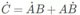競賽比完代碼模型怎么處理?Kaggle大神:別刪,這都是寶藏
那些被遺忘的競賽項目代碼、權(quán)重可能也是一筆寶藏。
很多人可能參加過許多比賽,做過許多項目,但比賽或項目結(jié)束之后,曾經(jīng)寫過的代碼、用過的模型就被丟到了一邊,甚至不久就被刪掉。
這種情況并不只存在于比賽中,在學(xué)術(shù)領(lǐng)域同樣存在。當(dāng)學(xué)生訓(xùn)練完模型、寫完論文并被學(xué)術(shù)會議接收后,該模型的 pipeline 就會被拋棄,訓(xùn)練數(shù)據(jù)也隨之被刪除。這是不是有點太可惜了?
長期參加 Kaggle 比賽的 Vladimir Iglovikov 在自己的博客中指出了這個問題,并提出了一些重新利用這些資源的建議。
Vladimir Iglovikov 是一位 Kaggle Grandmaster,曾在 Kaggle 全球榜單中排名第 19,拿到過 Carvana 圖像遮蔽挑戰(zhàn)的冠軍(他的個人經(jīng)歷參見:《Kaggle Grandmaster 是怎樣煉成的》)。
在他看來,競賽中曾經(jīng)用到的代碼、權(quán)重等資源是一筆寶貴的財富,可以幫助你鞏固技術(shù)知識、樹立個人品牌、提高就業(yè)機(jī)會。
為了解釋這些資源資源的價值,他還專門創(chuàng)建了一個 GitHub 項目(retinaface)來講述文本的建議。
項目鏈接:https://github.com/ternaus/retinaface
以下是博客的具體內(nèi)容。
花 5 分鐘將代碼發(fā)布到公開的 GitHub 存儲庫
很多時候,你的代碼可能已經(jīng)存到 GitHub 上了,但是是存在私人庫里。那公開又有什么損失呢?
某些情況下,有些代碼確實不宜公開,但你在 Kaggle 里做的那些練手項目、解決方案和論文或許沒這個必要。
為什么有些人不愿公開呢?因為很多人認(rèn)為,「所有公開發(fā)布的代碼都應(yīng)該是完美的,否則就會遭到批判。」
但實際情況是,其他人根本不 care,你只管發(fā)布就行。
公開代碼是心理防線的一次重大突破,公開不完美的代碼更是一個自信、大膽的舉動。所有后續(xù)步驟也都在這一步的基礎(chǔ)上展開。
花 20 分鐘提升代碼可讀性
你可以通過添加語法格式化工具和檢查工具來提升 python 代碼的可讀性。
這并不困難,也并不費時。檢查工具和格式化程序不會將爛代碼變成好代碼,但其可讀性會有所提升。以下是具體步驟:
步驟 1:文件配置
將這些文件添加到存儲庫的根目錄。
setup.cfg — flake8 和 mypy 的配置。
pyproject.toml — black 的配置。
步驟 2:requirements
用以下命令安裝所需的庫:
步驟 3:black
格式化代碼的方法有 100500 多種。諸如 black 或 yapf 之類的格式化工具會按照一組預(yù)定義的規(guī)則來修改代碼。
閱讀具有一定標(biāo)準(zhǔn)的代碼庫會更加容易。當(dāng)你花費幾個小時編寫代碼并需要在不同的編碼風(fēng)格之間切換語境時,你的意志力會被消耗殆盡。因此,沒有充分的理由就不要這么做。
運行以下命令將重新格式化所有的 python 文件以遵循 black 的規(guī)則。
步驟 4:flake8
運行以下命令不會修改代碼,但會檢查代碼中的語法問題并將其輸出到屏幕上。然后修改這些問題。
步驟 5:mypy
Python 沒有強(qiáng)制性的靜態(tài)類型化,但還是建議將類型添加至函數(shù)參數(shù)并返回類型。例如:
你應(yīng)該在代碼中添加鍵入內(nèi)容。這會讓代碼讀起來更容易。你可以使用 mypy 包檢查參數(shù)和函數(shù)類型的一致性。更新代碼后,在整個存儲庫上運行 mypy:
如果 mypy 出現(xiàn)問題,修復(fù)它們。
步驟 6:預(yù)提交鉤子(hook)
