打工人,從 JMM 透析 Volatile 與 Synchronized 原理
接下來我們通過圖文的方式分別認識 JVM 內(nèi)存結(jié)構(gòu)和 JMM 內(nèi)存模型,DJ, trop the beat, lets’go!
JVM 內(nèi)存結(jié)構(gòu)這么騷,需要和虛擬機運行時數(shù)據(jù)一起嘮叨,因為程序運行的數(shù)據(jù)區(qū)域需要他來劃分各領(lǐng)風(fēng)騷。
Java 內(nèi)存模型也很妖嬈,不能被 JVM 內(nèi)存結(jié)構(gòu)來搞混淆,實際他是一種抽象定義,主要為了并發(fā)編程安全訪問數(shù)據(jù)。
總結(jié)下就是:
- JVM 內(nèi)存結(jié)構(gòu)和 Java 虛擬機的運行時區(qū)域有關(guān);
- Java 內(nèi)存模型和 Java 的并發(fā)編程有關(guān)。
JVM 內(nèi)存結(jié)構(gòu)
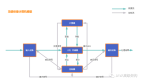
Java 代碼是運行在虛擬機上的,我們寫的 .java 文件首先會被編譯成 .class 文件,接著被 JVM 虛擬機加載,并且根據(jù)不同操作系統(tǒng)平臺翻譯成對應(yīng)平臺的機器碼運行,如下如所示:
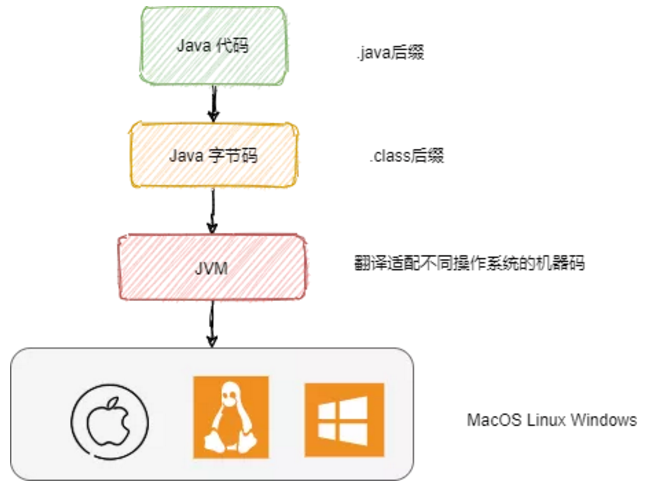
JVM跨平臺
從圖中可以看到,有了 JVM 這個抽象層之后,Java 就可以實現(xiàn)跨平臺了。JVM 只需要保證能夠正確加載 .class 文件,就可以運行在諸如 Linux、Windows、MacOS 等平臺上了。
JVM 通過 Java 類加載器加載 javac 編譯出來的 class 文件,通過執(zhí)行引擎解釋執(zhí)行或者 JIT 即時編譯調(diào)用才調(diào)用系統(tǒng)接口實現(xiàn)程序的運行。
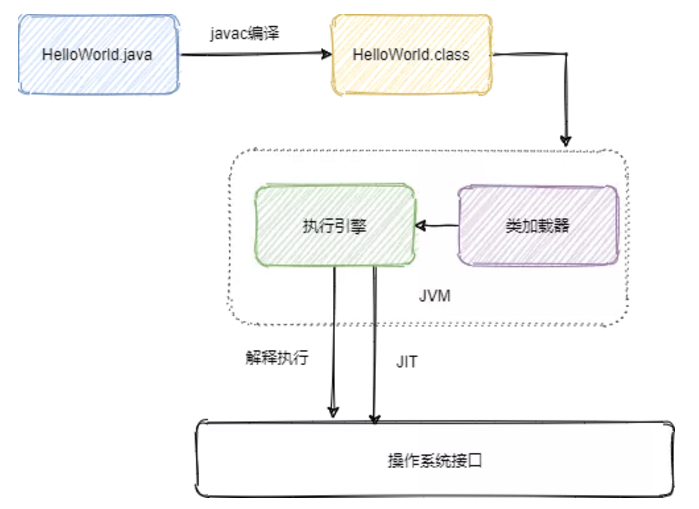
JVM加載
而虛擬機在運行程序的時候會把內(nèi)存劃分為不同的數(shù)據(jù)區(qū)域,不同區(qū)域負責(zé)不同功能,隨著 Java 的發(fā)展,內(nèi)存布局也在調(diào)整之中,如下是 Java 8 之后的布局情況,移除了永久代,使用 Mataspace 代替,所以 -XX:PermSize -XX:MaxPermSize 等參數(shù)變沒有意義。JVM 內(nèi)存結(jié)構(gòu)如下圖所示:
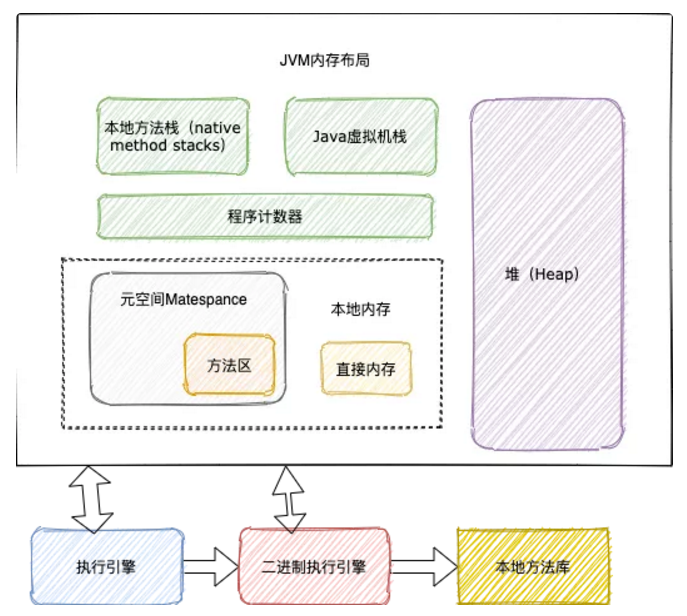
JVM內(nèi)存布局
執(zhí)行字節(jié)碼的模塊叫做執(zhí)行引擎,執(zhí)行引擎依靠程序計數(shù)器恢復(fù)線程切換。本地內(nèi)存包含元數(shù)據(jù)區(qū)域以及一些直接內(nèi)存。
堆(Heap)
數(shù)據(jù)共享區(qū)域存儲實例對象以及數(shù)組,通常是占用內(nèi)存最大的一塊也是數(shù)據(jù)共享的,比如 new Object() 就會生成一個實例;而數(shù)組也是保存在堆上面的,因為在 Java 中,數(shù)組也是對象。垃圾收集器的主要作用區(qū)域。
那一個對象創(chuàng)建的時候,到底是在堆上分配,還是在棧上分配呢?這和兩個方面有關(guān):對象的類型和在 Java 類中存在的位置。
Java 的對象可以分為基本數(shù)據(jù)類型和普通對象。
對于普通對象來說,JVM 會首先在堆上創(chuàng)建對象,然后在其他地方使用的其實是它的引用。比如,把這個引用保存在虛擬機棧的局部變量表中。
對于基本數(shù)據(jù)類型來說(byte、short、int、long、float、double、char),有兩種情況。
我們上面提到,每個線程擁有一個虛擬機棧。當你在方法體內(nèi)聲明了基本數(shù)據(jù)類型的對象,它就會在棧上直接分配。其他情況,通常在在堆上分配,逃逸分析的情況下可能會在棧分配。
注意,像 int[] 數(shù)組這樣的內(nèi)容,是在堆上分配的。數(shù)組并不是基本數(shù)據(jù)類型。
虛擬機棧(Java Virtual Machine Stacks)
Java 虛擬機棧基于線程,即使只有一個 main 方法,都是以線程的方式運行,在運行的生命周期中,參與計算的數(shù)據(jù)會出棧與入棧,而「虛擬機棧」里面的每條數(shù)據(jù)就是「棧幀」,在 Java 方法執(zhí)行的時候則創(chuàng)建一個「棧幀」并入棧「虛擬機棧」。調(diào)用結(jié)束則「棧幀」出棧,隨之對應(yīng)的線程也結(jié)束。
- public int add() {
- int a = 1, b = 2;
- return a + b;
- }
