做ML項目,任務繁多瑣碎怎么辦?這份自查清單幫你理清思路
機器學習項目中含有眾多因素,包括數據處理、模型優化等。開發者經常會陷入混亂,或者遺漏一些重要的東西。這里有一份備忘清單,請查收。
任何科研項目都是系統性的,機器學習項目也不例外,它包含一系列大大小小、或繁或簡的要素和組件,如討論、準備工作、提出問題、模型構建和優化調整等。在這種情況下,開發者很容易漏掉一些重要的東西。
這時就需要對項目中經涉及到的任務做一份詳盡的清單。有時開發者絞盡腦汁也無法找到一個好的起始點,那么任務清單則有助于他們在正確的信息源中提取有用的數據并建立聯系,從而發掘出深刻見解。
此外,還需要對項目中的每項任務進行規劃的檢查,確保任務的完成度。
正如 Atul Gawande 在其著作《清單宣言:如何把事情做對》(Checklist Manifesto)中說到的:
我們所了解事物的數量和復雜度已經超出了自身從它們中正確、安全或可靠地獲益的能力。
在本文中,網頁和數據科學講師 Harshit Tyagi 以端到端機器學習項目為例,對經常涉及的任務做了一份清單。
本文作者 Harshit Tyagi。
接下來,我們就來看 Harshit Tyagi 是如何一步步創建屬于自己的機器學習項目任務清單的。
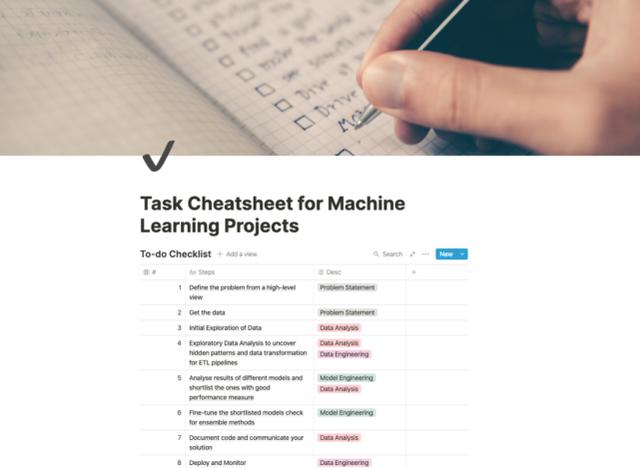
八步完成 ML 項目檢查清單
幾乎每個機器學習項目中都至少要執行 8-10 個步驟,其中一些步驟的執行順序也可以互換。
步驟 1:從一個高水平的視角定義問題
執行此步驟是為了弄清楚問題的業務邏輯。你應該了解到:
問題的本質(有監督的 / 無監督的,分類問題 / 回歸問題)。
你可以開發的方案類型。
應該用什么指標來度量性能?
機器學習是解決這個問題的正確方法嗎?
解決該問題的手動方法。
該問題固有的假設。
步驟 2:確定數據源并獲取數據
在大多數情況下,如果你已經準備一些數據并想要定義關于這些數據的問題以更好地利用輸入的數據,那么你可以先于步驟 1 執行這個步驟。
基于問題的定義,你需要確定數據源中哪些可以作為數據庫或傳感器等。對于生產中某個應用的部署,這一步應該通過開發數據 pipeline 來實現自動化,以保證輸入的數據能夠進入系統。
具體步驟如下:
列出你需要的數據源及數據量;
檢查存儲空間是否會成為問題;
檢查你是否有權限應用這些數據來達到你的目的;
獲取數據并將其轉換為可利用的格式;
檢查數據類型,通常包括文本、分類、數值、時序、圖像數據;
保留樣本以進行最終的測試。
步驟 3:初步探索數據
在這一步中,你需要對所有影響項目結果 / 預測 / 目標的特征進行研究。如果數據量很大,請對數據進行采樣使得分析更易管理。具體步驟如下:
使用 jupyter notebook,因為它為研究數據提供了簡單直觀的界面;
確定目標變量;
確定特征的類型(分類、數值、文本等);
分析特征之間的關系;
添加一些可視化數據,使每個特征對目標變量的影響更易于解釋;
記錄你的發現。
步驟 4:探索性數據分析以準備數據
在這一步中,通過定義數據轉換、數據清理、特征選擇 / 工程和擴展的函數來處理之前步驟中的發現。具體如下:
編寫數據轉換函數,并自動處理將輸入的下一批數據;
編寫數據清理函數(估算缺失值并處理異常值);
編寫函數以選擇和工程化特征,包括刪除冗余特征、特征格式化以及其他數學變換;
特征擴展——標準化特征。
步驟 5:開發一個基線模型,然后探索其他模型以選出最佳模型
創建一個能夠為所有其他復雜機器學習模型提供基線的基礎模型。具體步驟如下:
使用默認參數訓練一些常用的機器學習模型,如樸素貝葉斯、線性回歸、支持向量機(SVM)等;
度量并比較每種模型的性能;
對每個模型采用 N 倍交叉驗證并在 N 倍的基礎上計算性能指標的均值和標準差;
研究對目標影響最大的特征;
分析模型在預測過程中存在的錯誤類型;
用不同的方式工程化特征;
重復上述步驟幾次,以確保使用正確的特征,且其形式也無誤;
選出基于性能指標的最佳模型。
步驟 6:優化你選出的模型并檢查相關方法
這是你更加接近最終解決方案的關鍵步驟之一,具體步驟如下:
用交叉驗證優化超參數;
用隨機搜索或網格搜索等自動調整方法來找出最佳模型的最佳配置;
測試相關方法,比如集成學習等;
用盡可能多的數據測試模型;
最終確定后,使用在開始保留的未見過測試樣例來檢查模型是否存在過擬合或欠擬合。
步驟 7:保存代碼并交流你的方案
交流的過程也是性能加倍的過程。你需要記得所有已有或潛在的利益相關者。主要步驟包括如下:
保存代碼并記錄整個項目的過程及用到的方法;
創建儀表板,如 voila 或帶有接近自我解釋可視化的有效 presentation;
撰寫一篇描述你如何進行特征分析、測試數據轉換等的文章 / 報告。記錄你的學習過程,包括失敗的經驗和有效的技術方法;
總結主要結果并規劃未來設想(如果有的話)。
步驟 8:將模型投入生產并監測模型
如果你的項目需要在實時數據上進行測試,你應該創建一個可以在所有平臺(web、android、iOS)上使用的網頁版應用或 REST API。主要步驟包括:
在 h5 或 pickle 文件中保存你最終的訓練模型;
提供網頁版模型應用,你可以使用 Flask 來開發這些網頁服務;
關聯輸入數據源并設置 ETL 路徑;
基于擴展需求,用 pipenv、docker/Kubernetes 管理依賴關系;
你可以使用亞馬遜、Azure 或者谷歌云平臺來部署你的服務;
在實時數據上監測性能或讓人們在你的模型上方便地使用他們的數據。
最后,創建任務清單時需要注意的一點是:你可以根據項目的難易程度來對清單進行實時調整。