一直手動運行 flake8、black 和 mypy 會覺得厭倦。一個名為 pre-commit 的鉤子能夠解決這個問題。要啟用它,可以將以下文件復(fù)制到你的存儲庫中:https://github.com/ternaus/retinaface/blob/master/.pre-commit-config.yaml
你需要使用以下命令安裝 pre-commit 包。
使用以下命令進(jìn)行初始化:
安裝完成后,每次提交都會經(jīng)歷一組檢查。當(dāng)提交中有錯誤時,檢查不會允許提交通過。這和手動運行 black、flake8 以及 mypy 的不同之處在于,它不會乞求你修復(fù)問題,而是強(qiáng)制要求你做這件事。因此,這種方法不會浪費你的意志力、
步驟 7:Github 操作
你已經(jīng)向 pre-commit 鉤子中添加了檢查步驟,并在本地運行了這些步驟。但是你還需要第二道防線——讓 GitHub 在每個拉取請求上運行這些檢查步驟。
你要做的就是將以下文件添加到存儲庫中:https://github.com/ternaus/retinaface/blob/master/.github/workflows/ci.yml
執(zhí)行以下代碼來告訴 GitHub 要檢查什么:
我還建議放棄將代碼直接推送到 master 分支的做法。你可以創(chuàng)建一個新的分支、修改代碼、提交、放到 Github 上、創(chuàng)建 PR 請求,然后合并到 master。這是一項行業(yè)標(biāo)準(zhǔn),但是在學(xué)術(shù)研究和 Kaggle 參賽者中卻不常見。如果你對這些工具不熟悉,可能需要花 20 分鐘添加它們并修復(fù)錯誤和警告。
記住這次的操作。在下個項目中,你可以在沒寫代碼之前就在第一次提交中添加這些檢查。從這個時候開始,每次小的提交都會被檢查,你每次最多只需要修復(fù)幾行代碼。這么做開銷很小,也是一個良好的習(xí)慣。
花 20 分鐘寫一個優(yōu)秀的 readme
好的 readme 有兩個作用:
對你自己而言:可能你認(rèn)為你永遠(yuǎn)都不會再用到這些代碼了,但實際上并不一定。下次用的時候你可能也記不得它的具體內(nèi)容了,但 readme 可以幫到你。
對其他人而言:readme 是一個賣點。如果人們看不出該存儲庫的用途以及它所解決的問題,大家就不會使用它,你所做的所有工作都不會對他人產(chǎn)生積極影響。
一個機(jī)器學(xué)習(xí)庫的最低要求是說明以下問題:
用一張圖來說明任務(wù)是什么以及如何解決,而不需要任何文字。在花了幾周解決問題之后,你可能有 100500 張圖,但你不能把他們放在 readme 里;
數(shù)據(jù)放在哪里;
怎樣開始訓(xùn)練;
如何進(jìn)行推理。
如果你需要寫 100500 個詞來描述怎樣運行訓(xùn)練或者推理,那就說明你的項目存在問題了。你需要重構(gòu)代碼,使它對用戶更加友好。
人們經(jīng)常會問:如何提高寫代碼的能力?這便是一個鍛煉你的機(jī)會。你可能需要重寫代碼,嘗試站在別人的角度看待你的 Readme。
這是一個很好的鍛煉機(jī)會,它能夠讓你學(xué)會從用戶的角度看待問題。
花 20 分鐘提高模型易用性
我猜你會編寫如下代碼來加載預(yù)訓(xùn)練模型權(quán)重。
用上面的代碼從 retinaface.pre_trained_models 中引入 get_modelmodel = get_model("resnet50_2020-07-20", max_size=2048)。
如果權(quán)重不在磁盤上,那就會從網(wǎng)絡(luò)上先下載下來再緩存到磁盤上。初始化模型,并加載權(quán)重,這對用戶來說是很友好的,也是你在 torchvision 和 timm 庫中所看到的。
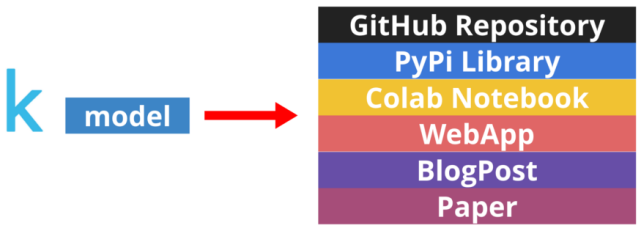
步驟 1:托管預(yù)訓(xùn)練模型的權(quán)重
