一文讀懂微內核架構
本文轉載自微信公眾號「 JAVA日知錄」,作者 JAVA日知錄 。轉載本文請聯系 JAVA日知錄公眾號。
什么是微內核架構?
微內核是一種典型的架構模式 ,區別于普通的設計模式,架構模式是一種高層模式,用于描述系統級的結構組成、相互關系及相關約束。微內核架構在開源框架中的應用非常廣泛,比如常見的 ShardingSphere 還有Dubbo都實現了自己的微內核架構。那么,在介紹什么是微內核架構之前,我們有必要先闡述這些開源框架會使用微內核架構的原因。
為什么要使用微內核架構?
微內核架構本質上是為了提高系統的擴展性 。所謂擴展性,是指系統在經歷不可避免的變更時所具有的靈活性,以及針對提供這樣的靈活性所需要付出的成本間的平衡能力。也就是說,當在往系統中添加新業務時,不需要改變原有的各個組件,只需把新業務封閉在一個新的組件中就能完成整體業務的升級,我們認為這樣的系統具有較好的可擴展性。
就架構設計而言,擴展性是軟件設計的永恒話題。而要實現系統擴展性,一種思路是提供可插拔式的機制來應對所發生的變化。當系統中現有的某個組件不滿足要求時,我們可以實現一個新的組件來替換它,而整個過程對于系統的運行而言應該是無感知的,我們也可以根據需要隨時完成這種新舊組件的替換。
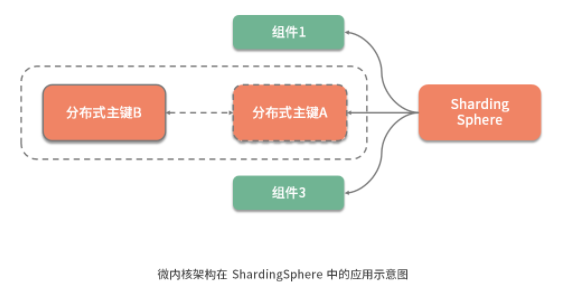
比如在 ShardingSphere 中提供的分布式主鍵功能,分布式主鍵的實現可能有很多種,而擴展性在這個點上的體現就是, 我們可以使用任意一種新的分布式主鍵實現來替換原有的實現,而不需要依賴分布式主鍵的業務代碼做任何的改變 。
微內核架構模式為這種實現擴展性的思路提供了架構設計上的支持,ShardingSphere 基于微內核架構實現了高度的擴展性。在介紹如何實現微內核架構之前,我們先對微內核架構的具體組成結構和基本原理做簡要的闡述。
什么是微內核架構?
從組成結構上講, 微內核架構包含兩部分組件:內核系統和插件 。這里的內核系統通常提供系統運行所需的最小功能集,而插件是獨立的組件,包含自定義的各種業務代碼,用來向內核系統增強或擴展額外的業務能力。在 ShardingSphere 中,前面提到的分布式主鍵就是插件,而 ShardingSphere 的運行時環境構成了內核系統。
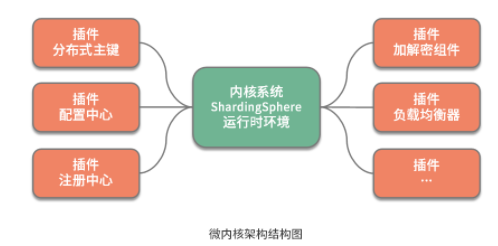
那么這里的插件具體指的是什么呢?這就需要我們明確兩個概念,一個概念就是經常在說的 API ,這是系統對外暴露的接口。而另一個概念就是 SPI(Service Provider Interface,服務提供接口),這是插件自身所具備的擴展點。就兩者的關系而言,API 面向業務開發人員,而 SPI 面向框架開發人員,兩者共同構成了 ShardingSphere 本身。
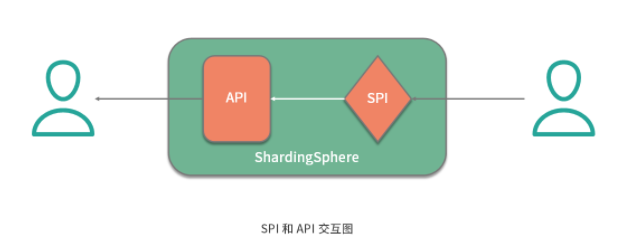
可插拔式的實現機制說起來簡單,做起來卻不容易,我們需要考慮兩方面內容。一方面,我們需要梳理系統的變化并把它們抽象成多個 SPI 擴展點。另一方面, 當我們實現了這些 SPI 擴展點之后,就需要構建一個能夠支持這種可插拔機制的具體實現,從而提供一種 SPI 運行時環境 。
如何實現微內核架構?
