知,快速排序和堆排序的時間復雜度都可以達到,但是對于快速排序來說,數據是順序訪問的。而對于堆排序來說,數據是跳著訪問的。比如堆排序中,最重要的一個操作就是數據的堆化。因此,快速排序的時間復雜度是優于堆排序的。
但是快速排序是新建數組,空間復雜度是,遠低于堆排序的。對于龐大的數據量,應該優先選擇堆排序。
如果使用heapq內置模塊,尋找數組中的第K個最大元素就是一行代碼,heapq中的nlargest接口封裝好了,返回的是一個數組,需要切片取值。
- import heapq
- class Solution:
- def findKthLargest(self, nums: List[int], k: int) -> int:
- return heapq.nlargest(k,nums)[-1]
當然,一般都是手寫堆排序,尋找數組中的第K個最大元素建立最小堆,尋找數組中的第K個最小元素建立最大堆,
思路:「取nums前K個元素建立大小為K的最小堆,后面就是維護一個容量為k的小頂堆,堆中的k個節點代表著當前最大的k個元素,而堆頂顯然是這k個元素中的最小值。」
因此只要遍歷整個數組,當二叉堆大小等于K后,當遇見大于堆頂數值的元素時彈出堆頂,并壓入該元素,持續維護最大的K個元素。遍歷結束后,堆頂元素即為第K個最大元素。時間復雜度。
- class Solution:
- def findKthLargest(self, nums: List[int], k: int) -> int:
- heapsize=len(nums)
- def maxheap(a,i,length):
- l=2*i+1
- r=2*i+2
- large=i
- if l<length and a[l]>a[large]:
- large=l
- if r<length and a[r]>a[large]:
- large=r
- if large!=i:
- a[large],a[i]=a[i],a[large]
- maxheap(a,large,length)
- def buildheap(a,length):
- for i in range(heapsize//2,-1,-1):
- maxheap(a,i,length)
- buildheap(nums,heapsize)
- for i in range(heapsize-1,heapsize-k,-1):
- nums[0],nums[i]=nums[i],nums[0]
- heapsize-=1
- maxheap(nums,0,heapsize)
- return nums[0]
相反如果是求前k個最小,那么就用最大堆,因此面對TopK問題,最完美的解法是堆排序。因此,只有你看到數組的第K個……,馬上就是想到堆排序。
如果在數據規模小、對時間復雜度、空間復雜度要求不高的時候,真沒必要上 “高大上” 的算法,寫一個快排就很完美了。
TopK問題就像搜索引擎每天會接收大量的用戶搜索請求,它會把這些用戶輸入的搜索關鍵詞記錄下來,然后再離線地統計分析,得到最熱門的Top10搜索關鍵詞,啥啥惹事就出來了。
本文已收錄 GitHub https://github.com/MaoliRUNsen/runsenlearnpy100