













C++并發(fā)編程實(shí)戰(zhàn):如何為多線程性能設(shè)計(jì)數(shù)據(jù)結(jié)構(gòu)?
在8.1節(jié)中我們看到了在線程間劃分工作的一些方法,在8.2節(jié)中我們看到了影響代碼性能的一些因素。當(dāng)設(shè)計(jì)多線程性能的數(shù)據(jù)結(jié)構(gòu)的時(shí)候如何使用這些信息呢?這是在第6章和第7章中處理的很困難的問(wèn)題,是關(guān)于設(shè)計(jì)可以安全并行讀取的數(shù)據(jù)結(jié)構(gòu)。正如你在8.2節(jié)中看到的一樣,即使沒(méi)有別的線程共享此數(shù)據(jù),單個(gè)線程使用的數(shù)據(jù)布局也會(huì)對(duì)它產(chǎn)生影響。
當(dāng)為多線程性能設(shè)計(jì)你的數(shù)據(jù)結(jié)構(gòu)時(shí)需要考慮的關(guān)鍵問(wèn)題是競(jìng)爭(zhēng)、假共享以及數(shù)據(jù)接近。這三個(gè)方面都會(huì)對(duì)性能產(chǎn)生很大影響,并且通常你可以通過(guò)改變數(shù)據(jù)布局或者改變分配給某線程的數(shù)據(jù)元素來(lái)提高性能。首先,我們來(lái)看一個(gè)簡(jiǎn)單的例子,在線程間劃分?jǐn)?shù)組元素。
8.3.1 為復(fù)雜操作劃分?jǐn)?shù)組元素
假設(shè)你正在做一些復(fù)雜的數(shù)學(xué)計(jì)算,你需要將兩個(gè)大矩陣想乘。為了實(shí)現(xiàn)矩陣相乘,你將第一個(gè)矩陣的第一行每個(gè)元素與第二個(gè)矩陣的第一列相對(duì)應(yīng)的每個(gè)元素相乘,并將結(jié)果相加得到結(jié)果矩陣左上角第一個(gè)元素。然后你繼續(xù)將第二行與第一列相乘得到結(jié)果矩陣第一列的第二個(gè)元素,以此類(lèi)推。正如圖8.3所示,突出顯示的部分表明了第一個(gè)矩陣的第二行與第二個(gè)矩陣的第三列配對(duì),得到結(jié)果矩陣的第三列第二行的值。
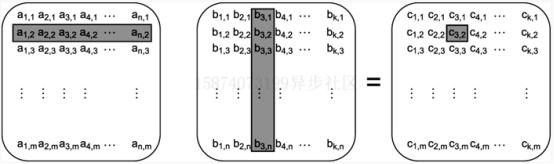
圖8.3 矩陣相乘
為了值得使用多線程來(lái)優(yōu)化該乘法運(yùn)算,現(xiàn)在我們假設(shè)這些都有幾千行和幾千列的大矩陣。通常,非稀疏矩陣在內(nèi)存中是用一個(gè)大數(shù)組表示的,第一行的所有元素后面是第二行的所有元素,以此類(lèi)推。為了實(shí)現(xiàn)矩陣相乘,現(xiàn)在就有三個(gè)大數(shù)組了。為了獲得更優(yōu)的性能,你就需要注意數(shù)據(jù)存取部分,特別是第三個(gè)數(shù)組。
有很多在線程間劃分工作的方法。假設(shè)你有比處理器更多的行例,那么你就可以讓每個(gè)線程計(jì)算結(jié)果矩陣中某些列的值,或者讓每個(gè)線程計(jì)算結(jié)果矩陣中某些行的值,或者甚至讓每個(gè)線程計(jì)算結(jié)果矩陣中規(guī)則矩形子集的值。
回顧8.2.3節(jié)和8.2.4節(jié),你就會(huì)發(fā)現(xiàn)讀取數(shù)組中的相鄰元素比到處讀取數(shù)組中的值要好,因?yàn)檫@樣減少了緩存使用以及假共享。如果你使每個(gè)線程處理一些列,那么就需要讀取第一個(gè)矩陣中的所有元素以及第二個(gè)矩陣中相對(duì)應(yīng)的列中元素,但是你只會(huì)得到列元素的值。假設(shè)矩陣是用行順序存儲(chǔ)的,這就意味著你從第一行中讀取N個(gè)元素,從第二行中讀取N個(gè)元素,以此類(lèi)推(N的值是你處理的列的數(shù)目)。別的線程會(huì)讀取每一行中別的元素,這就很清楚你應(yīng)該讀取相鄰的的列,因此每行的N個(gè)元素就是相鄰的,并且最小化了假共享。當(dāng)然,如果這N個(gè)元素使用的空間與緩存線的數(shù)量相等的話,就不會(huì)有假共享,因?yàn)槊總€(gè)線程都會(huì)工作在獨(dú)立的緩存線上。
