2020年優秀10款Python工具包,個個都是精品
2020已經過去,在過去的一年里,又有非常多優秀的Python庫涌現出來。
相對于numpy、TensorFlow、pandas這些已經經過多年維護、迭代,對于大多數Python開發者耳熟能詳的庫不同。
今天要給大家介紹的是誕生于2020年的新鮮Python庫,而且,本文介紹的這10個Python庫一直都受到非常好的維護。
廢話不多說,下面開始本文的正式內容!
1. Typer
或許,你并非經常編寫 CLI 應用程序,但是當你編寫時,有可能會遇到很多障礙。
繼FastAPI的巨大成功之后,tiangolo用同樣的原則為我們帶來了Typer[1]:一個新的庫,它能讓你利用Python 3.6+的類型提示功能來編寫命令行接口。
這個設計確實讓Typer脫穎而出。除了確保你的代碼是正確的文檔,你還可以通過小小的改動得到一個帶有驗證的CLI接口。
而且通過使用類型提示,你可以在你的Python編輯器中獲得自動完成(比如VSCode),這將提高你的工作效率。
為了增強它的功能,Typer在另外一款非常知名的CLI工具Click的基礎之上做了很多優化和改善。這意味著它可以利用它的所有優點、社區和插件,同時以較少的模板代碼開始簡單的工作。
2. Rich