add 方法會被抽象成一個「棧幀」的結(jié)構(gòu),當方法執(zhí)行過程中則對應(yīng)著操作數(shù) 1 與 2 的操作數(shù)棧入棧,并且賦值給局部變量 a 、b ,遇到 add 指令則將操作數(shù) 1、2 出棧相加結(jié)果入棧。方法結(jié)束后「棧幀」出棧,返回結(jié)果結(jié)束。
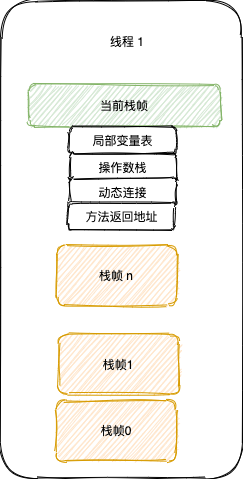
每個棧幀包含四個區(qū)域:
- 局部變量表:基本數(shù)據(jù)類型、對象引用、retuenAddress 指向字節(jié)碼的指針;
- 操作數(shù)棧
- 動態(tài)連接
- 返回地址
這里有一個重要的地方,敲黑板了:
- 實際上有兩層含義的棧,第一層是「棧幀」對應(yīng)方法;第二層對應(yīng)著方法的執(zhí)行,對應(yīng)著操作數(shù)棧。
- 所有的字節(jié)碼指令,都會被抽象成對棧的入棧與出棧操作。執(zhí)行引擎只需要傻瓜式的按順序執(zhí)行,就可以保證它的正確性。
每個線程擁有一個「虛擬機棧」,每個「虛擬機棧」擁有多個「棧幀」,而棧幀則對應(yīng)著一個方法。每個「棧幀」包含局部變量表、操作數(shù)棧、動態(tài)鏈接、方法返回地址。方法運行結(jié)束則意味著該「棧幀」出棧。
如下圖所示:
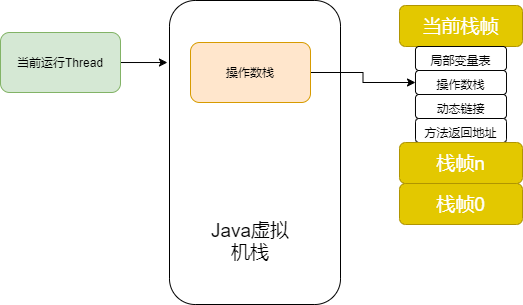
JVM虛擬機棧
方法區(qū)(Method Area)元空間
存儲每個 class 類的元數(shù)據(jù)信息,比如類的結(jié)構(gòu)、運行時的常量池、字段、方法數(shù)據(jù)、方法構(gòu)造函數(shù)以及接口初始化等特殊方法。
元空間是在堆上么?
答:不是在堆上分配的,而是在堆外空間分配,方法區(qū)就是在元空間中。
字符串常量池在那個區(qū)域中?
答:這個跟 JDK 不同版本不同區(qū)別,JDK 1.8 之前,元空間還沒有出道成團,方法區(qū)被放在一個叫永久代的空間,而字符串常量就在此間。
JDK 1.7 之前,字符串常量池也放在叫作永久帶的空間。JDK 1.7 之后,字符串常量池從永久帶挪到了堆上湊。
所以,從 1.7 版本開始,字符串常量池就一直存在于堆上。
本地方法棧(Native Method Stacks)
跟虛擬機棧類似,區(qū)別在于前者是為 Java 方法服務(wù),而本地方法棧是為 native 方法服務(wù)。
程序計數(shù)器(The PC Register)
保存當前正在執(zhí)行的 JVM 指令地址。我們的程序在線程切換中運行,那憑啥知道這個線程已經(jīng)執(zhí)行到什么地方呢?
程序計數(shù)器是一塊較小的內(nèi)存空間,它的作用可以看作是當前線程所執(zhí)行的字節(jié)碼的行號指示器。這里面存的,就是當前線程執(zhí)行的進度。
JMM(Java Memory Model,Java 內(nèi)存模型)
DJ, drop the beats!有請“碼哥字節(jié)”,撥弄 Java 內(nèi)存模型這根動人心弦。
首先他不是“真實存在”,而是和多線程相關(guān)的一組“規(guī)范”,需要每個 JVM 的實現(xiàn)都要遵守這樣的“規(guī)范”,有了 JMM 的規(guī)范保障,并發(fā)程序運行在不同的虛擬機得到出的程序結(jié)果才是安全可靠可信賴。
如果沒有 JMM 內(nèi)存模型來規(guī)范,就可能會出現(xiàn)經(jīng)過不同 JVM “翻譯”之后,運行的結(jié)果都不相同也不正確。
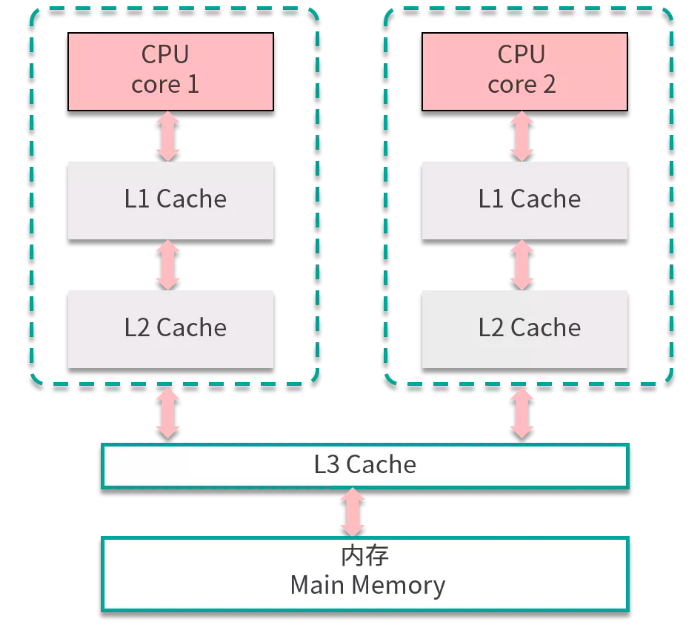
JMM 與處理器、緩存、并發(fā)、編譯器有關(guān)。它解決了 CPU 多級緩存、處理器優(yōu)化、指令重排等導(dǎo)致的結(jié)果不可預(yù)期的問題數(shù)據(jù),保證不同的并發(fā)語義關(guān)鍵字得到相應(yīng)的并發(fā)安全的數(shù)據(jù)資源保護。
主要目的就是讓 Java 程序員在各種平臺下達到一致性訪問效果。
是 JUC 包工具類和并發(fā)關(guān)鍵字的原理保障
volatile、synchronized、Lock 等,它們的實現(xiàn)原理都涉及 JMM。有了 JMM 的參與,才讓各個同步工具和關(guān)鍵字能夠發(fā)揮作用同步語義才能生效,使得我們開發(fā)出并發(fā)安全的程序。
JMM 最重要的三點內(nèi)容:重排序、原子性、內(nèi)存可見性。
指令重排序
我們寫的 bug 代碼,當我以為這些代碼的運行順序按照我神來之筆的書寫的順序執(zhí)行的時候,我發(fā)現(xiàn)我錯的。實際上,編譯器、JVM、甚至 CPU 都有可能出于優(yōu)化性能的目的,并不能保證各個語句執(zhí)行的先后順序與輸入的代碼順序一致,而是調(diào)整了順序,這就是指令重排序。
重排序優(yōu)勢
可能我們會疑問:為什么要指令重排序?有啥用?
