為什么不管大廠還是小廠,面試總是要提到 HashMap?
本文轉載自微信公眾號「Java極客技術」,作者鴨血粉絲。轉載本文請聯系Java極客技術公眾號。
Hello,大家好,我是阿粉~
不知道大家最近有沒有刷過 Java 面試題,有沒有發現幾乎所有面試題或多或少都會包括 HashMap 面試題。
為什么 Java 中小小的一個 HashMap,值得在面試中被反復提到?
阿粉認為是因為 HashMap 太重要了,大家回看一下自己的業務代碼,是不是都有在使用 HashMap ?
即使你真的沒有直接使用,但是你使用的一些中間件,或者一些開源框架,這些代碼肯定使用 HashMap 完成相關邏輯。
而 HashMap 包含很多核心知識點,從這些知識點可以考察出一個面試者基本知識掌握情況。
其實就算沒有面試,我們也應該或多乎或少去了解 一下 HashMap 基本實現原理。因為如果使用 HashMap 不當,很容易寫出一連串 Bug,而且可能還不容易排查。
HashMap 面試題網上很多,但是其實怎么問他都離不開這些核心知識點。
這就像我們以前解答數學題一樣,背后答案都是圍繞核心數學公式。
所以我們只要掌握 HashMap 核心知識點,就不用再怕面試中再問到。
