開源“Chaperone”:Uber是如何對Kafka進行端到端審計的
隨著Uber業務規模不斷增長,我們的系統也在持續不斷地產生更多的事件、服務間的消息和日志。這些數據在得到處理之前需要經過Kafka。那么我們的平臺是如何實時地對這些數據進行審計的呢?
為了監控Kafka數據管道的健康狀況并對流經Kafka的每個消息進行審計,我們完全依賴我們的審計系統Chaperone。Chaperone自2016年1月成為Uber的跨數據中心基礎設施以來,每天處理萬億的消息量。下面我們會介紹它的工作原理,并說明我們為什么會構建Chaperone。
Uber的Kafka數據管道概覽
Uber的服務以雙活的模式運行在多個數據中心。Apache Kafka和uReplicator是連接Uber生態系統各個部分的消息總線。
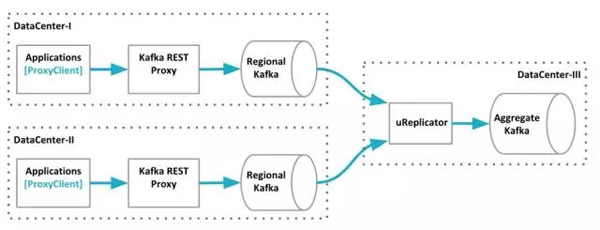
截止2016年11月份,Uber的Kafka數據管道概覽。數據從兩個數據中心聚合到一個Kafka集群上。
要讓Uber的Kafka對下游的消費者做出即時響應是很困難的。為了保證吞吐量,我們盡可能地使用批次,并嚴重依賴異步處理。服務使用自家的客戶端把消息發布到Kafka代理,代理把這些消息分批轉發到本地的Kafka集群上。有些Kafka的主題會被本地集群直接消費,而剩下的大部分會跟來自其他數據中心的數據一起被組合到一個聚合Kafka集群上,我們使用uReplicator來完成這種面向大規模流或批處理的工作。
Uber的Kafka數據管道可以分為四層,它們跨越了多個數據中心。Kafka代理和它的客戶端分別是第二層和***層。它們被作為消息進入第三層的網關,也就是每個數據中心的本地Kafka集群。本地集群的部分數據會被復制到聚合集群,也就是數據管道的***一層。
Kafka數據管道的數據都會經過分批和確認(發送確認):

Kafka數據管道的數據流經的路徑概覽。
Uber的數據從代理客戶端流向Kafka需要經過幾個階段:
- 應用程序通過調用代理客戶端的produce方法向代理客戶端發送消息。
- 代理客戶端把收到的消息放到客戶端的緩沖區中,并讓方法調用返回。
- 代理客戶端把緩沖區里的消息進行分批并發送到代理服務器端。
- 代理服務器把消息放到生產者緩沖區并對代理客戶端進行確認。這時,消息批次已經被分好區,并根據不同的主題名稱放在了相應的緩沖區里。
- 代理服務器對緩沖區里的消息進行分批并發送到本地Kafka服務器上。
- 本地Kafka服務器把消息追加到本地日志并對代理服務器進行確認(acks=1)。
- uReplicator從本地Kafka服務器獲取消息并發送到聚合服務器上。
- 聚合服務器把消息追加到本地日志并對uReplicator進行確認(acks=1)。
我們為了讓Kafka支持高吞吐量,做出了一些權衡。數以千計的微服務使用Kafka來處理成百上千的并發業務流量(而且還在持續增長)會帶來潛在的問題。Chaperone的目標是在數據流經數據管道的每個階段,能夠抓住每個消息,統計一定時間段內的數據量,并盡早準確地檢測出數據的丟失、延遲和重復情況。
Chaperone概覽
Chaperone由四個組件組成:AuditLibrary、ChaperoneService、ChaperoneCollector和WebService。
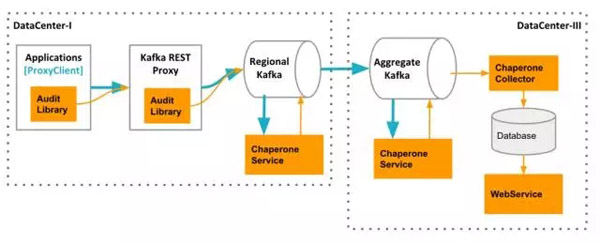
Chaperone架構:AuditLibrary、ChaperoneService、ChaperoneCollector和WebService,它們會收集數據,并進行相關計算,自動檢測出丟失和延遲的數據,并展示審計結果。