事實上,JDK 已經為我們提供了一種微內核架構的實現方式,就是JDK SPI。這種實現方式針對如何設計和實現 SPI 提出了一些開發和配置上的規范,ShardingSphere、Dubbo 使用的就是這種規范,只不過在這基礎上進行了增強和優化。所以要理解如何實現微內核架構,我們不妨先看看JDK SPI 的工作原理。
JDK SPI
SPI(Service Provider Interface)主要是被框架開發人員使用的一種技術。例如,使用 Java 語言訪問數據庫時我們會使用到 java.sql.Driver 接口,不同數據庫產品底層的協議不同,提供的 java.sql.Driver 實現也不同,在開發 java.sql.Driver 接口時,開發人員并不清楚用戶最終會使用哪個數據庫,在這種情況下就可以使用 Java SPI 機制在實際運行過程中,為 java.sql.Driver 接口尋找具體的實現。
下面我們通過一個簡單的示例演示一下JDK SPI的使用方式:
首先我們定義一個生成id鍵的接口,用來模擬id生成
- public interface IdGenerator {
- /**
- * 生成id
- * @return
- */
- String generateId();
- }
然后創建兩個接口實現類,分別用來模擬uuid和序列id的生成
- public class UuidGenerator implements IdGenerator {
- @Override
- public String generateId() {
- return UUID.randomUUID().toString();
- }
- }
- public class SequenceIdGenerator implements IdGenerator {
- private final AtomicLong atomicId = new AtomicLong(100L);
- @Override
- public String generateId() {
- long leastId = this.atomicId.incrementAndGet();
- return String.valueOf(leastId);
- }
- }
在項目的resources/META-INF/services 目錄下添加一個名為com.github.jianzh5.spi.IdGenerator的文件,這是 JDK SPI 需要讀取的配置文件,內容如下:
- com.github.jianzh5.spi.impl.UuidGenerator
- com.github.jianzh5.spi.impl.SequenceIdGenerator
創建main方法,讓其加載上述的配置文件,創建全部IdGenerator 接口實現的實例,并執行生成id的方法。
- public class GeneratorMain {
- public static void main(String[] args) {
- ServiceLoader<IdGenerator> serviceLoader = ServiceLoader.load(IdGenerator.class);
- Iterator<IdGenerator> iterator = serviceLoader.iterator();
- while(iterator.hasNext()){
- IdGenerator generator = iterator.next();
- String id = generator.generateId();
- System.out.println(generator.getClass().getName() + " >>id:" + id);
- }
- }
- }
執行結果如下:

JDK SPI 源碼分析
通過上述示例,我們可以看到 JDK SPI 的入口方法是 ServiceLoader.load() 方法,在這個方法中首先會嘗試獲取當前使用的 ClassLoader,然后調用 reload() 方法,調用關系如下圖所示:

調用關系
在 reload() 方法中,首先會清理 providers 緩存(LinkedHashMap 類型的集合),該緩存用來記錄 ServiceLoader 創建的實現對象,其中 Key 為實現類的完整類名,Value 為實現類的對象。之后創建 LazyIterator 迭代器,用于讀取 SPI 配置文件并實例化實現類對象。
- public void reload() {
- providers.clear();
- lookupIterator = new LazyIterator(service, loader);
- }
在前面的示例中,main() 方法中使用的迭代器底層就是調用了 ServiceLoader.LazyIterator 實現的。Iterator 接口有兩個關鍵方法:hasNext() 方法和 next() 方法。這里的 LazyIterator 中的 next() 方法最終調用的是其 nextService() 方法,hasNext() 方法最終調用的是 hasNextService() 方法,我們來看看 hasNextService()方法的具體實現:
- private static final String PREFIX = "META-INF/services/";
- Enumeration<URL> configs = null;
- Iterator<String> pending = null;
- String nextName = null;
- private boolean hasNextService() {
- if (nextName != null) {
- return true;
- }
- if (configs == null) {
- try {
- //META-INF/services/com.github.jianzh5.spi.IdGenerator
- String fullName = PREFIX + service.getName();
- if (loader == null)
- configs = ClassLoader.getSystemResources(fullName);
- else
- configs = loader.getResources(fullName);
- } catch (IOException x) {
- fail(service, "Error locating configuration files", x);
- }
- }
- // 按行SPI遍歷配置文件的內容
- while ((pending == null) || !pending.hasNext()) {
- if (!configs.hasMoreElements()) {
- return false;
- }
- // 解析配置文件
- pending = parse(service, configs.nextElement());
- }
- // 更新 nextName字段
- nextName = pending.next();
- return true;
- }