這里阿粉整理一下,HashMap 涉及核心知識點如下:
- 底層數據結構
- Hash 算法
- 尋址算法
- 擴容
- 多線程并發
底層數據結構
數據結構與算法是最近面試越來越注重考查的一方面,尤其是對于校招來講,這一塊百分百會涉及。
而 HashMap 底層結構一下子就涉及三大數據結構,數組、鏈表、紅黑樹。
數組
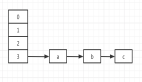
HashMap 中元素實際保存在一個個 Node 中,而Node 類保存在底層數組中。
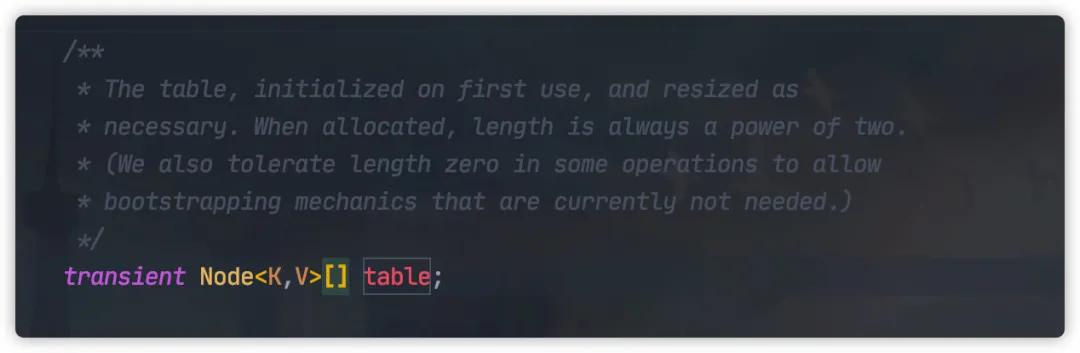
以上代碼來自 JDK1.8,JDK1.7 為 Entry 類型。
實際上 Node 為 Entry 類的子類
鏈表
我們觀察一下Node 類的數據結構,
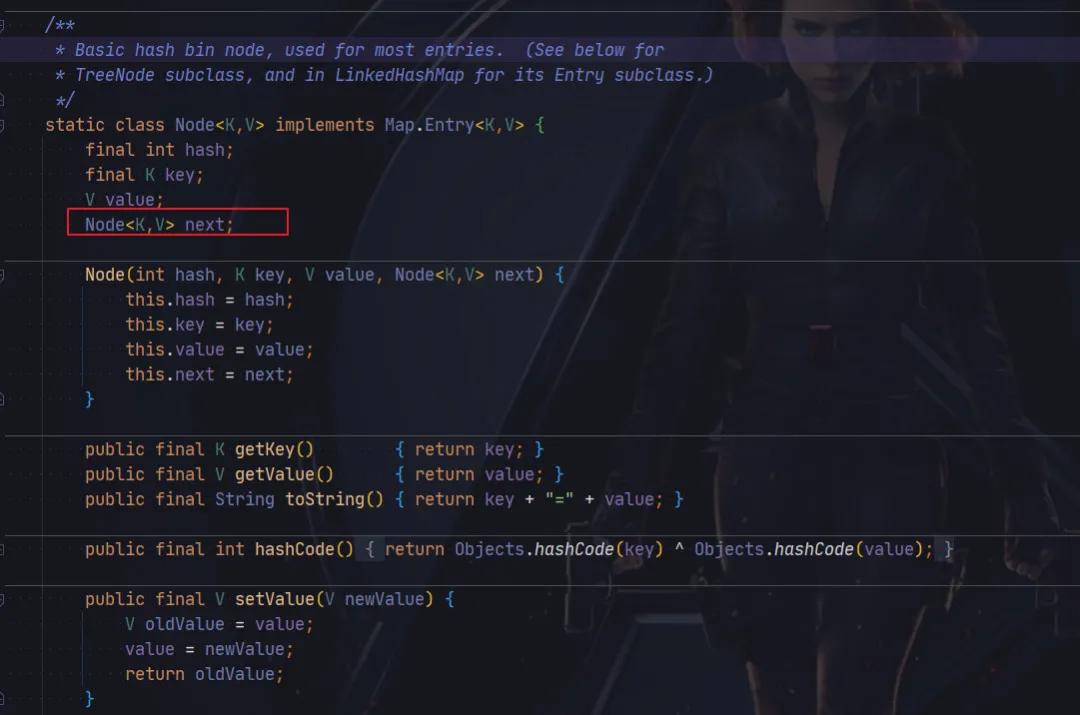
可以發現 Node 類中有一個 next 字段,用于保存下一個 Node 元素,通過這種方式就形成一個單向的鏈表。
那為什么需要鏈表那?
這可能與下面說道 Hash算法有關,因為再好的 Hash 算法,都有可能導致不同輸入產生相同的輸出。