AuditLibrary實現了審計算法,它會定時收集并打印統計時間窗。這個庫被其它三個組件所依賴。它的輸出模塊是可插拔的(可以使用Kafka、HTTP等)。在代理客戶端,審計度量指標被發送到Kafka代理。而在其它層,度量指標直接被發送到專門的Kafka主題上。
審計算法是AuditLibrary的核心,Chaperone使用10分鐘的滾動時間窗來持續不斷地從每個主題收集消息。消息里的事件時間戳被用來決定該消息應該被放到哪個時間窗里。對于同一個時間窗內的消息,Chaperone會計算它們的數量和p99延遲。Chaperone會定時把每個時間窗的統計信息包裝成審計消息發送到可插拔的后端,它們可能是Kafka代理或者之前提到的Kafka服務器。
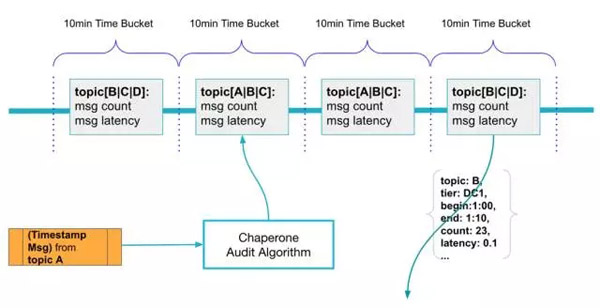
Chaperone根據消息的事件時間戳把消息聚合到滾動時間窗內。
審計消息里的tier字段很重要,通過它可以知道審計是在哪里發生的,也可以知道消息是否到達了某一個地方。通過比較一定時間段內不同層之間的消息數量,我們可以知道這段時間內所生成的消息是否被成功送達。
ChaperoneService是工作負載***的一個組件,而且總是處在饑餓的狀態。它消費Kafka的每一個消息并記錄時間戳。ChaperoneService是基于uReplicator的HelixKafkaConsumer構建的,這個消費者組件已經被證明比Kafka自帶的消費者組件(Kafka 0.8.2)更可靠,也更好用。ChaperoneService通過定時向特定的Kafka主題生成審計消息來記錄狀態。
ChaperoneCollector監聽特定的Kafka主題,并獲取所有的審計消息,然后把它們存到數據庫。同時,它還會生產多個儀表盤:
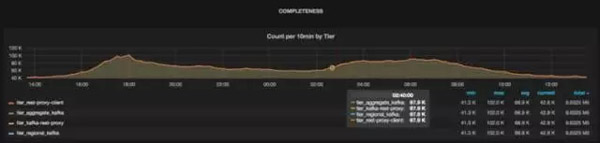
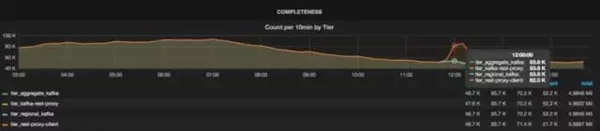
Chaperone創建的儀表盤,從上面我們看出數據的丟失情況。
從上圖可以看出每個層的主題消息總量,它們是通過聚合所有數據中心的消息得出的。如果沒有數據丟失,所有的線會***地重合起來。如果層之間有數據丟失,那么線與線之間會出現裂縫。例如,從下圖可以看出,Kafka代理丟掉了一些消息,不過在之后的層里沒有消息丟失。從儀表盤可以很容易地看出數據丟失的時間窗,從而可以采取相應的行動。
從儀表盤上還能看出消息的延遲情況,借此我們就能夠知道消息的及時性以及它們是否在某些層發生了傳輸延遲。用戶可以直接從這一個儀表盤上看出主題的健康狀況,而無需去查看Kafka服務器或uReplicator的儀表盤:
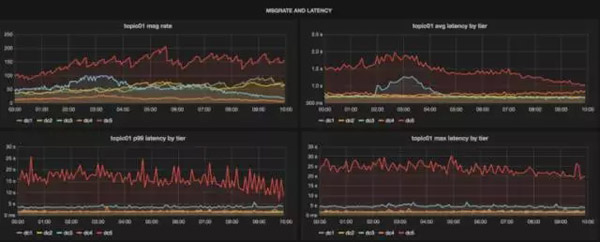
Chaperone提供一站式的儀表盤來查看每個數據中心的主題狀態。
***,WebService提供了REST接口來查詢Chaperone收集到的度量指標。通過這些接口,我們可以準確地計算出數據丟失的數量。在知道了數據丟失的時間窗后,我們可以從Chaperone查到確切的數量:
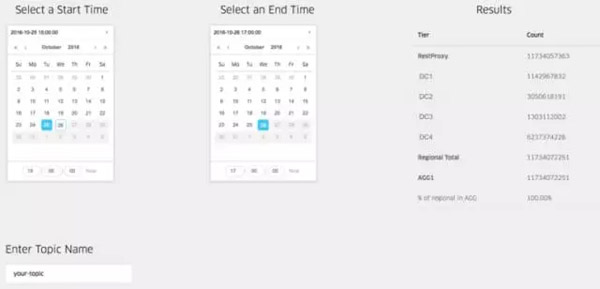
Chaperone的Web界面。
Chaperone的兩個設計目標
在設計Chaperone時,為了能夠做到準確的審計,我們把注意力集中在兩個必須完成的任務上:
1)每個消息只被審計一次
為了確保每個消息只被審計一次,ChaperoneService使用了預寫式日志(WAL)。ChaperoneService每次在觸發Kafka審計消息時,會往審計消息里添加一個UUID。這個帶有相關偏移量的消息在發送到Kafka之前被保存在WAL里。在得到Kafka的確認之后,WAL里的消息被標記為已完成。如果ChaperoneService崩潰,在重啟后它可以重新發送WAL里未被標記的審計消息,并定位到最近一次的審計偏移量,然后繼續消費。WAL確保了每個Kafka消息只被審計一次,而且每個審計消息至少會被發送一次。