如下圖:
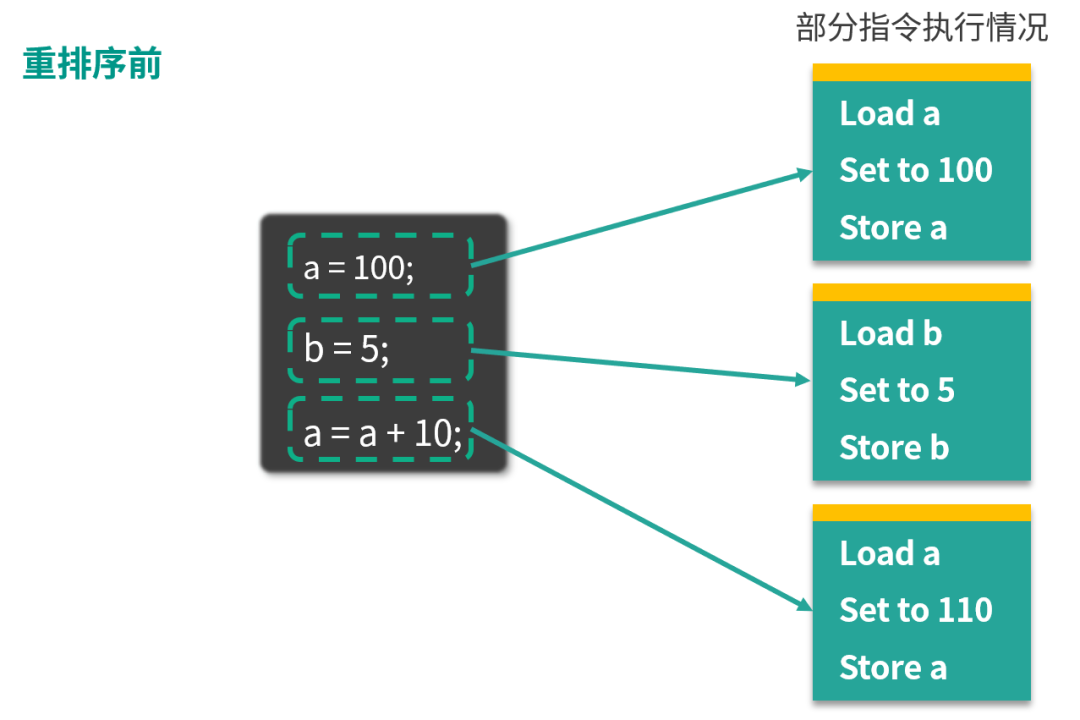
Java并發(fā)編程78講
經(jīng)過重排序之后,情況如下圖所示:
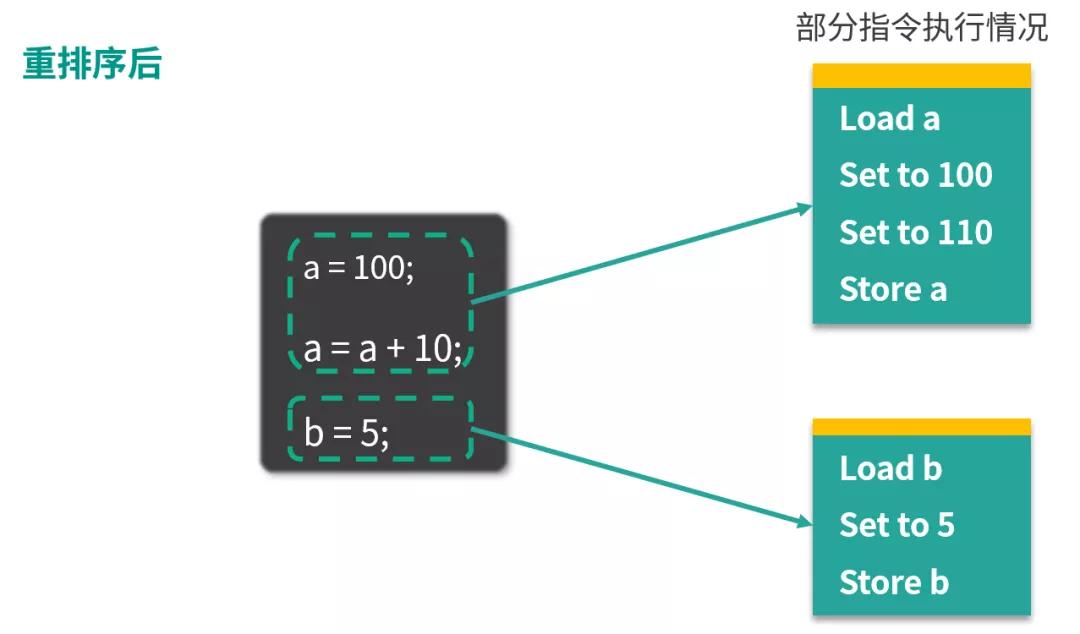
Java并發(fā)編程78講
重排序后,對 a 操作的指令發(fā)生了改變,節(jié)省了一次 Load a 和一次 Store a,減少了指令執(zhí)行,提升了速度改變了運行,這就是重排序帶來的好處。
重排序的三種情況
- 編譯器優(yōu)化
比如當前唐伯虎愛慕 “秋香”,那就把對“秋香”的愛慕、約會放到一起執(zhí)行效率就高得多。避免在撩“冬香”的時候又跑去約會“秋香”,減少了這部分的時間開銷,此刻我們需要一定的順序重排。不過重排序并不意味著可以任意排序,它需要需要保證重排序后,不改變單線程內(nèi)的語義,不能把對“秋香”說的話傳到“冬香”的耳朵里,否則能任意排序的話,后果不堪設(shè)想,“時間管理大師”非你莫屬。
- CPU 重排序
這里的優(yōu)化跟編譯器類似,目的都是通過打亂順序提高整體運行效率,這就是為了更快而執(zhí)行的秘密武器。
- 內(nèi)存“重排序”
我不是真正意義的重排序,但是結(jié)果跟重排序有類似的成績。因為還是有區(qū)別所以我加了雙引號作為不一樣的定義。
由于內(nèi)存有緩存的存在,在 JMM 里表現(xiàn)為主存和本地內(nèi)存,而主存和本地內(nèi)存的內(nèi)容可能不一致,所以這也會導(dǎo)致程序表現(xiàn)出亂序的行為。
每個線程只能夠直接接觸到工作內(nèi)存,無法直接操作主內(nèi)存,而工作內(nèi)存中所保存的數(shù)據(jù)正是主內(nèi)存的共享變量的副本,主內(nèi)存和工作內(nèi)存之間的通信是由 JMM 控制的。
舉個例子:
線程 1 修改了 a 的值,但是修改后沒有來得及把新結(jié)果寫回主存或者線程 2 沒來得及讀到最新的值,所以線程 2 看不到剛才線程 1 對 a 的修改,此時線程 2 看到的 a 還是等于初始值。但是線程 2 卻可能看到線程 1 修改 a 之后的代碼執(zhí)行效果,表面上看起來像是發(fā)生了重順序。
內(nèi)存可見性
先來看為何會有內(nèi)存可見性問題
- public class Visibility {
- int x = 0;
- public void write() {
- x = 1;
- }
- public void read() {
- int y = x;
- }
- }
內(nèi)存可見性問題:當 x 的值已經(jīng)被第一個線程修改了,但是其他線程卻看不到被修改后的值。
假設(shè)兩個線程執(zhí)行的上面的代碼,第 1 個線程執(zhí)行的是 write 方法,第 2 個線程執(zhí)行的是 read 方法。下面我們來分析一下,代碼在實際運行過程中的情景是怎么樣的,如下圖所示:

它們都可以從主內(nèi)存中去獲取到這個信息,對兩個線程來說 x 都是 0。可是此時我們假設(shè)第 1 個線程先去執(zhí)行 write 方法,它就把 x 的值從 0 改為了 1,但是它改動的動作并不是直接發(fā)生在主內(nèi)存中的,而是會發(fā)生在第 1 個線程的工作內(nèi)存中,如下圖所示。

那么,假設(shè)線程 1 的工作內(nèi)存還未同步給主內(nèi)存,此時假設(shè)線程 2 開始讀取,那么它讀到的 x 值不是 1,而是 0,也就是說雖然此時線程 1 已經(jīng)把 x 的值改動了,但是對于第 2 個線程而言,根本感知不到 x 的這個變化,這就產(chǎn)生了可見性問題。
volatile、synchronized、final、和鎖 都能保證可見性。要注意的是 volatile,每當變量的值改變的時候,都會立馬刷新到主內(nèi)存中,所以其他線程想要讀取這個數(shù)據(jù),則需要從主內(nèi)存中刷新到工作內(nèi)存上。
而鎖和同步關(guān)鍵字就比較好理解一些,它是把更多個操作強制轉(zhuǎn)化為原子化的過程。由于只有一把鎖,變量的可見性就更容易保證。
原子性
我們大致可以認為基本數(shù)據(jù)類型變量、引用類型變量、聲明為 volatile 的任何類型變量的訪問讀寫是具備原子性的(long 和 double 的非原子性協(xié)定:對于 64 位的數(shù)據(jù),如 long 和 double,Java 內(nèi)存模型規(guī)范允許虛擬機將沒有被 volatile 修飾的 64 位數(shù)據(jù)的讀寫操作劃分為兩次 32 位的操作來進行,即允許虛擬機實現(xiàn)選擇可以不保證 64 位數(shù)據(jù)類型的 load、store、read 和 write 這四個操作的原子性,即如果有多個線程共享一個并未聲明為 volatile 的 long 或 double 類型的變量,并且同時對它們進行讀取和修改操作,那么某些線程可能會讀取到一個既非原值,也不是其他線程修改值的代表了“半個變量”的數(shù)值。