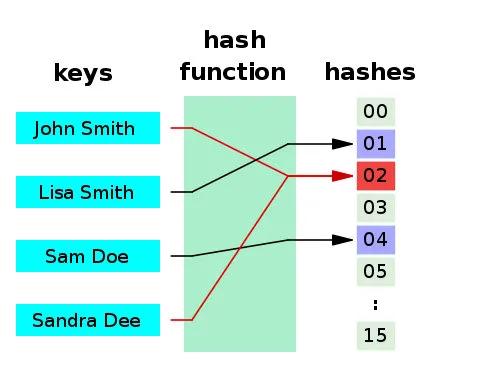
來自:阮一峰的博客
如果不同的輸入得到了同一個哈希值,就發生了"哈希碰撞"(collision)。
哈希碰撞解決辦法很多,這里 HashMap 就采用拉鏈法,即使用一個鏈表保存碰撞的元素的。
其他辦法還有:
- 線行探查法
- 平方探查法
- 雙散列函數探查法
紅黑樹
由于鏈表查找元素復雜度為 O(N),如果 HashMap 哈希碰撞很厲害,從而導致大部分元素落在同一個鏈表上,這就會導致 HashMap 性能會下降,極端一點 HashMap O(1) 查詢復雜度退化成 O(N)的復雜度。
JDK1.8 中引入紅黑樹數據結構,當鏈表元素等于 8 時,鏈表轉化為紅黑樹,這樣查找復雜度就可以為 O(logn)。
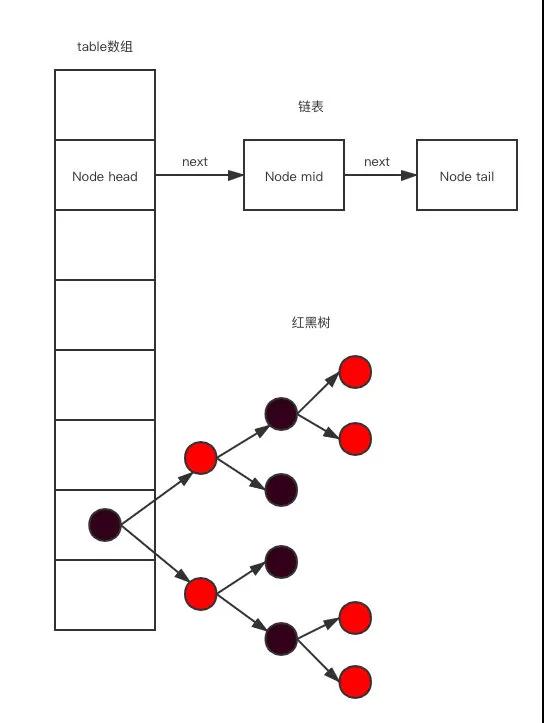
圖片來自網絡
那為什么使用紅黑樹,而不是使用其他二叉樹,?
這是因為紅黑樹對于新增與刪除的操作也都能保持O(logn) 新增,這樣就完美兼顧了查找與新增性能。
面試題
看完這個知識點,其實可以提很多相關數據結構面試題,比如數組與鏈表區別。
所以看完這個,我們就需要去整理學習數據結構相關知識。
Hash 算法
