如何成為一名更有“市場”的數據科學家?
這個標題可能有點奇怪,畢竟在2019年,數據科學家本身就已經是一個非常有市場的職業了。由于數據科學對當今的業務產生了巨大影響,因此對數據科學專家的需求正在增長。截至本文發布之前,僅LinkedIn就有144,527個數據科學工作。
但是,更重要的是要密切關注行業脈搏,了解最快、最有效的數據科學解決方案。為了幫助大家,癡迷于數據的CV Compiler團隊分析了一些職位空缺數量并確定了2019年數據科學領域的就業趨勢。
2019年更受歡迎的數據科學技能
下圖顯示了2019年雇主需要數據科學工程師能夠掌握的技能:
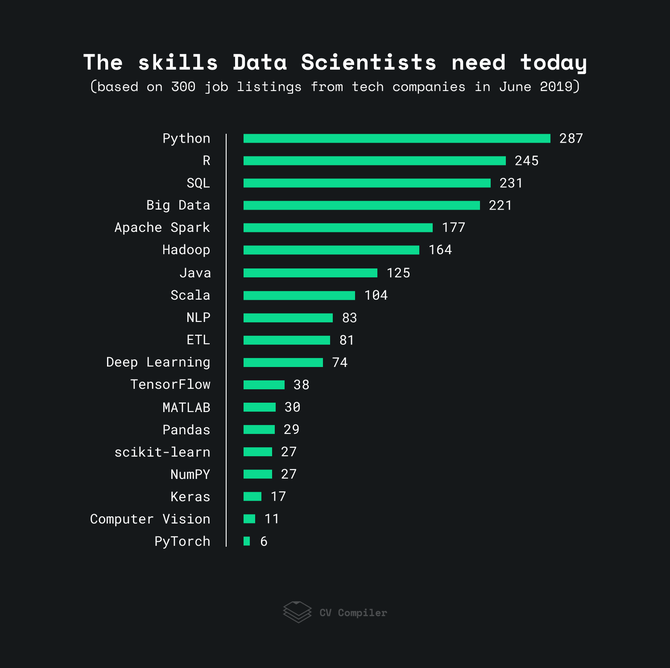
在此分析中,該團隊查看了來自StackOverflow,AngelList和類似網站的300個Data Science職位空缺。某些條款可能在一個職位列表中重復多次。
注意: 這項研究代表了雇主的偏好,而不是數據科學工程師自己。
關鍵要點和數據科學趨勢
顯然,數據科學更多地是在于基礎知識而不是框架和庫,但仍有一些趨勢和技術值得注意。
大數據
根據 2018年大數據分析市場研究,企業的大數據采用率從2015年的17%飆升至2018年的59%。因此,大數據工具的普及也在增長。如果不考慮Apache Spark和Hadoop的話,最受歡迎的是 MapReduce (36)和 Redshift (29)。
Hadoop
盡管Spark和云存儲很受歡迎, 但Hadoop的時代還沒有結束。因此,一些雇主仍然希望候選人熟悉 Apache Pig(30),HBase(32)和類似技術。 HDFS (20)也在調查中被提及。
實時數據處理
隨著各種傳感器、移動設備和物聯網(18)的應用越來越多 ,越來越多的企業的目標是從實時數據處理中獲得更多的見解。因此,像Apache Flink (21)這樣的流分析平臺在一些雇主中很受歡迎。
Pexels 上的 rawpixel.com 拍攝的照片
特征工程和超參數調整
準備數據和選擇模型參數是任何數據科學家工作的關鍵部分。數據挖掘(128)這一術語在雇主中頗為流行。一些雇主也非常重視超參數調整(21)。但是作為數據科學家,您首先需要關注特征工程。為模型選擇最佳功能至關重要,因為它們決定了模型在其創建的最早階段的成功。
數據可視化
處理數據并從中提取有價值的見解的能力至關重要。不過,數據可視化(55)對于任何數據科學家而言也同樣重要。其核心目的是,您可以以任何團隊成員或客戶都能理解的格式展示您的工作成果。至于數據可視化工具,雇主更喜歡Tableau(54)。
一般趨勢
在該項調查中,AWS(86)、Docker(36)和Kubernetes(24)這樣的術語也多此出現 。因此,軟件開發行業的一般趨勢也適用于數據科學領域。
數據科學是一個快速發展和復雜的行業,其中一般知識以及特定技術的經驗都很重要。希望這篇文章可以幫助您獲得有關2019年所需的數據科學技能的寶貴見解。