但由于目前各種平臺下的商用虛擬機幾乎都選擇把 64 位數(shù)據(jù)的讀寫操作作為原子操作來對待,因此在編寫代碼時一般也不需要將用到的 long 和 double 變量專門聲明為 volatile)。這些類型變量的讀、寫天然具有原子性,但類似于 “基本變量++” / “volatile++” 這種復(fù)合操作并沒有原子性。比如 i++;
Java 內(nèi)存模型解決的問題
JMM 最重要的的三點內(nèi)容:重排序、原子性、內(nèi)存可見性。那么 JMM 又是如何解決這些問題的呢?
JMM 抽象出主存儲器(Main Memory)和工作存儲器(Working Memory)兩種。
- 主存儲器是實例位置所在的區(qū)域,所有的實例都存在于主存儲器內(nèi)。比如,實例所擁有的字段即位于主存儲器內(nèi),主存儲器是所有的線程所共享的。
- 工作存儲器是線程所擁有的作業(yè)區(qū),每個線程都有其專用的工作存儲器。工作存儲器存有主存儲器中必要部分的拷貝,稱之為工作拷貝(Working Copy)。
線程是無法直接對主內(nèi)存進行操作的,如下圖所示,線程 A 想要和線程 B 通信,只能通過主存進行交換。
經(jīng)歷下面 2 個步驟:
1)線程 A 把本地內(nèi)存 A 中更新過的共享變量刷新到主內(nèi)存中去。
2)線程 B 到主內(nèi)存中去讀取線程 A 之前已更新過的共享變量。
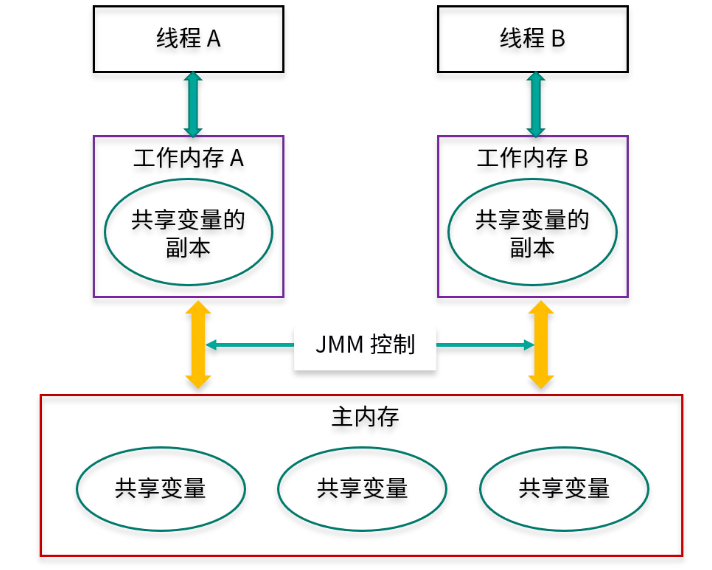
JMM內(nèi)存模型
從抽象角度看,JMM 定義了線程與主內(nèi)存之間的抽象關(guān)系:
- 線程之間的共享變量存儲在主內(nèi)存(Main Memory)中;
- 每個線程都有一個私有的本地內(nèi)存(Local Memory),本地內(nèi)存是 JMM 的一個抽象概念,并不真實存在,它涵蓋了緩存、寫緩沖區(qū)、寄存器以及其他的硬件和編譯器優(yōu)化。本地內(nèi)存中存儲了該線程以讀/寫共享變量的拷貝副本。
- 從更低的層次來說,主內(nèi)存就是硬件的內(nèi)存,而為了獲取更好的運行速度,虛擬機及硬件系統(tǒng)可能會讓工作內(nèi)存優(yōu)先存儲于寄存器和高速緩存中。
- Java 內(nèi)存模型中的線程的工作內(nèi)存(working memory)是 cpu 的寄存器和高速緩存的抽象描述。而 JVM 的靜態(tài)內(nèi)存儲模型(JVM 內(nèi)存模型)只是一種對內(nèi)存的物理劃分而已,它只局限在內(nèi)存,而且只局限在 JVM 的內(nèi)存。
八個操作
為了支持 JMM,Java 定義了 8 種原子操作(Action),用來控制主存與工作內(nèi)存之間的交互:
- read 讀取:作用于主內(nèi)存,將共享變量從主內(nèi)存?zhèn)鲃拥骄€程的工作內(nèi)存中,供后面的 load 動作使用。
- load 載入:作用于工作內(nèi)存,把 read 讀取的值放到工作內(nèi)存中的副本變量中。
- store 存儲:作用于工作內(nèi)存,把工作內(nèi)存中的變量傳送到主內(nèi)存中,為隨后的 write 操作使用。
- write 寫入:作用于主內(nèi)存,把 store 傳送值寫到主內(nèi)存的變量中。
- use 使用:作用于工作內(nèi)存,把工作內(nèi)存的值傳遞給執(zhí)行引擎,當虛擬機遇到一個需要使用這個變量的指令,就會執(zhí)行這個動作。
- assign 賦值:作用于工作內(nèi)存,把執(zhí)行引擎獲取到的值賦值給工作內(nèi)存中的變量,當虛擬機棧遇到給變量賦值的指令,執(zhí)行該操作。比如 int i = 1;
- lock(鎖定) 作用于主內(nèi)存,把變量標記為線程獨占狀態(tài)。
- unlock(解鎖) 作用于主內(nèi)存,它將釋放獨占狀態(tài)。
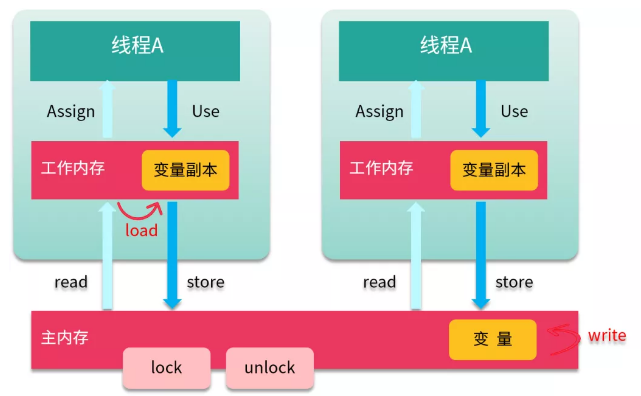
深入淺出Java虛擬機
如上圖所示,把一個變量數(shù)據(jù)從主內(nèi)存復(fù)制到工作內(nèi)存,要順序執(zhí)行 read 和 load;而把變量數(shù)據(jù)從工作內(nèi)存同步回主內(nèi)存,就要順序執(zhí)行 store 和 write 操作。
由于重排序、原子性、內(nèi)存可見性,帶來的不一致問題,JMM 通過 八個原子動作,內(nèi)存屏障保證了并發(fā)語義關(guān)鍵字的代碼能夠?qū)崿F(xiàn)對應(yīng)的安全并發(fā)訪問。
原子性保障
