你想成為數據科學家嗎?不要把機器學習當成入門第一課
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
很多人在聽到“數據科學”一詞時,首先想到的就是“機器學習”。我也一樣,在首次接觸到機器學習這個聽起來十分炫酷的概念時,對數據科學產生了濃厚興趣。所以當我尋找學習數據科學的切入點時,也受其影響。
這是我犯過的最大錯誤,也是本文重點:如果想要成為一名數據科學家,請不要從機器學習開始。
顯然,要成為一名“真正全能”的數據科學家,最終必須掌握機器學習的概念。但你會驚訝于沒有它你能走多遠。為什么不從機器學習開始呢?
1.機器學習僅是數據科學的一小部分。
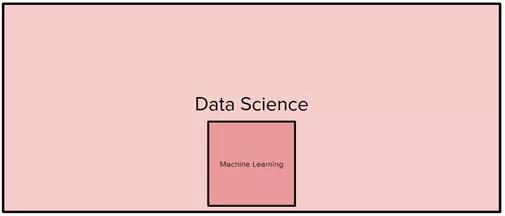
數據科學和機器學習就像是圖中所示的矩形和正方形。機器學習是數據科學的一部分,但數據科學并不一定是機器學習,就像正方形是一種矩形,但矩形不一定是正方形一樣。事實上,機器學習建模僅占數據科學家工作的5-10%,其余大部分時間基本投入在其他地方。
如果一開始便投身于機器學習,你將付出大量的時間和精力,卻收獲甚微。
2.若想全面理解機器學習,首先需要掌握其他幾門學科的基礎知識。
機器學習的核心是建立在統計、數學和概率的基礎上。在學習機器學習之前,必須先掌握基本理論知識,夯實理論基礎。例如:
- 線性回歸是大部分訓練營教授的第一個“機器學習算法”,但它實際上是統計方法。
- 進行主成分分析的前提是,學習矩陣和特征向量(線性代數)理念。
- 樸素貝葉斯是完全基于貝葉斯定理(概率)的機器學習模型。
因此,將上述內容歸結為兩點:一是學習基礎知識會使學習更高級的內容變得更加輕松容易;二是通過學習基礎知識,可掌握多個機器學習概念。
3. 機器學習并不能解決一切。
許多數據科學家都糾結于此,甚至包括我自己。和我最初的想法一致,大部分數據科學家認為“數據科學”和“機器學習”相輔相成,不可分割。因此,每每遇到問題,數據科學家都首先考慮以機器學習模型作為解決方案。但并非解決所有數據科學問題都需要機器學習模型。
在某些情況下,采用Excel或Pandas進行簡單的分析就足以解決當前問題。
在其他情況下,某個問題或許與機器學習完全無關。可能僅需要使用腳本清理和操縱數據、構建數據管道或創建交互式儀表板即可解決,這些問題都無需機器學習。
你應該如何做?
正如上文所述,學習基礎知識會讓學習更高級的內容變得更加輕松容易,并掌握多個機器學習概念。我知道,如果你正在學習統計學、數學或編程基礎知識,你可能會感覺自己在成為一名“數據科學家”的道路上,并未取得進步,但學習這些基礎知識定會對你未來的學習大有裨益。
若想從現在開始一些切實具體的行動,可以參考以下步驟:
- 從統計入手。在數學、統計學和編程基礎這三個組成部分中,個人認為統計是最重要的一環。如果你害怕學習統計,那么數據科學可能并不適合你。推薦觀看佐治亞理工學院的課程《統計方法》(Statistical Methods),或者可汗學院的視頻系列(Khan Academy’s videoseries)。
- 學習Python和SQL。我個人工作中從未使用過R語言,所以對R沒有太多意見。如果你是一個R型人才,推薦嘗試Python和SQL。使用Python和SQL的能力越強,在數據收集、操縱和實現方面就會越容易。
除此之外,熟悉Pandas、NumPy和Scijit-learn等Python庫也是一個不錯的選擇。而由于二叉樹是許多高級機器學習算法(如XGBoost)的基礎,所以也推薦大家學習。
- 學習線性代數基礎。處理任何與矩陣相關的事情時,線性代數就變得極其重要。這一點在推薦系統和深度學習應用中十分常見。
- 學習數據操縱。數據操縱至少占數據科學家工作的50%。更具體地說,學習更多關于特征工程、探索性數據分析和數據準備的知識。
我的總體建議是,由于機器學習一沒有充分利用時間,二無助于你成為工作中卓有成就的數據科學家,因此,以機器學習為學習重點并不可取。不過要注意的是,這是一篇個人觀點十分強烈的文章,所以,取你所想,取你所益。