另一方面,如果每個(gè)線程處理一些行元素,那么就需要讀取第二個(gè)矩陣中的所有元素,以及第一個(gè)矩陣中相關(guān)的行元素,但是它只會(huì)得到行元素。因?yàn)榫仃囀怯眯许樞虼鎯?chǔ)的,因此你現(xiàn)在讀取從N行開(kāi)始的所有元素。如果你選擇相鄰的行,那么就意味著此線程是現(xiàn)在唯一對(duì)這N行寫(xiě)入的線程;它擁有內(nèi)存中連續(xù)的塊并且不會(huì)被別的線程訪問(wèn)。這就比讓每個(gè)線程處理一些列元素更好,因?yàn)?i style="background-color: rgb(255, 153, 51);">唯一可能產(chǎn)生假共享的地方就是一塊的最后一些元素與下一個(gè)塊的開(kāi)始一些元素。但是值得花時(shí)間確認(rèn)目標(biāo)結(jié)構(gòu)。
第三種選擇一劃分為矩形塊如何呢?這可以被看做是先劃分為列,然后劃分為行。它與根據(jù)列元素劃分一樣存在假共享問(wèn)題。如果你可以選擇塊的列數(shù)目來(lái)避免這種問(wèn)題,那么從讀這方面來(lái)說(shuō),劃分為矩形塊有這樣的優(yōu)點(diǎn):你不需要讀取任何一個(gè)完整的源矩陣。你只需要讀取相關(guān)的目標(biāo)矩陣的行與列的值。從具體方面來(lái)看,考慮兩個(gè)1000行和1000列的矩陣相乘。就有一百萬(wàn)個(gè)元素。如果你有100個(gè)處理器,那么每個(gè)線程可以處理10行元素。盡管如此,為了計(jì)算這10000個(gè)元素,需要讀取第二個(gè)矩陣的所有元素(一百萬(wàn)個(gè)元素)加上第一個(gè)矩陣相關(guān)行的10000個(gè)元素,總計(jì)1010000個(gè)元素;另一方面,如果每個(gè)線程處理100行100列的矩陣塊(總計(jì)10000個(gè)元素) ,那么它們需要讀取第一個(gè)矩陣的100行元素( 100 x 1000=100000元素)和第二個(gè)矩陣的100列元素(另一個(gè)100000個(gè)元素)。這就只有200000元素,將讀取的元素?cái)?shù)量降低到五分之一。如果你讀取更少的元素,那么發(fā)生緩存未命中和更好性能的潛力的機(jī)會(huì)就更少了。
因此將結(jié)果矩陣劃分為小的方塊或者類(lèi)似方塊的矩陣比每個(gè)線程完全處理好幾行更好。當(dāng)然,你可以調(diào)整運(yùn)行時(shí)每個(gè)塊的大小,取決于矩陣的大小以及處理器的數(shù)量。如果性能很重要,基于目標(biāo)結(jié)構(gòu)分析各種選擇是很重要的。
你也有可能不進(jìn)行矩陣乘法,那么它是否適用呢?當(dāng)你在線程間劃分大塊數(shù)據(jù)的時(shí)候,同樣的原則也適用于這種情況。仔細(xì)觀察數(shù)據(jù)讀取方式,并且識(shí)別影響性能的潛在原因。在你遇到的問(wèn)題也可能有相似的環(huán)境,就是只要改變工作劃分方式可以提高性能而不需要改變基本算法。
好了,我們已經(jīng)看到數(shù)組讀取方式是如何影響性能的。其他數(shù)據(jù)結(jié)構(gòu)類(lèi)型呢?
