













谷歌AI最新3D數(shù)據(jù)集,1.5萬張動圖,讓AR主宰你的生活
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
見過3D物體數(shù)據(jù)集,見過會動的3D物體數(shù)據(jù)集嗎?

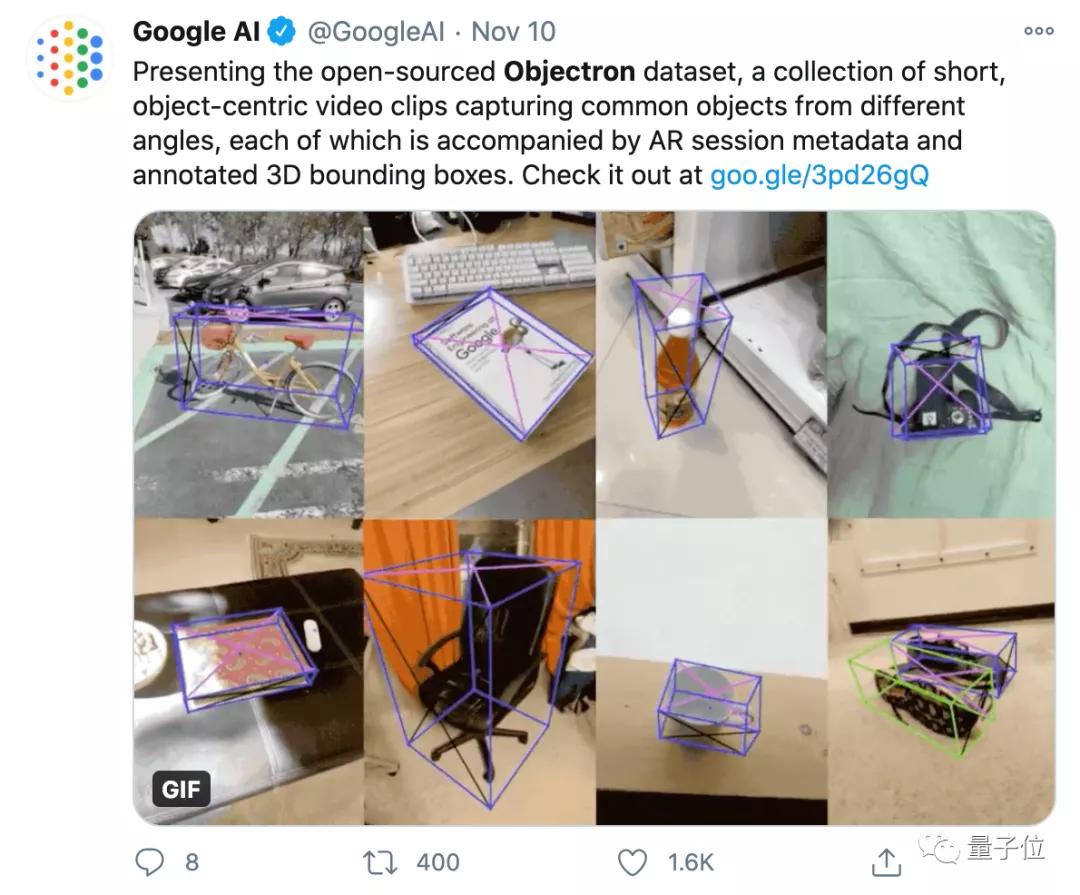
每段動態(tài)視頻都以目標為中心拍攝,不僅自帶標注整體的邊界框,每個視頻還附帶相機位姿和稀疏點云。
這是谷歌的開源3D物體數(shù)據(jù)集Objectron,包含15000份短視頻樣本,以及從五個大洲、十個國家里收集來的400多萬張帶注釋的圖像。
谷歌認為,3D目標理解領(lǐng)域,缺少像2D中的ImageNet這樣的大型數(shù)據(jù)集,而Objectron數(shù)據(jù)集能在一定程度上解決這個問題。
數(shù)據(jù)集一經(jīng)推出,1.6k網(wǎng)友點贊。
有網(wǎng)友調(diào)侃,谷歌恰好在自己想“谷歌”這類數(shù)據(jù)集的時候,把它發(fā)了出來。

