如果不能用Python執行機器學習,那該用什么呢?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
長期學習數據科學的人一定知道如何用Python、R和Julia這些語言執行機器學習任務。然而,如果速度很關鍵,但硬件很有限,或者所在公司僅使用SQL進行預測分析,又該怎么辦呢?答案就是——數據庫內的機器學習。
本文使用的是Oracle Cloud。它是免費的,你可以注冊并創建一個OLTP數據庫 (19c版本,有0.2TB的存儲空間)。完成之后,下載云錢包并通過SQL Developer或任何其他工具建立連接。這個過程至少要花費10分鐘,但操作很簡單,所以這里不多做贅述。
下面將使用Oracle機器學習(OML)在著名的Iris數據集中訓練一個分類模型。選擇它是因為無須任何準備,只需要創建表格并插入數據。
數據準備
如前所述,要創建一個表格來保存Iris數據集,然后將數據加載到其中。OML要求使用一個列作為行ID(序列),因此要記住:
- CREATE SEQUENCE seq_iris;
- CREATE TABLE iris_data(
- iris_id NUMBER DEFAULT seq_iris.NEXTVAL,
- sepal_length NUMBER,
- sepal_width NUMBER,
- petal_length NUMBER,
- petal_width NUMBER,
- species VARCHAR2(16)
- );
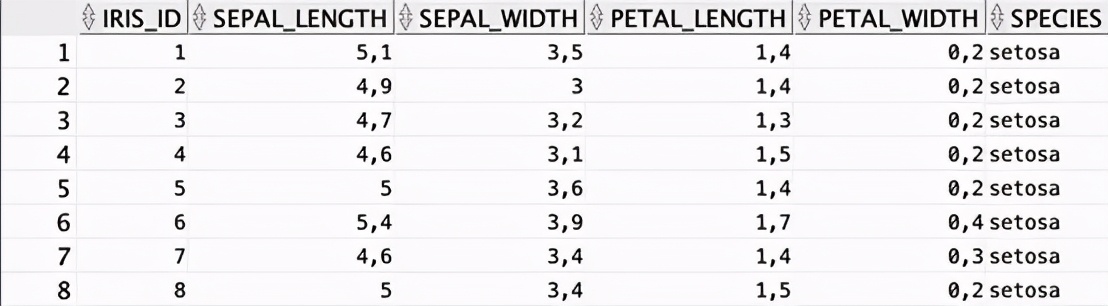
現在可以下載數據并進行加載了:
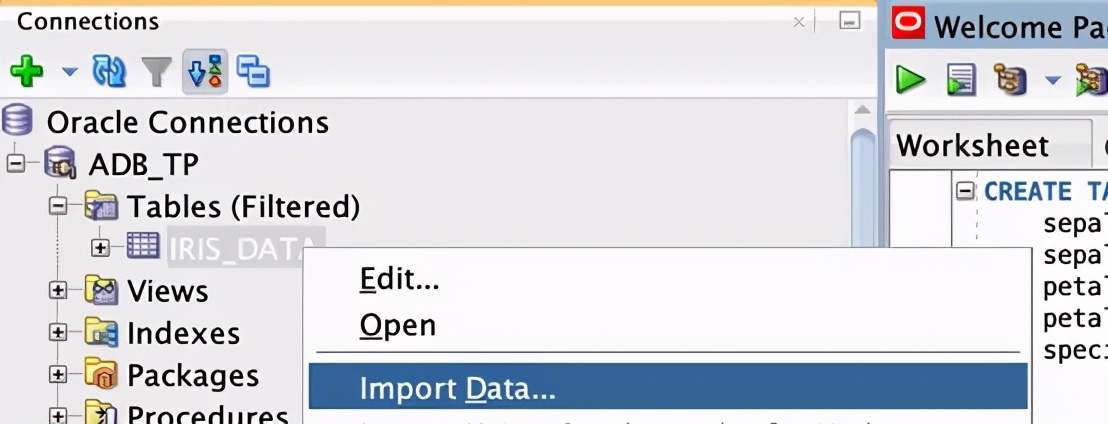
當一個模態窗口彈出時,只需提供下載CSV的路徑并多次點擊Next。SQL開發員無需幫助也能正確完成工作。
模型訓練
現在可以動手做一些有趣的事情了。訓練分類模型可以分解為多個步驟,例如訓練/測試分割、模型訓練和模型評估,我們從最簡單的開始。
訓練/測試分割
Oracle常用兩個視圖完成該步驟:一個用于訓練數據,一個用于測試數據。可以輕松創建這些神奇PL/SQL:
- BEGIN
- EXECUTE IMMEDIATE
- ‘CREATE OR REPLACE VIEW
- iris_train_data AS
- SELECT * FROM iris_data
- SAMPLE (75) SEED (42)’;
- EXECUTE IMMEDIATE
- ‘CREATE OR REPLACE VIEW
- iris_test_data AS
- SELECT * FROM iris_data
- MINUS
- SELECT * FROM iris_train_data’;
- END;
- /
該腳本完成下列兩件事:
- 創建一個訓練視圖-75%的數據 (SAMPLE (75)) 在隨機種子42中分割( SEED (42))。
- 創建一個測試視圖-區分整個數據集和訓練視圖
數據儲存在叫做iris_train_data和iris_test_data的視圖中,猜猜看它們分別存什么。
- SELECT COUNT(*) FROM iris_train_data;
- >>> 111
- SELECT COUNT(*) FROM iris_test_data;
- >>> 39
模型訓練
模型訓練最簡單的方法是無須創建額外的設置表格,只執行單一過程的DBMS_DATA_MINING包。使用決策樹算法來訓練模型。方法如下:
- DECLARE
- v_setlstDBMS_DATA_MINING.SETTING_LIST;
- BEGIN
- v_setlst(‘PREP_AUTO’) := ‘ON’;
- v_setlst(‘ALGO_NAME’) :=‘ALGO_DECISION_TREE’;
- DBMS_DATA_MINING.CREATE_MODEL2(
- ‘iris_clf_model’,
- ‘CLASSIFICATION’,
- ‘SELECT * FROM iris_train_data’,
- v_setlst,
- ‘iris_id’,
- ‘species’
- );
- END;
- /
CREATE_MODEL2過程接受多種參數。接著我們對進入的參數進行解釋:
- iris_clf_model — 只是模型名稱,它可以是任何東西。
- CLASSIFICATION — 正在進行的機器學習任務,因某種原因必須大寫。
- SELECT * FROM iris_train_data — 指定訓練數據存儲位置。
- v_setlst — 模型的上述設置列表。
- iris_id — 序列類型列的名稱(每個值都是唯一的)。
- species — 目標變量的名稱(試圖預測的東西)
執行這一模塊需要一到兩秒鐘,執行完畢就可以開始計算了!