JMM 保證了 read、load、assign、use、store 和 write 六個操作具有原子性,可以認為除了 long 和 double 類型以外,對其他基本數(shù)據(jù)類型所對應(yīng)的內(nèi)存單元的訪問讀寫都是原子的。
但是當你想要更大范圍的的原子性保證就需要使用 ,就可以使用 lock 和 unlock 這兩個操作。
內(nèi)存屏障:內(nèi)存可見性與指令重排序
那 JMM 如何保障指令重排序排序,內(nèi)存可見性帶來并發(fā)訪問問題?
內(nèi)存屏障(Memory Barrier)用于控制在特定條件下的重排序和內(nèi)存可見性問題。JMM 內(nèi)存屏障可分為讀屏障和寫屏障,Java 的內(nèi)存屏障實際上也是上述兩種的組合,完成一系列的屏障和數(shù)據(jù)同步功能。Java 編譯器在生成字節(jié)碼時,會在執(zhí)行指令序列的適當位置插入內(nèi)存屏障來限制處理器的重排序。
組合如下:
- Load-Load Barriers:load1 的加載優(yōu)先于 load2 以及所有后續(xù)的加載指令,在指令前插入 Load Barrier,使得高速緩存中的數(shù)據(jù)失效,強制重新從駐內(nèi)存中加載數(shù)據(jù)。
- Load-Store Barriers:確保 load1 數(shù)據(jù)的加載先于 store2 以及之后的存儲指令刷新到內(nèi)存。
- Store-Store Barriers:確保 store1 數(shù)據(jù)對其他處理器可見,并且先于 store2 以及所有后續(xù)的存儲指令。在 Store Barrie 指令后插入 Store Barrie 會把寫入緩存的最新數(shù)據(jù)刷新到主內(nèi)存,使得其他線程可見。
- Store-Load Barriers:在 Load2 及后續(xù)所有讀取操作執(zhí)行前,保證 Store1 的寫入對所有處理器可見。這條內(nèi)存屏障指令是一個全能型的屏障,它同時具有其他 3 條屏障的效果,而且它的開銷也是四種屏障中最大的一個。
JMM 總結(jié)
JMM 是一個抽象概念,由于 CPU 多核多級緩存、為了優(yōu)化代碼會發(fā)生指令重排的原因,JMM 為了屏蔽細節(jié),定義了一套規(guī)范,保證最終的并發(fā)安全。它抽象出了工作內(nèi)存于主內(nèi)存的概念,并且通過八個原子操作以及內(nèi)存屏障保證了原子性、內(nèi)存可見性、防止指令重排,使得 volatile 能保證內(nèi)存可見性并防止指令重排、synchronised 保證了內(nèi)存可見性、原子性、防止指令重排導(dǎo)致的線程安全問題,JMM 是并發(fā)編程的基礎(chǔ)。
并且 JMM 為程序中所有的操作定義了一個關(guān)系,稱之為 「Happens-Before」原則,要保證執(zhí)行操作 B 的線程看到操作 A 的結(jié)果,那么 A、B 之間必須滿足「Happens-Before」關(guān)系,如果這兩個操作缺乏這個關(guān)系,那么 JVM 可以任意重排序。
Happens-Before
- 程序順序原則:如果程序操作 A 在操作 B 之前,那么多線程中的操作依然是 A 在 B 之前執(zhí)行。
- 監(jiān)視器鎖原則:在監(jiān)視器鎖上的解鎖操作必須在同一個監(jiān)視器上的加鎖操作之前執(zhí)行。
- volatile 變量原則:對 volatile 修飾的變量寫入操作必須在該變量的毒操作之前執(zhí)行。
- 線程啟動原則:在線程對 Tread.start 調(diào)用必須在該線程執(zhí)行任何操作之前執(zhí)行。
- 線程結(jié)束原則:線程的任何操作必須在其他線程檢測到該線程結(jié)束前執(zhí)行,或者從 Thread.join 中成功返回,或者在調(diào)用 Thread.isAlive 返回 false。
- 中斷原則:當一個線程在另一個線程上調(diào)用 interrupt 時,必須在被中斷線程檢測到 interrupt 調(diào)用之前執(zhí)行。
- 終結(jié)器規(guī)則:對象的構(gòu)造方法必須在啟動對象的終結(jié)器之前完成。
- 傳遞性:如果操作 A 在操作 B 之前執(zhí)行,并且操作 B 在操作 C 之前執(zhí)行,那么操作 A 必須在操作 C 之前執(zhí)行。
volatile
它是 Java 中的一個關(guān)鍵字,當一個變量是共享變量,同時被 volatile 修飾當值被更改的時候,其他線程再讀取該變量的時候可以保證能獲取到修改后的值,通過 JMM 屏蔽掉各種硬件和操作系統(tǒng)的內(nèi)存訪問差異 以及 CPU 多級緩存等導(dǎo)致的數(shù)據(jù)不一致問題。