這里我們僅僅介紹一下 JDK1.8 Hash 算法。

它使用 key 的 hashcode 高低 16 位異或的方式計算產生。
通過這種方式,在后面尋址算法計算時候,降低碰撞的可能性。
尋址算法
當我們計算得到 Hash 值以后,我們還需要計算這個 Hash 值在數組中的位置。
簡單的方式我們可以直接使用求模的方式定位,比如
- hash=1000
- table.size=16
- n=hash%table.size=8
但是 HashMap 采用的是另外一種更為精妙的算法:
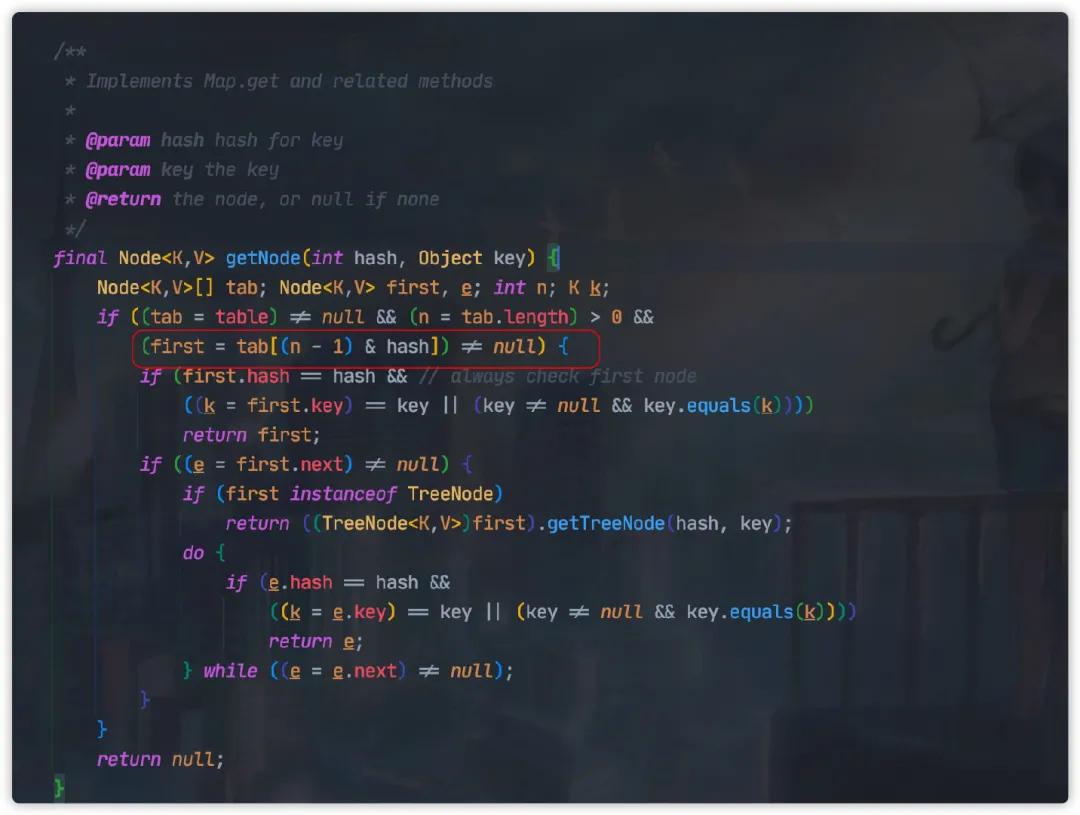
這種方式等同求模法,但是計算性能會更好,但是這里我們需要注意了,這種方式前提為 n 也就是數組的長度必須為 2 的冪次方。
這里阿粉就不具體計算了,感興趣的同學可以網上查找一下推導過程
面試題
為什么 HashMap 擴容都是 2 的冪次方?
看完這個,大家這個面試題了吧。
擴容
當 HashMap 元素過多時,這時必須擴容,從而保證 HashMap 查找性能。
擴容過程,我們就需要涉及以下幾個核心參數:
- 擴展因子:loadFactor
- 實際元素數量:size
- 數組長度:capacity