接下來,ChaperoneCollector使用ChaperoneService之前添加過的UUID來移除重復消息。有了UUID和WAL,我們可以確保審計的一次性。在代理客戶端和服務器端難以實現一次性保證,因為這樣會給它們帶來額外的開銷。我們依賴它們的優雅關閉操作,這樣它們的狀態才會被沖刷出去。
2)在層間使用一致性的時間戳
因為Chaperone可以在多個層里看到相同的Kafka消息,所以為消息內嵌時間戳是很有必要的。如果沒有這些時間戳,在計數時會發生時間錯位。在Uber,大部分發送到Kafka的數據要么使用avro風格的schema編碼,要么使用JSON格式。對于使用schema編碼的消息,可以直接獲取時間戳。而對于JSON格式的消息,需要對JSON數據進行解碼才能拿到時間戳。為了加快這個過程,我們實現了一個基于流的JSON消息解析器,這個解析器無需預先解碼整個消息就可以掃描到時間戳。這個解析器用在ChaperoneService里是很高效的,不過對代理客戶端和服務器來說仍然需要付出很高代價。所以在這兩個層里,我們使用的是消息的處理時間戳。因為時間戳的不一致造成的層間計數差異可能會觸發錯誤的數據丟失警告。我們正在著手解決時間戳不一致問題,之后也會把解決方案公布出來。
Chaperone在Uber的兩大用途
1. 檢測數據丟失
在Chaperone之前,數據丟失的***個征兆來自數據消費者,他們會出來抱怨數據的丟失情況。但是等他們出來抱怨已經為時已晚,而且我們無法知道是數據管道的哪一部分出現了問題。有了Chaperone之后,我們創建了一個用于檢測丟失數據的作業,它會定時地從Chaperone拉取度量指標,并在層間的消息數量出現不一致時發出告警。告警包含了Kafka數據管道端到端的信息,從中可以看出那些管道組件的度量指標無法告訴我們的問題。檢測作業會自動地發現新主題,并且你可以根據數據的重要性配置不同的告警規則和閾值。數據丟失的通知會通過多種通道發送出去,比如頁式調度系統、企業聊天系統或者郵件系統,總之會很快地通知到你。
2. 在Kafka里通過偏移量之外的方式讀取數據
我們生產環境的大部分集群仍然在使用Kafka 0.8.x,這一版本的Kafka對從時間戳到偏移量的索引沒有提供原生支持。于是我們在Chaperone里自己構建了這樣的索引。這種索引可以用來做基于時間區間的查詢,所以我們不僅限于使用Kafka的偏移量來讀取數據,我們可以使用Chaperone提供的時間戳來讀取數據。
Kafka對數據的保留是有期限的,不過我們對消息進行了備份,并把消息的偏移量也原封不動地保存起來。借助Chaperone提供的索引,用戶可以基于時間區間讀取這些備份數據,而不是僅僅局限于Kafka現存的數據,而且使用的訪問接口跟Kafka是一樣的。有了這個特性,Kafka用戶可以通過檢查任意時間段里的消息來對他們的服務進行問題診斷,在必要時可以回填消息。當下游系統的審計結果跟Chaperone出現不一致,我們可以把一些特定的消息導出來進行比較,以便定位問題的根源。
總結
我們構建了Chaperone來解決以下問題:
- 是否有數據丟失?如果是,那么丟失了多少數據?它們是在數據管道的哪個地方丟失的?
- 端到端的延遲是多少?如果有消息延遲,是從哪里開始的?
- 是否有數據重復?
Chaperone不僅僅告訴我們系統的健康情況,它還告訴我們是否有數據丟失。例如,在Kafka服務器返回非預期的錯誤時,uReplicator會出現死循環,而此時uReplicator和Kafka都不會觸發任何告警,不過我們的檢測作業會很快地把問題暴露出來。
如果你想更多地了解Chaperone,可以自己去探究。我們已經把Chaperone開源,它的源代碼放在Github上。