需要注意的是,volatile 修飾的變量對所有線程是立即可見的,關(guān)鍵字本身就包含了禁止指令重排的語意,但是在非原子操作的并發(fā)讀寫中是不安全的,比如 i++ 操作一共分三步操作。
相比 synchronised Lock volatile 更加輕量級,不會發(fā)生上下文切換等開銷,接著跟著「碼哥字節(jié)」來分析下他的適用場景,以及錯誤使用場景。
volatile 的作用
- 保證可見性:Happens-before 關(guān)系中對于 volatile 是這樣描述的:對一個 volatile 變量的寫操作 happen-before 后面對該變量的讀操作。
這就代表了如果變量被 volatile 修飾,那么每次修改之后,接下來在讀取這個變量的時候一定能讀取到該變量最新的值。
- 禁止指令重排:先介紹一下 as-if-serial 語義:不管怎么重排序,(單線程)程序的執(zhí)行結(jié)果不會改變。在滿足 as-if-serial 語義的前提下,由于編譯器或 CPU 的優(yōu)化,代碼的實際執(zhí)行順序可能與我們編寫的順序是不同的,這在單線程的情況下是沒問題的,但是一旦引入多線程,這種亂序就可能會導(dǎo)致嚴重的線程安全問題。用了 volatile 關(guān)鍵字就可以在一定程度上禁止這種重排序。
volatile 正確用法
boolean 標志位
共享變量只有被賦值和讀取,沒有其他的多個復(fù)合操作(比如先讀數(shù)據(jù)再修改的復(fù)合運算 i++),我們就可以使用 volatile 代替 synchronized 或者代替原子類,因為賦值操作是原子性操作,而 volatile 同時保證了 可見性,所以是線程安全的。
如下經(jīng)典場景 volatile boolean flag,一旦 flag 發(fā)生變化,所有的線程立即可見。
- volatile boolean shutdownRequested;
- ...
- public void shutdown() {
- shutdownRequested = true;
- }
- public void doWork() {
- while (!shutdownRequested) {
- // do stuff
- }
- }
線程 1 執(zhí)行 doWork() 的過程中,可能有另外的線程 2 調(diào)用了 shutdown,線程 1 里嗎讀區(qū)到修改的值并停止執(zhí)行。
這種類型的狀態(tài)標記的一個公共特性是:通常只有一種狀態(tài)轉(zhuǎn)換;shutdownRequested 標志從false 轉(zhuǎn)換為true,然后程序停止。
雙重檢查(單例模式)
- class Singleton{
- private volatile static Singleton instance = null;
- private Singleton() {
- }
- public static Singleton getInstance() {
- if(instance==null) { // 1
- synchronized (Singleton.class) {
- if(instance==null)
- instance = new Singleton(); //2
- }
- }
- return instance;
- }
- }
在雙重檢查鎖模式中為什么需要使用 volatile 關(guān)鍵字?
假如 Instance 類變量是沒有用 volatile 關(guān)鍵字修飾的,會導(dǎo)致這樣一個問題:
在線程執(zhí)行到第 1 行的時候,代碼讀取到 instance 不為 null 時,instance 引用的對象有可能還沒有完成初始化。
造成這種現(xiàn)象主要的原因是創(chuàng)建對象不是原子操作以及指令重排序。
第二行代碼可以分解成以下幾步:
- memory = allocate(); // 1:分配對象的內(nèi)存空間
- ctorInstance(memory); // 2:初始化對象
- instance = memory; // 3:設(shè)置instance指向剛分配的內(nèi)存地址
根源在于代碼中的 2 和 3 之間,可能會被重排序。例如:
- memory = allocate(); // 1:分配對象的內(nèi)存空間
- instance = memory; // 3:設(shè)置instance指向剛分配的內(nèi)存地址
- // 注意,此時對象還沒有被初始化!
- ctorInstance(memory); // 2:初始化對象
這種重排序可能就會導(dǎo)致一個線程拿到的 instance 是非空的但是還沒初始化完全。
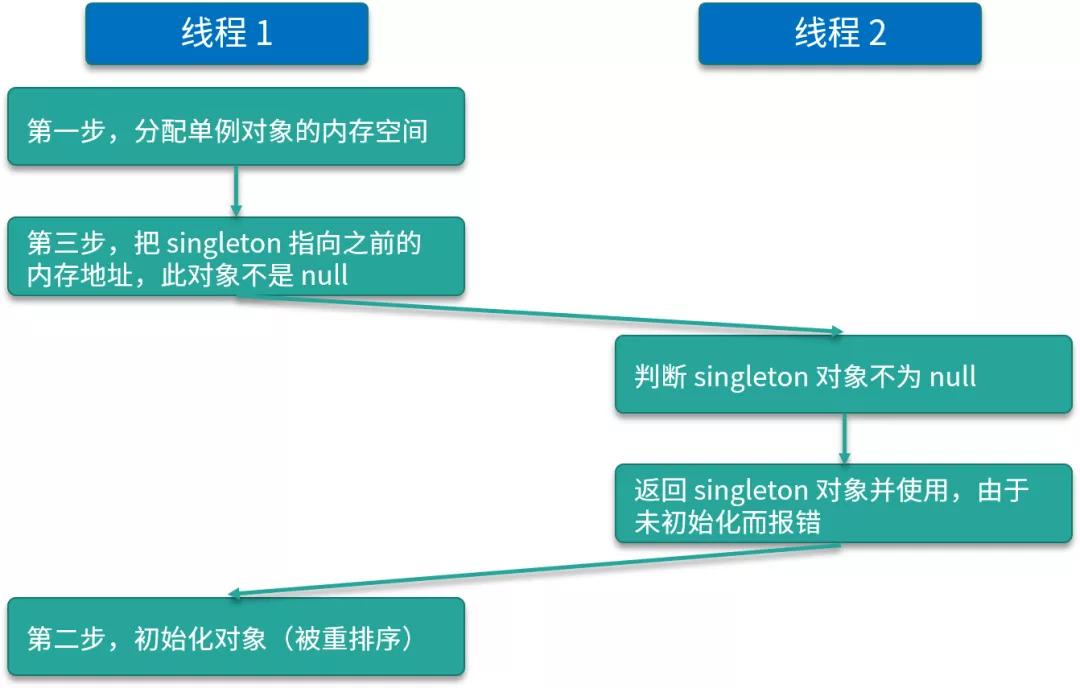
img
面試官可能會問你,“為什么要 double-check?去掉任何一次的 check 行不行?”
