2020年值得關注的4個大數據趨勢

在過去的幾年中,我們在Redpoint投資了超過15家數據公司,并部署了超過2.5億美元的資本。我們是數據/機器學習基礎設施和分析市場的長期信奉者,并沒有放緩。根據IDC的數據,全球大數據和業務分析市場在2019年達到約189B美元,預計到2022年將急劇增長至$ 274B,在此期間的復合年增長率約為13%。
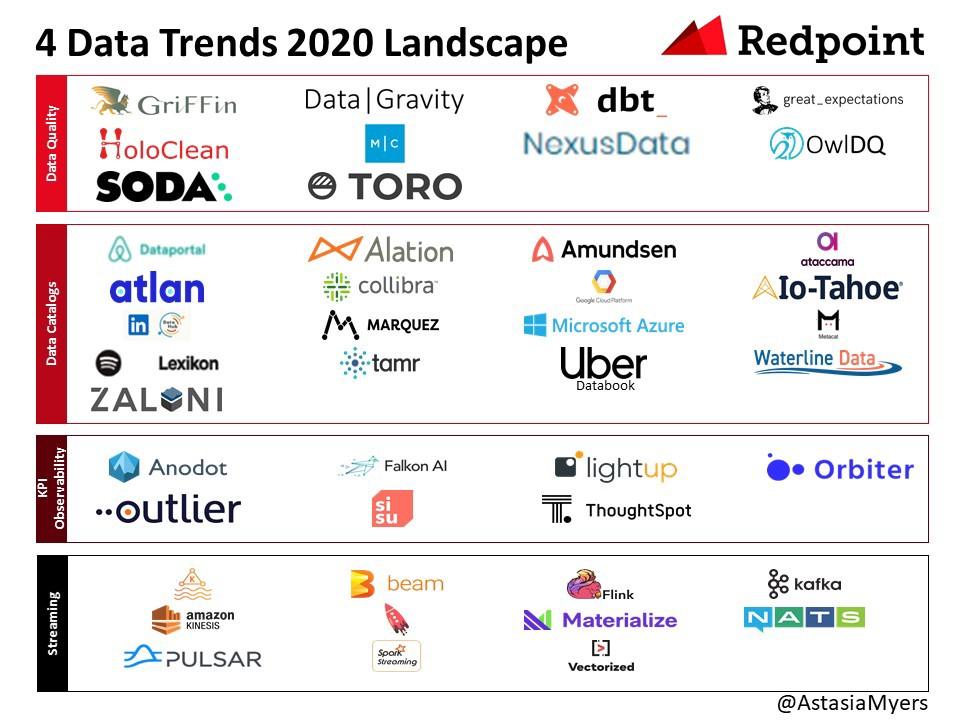
這是一個令人難以置信的動態類別,我非常熱衷于分析和評估接下來的工作(例如此處的數據安全性或此處的綜合數據)。 我的研究旨在挖掘開創性的見解,最終幫助推動該領域的發展。 以下是我們對2020年主要四大趨勢的看法:1)數據質量; 2)數據目錄; 3)KPI的可觀察性; 和4)流式傳輸。
1.數據質量
數據質量管理確保數據適合消費并滿足數據使用者的需求。為了獲得高質量,數據必須是一致且明確的。您可以通過包括準確性,完整性,一致性,完整性,合理性,時間表,唯一性,有效性和可訪問性在內的維度來衡量數據質量。數據質量問題通常是數據庫合并或系統/云集成過程的結果,在這些過程中,應兼容的數據字段不是由于架構或格式不一致引起的。不高質量的數據可以進行數據清理以提高其質量。
當前,大多數公司沒有識別"臟數據"的過程或技術。通常,必須有人發現錯誤。然后,數據平臺或工程團隊必須手動識別錯誤并進行修復。這是一項耗時且乏味的工作(占用了數據科學家80%的時間),這也是數據科學家最抱怨的問題。
高質量的數據對于公司能否依賴它至關重要,而且不良數據的風險也很大。 盡管苛刻的觀察結果"垃圾填入,垃圾填埋"困擾了幾代人的分析和決策,但它對機器學習(ML)提出了特殊警告,因為開發模型所花費的時間很長。 如果ML工程師花費時間培訓并提供使用不良數據構建的ML模型,則錯誤的ML模型將在生產中無效,并且可能對用戶體驗和收入產生負面的間接影響。 O'Reilly的一項調查發現,那些擁有成熟AI實踐(通過生產模型的時間來衡量)的人將"缺乏數據或數據質量問題"作為阻礙進一步采用ML的主要瓶頸。
數據質量是業務人員和機器決策的基礎。 臟數據可能會導致儀表板和執行人員簡介中的值不正確。 此外,我們聽說過糟糕的數據會導致產品開發決策,從而導致企業在工程上損失數百萬美元。 基于不良數據的機器決策可能導致有偏見或不正確的行動。
> https://profisee.com/data-quality-what-why-how-who/
有一些提供數據質量解決方案的早期創業公司和開源項目。一些供應商包括Soda Data,Toro Data和Monte Carlo。

