













TinyML:下一輪人工智能革命
人工智能的一個趨勢是正快速從“云端”走向“邊緣”。TinyML 是在海量的物聯網設備端微控制器上實現的人工智能,有望在未來幾年內,成為人工智能在工業領域的重要新應用。邊緣設備往往計算資源和電量受限,對功耗極為敏感。在此類設備上實現人工智能模型,面臨著新的挑戰,也提出了新的應用。本文是 TinyML 系列文章中的第一篇,介紹了 TinyML 概念、技術及未來潛力。
由 NASA 引領的小型化風潮已經席卷了整個消費電子產品產業。現在,一個領針中即可保存全部貝多芬作品,并可使用耳機聆聽。———天體物理學家、科學評論員 Neil deGrasse Tyson
……超低功耗嵌入式設備的普及,以及用于微控制器的 TensorFlow Lite 等嵌入式機器學習框架的推出,意味著人工智能驅動的 IoT 設備將得到大規模普及。———哈佛大學副教授 Vijay Janapa Reddi
圖 1 嵌入設備上的 TinyML 概覽圖
模型并非越大越好。
本文是 TinyML 系列文章中的第一篇,目的是向讀者介紹 TinyML 概念及其未來潛力。本系列的后續文章中,將深入介紹一些特定的應用、具體實現和教程。
引 言
過去的十年中,由于處理器速度的提高和大數據的出現,我們見證了機器學習算法的規模呈指數級增長。最初,模型的規模并不大,在本地計算機中運行,使用 CPU 的一或多個內核。
此后不久,GPU 計算使人們可以處理更大規模的數據集,并且通過基于云的服務,例如 Google Colaboratory 等 SaaS 平臺,Amazon EC2 Instances 等 IaaS,GPU 技術變得更易于獲取。與此同時,算法仍可在單機上運行。
最近,專用的 ASIC 和 TPU 已可提供大約 8 個 GPU 的處理能力。這些設備的發展,增強了將學習算法分布到多個系統中的能力,滿足了規模不斷增大的模型需求。
2020 年 5 月發布的 GPT-3 算法,推動模型的規模達到登峰造極的水平。在 GPT-3 的網絡架構中,包含了數量驚人的 1750 億個神經元,是人腦中約 850 億個神經元的兩倍多,也是 Turing-NLG 神經元數量的 10 倍以上。Turing-NLG 發布于 2020 年 2 月,是有史以來的第二大神經網絡,其中包含約 175 億個參數。有人估計,GPT-3 模型的訓練成本約為 1000 萬美元,使用約 3GWh 的電力,是三個核電站一小時的輸出。
盡管 GPT-3 和 Turing-NLG 的成就值得稱贊,但它們自然也引發了一些業內人士對人工智能行業日益增長碳足跡的批評。另一方面,它們也激發了人工智能領域對更為節能計算的興趣。過去數年中,更高效的算法、數據表示和計算等理念,一直是機器學習微型化(TinyML)這一看似毫無關聯領域的關注點。
TinyML 是機器學習和嵌入式 IoT 設備的交叉領域,是一門新興的工程學科,具有革新許多行業的潛力。
TinyML 的主要受益者,是邊緣計算和節能計算領域。TinyML 源自物聯網 IoT 的概念。物聯網的傳統做法,是將數據從本地設備發送到云端處理。一些人對這一方式在隱私、延遲、存儲和能源效率等方面存在疑慮。
- 能源效率。無論通過有線還是無線方式,數據傳輸都非常耗能,比使用乘積累加運算單元(multiply-accumulate units,MAU)的本機計算高出約一個數量級。最節能的做法,是研發具備本地數據處理能力的物聯網系統。相對于“以計算為中心”的云模型,“以數據為中心”的計算思想已得到了人工智能先驅者的一些先期探討,并已在當前得到了應用。
