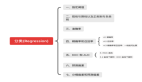
機(jī)器學(xué)習(xí)常見(jiàn)算法分類(lèi)匯總大全
- 1. 學(xué)習(xí)方式
- 1.1 監(jiān)督式學(xué)習(xí)
- 1.2 非監(jiān)督式學(xué)習(xí)
- 1.3 半監(jiān)督式學(xué)習(xí)
- 1.4 強(qiáng)化學(xué)習(xí)
- 2. 算法分類(lèi)
- 2.1 回歸算法
- 2.2 基于實(shí)例的算法
- 2.3 正則化方法
- 2.4 決策樹(shù)學(xué)習(xí)
- 2.5 貝葉斯方法
- 2.6 基于核的算法
- 2.7 聚類(lèi)算法
- 2.8 關(guān)聯(lián)規(guī)則學(xué)習(xí)
- 2.9 遺傳算法(genetic algorithm)
- 2.10 人工神經(jīng)網(wǎng)絡(luò)
- 2.11 深度學(xué)習(xí)
- 2.12 降低維度算法
- 2.13 集成算法

聲明:本篇博文根據(jù)http://www.ctocio.com/hotnews/15919.html整理,原作者張萌,尊重原創(chuàng)。
機(jī)器學(xué)習(xí)無(wú)疑是當(dāng)前數(shù)據(jù)分析領(lǐng)域的一個(gè)熱點(diǎn)內(nèi)容。很多人在平時(shí)的工作中都或多或少會(huì)用到機(jī)器學(xué)習(xí)的算法。本文為您總結(jié)一下常見(jiàn)的機(jī)器學(xué)習(xí)算法,以供您在工作和學(xué)習(xí)中參考。
機(jī)器學(xué)習(xí)的算法很多。很多時(shí)候困惑人們都是,很多算法是一類(lèi)算法,而有些算法又是從其他算法中延伸出來(lái)的。這里,我們從兩個(gè)方面來(lái)給大家介紹,第一個(gè)方面是學(xué)習(xí)的方式,第二個(gè)方面是算法的分類(lèi)。
博主在原創(chuàng)基礎(chǔ)上加入了遺傳算法(2.9)的介紹,這樣一來(lái),本篇博文所包含的機(jī)器學(xué)習(xí)算法更加全面豐富。該博文屬于總結(jié)型文章,如想具體理解每一個(gè)算法的具體實(shí)現(xiàn)方法,還得針對(duì)逐個(gè)算法進(jìn)行學(xué)習(xí)和推敲。
1. 學(xué)習(xí)方式
根據(jù)數(shù)據(jù)類(lèi)型的不同,對(duì)一個(gè)問(wèn)題的建模有不同的方式。在機(jī)器學(xué)習(xí)或者人工智能領(lǐng)域,人們首先會(huì)考慮算法的學(xué)習(xí)方式。在機(jī)器學(xué)習(xí)領(lǐng)域,有幾種主要的學(xué)習(xí)方式。將算法按照學(xué)習(xí)方式分類(lèi)是一個(gè)不錯(cuò)的想法,這樣可以讓人們?cè)诮:退惴ㄟx擇的時(shí)候考慮能根據(jù)輸入數(shù)據(jù)來(lái)選擇最合適的算法來(lái)獲得好的結(jié)果。
1.1 監(jiān)督式學(xué)習(xí)
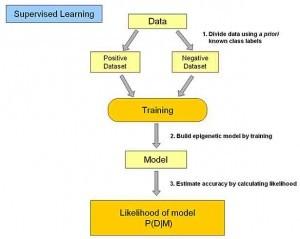
在監(jiān)督式學(xué)習(xí)下,輸入數(shù)據(jù)被稱(chēng)為“訓(xùn)練數(shù)據(jù)”,每組訓(xùn)練數(shù)據(jù)有一個(gè)明確的標(biāo)識(shí)或結(jié)果,如對(duì)防垃圾郵件系統(tǒng)中“垃圾郵件”“非垃圾郵件”,對(duì)手寫(xiě)數(shù)字識(shí)別中的“1“,”2“,”3“,”4“等。