8.3.2其他數(shù)據(jù)結(jié)構(gòu)中的數(shù)據(jù)訪問(wèn)方式
從根本上說(shuō),當(dāng)試圖優(yōu)化別的數(shù)據(jù)結(jié)構(gòu)的數(shù)據(jù)訪問(wèn)模式時(shí)也是適用的。
1、在線程間改變數(shù)據(jù)分配,使得相鄰的數(shù)據(jù)被同一個(gè)線程適用。
2、最小化任何給定線程需要的數(shù)據(jù)。
3、確保獨(dú)立的線程訪問(wèn)的數(shù)據(jù)相隔足夠遠(yuǎn)來(lái)避免假共享。
當(dāng)然,運(yùn)用到別的數(shù)據(jù)結(jié)構(gòu)上是不容易的。例如,二叉樹(shù)本來(lái)就很難用任何方式來(lái)再分,有用還是沒(méi)用,取決于樹(shù)是如何平衡的以及你需要將它劃分為多少個(gè)部分。同樣,樹(shù)的本質(zhì)意味著結(jié)點(diǎn)是動(dòng)態(tài)分配的,并且最后在堆上不同地方。
現(xiàn)在,使數(shù)據(jù)最后在堆上不同地方本身不是一個(gè)特別的問(wèn)題,但是這意味著處理器需要在緩存中保持更多東西。實(shí)際上這可以很有利。如果多個(gè)線程需要遍歷樹(shù),那么它們都需要讀取樹(shù)的結(jié)點(diǎn),但是如果樹(shù)的結(jié)點(diǎn)至包含指向該結(jié)點(diǎn)持有數(shù)據(jù)的指針,那么當(dāng)需要的時(shí)候,處理器就必須從內(nèi)存中載入數(shù)據(jù)。如果線程正在修改需要的數(shù)據(jù),這就可以避免結(jié)點(diǎn)數(shù)據(jù)與提供樹(shù)結(jié)構(gòu)的數(shù)據(jù)間的假共享帶來(lái)的性能損失。
使用互斥元保護(hù)數(shù)據(jù)的時(shí)候也有同樣的問(wèn)題。假設(shè)你有一個(gè)簡(jiǎn)單的類(lèi),它包含一些數(shù)據(jù)項(xiàng)和一個(gè)互斥元來(lái)保護(hù)多線程讀取。如果互斥元和數(shù)據(jù)項(xiàng)在內(nèi)存中離得很近,對(duì)于使用此互斥元的線程來(lái)說(shuō)就很好;它需要的數(shù)據(jù)已經(jīng)在處理器緩存中了,因?yàn)闉榱诵薷幕コ庠呀?jīng)將它載入了。但是它也有一個(gè)缺點(diǎn):當(dāng)第一個(gè)線程持有豆斥元的時(shí)候,如果別的線程試圖鎖住互斥元,它們就需要讀取內(nèi)存。互斥元的鎖通常作為一個(gè)在互斥元內(nèi)的存儲(chǔ)單元上試圖獲取互斥元的讀一修改一寫(xiě)原子操作來(lái)實(shí)現(xiàn)的,如果互斥元已經(jīng)被鎖的話,就接著調(diào)用操作系統(tǒng)內(nèi)核。這個(gè)讀一修改一寫(xiě)操作可能導(dǎo)致?lián)碛谢コ庠木€程持有的緩存中的數(shù)據(jù)變得無(wú)效。只要使用互斥元,這就不是問(wèn)題。盡管如此,如果互斥元和線程使用的數(shù)據(jù)共享同一個(gè)緩沖線,那么擁有此互斥元的線程的性能就會(huì)因?yàn)榱硪粋€(gè)線程試圖鎖住該互斥元而受到影響。
測(cè)試這種假共享是否是一個(gè)問(wèn)題的方法就是在數(shù)據(jù)元素間增加可以被不同的線程并發(fā)讀取的大塊填充數(shù)據(jù)例如,你可以使用:

來(lái)測(cè)試互斥元競(jìng)爭(zhēng)問(wèn)題或者使用:

來(lái)測(cè)試數(shù)組數(shù)據(jù)是否假共享。如果這樣做提高了性能,就可以得知假共享確實(shí)是一個(gè)問(wèn)題,并且你可以保留填充數(shù)據(jù)或者通過(guò)重新安排數(shù)據(jù)讀取的方式來(lái)消除假共享。
當(dāng)然,當(dāng)設(shè)計(jì)并發(fā)性的時(shí)候,不僅需要考慮數(shù)據(jù)讀取模式,因此讓我們來(lái)看看別的需要考慮的方面。
8.4 為并發(fā)設(shè)計(jì)時(shí)的額外考慮
本章我們看了一些在線程間劃分工作的方法,影響性能的因素,以及這些因素是如何影響你選擇哪種數(shù)據(jù)讀取模式和數(shù)據(jù)結(jié)構(gòu)的。但是,設(shè)計(jì)并發(fā)代碼需要考慮更多。你需要考慮的事情例如異常安全以及可擴(kuò)展性。如果當(dāng)系統(tǒng)中處理核心增加時(shí)性能(無(wú)論是從減少執(zhí)行時(shí)間還是從增加吞吐量方面來(lái)說(shuō))也增加的話,那么代碼就是可擴(kuò)展的。從理論上說(shuō),性能增加是線性的。因此一個(gè)有100個(gè)處理器的系統(tǒng)的性能比只有一個(gè)處理器的系統(tǒng)好100倍。
即使代碼不是可擴(kuò)展的,它也可以工作。例如,單線程應(yīng)用不是可擴(kuò)展的,異常安全是與正確性有關(guān)的。如果你的代碼不是異常安全的,就可能會(huì)以破碎的不變量或者競(jìng)爭(zhēng)條件結(jié)束,或者你的應(yīng)用可能因?yàn)橐粋€(gè)操作拋出異常而突然終止。考慮到這些,我們將首先考慮異常安全。
8.4.1 并行算法中的異常安全
異常安全是好的C++代碼的一個(gè)基本方面,使用并發(fā)性的代碼也不例外。實(shí)際上,并行算法通常比普通線性算法需要你考慮更多關(guān)于異常方面的問(wèn)題。如果線性算法中的操作拋出異常,該算法只要考慮確保它能夠處理好以避免資源泄漏和破碎的不變量。它可以允許擴(kuò)大異常給調(diào)用者來(lái)處理。相比之下,在并行算法中,很多操作在不同的線程上運(yùn)行。在這種情況下,就不允許擴(kuò)大異常了,因?yàn)樗阱e(cuò)誤的調(diào)用棧中。如果一個(gè)函數(shù)大量產(chǎn)生以異常結(jié)束的新線程,那么該應(yīng)用就會(huì)被終止。
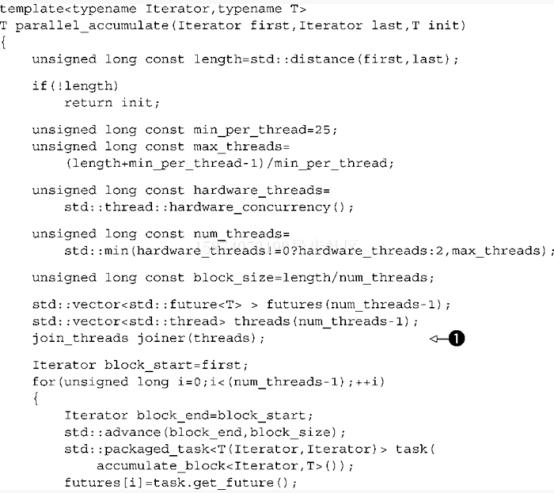
作為一個(gè)具體的例子,我們來(lái)回顧清單2.8中的 parallel_accumulate函數(shù),清單8.2中會(huì)做一些修改
清單8.2 sta::accumulate的并行版本(來(lái)自清單2.8)

現(xiàn)在我們檢查并且確定拋出異常的位置:總的說(shuō)來(lái),任何調(diào)用函數(shù)的地方或者在用戶(hù)定義的類(lèi)型上執(zhí)行操作的地方都可能拋出異常。
首先,你調(diào)用distance 2,它在用戶(hù)定義的迭代器類(lèi)型上執(zhí)行操作。因?yàn)槟氵€沒(méi)有進(jìn)行任何工作,并且這是在調(diào)用線程上,所以這是沒(méi)問(wèn)題的。下一步,你分配了results選代器3和threads迭代器4。同樣,這是在調(diào)用線程上,并且你沒(méi)有做任何工作或者生產(chǎn)任何線程,因此這是沒(méi)問(wèn)題的。當(dāng)然,如果threads構(gòu)造函數(shù)拋出異常,那么就必須清楚為results分配的內(nèi)存,析構(gòu)函數(shù)將為你完成它。
