Python遷移學習:機器學習算法
機器學習是人工智能中一個流行的子領域,其涉及的領域非常廣泛。流行的原因之一是在其策略下有一個由復雜的算法、技術和方法論組成的綜合工具箱。該工具箱已經經過了多年的開發和改進,同時新的工具箱也在持續不斷地被研究出來。為了更好地使用機器學習工具箱,我們需要先了解以下幾種機器學習的分類方式。
基于是否有人工進行監督的分類如下。
- 監督學習。這一類別高度依賴人工監督。監督學習類別下的算法從訓練數據和對應的輸出中學習兩個變量之間的映射,并將該映射運用于從未見過的數據。分類任務和回歸任務是監督學習算法的兩種主要任務類型。
- 無監督學習。這類算法試圖從沒有任何(在人工監督之下)關聯輸出或標記的輸入數據中學習內在的潛在結構、模式和關系。聚類、降維、關聯規則挖掘等任務是無監督學習算法的幾種主要任務類型。
- 半監督學習。這類算法是監督學習算法和無監督學習算法的混合。這一類別下的算法使用少量的標記訓練數據和更多的非標記訓練數據,因此需要創造性地使用監督學習方法和無監督學習方法來解決特定問題。
- 強化學習。這類算法與監督學習和無監督學習算法略有不同。強化學習算法的中心實體是一個代理,它在訓練期間會同環境進行交互讓獎勵最大化。代理會迭代地進行學習,并基于和環境的交互中獲得的獎勵或懲罰來調整其策略。
基于數據可用性的分類如下。
- 批量學習。也被稱為離線學習,當所需的訓練數據可用時可以使用這類算法,同時這種算法也可以在部署到生產環境或現實世界之前對模型進行訓練和微調。
- 在線學習。顧名思義,在這類算法中只要數據可用,學習就不會停止。另外,在這類算法中,數據會被小批量地輸入系統,而下一次訓練將會使用新批次中的數據。
前面討論的分類方法讓我們對關于如何組織、理解和利用機器學習算法有了一個抽象的理解。機器學習算法最常見的分類方法為監督學習算法和無監督學習算法。下面讓我們更詳細地討論這兩個類別,因為這將有助于我們開啟后面將要介紹的更高級的主題。
1.2.1 監督學習
監督學習算法是一類使用數據樣本(也稱為訓練樣本)和對應輸出(或標簽)來推斷兩者之間映射函數的算法。推斷映射函數或學習函數是這個訓練過程的輸出。學習函數能正確地映射新的和從未見過的數據點(即輸入元素),以測試自身的性能。
監督學習算法中的幾個關鍵概念的介紹如下。
- 訓練數據集。訓練過程中使用的訓練樣本和對應的輸出稱為訓練數據。在形式上,一個訓練數據集是由一個輸入元素(通常是一個向量)和對應的輸出元素或信號組成的二元元組。