在建立預(yù)測(cè)模型的時(shí)候,監(jiān)督式學(xué)習(xí)建立一個(gè)學(xué)習(xí)過(guò)程,將預(yù)測(cè)結(jié)果與“訓(xùn)練數(shù)據(jù)”的實(shí)際結(jié)果進(jìn)行比較,不斷的調(diào)整預(yù)測(cè)模型,直到模型的預(yù)測(cè)結(jié)果達(dá)到一個(gè)預(yù)期的準(zhǔn)確率。監(jiān)督式學(xué)習(xí)的常見(jiàn)應(yīng)用場(chǎng)景如分類(lèi)問(wèn)題和回歸問(wèn)題。常見(jiàn)算法有邏輯回歸(Logistic Regression)和反向傳遞神經(jīng)網(wǎng)絡(luò)(Back Propagation Neural Network)。
1.2 非監(jiān)督式學(xué)習(xí)
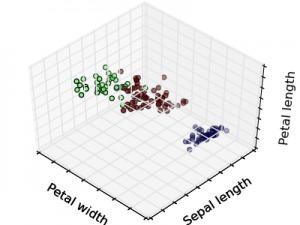
在非監(jiān)督式學(xué)習(xí)中,數(shù)據(jù)并不被特別標(biāo)識(shí),學(xué)習(xí)模型是為了推斷出數(shù)據(jù)的一些內(nèi)在結(jié)構(gòu)。常見(jiàn)的應(yīng)用場(chǎng)景包括關(guān)聯(lián)規(guī)則的學(xué)習(xí)以及聚類(lèi)等。常見(jiàn)算法包括Apriori算法以及k-Means算法。
1.3 半監(jiān)督式學(xué)習(xí)
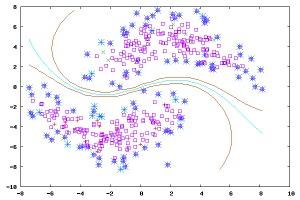
在此學(xué)習(xí)方式下,輸入數(shù)據(jù)部分被標(biāo)識(shí),部分沒(méi)有被標(biāo)識(shí),這種學(xué)習(xí)模型可以用來(lái)進(jìn)行預(yù)測(cè),但是模型首先需要學(xué)習(xí)數(shù)據(jù)的內(nèi)在結(jié)構(gòu)以便合理的組織數(shù)據(jù)來(lái)進(jìn)行預(yù)測(cè)。應(yīng)用場(chǎng)景包括分類(lèi)和回歸,算法包括一些對(duì)常用監(jiān)督式學(xué)習(xí)算法的延伸,這些算法首先試圖對(duì)未標(biāo)識(shí)數(shù)據(jù)進(jìn)行建模,在此基礎(chǔ)上再對(duì)標(biāo)識(shí)的數(shù)據(jù)進(jìn)行預(yù)測(cè)。如圖論推理算法(Graph Inference)或者拉普拉斯支持向量機(jī)(Laplacian SVM.)等。
1.4 強(qiáng)化學(xué)習(xí)

在這種學(xué)習(xí)模式下,輸入數(shù)據(jù)作為對(duì)模型的反饋,不像監(jiān)督模型那樣,輸入數(shù)據(jù)僅僅是作為一個(gè)檢查模型對(duì)錯(cuò)的方式,在強(qiáng)化學(xué)習(xí)下,輸入數(shù)據(jù)直接反饋到模型,模型必須對(duì)此立刻作出調(diào)整。常見(jiàn)的應(yīng)用場(chǎng)景包括動(dòng)態(tài)系統(tǒng)以及機(jī)器人控制等。常見(jiàn)算法包括Q-Learning以及時(shí)間差學(xué)習(xí)(Temporal difference learning)。
在企業(yè)數(shù)據(jù)應(yīng)用的場(chǎng)景下, 人們最常用的可能就是監(jiān)督式學(xué)習(xí)和非監(jiān)督式學(xué)習(xí)的模型。 在圖像識(shí)別等領(lǐng)域,由于存在大量的非標(biāo)識(shí)的數(shù)據(jù)和少量的可標(biāo)識(shí)數(shù)據(jù), 目前半監(jiān)督式學(xué)習(xí)是一個(gè)很熱的話題。 而強(qiáng)化學(xué)習(xí)更多的應(yīng)用在機(jī)器人控制及其他需要進(jìn)行系統(tǒng)控制的領(lǐng)域。
2. 算法分類(lèi)