- 擴容的閾值大小:threshold=capacity*loadFactor
當 HashMap 中元素數量大于 threshold,HashMap 就會開始擴容。
JDK1.7 擴容的時候,HashMap 每個元素將會重新計算 Hash 值,然后使用尋址算法,查找新的位置。
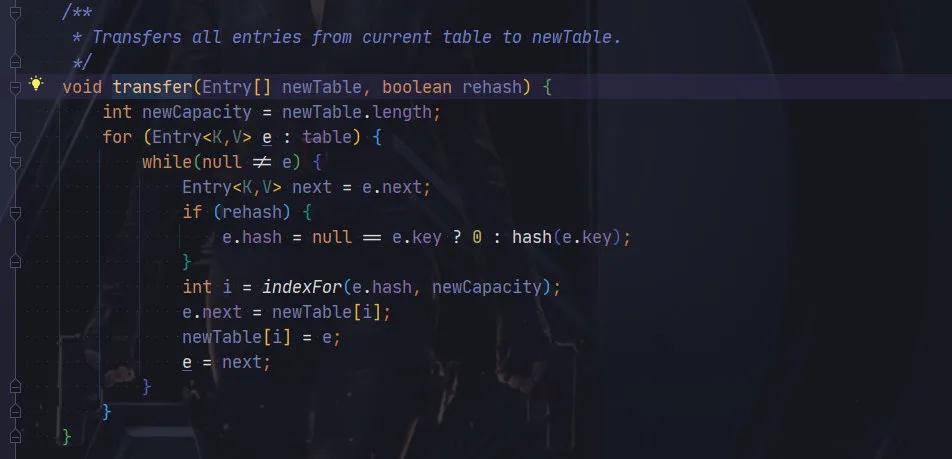
在 JDk1.8 中,采用了一種更精妙的算法:
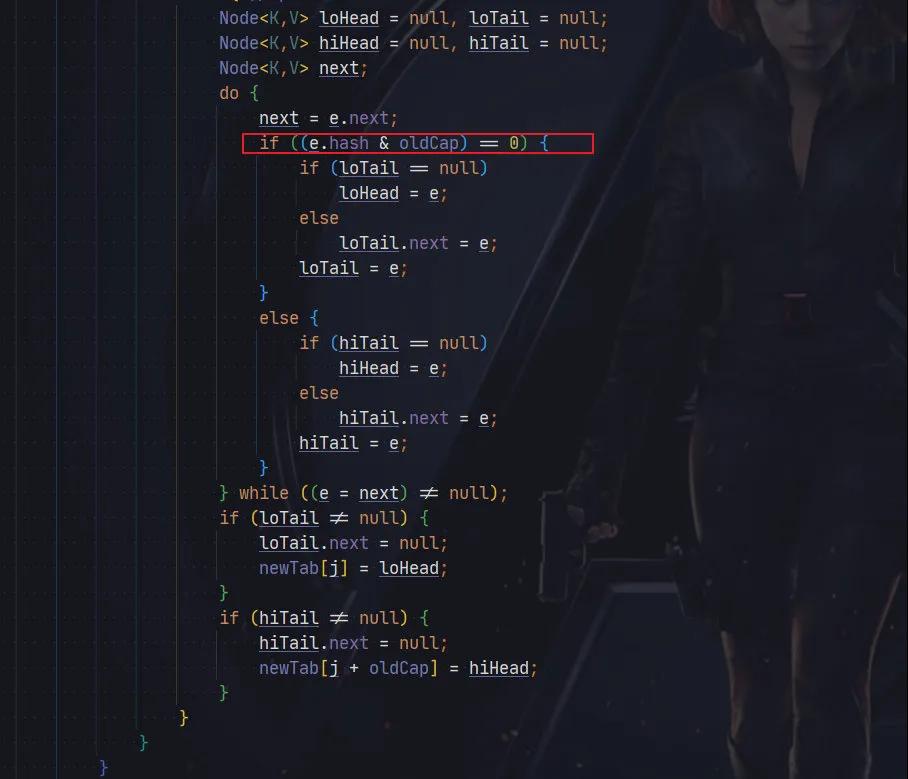
其使用 e.hash & oldCap == 0, 元素要么放在原位置,要么放在原位置+原數組長度。
這里解釋起來比較復雜,這里阿粉就不再詳細展開,感興趣同學可以自行查找一下相關文章。
面試題
問:加載因子為什么 0.75,而不是其他值?
答:可以說是一個經過考量的經驗值。加載因子涉及擴容,下次擴容的閾值=數組桶的大小*加載因子,如果加載因子太小,這就會導致閾值太小,這就會導致比較容易發生擴容。
如果加載因子太大,那就會導致閾值太大,可能沖突會很多,導致查找效率下降。
多線程并發
好了,終于到到了最后一個知識點,多線程并發。
HashMap 在多線程并發情況下會怎么樣?