在 hasNextService() 方法中完成 SPI 配置文件的解析之后,再來看 LazyIterator.nextService() 方法,該方法「負責實例化 hasNextService() 方法讀取到的實現類」,其中會將實例化的對象放到 providers 集合中緩存起來,核心實現如下所示:
- private S nextService() {
- String cn = nextName;
- nextName = null;
- // 加載 nextName字段指定的類
- Class<?> c = Class.forName(cn, false, loader);
- if (!service.isAssignableFrom(c)) { // 檢測類型
- fail(service, "Provider " + cn + " not a subtype");
- }
- S p = service.cast(c.newInstance()); // 創建實現類的對象
- providers.put(cn, p); // 將實現類名稱以及相應實例對象添加到緩存
- return p;
- }
以上就是在 main() 方法中使用的迭代器的底層實現。最后,我們再來看一下 main() 方法中使用 ServiceLoader.iterator() 方法拿到的迭代器是如何實現的,這個迭代器是依賴 LazyIterator 實現的一個匿名內部類,核心實現如下:
- public Iterator<S> iterator() {
- return new Iterator<S>() {
- // knownProviders用來迭代providers緩存
- Iterator<Map.Entry<String,S>> knownProviders
- = providers.entrySet().iterator();
- public boolean hasNext() {
- // 先走查詢緩存,緩存查詢失敗,再通過LazyIterator加載
- if (knownProviders.hasNext())
- return true;
- return lookupIterator.hasNext();
- }
- public S next() {
- // 先走查詢緩存,緩存查詢失敗,再通過 LazyIterator加載
- if (knownProviders.hasNext())
- return knownProviders.next().getValue();
- return lookupIterator.next();
- }
- // 省略remove()方法
- };
- }
JDK SPI 在 JDBC 中的應用
了解了 JDK SPI 實現的原理之后,我們再來看實踐中 JDBC 是如何使用 JDK SPI 機制加載不同數據庫廠商的實現類。
JDK 中只定義了一個 java.sql.Driver 接口,具體的實現是由不同數據庫廠商來提供的。這里我們就以 MySQL 提供的 JDBC 實現包為例進行分析。
在 mysql-connector-java-*.jar 包中的 META-INF/services 目錄下,有一個 java.sql.Driver 文件中只有一行內容,如下所示:
- com.mysql.cj.jdbc.Driver
在使用 mysql-connector-java-*.jar 包連接 MySQL 數據庫的時候,我們會用到如下語句創建數據庫連接:
- String url = "jdbc:xxx://xxx:xxx/xxx";
- Connection conn = DriverManager.getConnection(url, username, pwd);
「DriverManager 是 JDK 提供的數據庫驅動管理器」,其中的代碼片段,如下所示:
- static {
- loadInitialDrivers();
- println("JDBC DriverManager initialized");
- }
在調用 getConnection() 方法的時候,DriverManager 類會被 Java 虛擬機加載、解析并觸發 static 代碼塊的執行;在 loadInitialDrivers()方法中通過 JDK SPI 掃描 Classpath 下 java.sql.Driver 接口實現類并實例化,核心實現如下所示:
- private static void loadInitialDrivers() {
- String drivers = System.getProperty("jdbc.drivers")
- // 使用 JDK SPI機制加載所有 java.sql.Driver實現類
- ServiceLoader<Driver> loadedDrivers =
- ServiceLoader.load(Driver.class);
- Iterator<Driver> driversIterator = loadedDrivers.iterator();
- while(driversIterator.hasNext()) {
- driversIterator.next();
- }
- String[] driversList = drivers.split(":");
- for (String aDriver : driversList) { // 初始化Driver實現類
- Class.forName(aDriver, true,
- ClassLoader.getSystemClassLoader());
- }
- }
在 MySQL 提供的 com.mysql.cj.jdbc.Driver 實現類中,同樣有一段 static 靜態代碼塊,這段代碼會創建一個 com.mysql.cj.jdbc.Driver 對象并注冊到 DriverManager.registeredDrivers 集合中(CopyOnWriteArrayList 類型),如下所示:
- static {
- java.sql.DriverManager.registerDriver(new Driver());
- }
在 getConnection() 方法中,DriverManager 從該 registeredDrivers 集合中獲取對應的 Driver 對象創建 Connection,核心實現如下所示:
- private static Connection getConnection(String url, java.util.Properties info, Class<?> caller) throws SQLException {
- // 省略 try/catch代碼塊以及權限處理邏輯
- for(DriverInfo aDriver : registeredDrivers) {
- Connection con = aDriver.driver.connect(url, info);
- return con;
- }
- }
小結
本文我們詳細講述了微內核架構的一些基本概念并通過一個示例入手,介紹了 JDK 提供的 SPI 機制的基本使用,然后深入分析了 JDK SPI 的核心原理和底層實現,對其源碼進行了深入剖析,最后我們以 MySQL 提供的 JDBC 實現為例,分析了 JDK SPI 在實踐中的使用方式。
掌握了JDK的SPI機制就等于掌握了微內核架構的核心,以上,希望對你有所幫助!