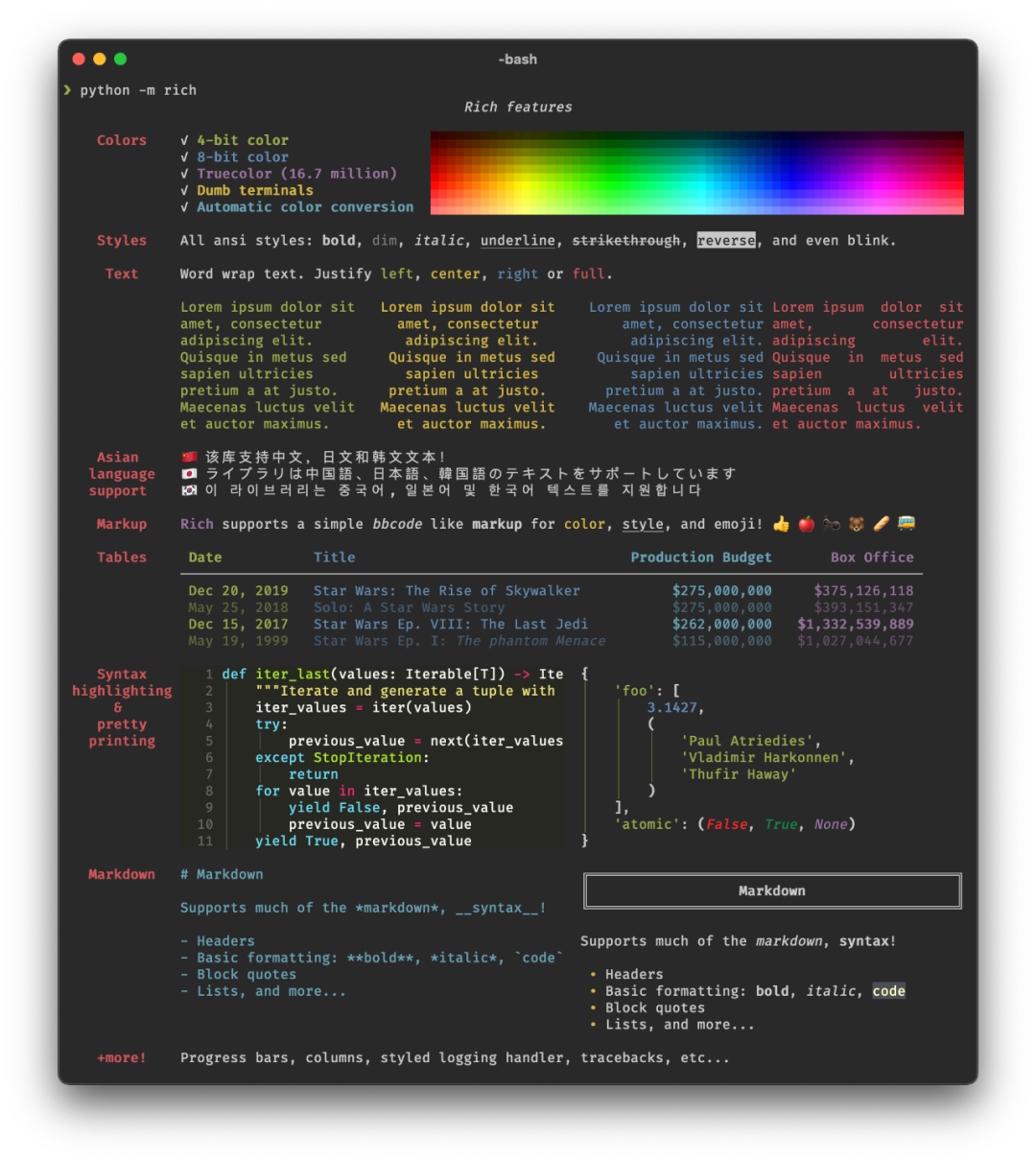
順著CLI的話題,在使用終端時,往往是單調的白色,這非常不利于分辨和閱讀。
你想給你的終端輸出添加色彩和與眾不同的風格嗎?打印復雜的表格?顯示漂亮的進度條?Markdown?Emojis?
Rich[2]都能滿足你的要求。
請看示例截圖,了解一下它的功能。
3. Dear PyGui
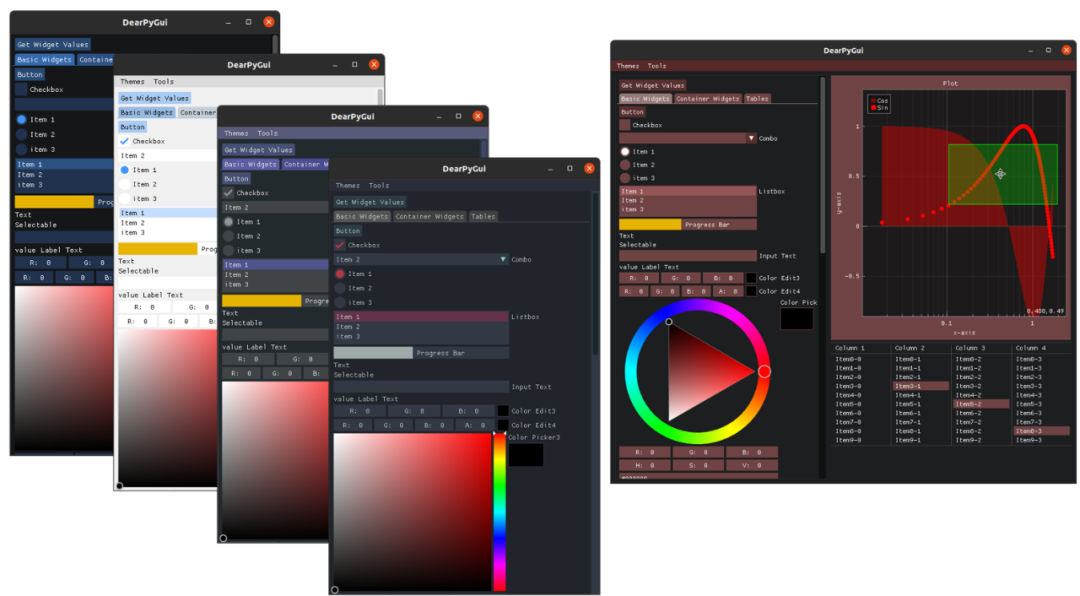
雖然,正如我們所看到的,終端應用可以很好看,但有時這還不夠,你需要一個真正的GUI。
為此,Dear PyGui[3]應運而生,它是流行的Dear ImGui C++項目的Python移植。
Dear PyGui利用了在視頻游戲中流行的所謂即時模式范式。
這意味著動態GUI是一幀一幀獨立繪制的,不需要持久化任何數據。這使得這個工具與其他Python GUI框架有著本質上的區別。
它具有很高的性能,并使用計算機的GPU來促進高動態界面的構建,這在工程、模擬、游戲或數據科學應用中是經常需要的。
4. PrettyErrors
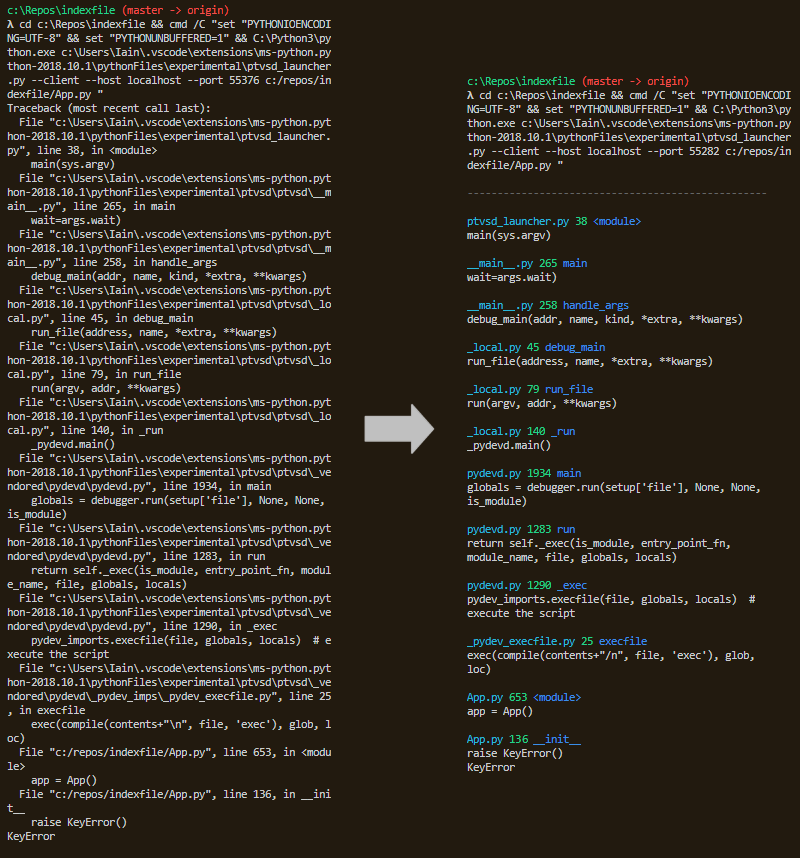
這是一個讓你覺得:"怎么以前沒有人想到它?"的Python庫。