這對我來說是最大的障礙。如果不想使用 AWS、GCP,我要把模型的權(quán)重放在哪里?GitHub 上的 releases 是一個不錯的選擇。
每個文件的大小限制是 2Gb,對大多數(shù)深度學(xué)習(xí)模型來說夠用了。
步驟 2:編寫一個初始化模型和加載權(quán)重的函數(shù)。
我給出的示例代碼如下:
在構(gòu)建 Colab Notebook 和 WebApp 時會用到這個函數(shù)。
花 20 分鐘創(chuàng)建一個庫
這一步是為了降低你模型的入口點。
步驟 1:向 requirements.txt 中添加必要的依賴,你可以手動更新或使用如下代碼:
步驟 2:改變存儲庫的文件結(jié)構(gòu)
創(chuàng)建一個「主文件夾」,在我給出的示例中,這個文件夾叫「retinaface」。
將所有重要代碼都放進(jìn)這個文件夾,但不要把 helper 圖像、Readme、notebook 或 test 放進(jìn)去。手動操作這一步驟并更新所有的 import 會很累。PyCharm 或者類似的 IDE 會為你執(zhí)行這一步驟。
這是存儲庫中構(gòu)建代碼結(jié)構(gòu)的常用方法。如果你想讓其更加結(jié)構(gòu)化,請查看 Cookie Cutter 包。
步驟 3:添加配置文件
向根目錄中添加 setup.py,內(nèi)容類似于示例文件「setup.py」中的內(nèi)容。添加包的版本,在我的示例中,我將它添加到了主文件夾的 init 文件中。
步驟 4:在 PyPI 上創(chuàng)建一個賬戶。
步驟 5:搭建一個庫并上傳到 PyPI 上。
你的存儲庫是一個庫,每個人都可以使用如下命令安裝它:
如果你在 PyPI 上查看包的頁面,你就會看到它使用你存儲庫中的 Readme 文件來陳述項目。我們將會在 Google Colab 和 Web App 上使用這一步的功能。
花 20 分鐘創(chuàng)建 Google Colab notebook
將 Jupiter notebook 添加到存儲庫是一個好習(xí)慣,以展示如何初始化模型和執(zhí)行推理功能。
在前兩個步驟中,我們使用了模型初始化和 pip install。接下來創(chuàng)建 Google Golab notebook。
現(xiàn)在,只需要一個瀏覽器,就會有更多的人嘗試你的模型了。別忘了在 readme 中添加 notebook 的鏈接,并在 PyPi 上更新版本。
花 20 分鐘創(chuàng)建 WebApp
許多數(shù)據(jù)科學(xué)家認(rèn)為構(gòu)建 web 應(yīng)用程序是一個復(fù)雜的過程,需要專業(yè)知識。這種想法是正確的。一個復(fù)雜項目的 web 應(yīng)用程序確實需要很多數(shù)據(jù)科學(xué)家并不具備的專業(yè)知識,但構(gòu)建一個簡單的 web 應(yīng)用程序來展示模型還是很容易的。
我為一個 web 應(yīng)用程序創(chuàng)建了一個單獨的 GitHub 存儲庫。不過,你仍然可以在你的存儲庫中用你的模型來操作。這里有一篇描述具體細(xì)節(jié)的技術(shù)博客:https://towardsdatascience.com/deploy-streamlit-on-heroku-9c87798d2088。
步驟 1:為應(yīng)用程序添加代碼:
步驟 2:添加配置文件
你需要添加以下文件:
setup.sh — 該文件可以直接使用,不需要更改。
Procfile — 你需要使用應(yīng)用程序修改文件的路徑。
步驟 3:添加 requirements.txt 文件
步驟 4:在 herokuapp 上注冊
步驟 5:執(zhí)行以下代碼:
花 4 小時寫一篇技術(shù)博客
很多人低估了他們研究的價值。實際上你的文章很可能能夠幫助別人,并且能夠為自己的職業(yè)生涯提供更多的機(jī)會。
如果要寫機(jī)器學(xué)習(xí)方面的文章,我建議你包含以下內(nèi)容:
研究問題是什么?
