Redis 字符串用起來簡單,但是原理可是真不簡單
本文轉載自微信公眾號「Java極客技術」,作者鴨血粉絲 。轉載本文請聯系Java極客技術公眾號。
Hello,大家好,我是阿粉~
無論你現在使用什么編程語言,每天最高頻使用的應該就是字符串。可以說字符串對象很基礎,也很重要。
那么今天想跟大家聊聊 Redis 字符串相關實現,來看下這個看起來簡單的字符串,為什么實現起來確實不簡單?
看完這篇文章你可以學到:
- Redis 字符串對象多種數據結構
- 底層數據結構轉換關系
- SDS 動態字符串
- Redis 采用 C 語言實現,那么字符串為什么不直接使用 C 語言的字符串?
Redis 對象
每當我們在 Redis 中保存一對新的鍵值對時,Redis 至少會創建兩個對象,一個對象用作保存鍵,而另一個對象用作保存值。
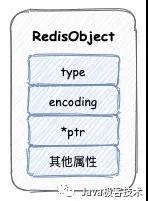
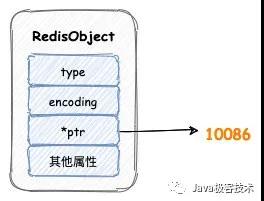
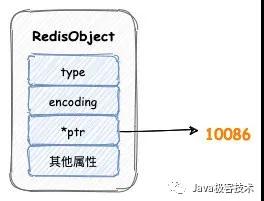
Redis 中每個對象都是一個 redisObject 結構,這個結構中有三個屬性:
- type,表示對象的類型
- encoding,表示編碼
- pstr,指向底層數據結構的指針
type 代表對象類型,目前可以使用類型為:
- 字符串對象
- 列表對象
- 哈希對象
- 集合對象
- 有序集合對象
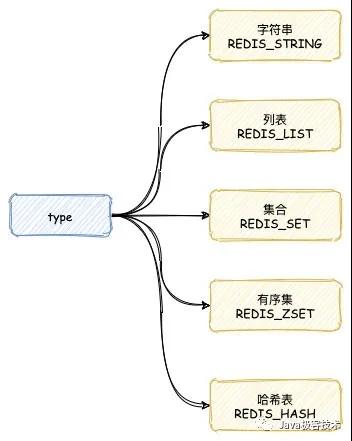
我們可以使用 Redis 的 TYPE 指令,查看當前鍵對應值對象類型。

Redis 鍵對象說起來很簡單,它總是是一個字符串對象,而值對象就相對復雜了,它可以是字符串,也可以是集合,也可以是字典等對象。
每個對象類型底層實現的時候將會采用了多種數據結構,而 encoding 代表底層數據結構類型:
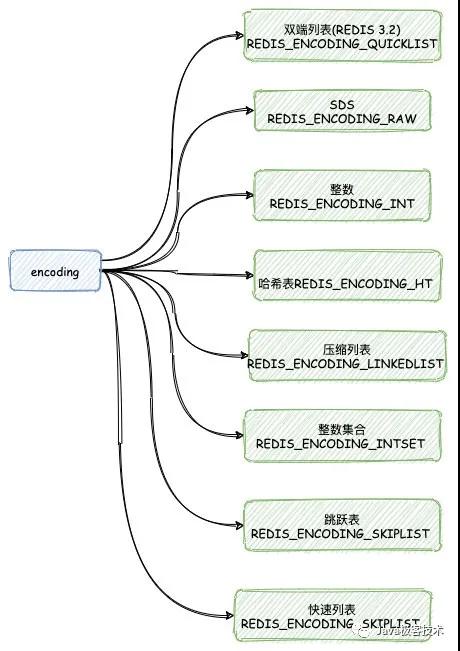
我們可以使用 Redis 的 OBJECT ENCODING 指令查看一個當前鍵值對象底層的編碼:
每個對象類型,可能支持多種數據結構,關系如下:
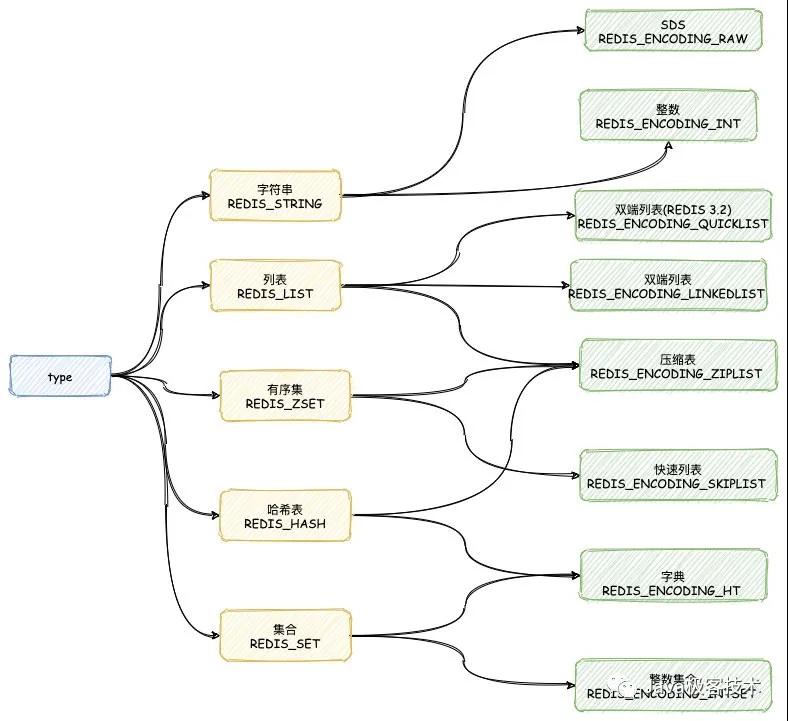
Redis 字符串對象Redis 字符串對象底層支持三種數據結構,分別是(下面使用 OBJECT ENCODING 輸出):
- int
- embstr
- raw
int 代表 long 類型的整數,只要字符串對象中保存的是一個整數值,就將會使用 int 。
這里需要注意,只有整數才會使用 int,如果是浮點數, Redis 內部其實先將浮點數轉化為字符串值,然后再保存。
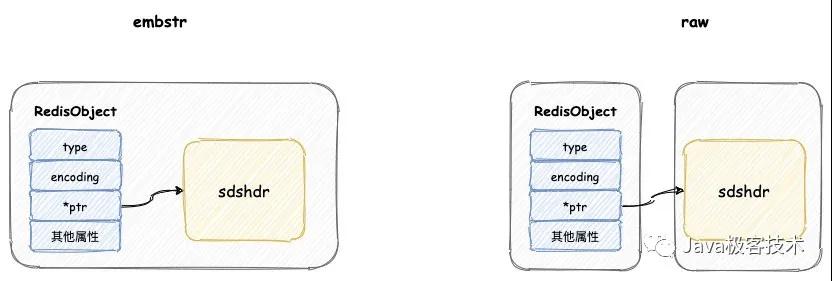
embstr 與 raw 類型底層的數據結構其實都是 SDS (簡單動態字符串),Redis 內部定義 sdshdr 一種結構。
