幾種緩存更新的設計方法,值得一看
前言
Hello,everybody,我是asong,今天我依然聊一聊緩存,不過今天我們聊的不是面試了,我們一起來看一看我們在系統中緩存更新的設計,因自己經驗有限,所以這些緩存設計來源于網上,我只是在這里總結一下,有什么不對的歡迎指出。
緩存預熱 To solve 緩存冷啟動
什么是緩存預熱呢?我們都知道平常在跑步前都要熱身,可以預防肌肉拉傷等一系例的好處。所以緩存預熱具有同樣的道理,我們的新系統上線后,我們可以將相關的緩存數據直接加載到緩存系統。這樣可以避免在用戶請求的時候,先去查詢數據庫,然后再將數據緩存的問題。用戶可以直接查詢事先已被預熱的緩存數據。其實緩存預熱是為了解決緩存冷啟動問題,我們新系統上線后,redis集群啟動后,沒有任何的緩存數據,這就是redis的冷啟動。
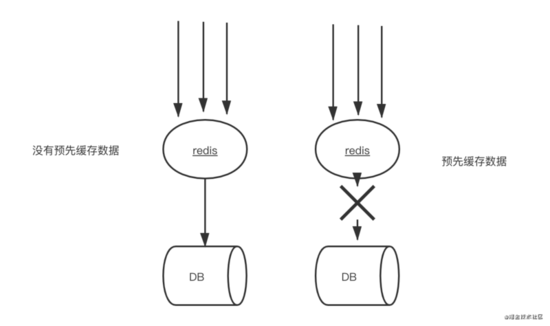
如上圖所示,如果不進行預熱,那么Redis初識狀態數據為空,系統上線初期,對于高并發的流量,都會訪問到數據庫中,對數據庫造成流量的壓力。
如何解決
現在我們已經知道會有緩存預熱這個問題,那么就要想一下對策咯。可以分析出以下兩點:
- 需要統計訪問頻度較高的熱點數據
- 使用LRU數據刪除策略,構建數據留存隊列
所以我們可以設計一個如下方案:
- 首先,通過 nginx + lua 的方式,把訪問流量數據上報到 Kafka,也可以是其它的 mq 隊列。
- 然后使用實時計算框架(如 storm 、spark streaming、flume)從 kafka 中消費訪問流量數據,實時計算出訪問頻率高的數據,這里統計出來的可能只會有編號信息,如商品編號或博客編號等。
- 最后,根據編號從 mysql 數據庫中查詢出具體的信息,寫入 redis,開始提供服務。
緩存更新的幾種設計
1. 先刪除緩存,在更新數據庫
雖然這是一種錯誤方法,但是這種設計也是屬于緩存更新的一種方法,所以大家還是要知道為什么不可以這么做。還是那句話:知其所以然嘛。
這種方法就是在更新數據庫時,先刪除緩存,然后在更新數據庫,而后續的操作會把數據在裝載到緩存中,這種邏輯在并發時就會先臟數據,看如下圖:
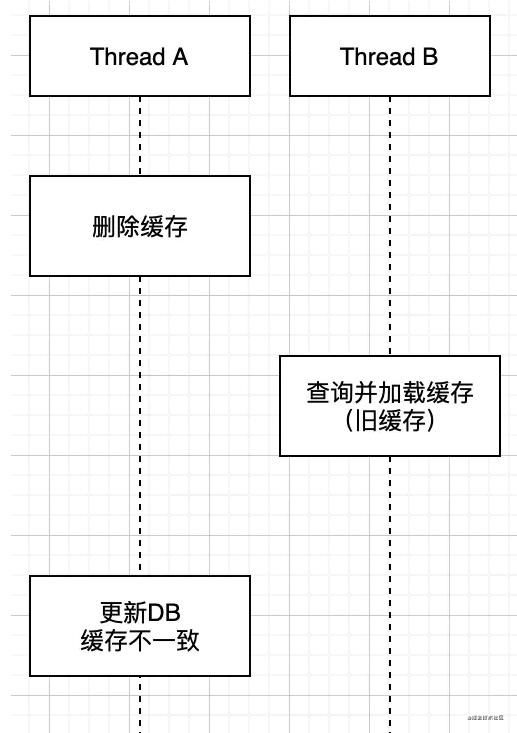
我們解釋一下上圖的操作,兩個并發操作,一個是更新操作,另一個是查詢操作,更新操作刪除緩存后,查詢操作沒有命中緩存,先把老數據讀出來后放到緩存中,然后更新操作更新了數據庫。于是,在緩存中的數據還是老的數據,導致緩存中的數據是臟的,而且還一直這樣臟下去了。所以這個設計是錯誤的,不建議使用。
2. Cache aside
這是我們最常用的一種設計模式,其邏輯如下:
- 查詢:程序先從cache中獲取數據,有數據直接返回,沒有得到,則去數據庫中取數據,成功后更新到緩存中。
- 更新:先把數據存到數據庫中,成功后,再讓緩存失效。
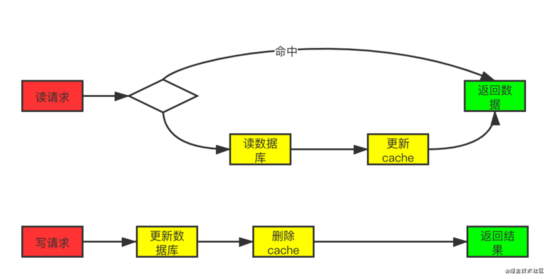
這種設計正好能解決上文出現臟數據的問題。我們來理一下,一個是查詢操作,一個是更新操作的并發,沒有了刪除cache數據的操作了,而是先更新了數據庫中的數據,此時,緩存依舊有效,所以,并發的查詢操作拿的是沒有更新的數據,但是,更新操作馬上讓緩存的失效了,后續的查詢操作再把數據從數據庫中拉出來。而不會像文章開頭的那個邏輯產生的問題,后續的查詢操作一直都在取老的數據。