我們先來看第二次的 check,這時你需要考慮這樣一種情況,有兩個線程同時調(diào)用 getInstance 方法,由于 singleton 是空的 ,因此兩個線程都可以通過第一重的 if 判斷;然后由于鎖機制的存在,會有一個線程先進入同步語句,并進入第二重 if 判斷 ,而另外的一個線程就會在外面等待。
不過,當?shù)谝粋€線程執(zhí)行完 new Singleton() 語句后,就會退出 synchronized 保護的區(qū)域,這時如果沒有第二重 if (singleton == null) 判斷的話,那么第二個線程也會創(chuàng)建一個實例,此時就破壞了單例,這肯定是不行的。
而對于第一個 check 而言,如果去掉它,那么所有線程都會串行執(zhí)行,效率低下,所以兩個 check 都是需要保留的。
volatile 錯誤用法
volatile 不適合運用于需要保證原子性的場景,比如更新的時候需要依賴原來的值,而最典型的就是 a++ 的場景,我們僅靠 volatile 是不能保證 a++ 的線程安全的。代碼如下所示:
- public class DontVolatile implements Runnable {
- volatile int a;
- public static void main(String[] args) throws InterruptedException {
- Runnable r = new DontVolatile();
- Thread thread1 = new Thread(r);
- Thread thread2 = new Thread(r);
- thread1.start();
- thread2.start();
- thread1.join();
- thread2.join();
- System.out.println(((DontVolatile) r).a);
- }
- @Override
- public void run() {
- for (int i = 0; i < 1000; i++) {
- a++;
- }
- }
- }
最終的結(jié)果 a < 2000。
synchronised
互斥同步是常見的并發(fā)正確性保障方式。同步就好像在公司上班,廁所只有一個,現(xiàn)在一幫人同時想去「帶薪拉屎」占用廁所,為了保證廁所同一時刻只能一個員工使用,通過排隊互斥實現(xiàn)。
互斥是實現(xiàn)同步的一種手段,臨界區(qū)、互斥量(Mutex)和信號量(Semaphore)都是主要互斥方式。互斥是因,同步是果。
監(jiān)視器鎖(Monitor 另一個名字叫管程)本質(zhì)是依賴于底層的操作系統(tǒng)的 Mutex Lock(互斥鎖)來實現(xiàn)的。每個對象都存在著一個 monitor 與之關(guān)聯(lián),對象與其 monitor 之間的關(guān)系有存在多種實現(xiàn)方式,如 monitor 可以與對象一起創(chuàng)建銷毀或當線程試圖獲取對象鎖時自動生成,但當一個 monitor 被某個線程持有后,它便處于鎖定狀態(tài)。
mutex 的工作方式
在 Java 虛擬機 (HotSpot) 中,Monitor 是基于 C++ 實現(xiàn)的,由 ObjectMonitor 實現(xiàn)的, 幾個關(guān)鍵屬性:
- _owner:指向持有 ObjectMonitor 對象的線程
- _WaitSet:存放處于 wait 狀態(tài)的線程隊列
- _EntryList:存放處于等待鎖 block 狀態(tài)的線程隊列
- _recursions:鎖的重入次數(shù)
- count:用來記錄該線程獲取鎖的次數(shù)
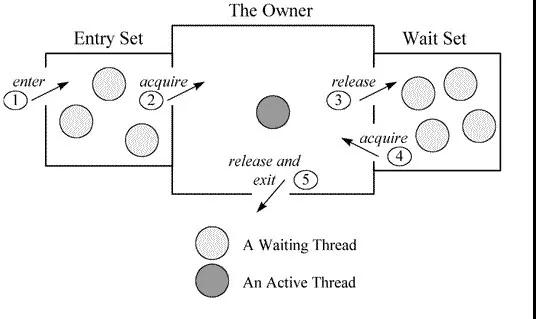
ObjectMonitor 中有兩個隊列,_WaitSet 和 _EntryList,用來保存 ObjectWaiter 對象列表( 每個等待鎖的線程都會被封裝成 ObjectWaiter 對象),_owner 指向持有 ObjectMonitor 對象的線程,當多個線程同時訪問一段同步代碼時,首先會進入 _EntryList 集合,當線程獲取到對象的 monitor 后進入 _Owner 區(qū)域并把 monitor 中的 owner 變量設(shè)置為當前線程同時 monitor 中的計數(shù)器 count 加 1。
若線程調(diào)用 wait() 方法,將釋放當前持有的 monitor,owner 變量恢復(fù)為 null,count 自減 1,同時該線程進入 WaitSet 集合中等待被喚醒。若當前線程執(zhí)行完畢也將釋放 monitor(鎖)并復(fù)位變量的值,以便其他線程進入獲取 monitor(鎖)。
在 Java 中,最基本的互斥同步手段就是 synchronised,經(jīng)過編譯之后會在同步塊前后分別插入 monitorenter, monitorexit 這兩個字節(jié)碼指令,而這兩個字節(jié)碼指令都需要提供一個 reference 類型的參數(shù)來指定要鎖定和解鎖的對象,具體表現(xiàn)如下所示:
- 在普通同步方法,reference 關(guān)聯(lián)和鎖定的是當前方法示例對象;
- 對于靜態(tài)同步方法,reference 關(guān)聯(lián)和鎖定的是當前類的 class 對象;
- 在同步方法塊中,reference 關(guān)聯(lián)和鎖定的是括號里制定的對象;
Java 對象頭
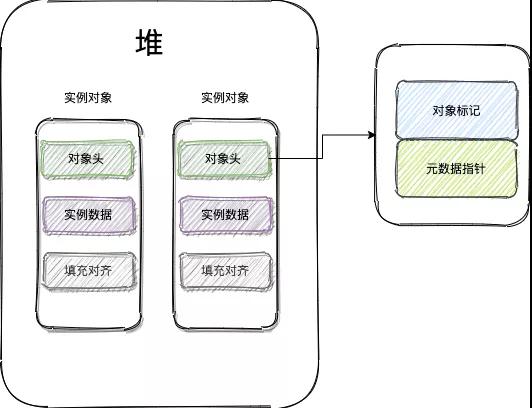
synchronised 用的鎖也存在 Java 對象頭里,在 JVM 中,對象在內(nèi)存的布局分為三塊區(qū)域:對象頭、實例數(shù)據(jù)、對其填充。
對象頭
- 對象頭:MarkWord 和 metadata,也就是圖中對象標記和元數(shù)據(jù)指針;