- 測試數據集。用來測試學習函數性能的從未見過的數據集。該數據集也是一個包含輸入數據點和對應輸出信號的二元元組。在訓練階段不使用該集合中的數據點(該數據集也會進一步劃分為驗證集,我們將在后續章節中詳細討論)。
- 學習函數。這是訓練階段的輸出,也稱為推斷函數或模型。該函數基于訓練數據集中的訓練實例(輸入數據點及其對應的輸出)被推斷出。一個理想的模型或學習函數學到的映射也能推廣到從未見過的數據。
可用的監督學習算法有很多。根據使用需求,它們主要被劃分為分類模型和回歸模型。
1.分類模型
用最簡單的話來說,分類算法能幫助我們回答客觀問題或是非預測。例如這些算法在一些場景中很有用,如“今天會下雨嗎?”或者“這個腫瘤可能癌變嗎?”等。
從形式上來說,分類算法的關鍵目標是基于輸入數據點預測本質分類的輸出標簽。輸出標簽在本質上都是類別,也就是說,它們都屬于一個離散類或類別范疇。
邏輯回歸、支持向量機(Support Vector Machine,SVM)、神經網絡、隨機森林、K-近鄰算法(K-Nearest Neighbour,KNN)、決策樹等算法都是流行的分類算法。
假設我們有一個真實世界的用例來評估不同的汽車模型。為了簡單起見,我們假設模型被期望基于多個輸入訓練樣本預測每個汽車模型的輸出是可接受的還是不可接受的。輸入訓練樣本的屬性包括購買價格、門數、容量(以人數為單位)和安全級別。
除了類標簽以外,每一層的其他屬性都會用于表示每個數據點是否可接受。圖1.3所示描述了目前的二元分類問題。分類算法以訓練樣本為輸入來生成一個監督模型,然后利用該模型為一個新的數據點預測評估標簽。
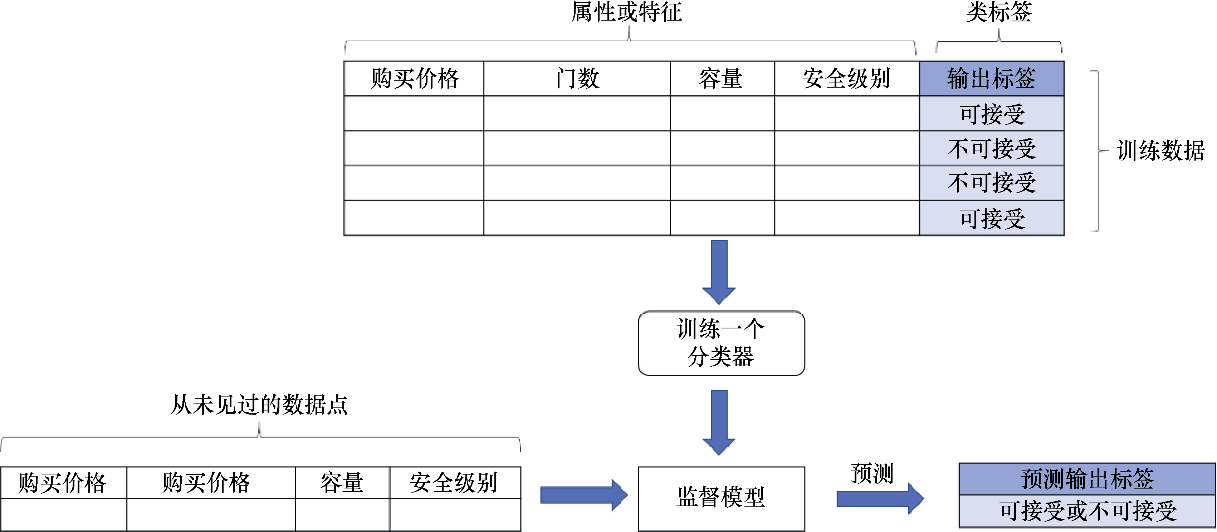
圖1.3
在分類問題中,由于輸出標簽是離散類,因此如果只有兩個可能的輸出類,任務則被稱為二元分類問題,否則被稱為多類分類問題。例如預測明天是否下雨是一個二元分類問題(其輸出為是或否);從掃描的手寫圖像中預測一個數字則是一個包含10個標簽(可能的輸出標簽為0~9)的多類分類問題。
2.回歸模型
這類監督學習算法能幫助我們回答“數量是多少”這樣的量化問題。從形式上來說,回歸模型的關鍵目標是估值。在這類問題中,輸出標簽本質上是連續值(而不是分類問題中的離散輸出)。
在回歸問題中,輸入數據點被稱為自變量或解釋變量,而輸出被稱為因變量。回歸模型還會使用由輸入(或自變量)數據點和輸出(或因變量)信號組成的訓練數據樣本進行訓練。線性回歸、多元回歸、回歸樹等算法都是監督回歸算法。