2.數據目錄
根據Alation的說法,數據目錄是"元數據的集合,結合了數據管理和搜索工具,可以幫助分析師和其他數據用戶找到所需的數據,充當可用數據的清單,并提供評估信息。預期用途的適用性數據。"目錄捕獲有關數據的豐富信息,包括其應用程序上下文,行為和更改。我們對數據目錄感興趣,因為它們支持自助數據訪問,從而使個人和團隊受益。借助數據目錄,分析師可以避免與IT部門合作來接收數據的緩慢過程,并且可以自行發現相關數據,從而提高了生產率。此外,數據目錄可以通過收集有關數據使用,數據訪問和PII的信息來幫助實現合規性。
有商業和開源數據目錄。 商業數據目錄包括Collibra,Waterline數據,Alation,Atlan,Ataccama,Zaloni,Azure數據目錄,Google Cloud的數據目錄,IO-Tahoe和Tamr。 Collibra在其籌款過程中最遙遙領先,最近以$ 2.3B的融資后估值籌集了$ 112.5M。 許多科技公司開放了其數據目錄的來源或公開談論它們,包括Airbnb,LinkedIn,Lyft Netflix,Spotify,Uber和WeWork。

3. KPI可觀察性
大多數數據驅動型公司都利用商業智能工具(如Looker,Tableau和Superset)來跟蹤關鍵的KPI。盡管這些操作系統可以在度量標準超過特定閾值時主動發送警報,但分析人員仍然需要深入研究細節以確定KPI為何更改。診斷仍然相當手動。
我們看到了一套新的解決方案,可以使每個企業了解推動其關鍵指標的因素。 運營分析平臺可幫助團隊超越儀表板,了解其關鍵指標正在發生變化的原因。 通過利用機器學習,解決方案可以確定導致KPI更改的特定因素。 我們認為,在這個領域中存在機會,因為企業需要圍繞哪些基本因素提供指導。
我們將生態系統分為三類:1)異常檢測/根本原因分析;2)趨勢檢測;和3)數據洞察力。異常通常會急劇增加/減少,并在單一度量標準級別上運行。趨勢檢測可捕獲異常,但更重要的是可捕獲基礎結構的漂移和變化。數據洞察力從大量數據中發現了意外情況。
有幾家公司提供KPI可觀察性。 Anodot,Lightup和Orbiter專注于異常檢測和引起該變化的潛在因素。 Falkon和Sisu專注于異常檢測和趨勢檢測。 Thoughtspot SpotAI和Outlier嘗試從大量數據中產生最重要的見解,而無需人工監督/配置。 在下面的展覽中,我們將所有相關類別的供應商都包括在內。

4.流式傳輸
對企業實時決策和提供服務的需求不斷增長,因此企業正在轉向流式通信,存儲和數據處理系統。 我們相信,隨著團隊繼續從批處理系統轉移到流系統,存在巨大的市場機會。