這里我們需要分 JDK1.7 與 JDK1.8 來講。
在 JDK1.7 中,由于擴容遷移時采用了頭插法,從而將會導致產生死鏈。
- void transfer(Entry[] newTable, boolean rehash) {
- int newCapacity = newTable.length;
- for (Entry<K,V> e : table) {
- while(null != e) {
- Entry<K,V> next = e.next;
- if (rehash) {
- e.hash = null == e.key ? 0 : hash(e.key);
- }
- int i = indexFor(e.hash, newCapacity);
- // 以下代碼導致死鏈的產生
- e.next = newTable[i];
- // 插入到鏈表頭結點,
- newTable[i] = e;
- e = next;
- }
- }
- }
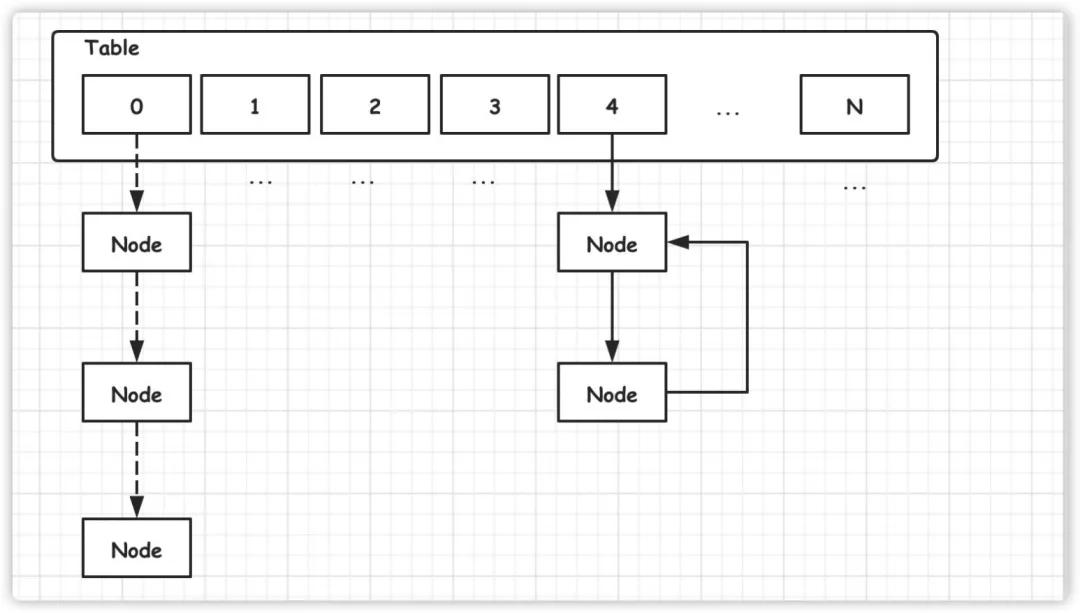
而一旦產生死鏈,極有可能導致程序陷入死循環,從而導致 CPU 使用率上升。
JDK1.8 中使用尾插法,從而解決這個問題,但是依然還會存在相關問題。
比如:
并發賦值時被覆蓋
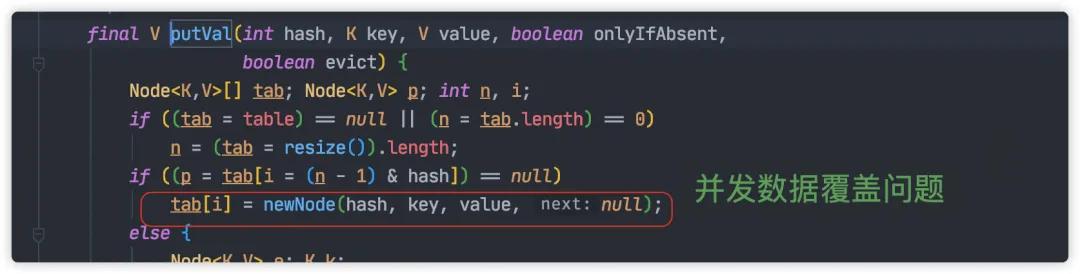
并發的情況下,一個線程的賦值可能被另一個線程覆蓋,這就導致對象的丟失。
size 計算問題

img
每次元素增加完成之后,size 將會加 1。這里采用 ++i方法,天然的并發不安全。
面試題
關于并發,這里可以提到很多面試題。
可以是線程相關的,也可以是并發編程相關。
不過如果面試官既然已經提到這里,我們可以試著將他引導他如何解決 HashMap 并發編程的問題,從而我們下面開始回答出 ConcurrentHashMap。
最后
經過上面一頓分析,我們可以看到小小一個 HashMap 其實涉及到很多知識點,這些點拆開來講就可以變成一道道面試題。
另外這些點在平常編程的過程中也要特別注意,一不小心我們就會踩一個大坑。
今天這篇文章主要提及一下,HashMap 涉及的知識點,所以阿粉沒有過多深入的分析,這里感興趣的同學可以在深入學習準備一下。