根據(jù)算法的功能和形式的類(lèi)似性,我們可以把算法分類(lèi),比如說(shuō)基于樹(shù)的算法,基于神經(jīng)網(wǎng)絡(luò)的算法等等。當(dāng)然,機(jī)器學(xué)習(xí)的范圍非常龐大,有些算法很難明確歸類(lèi)到某一類(lèi)。而對(duì)于有些分類(lèi)來(lái)說(shuō),同一分類(lèi)的算法可以針對(duì)不同類(lèi)型的問(wèn)題。這里,我們盡量把常用的算法按照最容易理解的方式進(jìn)行分類(lèi)。
2.1 回歸算法
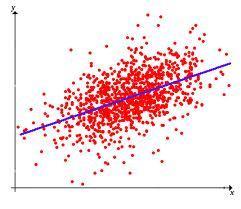
回歸算法是試圖采用對(duì)誤差的衡量來(lái)探索變量之間的關(guān)系的一類(lèi)算法。回歸算法是統(tǒng)計(jì)機(jī)器學(xué)習(xí)的利器。在機(jī)器學(xué)習(xí)領(lǐng)域,人們說(shuō)起回歸,有時(shí)候是指一類(lèi)問(wèn)題,有時(shí)候是指一類(lèi)算法,這一點(diǎn)常常會(huì)使初學(xué)者有所困惑。常見(jiàn)的回歸算法包括:最小二乘法(Ordinary Least Square),邏輯回歸(Logistic Regression),逐步式回歸(Stepwise Regression),多元自適應(yīng)回歸樣條(Multivariate Adaptive Regression Splines)以及本地散點(diǎn)平滑估計(jì)(Locally Estimated Scatterplot Smoothing)。
2.2 基于實(shí)例的算法
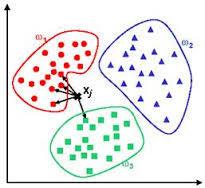
基于實(shí)例的算法常常用來(lái)對(duì)決策問(wèn)題建立模型,這樣的模型常常先選取一批樣本數(shù)據(jù),然后根據(jù)某些近似性把新數(shù)據(jù)與樣本數(shù)據(jù)進(jìn)行比較。通過(guò)這種方式來(lái)尋找匹配。因此,基于實(shí)例的算法常常也被稱(chēng)為“贏家通吃”學(xué)習(xí)或者“基于記憶的學(xué)習(xí)”。常見(jiàn)的算法包括 k-Nearest Neighbor(KNN), 學(xué)習(xí)矢量量化(Learning Vector Quantization, LVQ),以及自組織映射算法(Self-Organizing Map , SOM)。
2.3 正則化方法
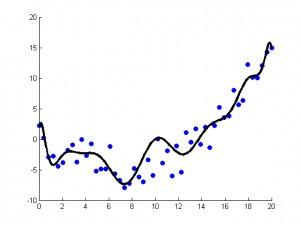
正則化方法是其他算法(通常是回歸算法)的延伸,根據(jù)算法的復(fù)雜度對(duì)算法進(jìn)行調(diào)整。正則化方法通常對(duì)簡(jiǎn)單模型予以獎(jiǎng)勵(lì)而對(duì)復(fù)雜算法予以懲罰。常見(jiàn)的算法包括:Ridge Regression, Least Absolute Shrinkage and Selection Operator(LASSO),以及彈性網(wǎng)絡(luò)(Elastic Net)。
2.4 決策樹(shù)學(xué)習(xí)
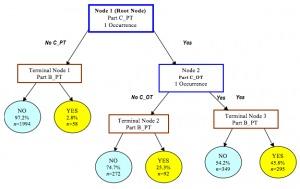
決策樹(shù)算法根據(jù)數(shù)據(jù)的屬性采用樹(shù)狀結(jié)構(gòu)建立決策模型, 決策樹(shù)模型常常用來(lái)解決分類(lèi)和回歸問(wèn)題。常見(jiàn)的算法包括:分類(lèi)及回歸樹(shù)(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 隨機(jī)森林(Random Forest), 多元自適應(yīng)回歸樣條(MARS)以及梯度推進(jìn)機(jī)(Gradient Boosting Machine, GBM)
2.5 貝葉斯方法