模型評價
使用該腳本評估此模型:
- BEGIN
- DBMS_DATA_MINING.APPLY(
- ‘iris_clf_model’,
- ‘iris_test_data’,
- ‘iris_id’,
- ‘iris_apply_result’
- );
- END;
- /
它將iris_clf_model應用于不可見測試數據iris_test_data,并將評估結果存儲到iris_apply_result表中。
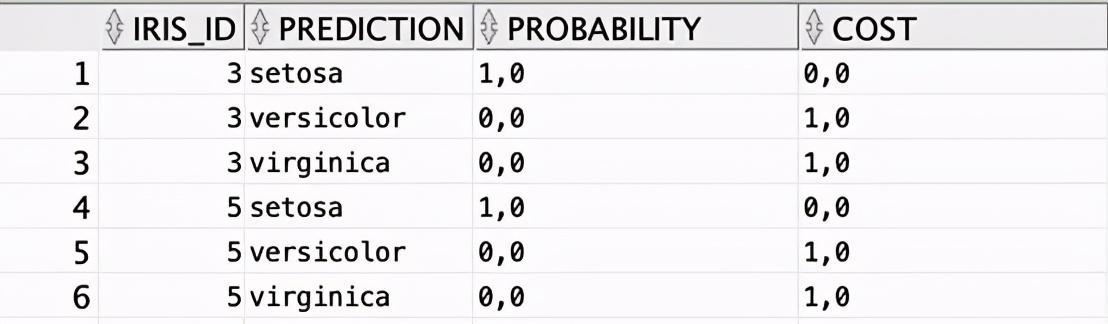
行數更多(39×3),但突顯了要點。這還不夠直觀,所以下面以一種稍微不同的方式來展示結果:
- DECLARE
- CURSOR iris_ids IS
- SELECT DISTINCT(iris_id) iris_id
- FROM iris_apply_result
- ORDER BY iris_id;
- curr_y VARCHAR2(16);
- curr_yhat VARCHAR2(16);
- num_correct INTEGER := 0;
- num_total INTEGER := 0;
- BEGIN
- FOR r_id IN iris_ids LOOP
- BEGIN
- EXECUTE IMMEDIATE
- ‘SELECT species FROM
- iris_test_data
- WHERE iris_id = ‘ ||r_id.iris_id
- INTO curr_y;
- EXECUTE IMMEDIATE
- ‘SELECT prediction
- FROM iris_apply_result
- WHERE iris_id = ‘ ||r_id.iris_id ||
- ‘AND probability = (
- SELECTMAX(probability)
- FROMiris_apply_result
- WHERE iris_id = ‘|| r_id.iris_id ||
- ‘)’ INTO curr_yhat;
- END;
- num_total := num_total + 1;
- IF curr_y = curr_yhat THEN
- num_correct := num_correct +1;
- END IF;
- END LOOP;
- DBMS_OUTPUT.PUT_LINE(‘Num. testcases: ‘
- || num_total);
- DBMS_OUTPUT.PUT_LINE(‘Num. correct :‘
- || num_correct);
- DBMS_OUTPUT.PUT_LINE(‘Accuracy : ‘
- || ROUND((num_correct /num_total), 2));
- END;
- /
確實很多,但上述腳本不能再簡化了。下面進行分解:
- CURSOR—得到所有不同的iris_ids(因為iris_apply_results 表中有重復)。
- curr_y, curr_yhat, num_correct, num_total 是存儲每次迭代中的實際種類和預測種類、正確分類數量和測試項總數的變量。
- 對于每個唯一的iris_id 得到實際種類(來自匹配ID的iris_test_data)和預測種類(在 iris_apply_results 表中預測概率最高)
- 輕松檢查實際值和預測值是否相同——這表明分類是正確的。
- 變量 num_total 和 num_correct 在每次迭代中更新。
- 最后,將模型性能打印到控制臺。
下面為該腳本輸出:

- 測試集有39個用例
- 39個樣本中,正確分類的有37個
- 結果準確率為95%
以上就是模型評估的基本內容。
并不是所有人在工作中都能使用Python,現在,你又掌握了一種解決機器學習任務的方法。