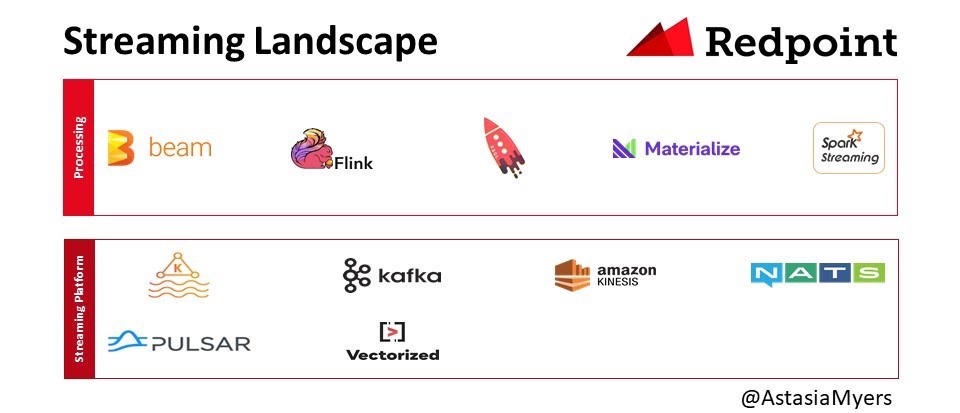
該領域的主要參與者是Kafka,LinkedIn于2011年開源。Kafka是一個發布-訂閱系統,可提供持久,有序,可擴展的消息傳遞。它的體系結構包括主題,發布者和訂閱者。Kafka可以劃分消息主題并支持并行使用。在過去的十年中,該技術從消息傳遞隊列演變為事件流平臺。
雖然有傳言說Kafka背后的公司Confluent的估值為5B美元,但我們聽說該解決方案難以大規模實施和管理。 我們被告知,Zookeeper尤其難以管理,盡管該團隊正在更換此組件,但可以改善用戶體驗。 此外,我們聽說維護可能會遇到挑戰,因為主題數量會迅速增加,因此團隊必須一致地平衡和升級實例。
諸如Apache Pulsar之類的新流媒體方法具有兩層體系結構,其中服務和存儲可以分別擴展。 這對于具有無限數據保留潛力的用例來說非常重要,例如記錄事件可以永久存在的情況。 此外,如果您必須存儲所有消息,則不需要將所有內容都存儲在高性能磁盤中。 使用Pulsar,您可以將較舊的數據移至S3,而Kafka則無法。 還有自動平衡功能,這是AWS Kinesis無法做到的。 我們還聽說用戶對Pulsar比Kafka更輕的客戶端模型表示了同情。 除了Kafka和Flink,還有其他系統,例如NATS和Vectorized。
對于實時數據處理,Apache Flink是最著名的。 當元素出現時,Flink會對其進行處理,而不是像Spark流這樣的微型批次中對其進行處理。 微批量方法的缺點是批量可能非常龐大,需要大量資源進行處理。 對于不一致或突發的數據流,這可能尤其痛苦。 Flink的另一個優點是,您無需通過反復試驗就可以找到適用于微型批次的適當配置。 如果配置生成的處理時間超過其累積時間,則存在問題。 然后批次開始排隊,最終所有處理都將停止。 Materialise團隊還提供了更新的流引擎,例如Confluent KSQL和Timely Dataflow。
ResearchAndMarkets預測,到2023年,全球事件流處理(ESP)市場將從2018年的6.9億美元增長到$ 1.8B,在此期間的復合年增長率為22%。 根據與買家的對話,我們認為市場的增長速度快于此。
明年,我們將關注1)數據質量的演變; 2)數據目錄; 3)KPI的可觀察性; 和4)流式傳輸。 如果您或您認識的某個人正在從事數據/ ML基礎結構和分析項目或啟動工作,那么很高興收到您的來信。 您看到什么趨勢? 請在下面發表評論,或通過amyers@redpoint.com給我發送電子郵件,讓我們知道。