也有團隊前成員表示,很高興看到這樣的數(shù)據(jù)集和模型,給AR帶來進步的可能。

除此之外,谷歌還公布了用Objectron數(shù)據(jù)集訓(xùn)練的針對鞋子、椅子、杯子和相機4種類別的3D目標檢測模型。
來看看這個數(shù)據(jù)集包含什么,以及谷歌提供的3D目標檢測方案吧~(項目地址見文末)
9類物體,對AR挺友好
目前,這個數(shù)據(jù)集中包含的3D物體樣本,包括自行車,書籍,瓶子,照相機,麥片盒子,椅子,杯子,筆記本電腦和鞋子。

當然,這個數(shù)據(jù)集,絕不僅僅只是一些以物體為中心拍攝的視頻和圖像,它具有如下特性:
注釋標簽(3D目標立體邊界框)
用于AR數(shù)據(jù)的數(shù)據(jù)(相機位姿、稀疏點云、二維表面)
數(shù)據(jù)預(yù)處理(圖像格式為tf.example,視頻格式為SequenceExample)
支持通過腳本運行3D IoU指標的評估
支持通過腳本實現(xiàn)Tensorflow、PyTorch、JAX的數(shù)據(jù)加載及可視化,包含“Hello World”樣例
支持Apache Beam,用于處理谷歌云(Google Cloud)基礎(chǔ)架構(gòu)上的數(shù)據(jù)集
所有可用樣本的索引,包括訓(xùn)練/測試部分,便于下載
圖像部分的畫風,基本是這樣的,也標注得非常詳細:

而在視頻中,不僅有從各個角度拍攝的、以目標為中心的片段(從左到右、從下到上):

也有不同數(shù)量的視頻類型(一個目標、或者兩個以上的目標):

谷歌希望通過發(fā)布這個數(shù)據(jù)集,讓研究界能夠進一步突破3D目標理解領(lǐng)域,以及相關(guān)的如無監(jiān)督學(xué)習等方向的研究應(yīng)用。
怎么用?谷歌“以身示范”
拿到數(shù)據(jù)集的第一刻,并不知道它是否好用,而且總感覺有點無從下手?
別擔心,這個數(shù)據(jù)集的訓(xùn)練效果,谷歌已經(jīng)替我們試過了。
看起來還不錯:

此外,谷歌將訓(xùn)練好的3D目標檢測模型,也一并給了出來。(傳送見文末)
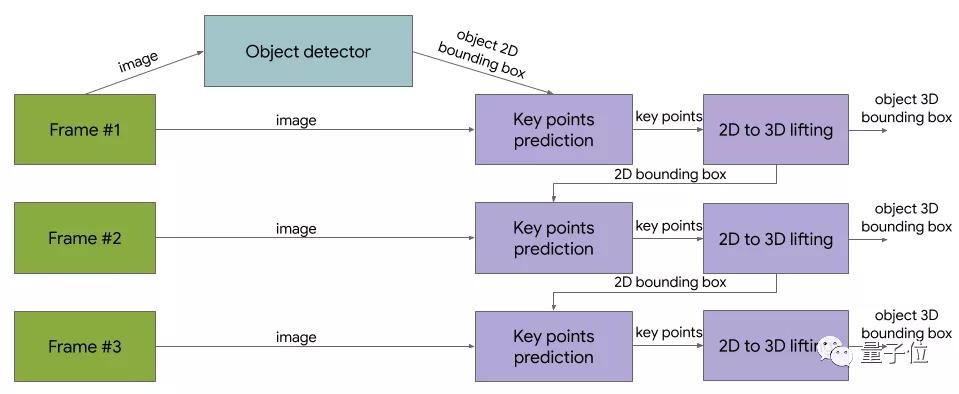
算法主要包括兩部分,第一部分是Tensorflow的2D目標檢測模型,用來“發(fā)現(xiàn)物體的位置”;
第二部分則進行圖像裁剪,來估計3D物體的邊界框(同時計算目標下一幀的2D裁剪,因此不需要運行每個幀),整體結(jié)構(gòu)如下圖:
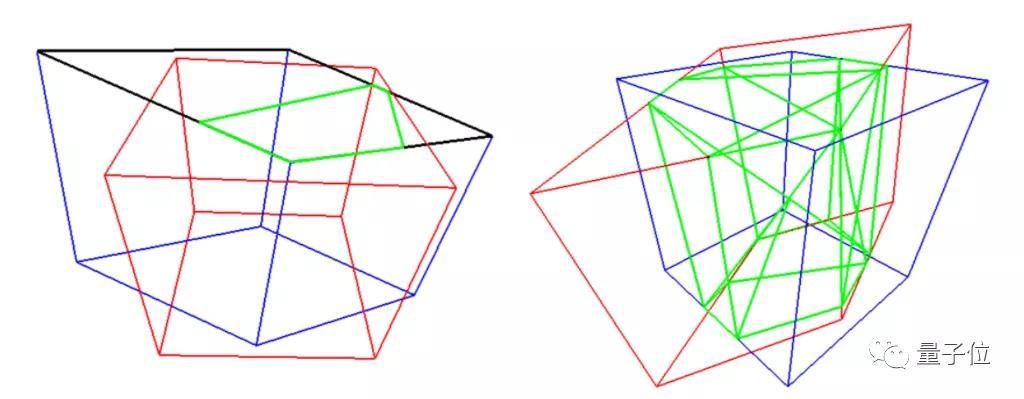
在模型的評估上,谷歌采用了Sutherland-Hodgman多邊形裁剪算法,來計算兩個立體邊界框的交點,并計算出兩個立方體的相交體積,最終計算出3D目標檢測模型的IoU。
簡單來說,兩個立方體重疊體積越大,3D目標檢測模型效果就越好。
這個模型是谷歌推出的MediaPipe中的一個部分,后者是一個開源的跨平臺框架,用于構(gòu)建pipeline,以處理不同形式的感知數(shù)據(jù)。