- 隱私。數據傳輸中存在侵犯隱私的隱患。數據可能被惡意行為者攔截,并且存儲在云等單個位置中時,數據固有的安全性也會降低。通過將數據大部保留在設備上,可最大程度地減少通信需求,進而提高安全性和隱私性。
- 存儲。許多物聯網設備所獲取的大部分數據是毫無用處的。想象一下,一臺安防攝像機每天 24 小時不間斷地記錄著建筑物的入口情況。在一天的大部分時間中,該攝像機并沒有發揮任何作用,因為并沒有什么異常情況發生。采用僅在必要時激活的更智能的系統,可降低對存儲容量的需求,進而降低需傳輸到云端的數據量。
- 延遲。標準的物聯網設備,例如 Amazon Alexa,需將數據傳輸到云來處理,然后由算法的輸出給出響應。從這個意義上講,設備只是云模型的一個便捷網關,類似于和 Amazon 服務器之間的信鴿。設備本身并非智能的,響應速度完全取決于互聯網性能。如果網速很慢,那么 Amazon Alexa 的響應也會變慢。自帶自動語音識別功能的智能 IoT 設備,由于降低甚至是完全消除了對外部通信的依賴,因此降低了延遲。
上述問題推動著邊緣計算的發展。邊緣計算的理念就是在部署在云“邊緣”的設備上實現數據處理功能。這些邊緣設備在內存、計算和功能方面都高度受限于設備自身的資源,進而需要研發更為高效的算法、數據結構和計算方法。
此類改進同樣適用于規模較大的模型,在不降低模型準確率(accuracy)的同時,實現機器學習模型效率數個數量級的提高。例如,Microsoft 開發的 Bonsai 算法 可小到 2 KB,但比通常 40MB 的 kNN 算法或是 4MB 的神經網絡具有更好的性能。這個結果聽上去可能無感,但如果換句話說——在規模縮小了一萬倍的模型上取得同樣的準確率,這就十分令人印象深刻了。規模如此小的模型,可以運行在 2KB 內存的 Arduino Uno 上。簡而言之,現在可以在售價 5 美元的微控制器上構建此類機器學習模型。
機器學習正處于一個交叉路口,兩種計算范式齊頭并進,即以計算為中心的計算,和以數據為中心的計算。在以計算為中心的計算范式下,數據是在數據中心的實例上存儲和分析的;而在以數據為中心的計算范式下,處理是在數據的原始位置執行的。盡管在目前,以計算為中心的計算范式似乎很快會達到上限,但是以數據為中心的計算范式才剛剛起步。
當前,物聯網設備和嵌入式機器學習模型日益普及。預計到 2020 年底,將有超過 200 億臺活躍設備。人們可能并未注意到其中許多設備,例如智能門鈴、智能恒溫器,以及只要用戶說話甚至拿起就可以“喚醒”的智能手機。本文下面將深入介紹 TinyML 的工作機制,以及在當前和將來的應用情況。

圖 2 云的層級結構圖。
TinyML 示例
以前,設備執行的各種操作必需基于復雜的集成電路。現在,機器學習的硬件“智能”正逐漸抽象為軟件,使得嵌入式設備更加簡單、輕量級和靈活。
使用嵌入式設備實現機器學習,需解決巨大的挑戰,但在該領域也取得了長足的進步。在微控制器上部署神經網絡,關鍵挑戰在于低內存占用、功率受限和計算受限。
智能手機是最典型的 TinyML 例子。手機一直處于主動聆聽“喚醒詞”的狀態,例如 Android 智能手機的“你好,谷歌”,以及 iPhone 的“你好,Siri”。如果通過智能手機的 CPU(主流 iPhone 的 CPU 已達 1.85 GHz)運行語音喚醒服務,那么電池電量會在短短幾個小時內耗盡。這樣的電量消耗是不可接受的,而語音喚醒服務大多數人每天最多使用幾次。
為了解決這個問題,開發人員創建了可以用小型電池(例如 CR2032 紐扣電池)供電的專用低功耗硬件。即使 CPU 未運行(通常表現為屏幕并未點亮),集成電路也能保持活躍狀態。