貝葉斯方法算法是基于貝葉斯定理的一類(lèi)算法,主要用來(lái)解決分類(lèi)和回歸問(wèn)題。常見(jiàn)算法包括:樸素貝葉斯算法,平均單依賴估計(jì)(Averaged One-Dependence Estimators, AODE),以及Bayesian Belief Network(BBN)。
2.6 基于核的算法

基于核的算法中最著名的莫過(guò)于支持向量機(jī)(SVM)了。 基于核的算法把輸入數(shù)據(jù)映射到一個(gè)高階的向量空間, 在這些高階向量空間里, 有些分類(lèi)或者回歸問(wèn)題能夠更容易的解決。 常見(jiàn)的基于核的算法包括:支持向量機(jī)(Support Vector Machine, SVM), 徑向基函數(shù)(Radial Basis Function ,RBF), 以及線性判別分析(Linear Discriminate Analysis ,LDA)等。
2.7 聚類(lèi)算法
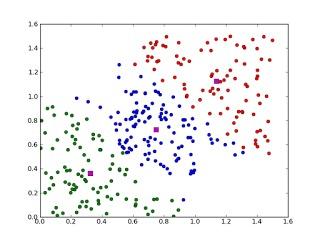
聚類(lèi),就像回歸一樣,有時(shí)候人們描述的是一類(lèi)問(wèn)題,有時(shí)候描述的是一類(lèi)算法。聚類(lèi)算法通常按照中心點(diǎn)或者分層的方式對(duì)輸入數(shù)據(jù)進(jìn)行歸并。所以的聚類(lèi)算法都試圖找到數(shù)據(jù)的內(nèi)在結(jié)構(gòu),以便按照最大的共同點(diǎn)將數(shù)據(jù)進(jìn)行歸類(lèi)。常見(jiàn)的聚類(lèi)算法包括 k-Means算法以及期望最大化算法(Expectation Maximization, EM)。
2.8 關(guān)聯(lián)規(guī)則學(xué)習(xí)
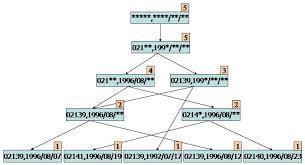
關(guān)聯(lián)規(guī)則學(xué)習(xí)通過(guò)尋找最能夠解釋數(shù)據(jù)變量之間關(guān)系的規(guī)則,來(lái)找出大量多元數(shù)據(jù)集中有用的關(guān)聯(lián)規(guī)則。常見(jiàn)算法包括 Apriori算法和Eclat算法等。
2.9 遺傳算法(genetic algorithm)
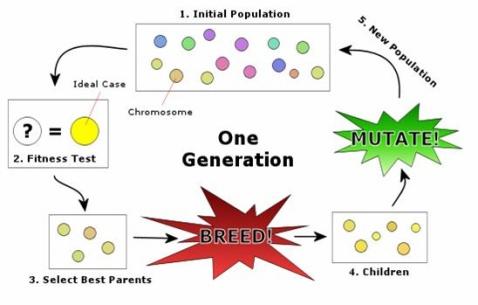
遺傳算法模擬生物繁殖的突變、交換和達(dá)爾文的自然選擇(在每一生態(tài)環(huán)境中適者生存)。它把問(wèn)題可能的解編碼為一個(gè)向量,稱(chēng)為個(gè)體,向量的每一個(gè)元素稱(chēng)為基因,并利用目標(biāo)函數(shù)(相應(yīng)于自然選擇標(biāo)準(zhǔn))對(duì)群體(個(gè)體的集合)中的每一個(gè)個(gè)體進(jìn)行評(píng)價(jià),根據(jù)評(píng)價(jià)值(適應(yīng)度)對(duì)個(gè)體進(jìn)行選擇、交換、變異等遺傳操作,從而得到新的群體。遺傳算法適用于非常復(fù)雜和困難的環(huán)境,比如,帶有大量噪聲和無(wú)關(guān)數(shù)據(jù)、事物不斷更新、問(wèn)題目標(biāo)不能明顯和精確地定義,以及通過(guò)很長(zhǎng)的執(zhí)行過(guò)程才能確定當(dāng)前行為的價(jià)值等。同神經(jīng)網(wǎng)絡(luò)一樣,遺傳算法的研究已經(jīng)發(fā)展為人工智能的一個(gè)獨(dú)立分支,其代表人物為霍勒德(J.H.Holland)。
2.10 人工神經(jīng)網(wǎng)絡(luò)
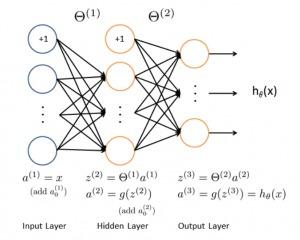