回歸模型可以基于其對因變量和自變量之間關系的模型進一步分類。
簡單線性回歸模型適用于包含單個自變量和單個因變量的問題。普通最小二乘(Ordinary Least Square,OLS)回歸是一種流行的線性回歸模型。多元回歸或多變量回歸是指只有一個因變量,而每個觀測值是由多個解釋變量組成的向量的問題。
多項式回歸模型是多元回歸的一種特殊形式。該模型使用自變量的n次方對因變量進行建模。由于多項式回歸模型能擬合或映射因變量和自變量之間的非線性關系,因此這類模型也被稱為非線性回歸模型。
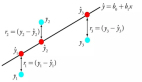
圖1.4所示是一個線性回歸的例子。
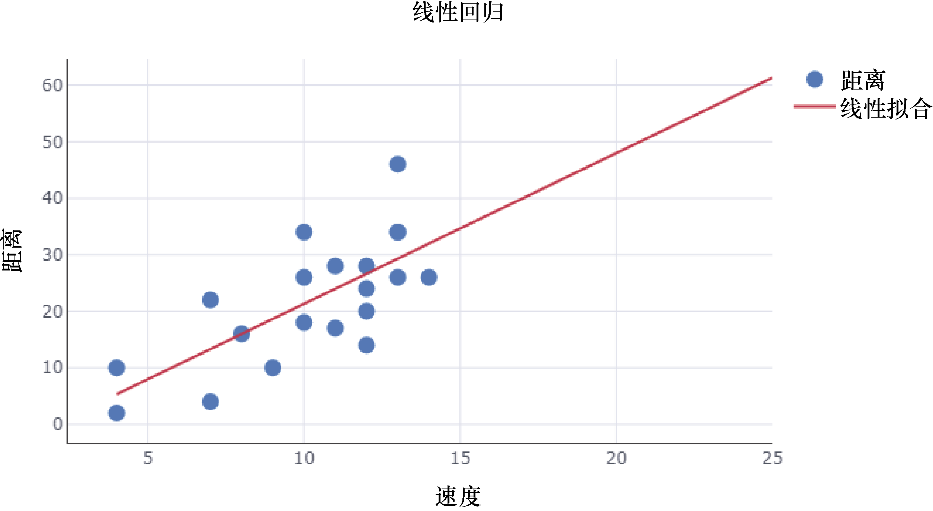
圖1.4
為了理解不同的回歸類型,我們可以考慮一個現實世界中根據車速估計汽車的行車距離(單位省略)的用例。在這個問題中,基于已有的訓練數據,我們可以將距離建模為汽車速度(單位省略)的線性函數,或汽車速度的多項式函數。記住,主要目標是在不過擬合訓練數據本身的前提下將誤差最小化。
前面的圖1.4描述了一個線性擬合模型,而圖1.5所示描述了使用同一數據集的多項式擬合模型。
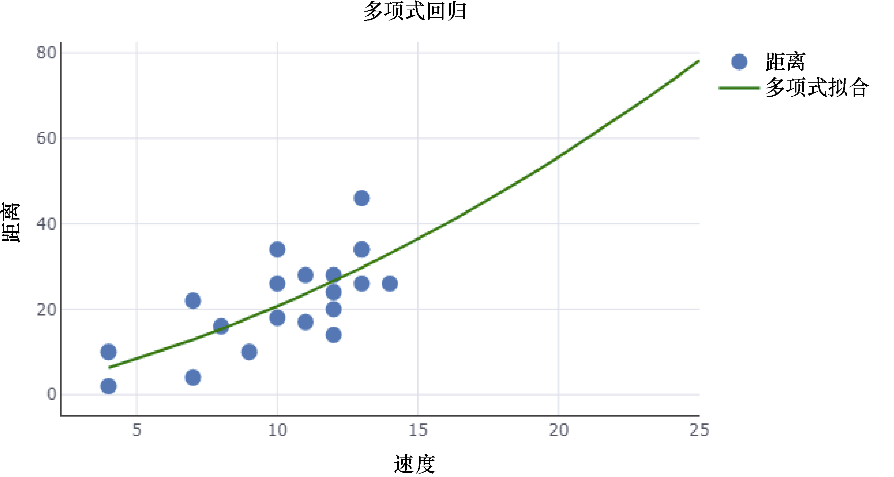
圖1.5
1.2.2 無監督學習
顧名思義,無監督學習算法是在沒有監督的情況下對概念進行學習或推斷。監督學習算法基于輸入數據點和輸出信號組成的訓練數據集來推斷映射函數,而無監督學習算法的任務是在沒有任何輸出信號的訓練數據集中找出訓練數據中的模式和關系。這類算法利用輸入數據集來檢測模式,挖掘規則或將數據點進行分組/聚類,從而從原始輸入數據集中提取出有意義的見解。
當我們沒有包含相應輸出信號或標簽的訓練集時,無監督學習算法就能派上用場。在許多現實場景中,數據集在沒有輸出信號的情況下是可用的,并且很難手動對其進行標記。因此無監督學習算法有助于填補這些空缺。
與監督學習算法類似,為了便于理解和學習,無監督學習算法也可以進行分類。下面是不同類別的無監督學習算法。
1.聚類
分類問題的無監督學習算法稱為聚類。這些算法能夠幫助我們將數據點聚類或分組到不同的組或類別中,而不需要在輸入或訓練數據集中包含任何輸出標簽。這些算法會嘗試從輸入數據集中找到模式和關系,利用固有特征基于某種相似性度量將它們分組。
一個有助于理解聚類的現實世界的例子是新聞文章。每天有數百篇新聞報道被創作出來,每一篇都針對不同的話題,如政治、體育和娛樂等。聚類是一種可以將這些文章進行分組的無監督方法,如圖1.6所示。