這樣的集成電路消耗功率僅為 1mW,如果使用標準的 CR2032 電池,可供電長達一年。
雖然有些人不覺得這有什么了不起的,但這是非常重要的進步。許多電子設備的瓶頸就是能源。任何需要市電供應的設備,其使用都受電力布線位置的限制。如果同一位置部署了十幾臺設備,可能電源會很快不堪重負。市電的效率并不高,且代價昂貴。將電源電壓(例如美國使用的 120V)轉換為典型的電路電壓范圍(通常約為 5V),會浪費掉大量的能量。筆記本電腦用戶在拔充電器時,對此都深有體會吧。充電器的內部變壓器所產生的熱量,就是在電壓轉換過程中被浪費掉的能量。
即使設備自帶電池,電池續航也是有限的,需要頻繁充電。許多消費類電子設備的電池,設計上可持續使用一個工作日。一些 TinyML 設備可以使用硬幣大小的電池持續運行一年,這意味著可將此類設備部署在一些偏遠的環境中,僅在必要時進行通信,以節省電源。
在一臺智能手機中,喚醒詞服務并非唯一無縫嵌入的 TinyML 應用。加速度計數據可用于確定用戶是否剛拿起手機,進而喚醒 CPU 并點亮屏幕。
顯然,這些并非 TinyML 的唯一用武之地。實際上,TinyML 為產品粉絲和企業提供了大量令人興奮的應用,用于實現更智能的 IoT 設備。在當前數據變得越來越重要的情況下,將機器學習資源分發到遠端內存受限設備的能力,為農業、天氣預報或地震等數據密集行業提供了巨大機遇。
毫無疑問,賦予邊緣設備執行數據驅動處理的能力,將為工業過程中的計算范式帶來轉變。舉個例子,如果能夠監測農作物并檢測到諸如土壤濕度、特定氣體(例如蘋果成熟時會釋放出乙烷)等特征或特定的大氣條件(例如大風、低溫或高濕度等),將極大地促進作物的生長,提高作物的產量。
另一個例子是,在智能門鈴中可安裝攝像機,使用面部識別確定到場的來訪者。這將實現安防功能,甚至可以在有人到場時將門鈴攝像頭輸出到屋內電視屏幕,以便主人了解門口的訪客情況。
目前,TinyML 主要的兩個重點應用領域是:
- 關鍵字發現。大多數人已經非常熟悉此應用,例如“你好,Siri”和“你好,Google”等關鍵字,通常也稱為“熱詞”或“喚醒詞”。設備會連續監聽來自麥克風的音頻輸入,訓練實現僅響應與所學關鍵字匹配的特定聲音序列。這些設備比自動語音識別(automatic speech recognition,ASR)更簡單,使用更少的資源。Google 智能手機等設備還使用了 級聯架構 實現揚聲器的驗證,以確保安全性。
- 視覺喚醒詞。視覺喚醒詞使用圖像類似替代喚醒詞的功能,通過對圖像做二分類表示存在與否。例如,設計一個智能照明系統,在檢測到人的存在時啟動,并在人離開時關閉。同樣,野生動物攝影師可以使用視覺喚醒功能在特定的動物出現時啟動拍攝,安防攝像機可以在檢測到人活動時啟動拍攝。
下圖全面展示當前 TinyML 機器學習的應用概覽。
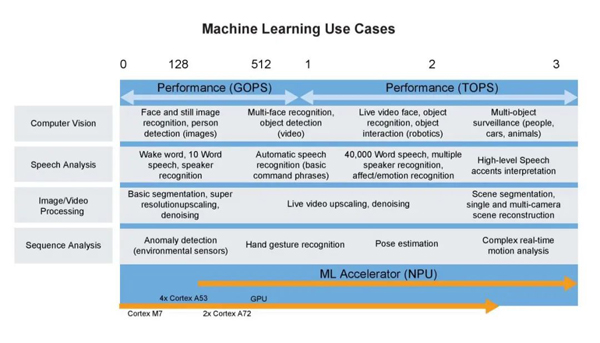
圖 3 TinyML 的機器學習用例。圖片來源:NXP。
TinyML 工作機制
TinyML 算法的工作機制與傳統機器學習模型幾乎完全相同,通常在用戶計算機或云中完成模型的訓練。訓練后處理是 TinyML 真正發揮作用之處,通常稱為“深度壓縮”(deep compression)。
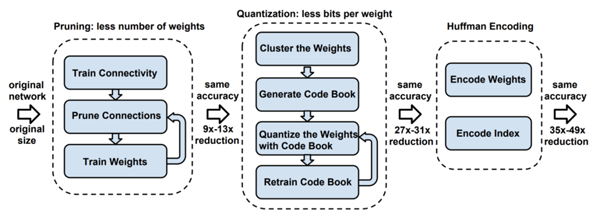
圖 4 深度壓縮示意圖。來源:[ArXiv 論文](https://arxiv.org/pdf/1510.00149.pdf).