那么是不是這種設計就不會存在并發問題了呢?不是的,比如,一個是讀操作,但是沒有命中緩存,然后就到數據庫中取數據,此時來了一個寫操作,寫完數據庫后,讓緩存失效,然后,之前的那個讀操作再把老的數據放進去,所以,會造成臟數據。但,這個case理論上會出現,不過,實際上出現的概率可能非常低,因為這個條件需要發生在讀緩存時緩存失效,而且并發著有一個寫操作。而實際上數據庫的寫操作會比讀操作慢得多,而且還要鎖表,而讀操作必需在寫操作前進入數據庫操作,而又要晚于寫操作更新緩存,所有的這些條件都具備的概率基本并不大。
我們可以為緩存設置上過期時間,這樣可以有效解決這個問題。
3. Read/Write Through
這個模式其實就是將 緩存服務 作為主要的存儲,應用的所有讀寫請求都是直接與緩存服務打交道,而不管最后端的數據庫了,數據庫的數據由緩存服務來維護和更新。不過緩存中數據變更的時候是同步去更新數據庫的,在應用的眼中只有緩存服務。
流程如下:
- Read Through
Read Through 套路就是在查詢操作中更新緩存,也就是說,當緩存失效的時候(過期或LRU換出),Cache Aside是由調用方負責把數據加載入緩存,而Read Through則用緩存服務自己來加載,從而對應用方是透明的。
- Write Through
Write Through 套路和Read Through相仿,不過是在更新數據時發生。當有數據更新的時候,如果沒有命中緩存,直接更新數據庫,然后返回。如果命中了緩存,則更新緩存,然后再由Cache自己更新數據庫(這是一個同步操作)
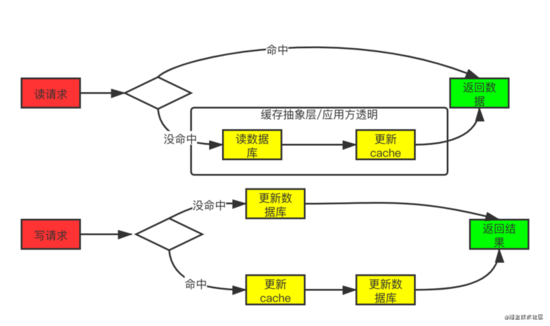
這個模式的特點就是出現臟數據的概率就比較低,但是就強依賴緩存了,對緩存服務的穩定性有較大要求,另外,增加新緩存節點時還會有初始狀態空數據問題。
4. Write Behind Caching
Write Behind Caching又叫做Write Back,就是在更新數據的時候,只更新緩存,不更新數據庫,而緩存會異步地批量更新數據庫。這個設計的好處是讓數據的I/O操作可以很快,異步的操作還可以合并對同一個數據的多次操作,性能上是非常可觀的。
但是,其帶來的問題是,數據不是強一致性的,而且可能會丟失。在軟件設計上,我們基本上不可能做出一個沒有缺陷的設計,就像算法設計中的時間換空間,空間換時間一個道理,有時候,強一致性和高性能,高可用和高性性是有沖突的。軟件設計從來都是取舍Trade-Off。另外,Write Back實現邏輯比較復雜,因為他需要track有哪數據是被更新了的,需要刷到持久層上。操作系統的write back會在僅當這個cache需要失效的時候,才會被真正持久起來,比如,內存不夠了,或是進程退出了等情況,這又叫lazy write。
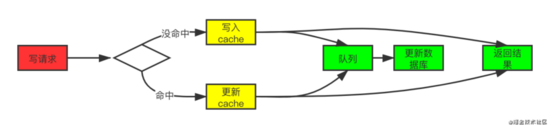
這個模式的特點就是速度很快,效率會非常高,但是數據的一致性比較差,還可能會有數據的丟失情況,實現邏輯也較為復雜。
總結
上面講的這幾種緩存更新設計,都是一些前人使用的總結,這些設計也不是完美的,這個世界上沒有完美的設計,所以我們的設計多多少少會有問題,比如我們沒有考慮緩存(Cache)和持久層(Repository)的整體事務的問題。比如,更新Cache成功,更新數據庫失敗了怎么嗎?或是反過來。關于這個事,如果你需要強一致性,就要好好考慮怎么解決這個問題。在軟件開發或設計中,我非常建議在之前先去參考一下已有的設計和思路, 看看相應的guideline,best practice或design pattern,吃透了已有的這些東西,再決定是否要重新發明輪子 。千萬不要似是而非地,想當然的做軟件設計。