執行聚類過程的方法有多種,其中最受歡迎的方法包括以下幾種。
- 基于重心的方法。例如流行的K-均值算法和K-中心點算法。
- 聚合和分裂層次聚類法。例如流行的沃德算法和仿射傳播算法。
- 基于數據分布的方法。例如高斯混合模型。
- 基于密度的方法。例如具有噪聲的基于密度的基類方法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)等。
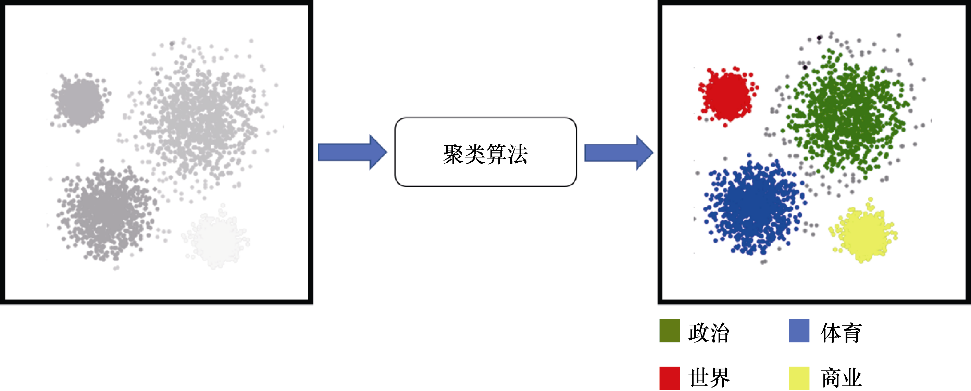
圖1.6
2.降維
數據和機器學習是最好的朋友,但是更多、更大的數據會帶來許多問題。大量的屬性或膨脹的特征空間是常見的問題。一個大型特征空間在帶來數據分析和可視化方面的問題的同時,也帶來了與訓練、內存和空間約束相關的問題。這種現象被稱為維度詛咒。由于無監督方法能夠幫助我們從未標記的訓練數據集中提取見解和模式,因此這些方法在幫助我們減少維度方面很有用。
換句話說,無監督方法能夠幫助我們從完整的可用列表中選擇一組具有代表性的特征,從而幫助我們減少特征空間,如圖1.7所示。
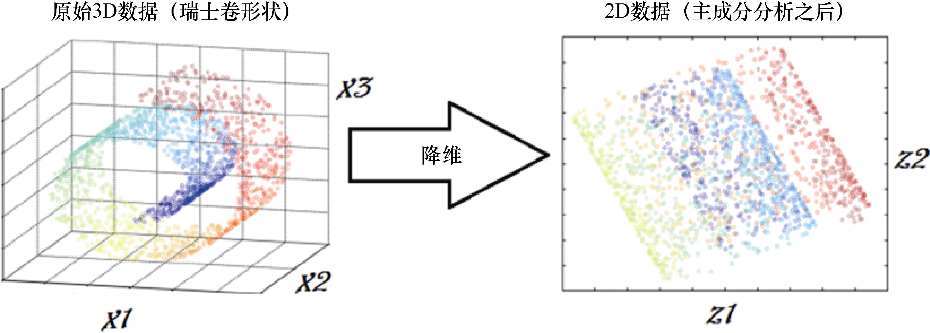
圖1.7
主成分分析(Principal Component Analysis,PCA)、最近鄰分析和判別分析是常用的降維技術。
圖1.7所示是基于PCA的降維技術的工作原理的著名描述圖片。圖片左側展示了一組在三維空間中能表示為瑞士卷形狀的數據,圖片右側則展示了應用PCA將數據轉換到二維空間中的結果。
3.關聯規則挖掘
這類無監督機器學習算法能夠幫助我們理解和從交易數據集中提取模式。這些算法被稱為市場籃子分析(Market Basket Analysis,MBA),可以幫助我們識別交易項目之間有趣的關系。
使用關聯規則挖掘,我們可以回答“在特定的商店中哪些商品會被一起購買?”或者“買葡萄酒的人也會買奶酪嗎?”等問題。FP-growth、ECLAT和Apriori是關聯規則挖掘任務的一些廣泛使用的算法。
4.異常檢測
異常檢測是基于歷史數據識別罕見事件或觀測的任務,也稱為離群點檢測。異常值或離群值通常具有不頻繁出現或在短時間內突然爆發的特征。
對于這類任務,我們為算法提供了一個歷史數據集,因此它能夠以無監督學習的方式識別和學習數據的正常行為。一旦學習完成之后,算法將幫助我們識別不同于之前學習行為的模式。