模型蒸餾(Distillation)
模型在訓練后需要更改,以創建更緊湊的表示形式。這一過程的主要實現技術包括剪枝(pruning)和知識蒸餾。
知識蒸餾的基本理念,是考慮到較大網絡內部存在的稀疏性或冗余性。雖然大規模網絡具有較高的表示能力,但如果網絡容量未達到飽和,則可以用具有較低表示能力的較小網絡(即較少的神經元)表示。在 Hinton 等人 2015 年發表的研究工作中,將 Teacher 模型中轉移給 Student 模型的嵌入信息稱為“黑暗知識”(dark knowledge)。
下圖給出了知識蒸餾的過程:
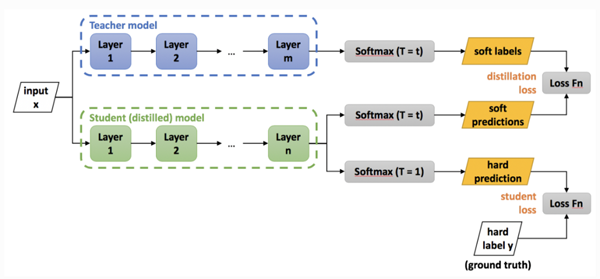
圖 5 深度壓縮過程圖。
圖中 Teacher 模型是經過訓練的卷積神經網絡模型,任務是將其“知識”轉移給稱為 Student 模型的,參數較少的小規模卷積網絡模型。此過程稱為“知識蒸餾”,用于將相同的知識包含在規模較小的網絡中,從而實現一種網絡壓縮方式,以便用于更多內存受限的設備上。
同樣,剪枝有助于實現更緊湊的模型表示。寬泛而言,剪枝力圖刪除對輸出預測幾乎無用的神經元。這一過程通常涉及較小的神經權重,而較大的權重由于在推理過程中具有較高的重要性而會得到保留。隨后,可在剪枝后的架構上對網絡做重新訓練,調優輸出。
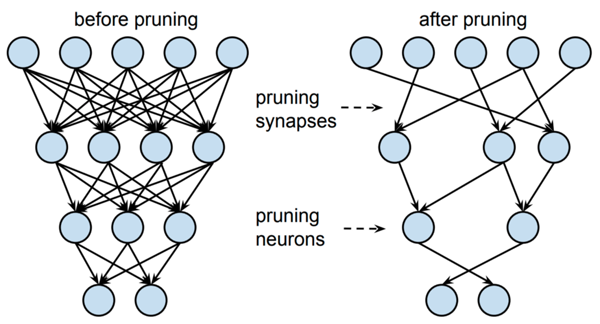
圖 6 對蒸餾模型知識表示做剪枝的圖示。
量化(Quantization)
蒸餾后的模型,需對此后的訓練進行量化,形成兼容嵌入式設備架構的格式。
為什么要做量化?假定對于一臺 Arduino Uno,使用 8 位數值運算的 ATmega328P 微控制器。在理想情況下要在 Uno 上運行模型,不同于許多臺式機和筆記本電腦使用 32 位或 64 位浮點表示,模型的權重必須以 8 位整數值存儲。通過對模型做量化處理,權重的存儲規模將減少到 1/4,即從 32 位量化到 8 位,而準確率受到的影響很小,通常約 1-3%。
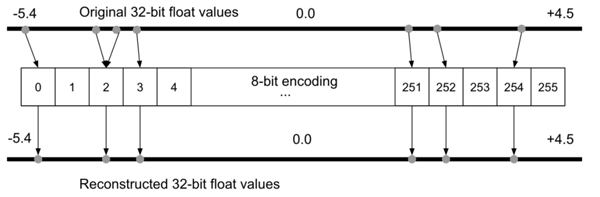
圖 7 8 位編碼過程中的量化誤差示意圖,進而將用于重構 32 位浮點數。圖片來源:《[TinyML](https://tinymlbook.com/)》一書。
由于存在 量化誤差),可能會在量化過程中丟失某些信息。例如在基于整型的平臺上,值為 3.42 的浮點表示形式可能會被截取為 3。為了解決這個問題,有研究提出了量化可感知(quantization-aware,QA)訓練作為替代方案。QA 訓練本質上是在訓練過程中,限制網絡僅使用量化設備可用的值(具體參見 Tensorflow 示例)。
霍夫曼編碼
編碼是可選步驟。編碼通過最有效的方式來存儲數據,可進一步減小模型規模。通常使用著名的 霍夫曼編碼。
編譯
對模型量化和編碼后,需將模型轉換為可被輕量級網絡解釋器解釋的格式,其中最廣為使用的就是 TF Lite(約 500 KB 大小)和 TF Lite Micro(約 20 KB)。模型將編譯為可被大多數微控制器使用并可有效利用內存的 C 或 C++ 代碼,由設備上的解釋器運行。
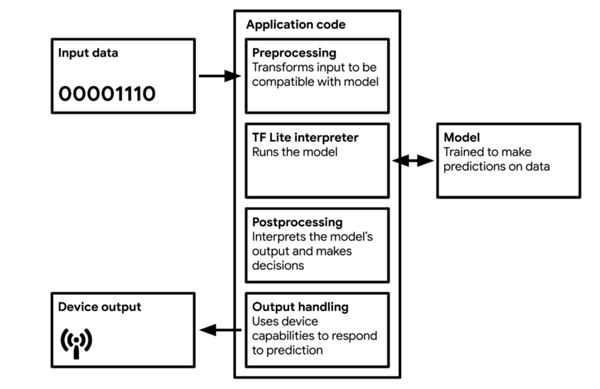
圖 8 TinyML 應用的工作流圖。來源:Pete Warden 和 Daniel Situnayake 編寫的《[TinyML](https://tinymlbook.com/)》一書。
大多數 TinyML 技術,針對的是處理微控制器所導致的復雜性。TF Lite 和 TF Lite Micro 非常小,是因為其中刪除了所有非必要的功能。不幸的是,它們同時也刪除了一些有用的功能,例如調試和可視化。這意味著,如果在部署過程中出現錯誤,可能很難判別原因。