PrettyErrors[4]只做了一件事,而且做得很好。
在支持彩色輸出的終端中,它將混亂的報錯信息轉化為更適合我們人類的眼睛來解析的東西。
不再苦苦掃描整個屏幕,定位報錯信息......現在你可以一目了然地找到它。
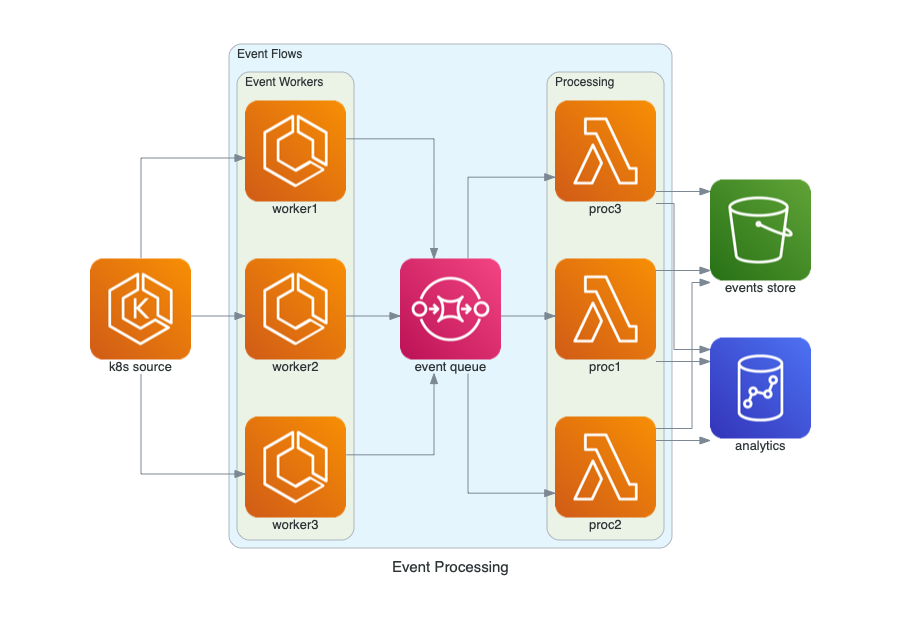
5. Diagrams
我們程序員喜歡解決問題和編碼。
但有時,作為非常需要的項目文檔的一部分,我們需要向其他同事解釋復雜的架構設計。
傳統上,我們已經求助于GUI工具,我們可以在圖表和可視化上下功夫,把它放在演示和文檔中。
但這不是唯一的方式。
Diagrams[5]可以讓你不用任何設計工具,直接在Python代碼中繪制云系統架構。
只需要幾行代碼,就可以繪制一幅亮眼的架構圖。
6. Hydra and OmegaConf
在做機器學習項目的研究和實驗時,總有無數的設置需要嘗試。
在一些應用中,配置管理變得非常復雜。如果有一種結構化的方式來處理這種復雜性,會極大的提高開發效率。
Hydra[6]是一個工具,它允許你以可組合的方式構建配置,并從命令行或配置文件中覆蓋某些部分。
- python train_model.py variation=option_a,option_b