你是如何解決這個問題的?
示例如下:
項目:https://www.kaggle.com/c/sp-society-camera-model-identification
博客:http://ternaus.blog/machine_learning/2018/12/05/Forensic-Deep-Learning-Kaggle-Camera-Model-Identification-Challenge.html
花時間寫篇論文,描述你在這場機(jī)器學(xué)習(xí)競賽中的解決方案
即使你的論文中沒有重大突破,它也會被發(fā)表并幫到別人。撰寫學(xué)術(shù)論文也是一項技能。你現(xiàn)在可能還不具備這種技能,但你可以與擅長學(xué)術(shù)寫作的人合作。
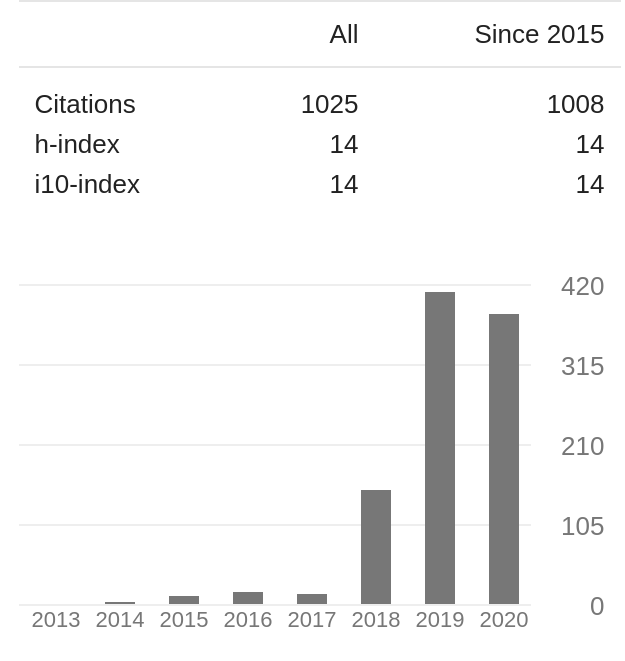
下面是我的 Google Scholar 引用情況,這幾年引用量的猛增都得益于我寫的那些總結(jié)機(jī)器學(xué)習(xí)競賽的論文。
當(dāng)然,你的論文也包含在一個大包里,這個包里還有:
GitHub 存儲庫,里面有整潔的代碼和良好的 readme 文件。
非機(jī)器學(xué)習(xí)人員能夠使用的庫。
允許在瀏覽器中用你的模型進(jìn)行快速實驗的 Colab notebook。
吸引非技術(shù)受眾的 WebApp。
用人類語言講故事的博客文章。
有了這些之后,它就不再只是一篇論文,而是一種綜合性的策略,可以顯示你對該項目的所有權(quán),還能幫助你與他人進(jìn)行溝通。這兩者對于你的職業(yè)生涯都是至關(guān)重要的。