人工神經(jīng)網(wǎng)絡(luò)算法模擬生物神經(jīng)網(wǎng)絡(luò),是一類(lèi)模式匹配算法。通常用于解決分類(lèi)和回歸問(wèn)題。人工神經(jīng)網(wǎng)絡(luò)是機(jī)器學(xué)習(xí)的一個(gè)龐大的分支,有幾百種不同的算法。(其中深度學(xué)習(xí)就是其中的一類(lèi)算法,我們會(huì)單獨(dú)討論),重要的人工神經(jīng)網(wǎng)絡(luò)算法包括:感知器神經(jīng)網(wǎng)絡(luò)(Perceptron Neural Network), 反向傳遞(Back Propagation), Hopfield網(wǎng)絡(luò),自組織映射(Self-Organizing Map, SOM)。
2.11 深度學(xué)習(xí)

深度學(xué)習(xí)算法是對(duì)人工神經(jīng)網(wǎng)絡(luò)的發(fā)展。 在近期贏得了很多關(guān)注, 特別是百度也開(kāi)始發(fā)力深度學(xué)習(xí)后, 更是在國(guó)內(nèi)引起了很多關(guān)注。 在計(jì)算能力變得日益廉價(jià)的今天,深度學(xué)習(xí)試圖建立大得多也復(fù)雜得多的神經(jīng)網(wǎng)絡(luò)。很多深度學(xué)習(xí)的算法是半監(jiān)督式學(xué)習(xí)算法,用來(lái)處理存在少量未標(biāo)識(shí)數(shù)據(jù)的大數(shù)據(jù)集。常見(jiàn)的深度學(xué)習(xí)算法包括:受限波爾茲曼機(jī)(Restricted Boltzmann Machine, RBN), Deep Belief Networks(DBN),卷積網(wǎng)絡(luò)(Convolutional Network), 堆棧式自動(dòng)編碼器(Stacked Auto-encoders)。
2.12 降低維度算法
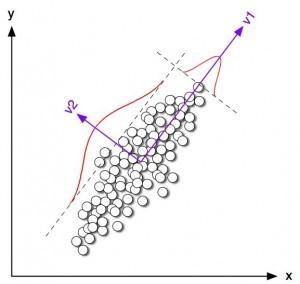
像聚類(lèi)算法一樣,降低維度算法試圖分析數(shù)據(jù)的內(nèi)在結(jié)構(gòu),不過(guò)降低維度算法是以非監(jiān)督學(xué)習(xí)的方式試圖利用較少的信息來(lái)歸納或者解釋數(shù)據(jù)。這類(lèi)算法可以用于高維數(shù)據(jù)的可視化或者用來(lái)簡(jiǎn)化數(shù)據(jù)以便監(jiān)督式學(xué)習(xí)使用。常見(jiàn)的算法包括:主成份分析(Principle Component Analysis, PCA),偏最小二乘回歸(Partial Least Square Regression,PLS), Sammon映射,多維尺度(Multi-Dimensional Scaling, MDS), 投影追蹤(Projection Pursuit)等。
2.13 集成算法
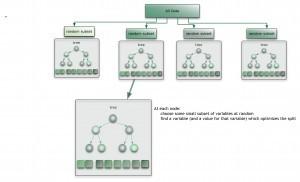
集成算法用一些相對(duì)較弱的學(xué)習(xí)模型獨(dú)立地就同樣的樣本進(jìn)行訓(xùn)練,然后把結(jié)果整合起來(lái)進(jìn)行整體預(yù)測(cè)。集成算法的主要難點(diǎn)在于究竟集成哪些獨(dú)立的較弱的學(xué)習(xí)模型以及如何把學(xué)習(xí)結(jié)果整合起來(lái)。這是一類(lèi)非常強(qiáng)大的算法,同時(shí)也非常流行。常見(jiàn)的算法包括:Boosting, Bootstrapped Aggregation(Bagging), AdaBoost,堆疊泛化(Stacked Generalization, Blending),梯度推進(jìn)機(jī)(Gradient Boosting Machine, GBM),隨機(jī)森林(Random Forest),GBDT(Gradient Boosting Decision Tree)。