另外,盡管模型必須存儲在設備本地,但模型也必須要支持執行推理。這意味著微控制器必須具有足夠大的內存去運行(1)操作系統和軟件庫;(2)神經網絡解釋器,例如 TF Lite);(3)存儲的神經網絡權重和架構;(4)推理過程中的中間結果。因此,TinyML 方向的研究論文在給出內存使用量、乘法累加單元(multiply-accumulate units,MAC)數量,準確率等指標的同時,通常還需給出量化算法的峰值內存使用情況。
為什么不在設備上訓練?
在設備上進行訓練會引入額外的復雜性。由于數值精度的降低,要確保網絡訓練所需的足夠準確率是極為困難的。在標準臺式計算機的精度下,自動微分方法是大體準確的。計算導數的精度可達令人難以置信的 10^{-16},但是在 8 位數值上做自動微分,將給出精度較差的結果。在反向傳播過程中,會組合使用求導并最終用于更新神經參數。在如此低的數值精度下,模型的準確率可能很差。
盡管存在上述問題,一些神經網絡還是使用了 16 位和 8 位浮點數做了訓練。
第一篇研究降低深度學習中的數值精度的論文,是 Suyog Gupta 及其同事在 2015 年發表的“具有有限數值精度的深度學習”(Deep Learning with Limited Numerical Precision)。該論文給出的結果非常有意思,即可在幾乎不降低準確率的情況下,將 32 位浮點表示形式降至 16 位固定點表示。但該結果僅適用于使用隨機舍入(stochastic rounding)的情況,因為其在均值上產生無偏結果。
在 Naigang Wang 及其同事 2018 年發表的論文“使用 8 位浮點數訓練深度神經網絡”(Training Deep Neural Networks with 8-bit Floating Point Numbers)中,使用了 8 位浮點數訓練神經網絡。在訓練中使用 8 位數值,相比在推理中要明顯難以實現,因為需要在反向傳播期間保持梯度計算的保真度(fidelity),使得在做自動微分時能夠達到機器的精度。
計算效率如何?
可以通過定制模型,提高模型的計算效率。一個很好的例子就是 MobileNet V1 和 MobileNet V2,它們是已在移動設備上得到廣泛部署的模型架構,本質上是一種通過重組(recast)實現更高計算效率卷積運算的卷積神經網絡。這種更有效的卷積形式,稱為深度可分離卷積結構(depthwise separable convolution)。針對架構延遲的優化,還可以使用 基于硬件的概要(hardware-based profiling) 和 神經架構搜索(neural architecture search) 等技術,對此本文將不做詳述。
新一輪人工智能革命
在資源受限的設備上運行機器學習模型,為許多新的應用打開了大門。使標準的機器學習更加節能的技術進步,將有助于消除數據科學對環境影響的一些擔憂。此外,TinyML 支持嵌入式設備搭載基于數據驅動算法的全新智能,進而應用在了從 預防性維護 到 檢測森林中的鳥叫聲 等多種場景中。
盡管繼續擴大模型的規模是一些機器學習從業者的堅定方向,但面向內存、計算和能源效率更高的機器學習算法發展也是一個新的趨勢。TinyML 仍處于起步階段,在該方向上的專家很少。本文參考文獻中列出了一些 TinyML 領域中的重要論文,建議有興趣的讀者去閱讀。該方向正在快速增長,并將在未來幾年內,成為人工智能在工業領域的重要新應用。請保持關注。




