那這兩者的區別其實在于,embstr類型將會調用內存分配函數,分配一塊連續的內存空間,空間中依次包含 redisObject 與 sdshdr 兩個數據結構。
而 raw 類型將會調用兩次內存分配函數,分配兩塊內存空間,一塊用于包含 redisObject結構,而另一塊用于包含 sdshdr 結構。
SDS 簡單動態字符串
接下來我們來看下簡單動態字符串。
sdshdrsds
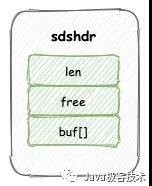
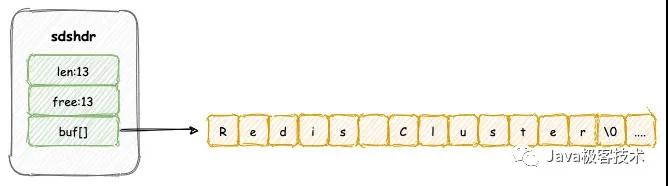
底層的結構包含三個屬性:
- len,用于記錄下面 buf[] 數組已使用的長度,即等于 SDS 所保存的字符串長度
- free,用于記錄下面buf[] 數組未使用長度
- buf[],用戶保存字符串
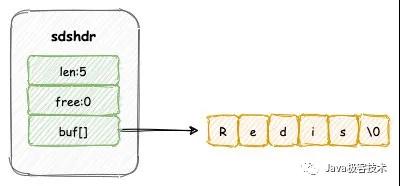
這里我們需要注意了,buf[]數組中最后一個字節將會保存一個空字符 \0,代表字符串結束。sdshdr 結構中的 len 長度是沒有包含這個這一個空字符。
這一點設計上與 C 語言的字符串相同。
SDS 擴容
當我們對 SDS 字符串進行增長操作,如果 SDS 空間不足,SDS 將會先進行擴容,然后再執行修改操作。
假設當前 SDS 值如下所示:
現在執行一次字符串拼接指令,
- APPEND sds " Cluster"
由于拼接完成之后字符串總長度為 13,SDS 剩余空間不足,所以 SDS 將進行擴容,重新執行一次內存重分配。
由于我們上面的例子,SDS 修改之后的長度(即 len 屬性值)小于 1MB,那么程序將會分配和 len 屬性同樣大小的未使用空間,此時 SDS 中 len 屬性與 free 屬性值相同。
此時 SDS buf 數組的實際長度為:
- 13+13+1=27
如果 SDS 修改之后長度大于 1MB,那么 Redis 將會分配 1MB的未使用空間。
假設進行修改之后,SDS len 屬性變為 20MB,那么程序將會分配 1 MB 的未使用空間,此時 SDS buf 數組的實際長度為:
- 20MB+1MB+1byte
接著上面的例子,如果我們再次執行字符串拼接指令:
- APPEND sds " Guide"
這次 SDS 未使用空間足夠保存拼接字符串,所以這次不需要重新分配內存。

SDS 惰性空間釋放
當我們對字符串進行縮減操作, SDS 字符串值將會被縮短,這樣 SDS 剩余空間將會變多。
此時程序不會立即就使用內存分配函數回收多余空間,而是使用 free 屬性記錄多余空間,等待后面使用。
通過這種惰性空間釋放策略,SDS 避免字符串縮短所需內存重分配操作,后續 SDS 字符串增長,可以直接使用多余的空間。
當然 SDS 也有相應的 API,可以真正釋放 SDS 未使用的空間,所以不用擔心惰性釋放策略帶來的內存浪費。
為什么 Redis 不直接使用 C 語言字符串?Redis 底層使用 C 語言編程,那么其實 C 語言也有字符串,Redis 完全可以復用 C 語言字符串~