- ├── variation
- │ ├── option_a.yaml
- │ └── option_b.yaml
- ├── base.yaml
- └── train_model.py
另一款工具,OmegaConf[7]為分層配置系統的基礎提供了一致的API,支持YAML、配置文件、對象和CLI參數等不同來源。
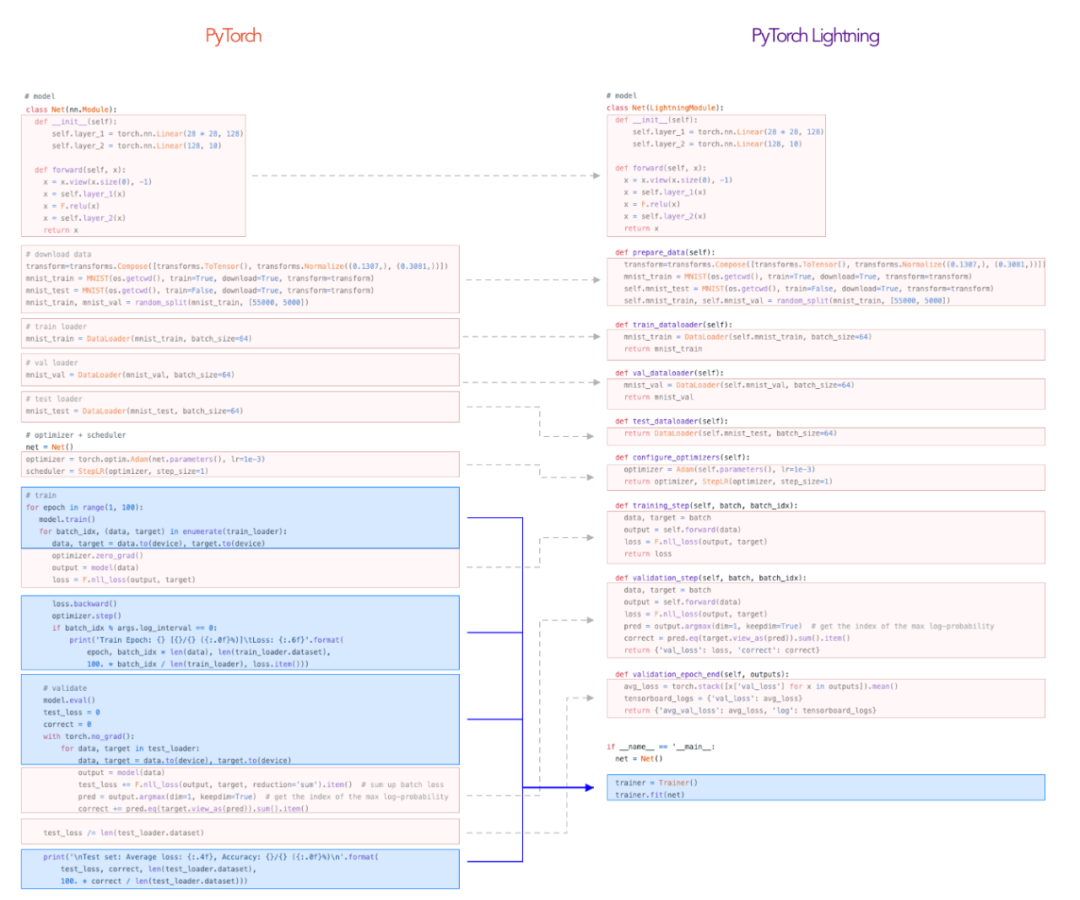
7. PyTorch Lightning
每一個能夠提高數據科學團隊生產力的工具都是價值連城的。
沒有理由讓在數據科學項目中工作的人每次都要重新發明輪子,反復思考如何更好地組織項目中的代碼,使用一些不太好維護的 "PyTorch boilerplate",或者用潛在的控制權換取使用更高級別的抽象。
Lightning[8]通過將科學與工程脫鉤,有助于提高生產力。它有點像TensorFlow的Keras,在某種意義上,它使你的代碼更加簡潔。
然而,它并沒有奪走你的控制權。它仍然是PyTorch,你可以使用所有常用的API。
這個庫可以幫助團隊利用軟件工程的良好實踐,圍繞組件的組織和明確的責任,構建高質量的代碼,可以輕松地擴展到多個GPU、TPU和CPU上進行訓練。