- 實例對象:存放類的屬性數(shù)據(jù),包括父類的屬性信息,如果是數(shù)組的實例部分還包括數(shù)組的長度,這部分內(nèi)存按 4 字節(jié)對齊;
- 填充數(shù)據(jù):由于虛擬機要求對象起始地址必須是 8 字節(jié)的整數(shù)倍。填充數(shù)據(jù)不是必須存在的,僅僅是為了字節(jié)對齊;
對象頭是 synchronised 實現(xiàn)的關(guān)鍵,使用的鎖對象是存儲在 Java 對象頭里的,jvm 中采用 2 個字寬(一個字寬代表 4 個字節(jié),一個字節(jié) 8bit)來存儲對象頭(如果對象是數(shù)組則會分配 3 個字寬,多出來的 1 個字寬記錄的是數(shù)組長度)。其主要結(jié)構(gòu)是由 Mark Word 和 Class Metadata Address 組成。
Mark word 記錄了對象和鎖有關(guān)的信息,當某個對象被 synchronized 關(guān)鍵字當成同步鎖時,那么圍繞這個鎖的一系列操作都和 Mark word 有關(guān)系。
- 虛擬機位數(shù) 對象結(jié)構(gòu) 說明
- 32/64bit Mark Word 存儲對象的 hashCode、鎖信息或分代年齡或 GC 標志等信息
- 32/64bit Class Metadata Address 類型指針指向?qū)ο蟮念愒獢?shù)據(jù),JVM 通過這個指針確定該對象是哪個類的實例。
- 32/64bit Array length 數(shù)組的長度(如果當前對象是數(shù)組)
其中 Mark Word 在默認情況下存儲著對象的 HashCode、分代年齡、鎖標記位等。Mark Word 在不同的鎖狀態(tài)下存儲的內(nèi)容不同,在 32 位 JVM 中默認狀態(tài)為下:
| 鎖狀態(tài) | 25 bit | 4 bit | 1 bit 是否是偏向鎖 | 2 bit 鎖標志位 |
|---|---|---|---|---|
| 無鎖 | 對象 HashCode | 對象分代年齡 | 0 | 01 |
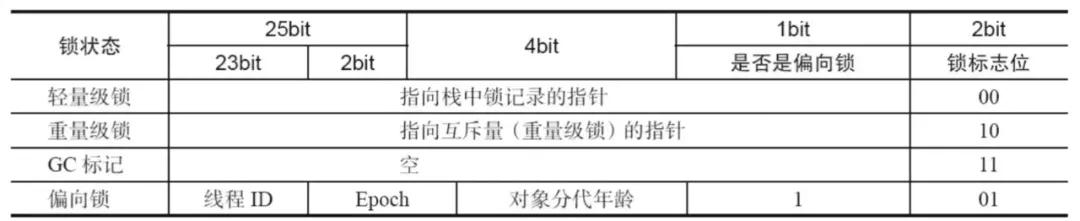
在運行過程中,Mark Word 存儲的數(shù)據(jù)會隨著鎖標志位的變化而變化,可能出現(xiàn)如下 4 種數(shù)據(jù):
鎖標志位的表示意義:
- 鎖標識 lock=00 表示輕量級鎖
- 鎖標識 lock=10 表示重量級鎖
- 偏向鎖標識 biased_lock=1 表示偏向鎖
- 偏向鎖標識 biased_lock=0 且鎖標識=01 表示無鎖狀態(tài)
到目前為止,我們再總結(jié)一下前面的內(nèi)容,synchronized(lock) 中的 lock 可以用 Java 中任何一個對象來表示,而鎖標識的存儲實際上就是在 lock 這個對象中的對象頭內(nèi)。
Monitor(監(jiān)視器鎖)本質(zhì)是依賴于底層的操作系統(tǒng)的 Mutex Lock(互斥鎖)來實現(xiàn)的。Mutex Lock 的切換需要從用戶態(tài)轉(zhuǎn)換到核心態(tài)中,因此狀態(tài)轉(zhuǎn)換需要耗費很多的處理器時間。所以 synchronized 是 Java 語言中的一個重量級操作。
為什么任意一個 Java 對象都能成為鎖對象呢?
Java 中的每個對象都派生自 Object 類,而每個 Java Object 在 JVM 內(nèi)部都有一個 native 的 C++對象 oop/oopDesc 進行對應(yīng)。其次,線程在獲取鎖的時候,實際上就是獲得一個監(jiān)視器對象(monitor) ,monitor 可以認為是一個同步對象,所有的 Java 對象是天生攜帶 monitor。
多個線程訪問同步代碼塊時,相當于去爭搶對象監(jiān)視器修改對象中的鎖標識, ObjectMonitor 這個對象和線程爭搶鎖的邏輯有密切的關(guān)系。
總結(jié)討論
JMM 總結(jié)
JVM 內(nèi)存結(jié)構(gòu)和 Java 虛擬機的運行時區(qū)域有關(guān);
Java 內(nèi)存模型和 Java 的并發(fā)編程有關(guān)。JMM 是并發(fā)編程的基礎(chǔ),它屏蔽了硬件和系統(tǒng)造成的內(nèi)存訪問差異,保證了 一致性、原子性、并禁止指令重排保證了安全訪問。通過總線嗅探機制使得緩存數(shù)據(jù)失效, 保證 volatile 內(nèi)存可見性。
JMM 是一個抽象概念,由于 CPU 多核多級緩存、為了優(yōu)化代碼會發(fā)生指令重排的原因,JMM 為了屏蔽細節(jié),定義了一套規(guī)范,保證最終的并發(fā)安全。它抽象出了工作內(nèi)存于主內(nèi)存的概念,并且通過八個原子操作以及內(nèi)存屏障保證了原子性、內(nèi)存可見性、防止指令重排,使得 volatile 能保證內(nèi)存可見性并防止指令重排、synchronised 保證了內(nèi)存可見性、原子性、防止指令重排導(dǎo)致的線程安全問題,JMM 是并發(fā)編程的基礎(chǔ)。
synchronized 原理
提到了鎖的幾個概念,偏向鎖、輕量級鎖、重量級鎖。在 JDK1.6 之前,synchronized 是一個重量級鎖,性能比較差。從 JDK1.6 開始,為了減少獲得鎖和釋放鎖帶來的性能消耗,synchronized 進行了優(yōu)化,引入了偏向鎖和輕量級鎖的概念。
所以從 JDK1.6 開始,鎖一共會有四種狀態(tài),鎖的狀態(tài)根據(jù)競爭激烈程度從低到高分別是: 無鎖狀態(tài)->偏向鎖狀態(tài)->輕量級鎖狀態(tài)->重量級鎖狀態(tài)。這幾個狀態(tài)會隨著鎖競爭的情況逐步升級。為了提高獲得鎖和釋放鎖的效率,鎖可以升級但是不能降級。
本文轉(zhuǎn)載自微信公眾號「碼哥字節(jié)」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系碼哥字節(jié)公眾號。