那么為什么 Redis 還要閉門造車,重新設計一個 SDS 數據結構呢?
這是因為 C 原因這種簡單的字符串形式,在安全性,效率以及功能方面不滿足 Redis 需求。
首先如果我們需要獲取 C 語言字符串的長度,我們可以使用以下函數:
- strlen(str)
strlen函數實際上使用遍歷的方式,對每個字符計數,直到遇到代表字符串結束的空字符。
這個操作時間復雜度 O(N)。
而 SDS 由于 len 記錄當前字符串的長度,所以直接讀取即可,時間復雜度僅為 O(1)。
這就確保獲取字符串長度的操作不會成為 Redis 性能瓶頸。
第二點每次增長或縮短 C 語言的字符串將會進行內存的重分配,否則可能導致緩沖區溢出,也有可能導致內存泄漏。
而 SDS 由于使用空間預分配的策略,如果 SDS 連續增長 N 次,內存重分配的次數從必定 N 次降低為最多 N 次。
第三點,C 語言字符串不能包含空字符,否則第一個空字符將會被誤認為字符串結尾,這就大大限制使用的場景。
而 SDS 中由于可以使用 len 屬性的值判斷字符串是否結束,所以沒有這種困擾。
所以 SDS 字符串是二進制安全的。
字符串對象底層數據結構轉換
SDS 結構由于需要額外的屬性記錄長度以及未使用長度,雖然這樣減少系統的復雜度,提高了性能,但是還是付出相應的代價,即存在一定內存空間浪費。
所以 Redis 字符串對象底層結構并不都是采用了 SDS。
如果字符串對象保存的是整數值,那么這個整數值將會直接保存在字符串對象結構的 ptr 屬性。
如果保存不是整數,但是字符串長度小于等于 39 字節,那么字符串將會使用 embstr編碼方式。最后上述兩個都不滿足才會使用 raw 編碼方式。
另外,int 編碼與 embstr,在一定條件也將會轉換為 raw 編碼格式。
如果對底層整數執行追加操作,使其不再是一個整數,則字符串對象的編碼就會從 int 變為 raw。
對于 embstr 編碼,實際其實只讀的,這是因為 Redis 底層并沒有提供任何程序修改 embstr 編碼對象。
所以一旦我們對embstr 編碼字符串進行修改,字符串對象的編碼就會從 embstr 變為 raw。
總結
Redis 字符串是我們平常操作最頻繁的數據結構,了解底層字符串對象,對于我們了解 Redis 非常重要的。
Redis 字符串對象底層結構可以分為整數與 SDS,當我們在操作 set 命令保存整數時,就將會直接使用整數。
而 SDS 是 Redis 內部定義另一種結構,相比于 C 語言字符串,它可以快速計算字符串長度,不需要頻繁的分配的內存,最終要一點 SDS 是一種二進制安全的字符串。
SDS 設計雖然帶來的很多優勢,但是這種結構相比于 C 語言,至少多占用 4(len)+4(free)=8 字節內存,如果 buf []數組還存在沒有使用的空間,空間浪費更加嚴重。
所以 Redis 字符串不是萬金油,某些場景下可能會占用大量內存。但是如果換一種數據結構,可能內存占用就會變少。
所以我們一定要基于合適場景使用合適的數據機構。