這個庫可以幫助數據科學團隊中那些初級成員產生更好的結果,同時,更有經驗的成員也會喜歡它,因為在不放棄控制權的前提下,提高了整體生產力。
8. Hummingbird
不是所有的機器學習都是深度學習。很多時候,你的模型由scikit-learn中實現的比較傳統的算法組成(比如隨機森林),或者你使用梯度提升方法,比如流行的LightGBM和XGBoost。
然而,在深度學習領域正在發生很多變化。像PyTorch這樣的框架正在以令人窒息的速度前進,硬件設備也在優化,以更快的速度和更低的功耗運行張量計算。如果我們能夠利用這些工作,更快、更高效地運行我們的傳統方法,豈不美哉?
這就是Hummingbird[9]的用武之地。
微軟的這個新庫可以將你訓練好的傳統ML模型編譯成張量計算。
這很好,因為它可以讓你擺脫重新設計模型的需要。
截至目前,Hummingbird支持轉換到PyTorch、TorchScript、ONNX和TVM,以及各種ML模型和矢量器。
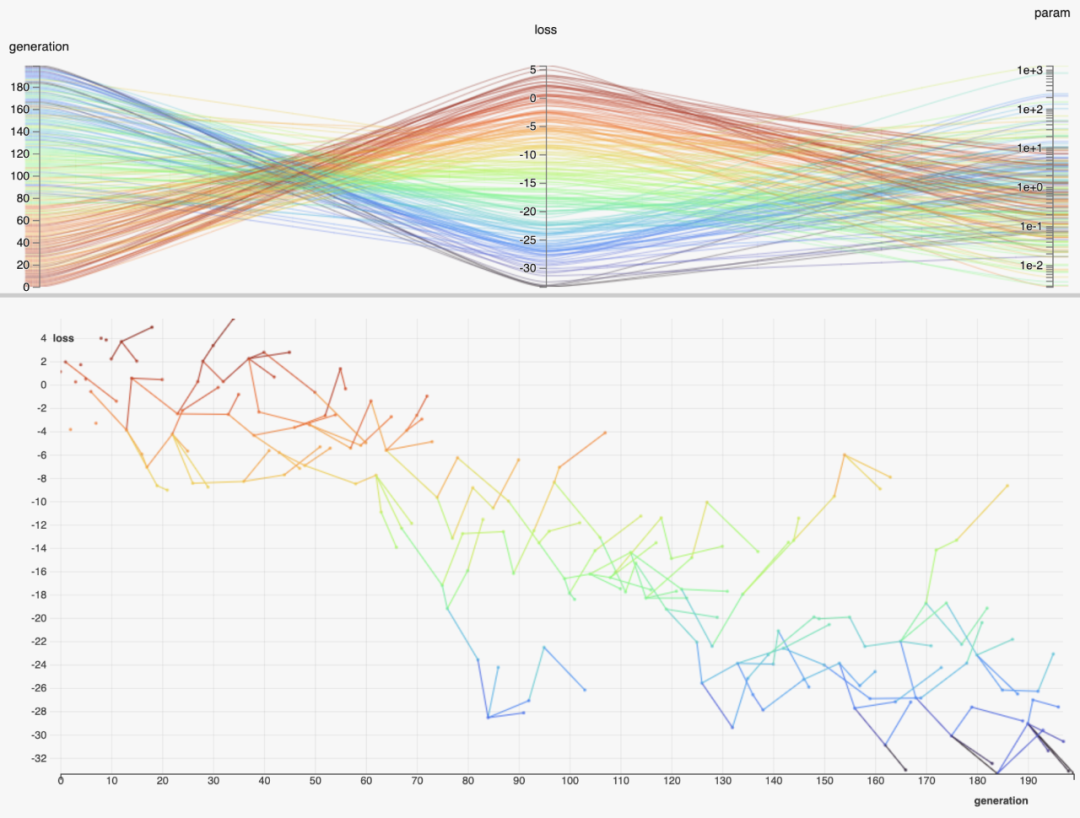
9. HiPlot
幾乎每一位數據科學家在其職業生涯的某個階段都曾處理過高維數據。
不幸的是,人類的大腦并沒有足夠的能力直觀地處理這種數據,所以我們必須借助其他技術。