它推出的MediaPipe Objectron實時3D目標檢測模型,用移動設(shè)備(手機)就能進行目標實時檢測。
看,(他們玩得多歡快)實時目標檢測的效果還不錯:

其他部分3D數(shù)據(jù)集
除了谷歌推出的數(shù)據(jù)集以外,此前視覺3D目標領(lǐng)域,也有許多類型不同的數(shù)據(jù)集,每個數(shù)據(jù)集都有自己的特點。
例如斯坦福大學(xué)等提出的ScanNetV2,是個室內(nèi)場景數(shù)據(jù)集,而ScanNet則是個RGB-D視頻數(shù)據(jù)集,一共有21個目標類,一共1513個采集場景數(shù)據(jù),可做語義分割和目標檢測任務(wù)。

而目前在自動駕駛領(lǐng)域非常熱門的KITTI數(shù)據(jù)集,也是一個3D數(shù)據(jù)集,是目前最大的自動駕駛場景下計算機視覺的算法評測數(shù)據(jù)集,包含市區(qū)、鄉(xiāng)村和高速公路等場景采集的真實圖像數(shù)據(jù)。

此外,還有Waymo、SemanticKITTI、H3D等等數(shù)據(jù)集,也都用在不同的場景中。(例如SemanticKITTI,通常被專門用于自動駕駛的3D語義分割)
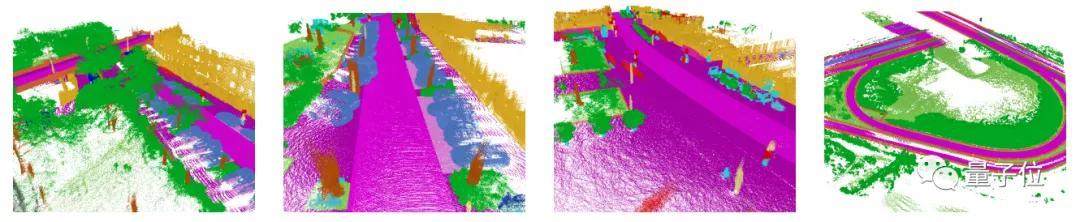
無論是視頻還是圖像,這些數(shù)據(jù)集的單個樣本基本包含多個目標,使用場景上也與谷歌的Objectron有所不同。
感興趣的小伙伴們,可以通過下方傳送門,瀏覽谷歌最新的3D目標檢測數(shù)據(jù)集,以及相關(guān)模型~
Objectron數(shù)據(jù)集傳送門:
https://github.com/google-research-datasets/Objectron/
針對4種物體的3D目標檢測模型:
https://google.github.io/mediapipe/solutions/objectron




