今年年初,Facebook發布了HiPlot[10],這是一個幫助發現高維數據中的相關性和模式的庫,使用平行圖和其他圖形方式來表示信息。在他們的發布博文中解釋了這個概念,但基本上是一種很好的、方便的可視化和過濾高維數據的方法。
HiPlot是交互式的,可擴展的,你可以從你的標準Jupyter Notebooks或通過它自己的服務器使用它。
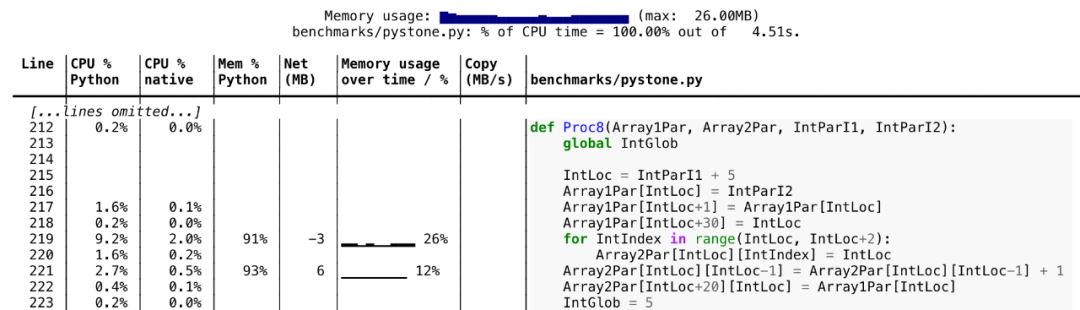
10. Scalene
隨著Python庫的生態系統越來越復雜,我們發現自己編寫了越來越多的依賴于C擴展和多線程代碼的代碼。
在對比性能時,這就成了一個問題,因為CPython內置的剖析工具不能正確處理多線程和本地代碼。
這時,Scalene[11]就來救場了。
Scalene是一個針對Python腳本的CPU和內存剖析工具,它能夠正確處理多線程代碼,并區分運行Python和本地代碼的時間。
你不需要修改你的代碼,你只需要用scalene從命令行運行你的腳本,它就會為你生成一個文本或HTML報告,顯示每行代碼的CPU和內存使用情況。
結語
一款好用的工具,能夠讓開發者事半功倍。
對于Python這種極度依賴第三方工具包的編程語言更是如此。
因為有了這些優秀的工具,才使得Python生態得以完善和狀態。