跳過(guò)block_start 的初始化5因?yàn)檫@是安全的,就到了產(chǎn)生線程的循環(huán)中的操作6、7、8。一旦在7中創(chuàng)造了第一個(gè)線程,如果拋出異常的話就會(huì)很麻煩,你的新sta::thread 對(duì)象的析構(gòu)函數(shù)會(huì)調(diào)用
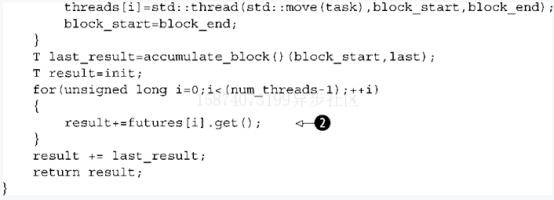
std::terminate 然后中程序,
調(diào)用accumulate_block 9也可能會(huì)拋出異常,你的線程對(duì)象將被銷(xiāo)毀并且調(diào)用std:terminate ;另一方面,最后調(diào)用std::accumulate 10的時(shí)候也可能拋出異常并且不導(dǎo)致任何困難,因?yàn)樗芯€程將在此處匯合。
這不是對(duì)于主線程來(lái)說(shuō)的,但是也可能拋出異常,在新線程上調(diào)用 accumulate_block 可能拋出異常1。這里沒(méi)有任何catch塊,因此該異常將被稍后處理并且導(dǎo)致庫(kù)調(diào)用sta::terminate()來(lái)中止程序。
即使不是顯而易見(jiàn)的,這段代碼也不是異常安全的。
1·增加異常安全性
好了,我們識(shí)別出了所有可能拋出異常的地方以及異常所造成的不好影響。那么如何處理它呢?我們先來(lái)解決在新線程上拋出異常的問(wèn)題。
在第4章中介紹了完成此工作的工具。如果你仔細(xì)考慮在新線程中想獲得什么,那么很明顯當(dāng)允許代碼拋出異常的時(shí)候,你試圖計(jì)算結(jié)果來(lái)返回。std: :packaged_task 和std:future 的組合設(shè)計(jì)是恰好的。如果你重新設(shè)計(jì)代碼來(lái)使用 std::packaged_task ,就以清單8.3中的代碼結(jié)束。
清單8.3使用std::packaged_task的std::accumulate的并行版本


第一個(gè)改變就是,函數(shù)調(diào)用accumulate_block操作直接返回結(jié)果,而不是返回存儲(chǔ)地址的引用1。你使用std::packaged_task 和std::future來(lái)保證異常安全,因此你也可以使用它來(lái)轉(zhuǎn)移結(jié)果。這就需要你調(diào)用std::accumulate 2明確使用默認(rèn)構(gòu)造函數(shù)T而不是重新使用提供的result值,不過(guò)這只是一個(gè)小小的改變。
下一個(gè)改變就是你用futures 向量3,而不是用結(jié)果為每個(gè)生成的線程存儲(chǔ)一個(gè) std:future
既然你已經(jīng)使用了future ,就不再有結(jié)果數(shù)組了,因此必須將最后一塊的結(jié)果存儲(chǔ)在一個(gè)變量中7而不是存儲(chǔ)在數(shù)組的一個(gè)位置中。同樣,因?yàn)槟銓膄uture中得到值,使用基本的for 循環(huán)比使用std:accumulate要簡(jiǎn)單,以提供的初始值開(kāi)始8,并且將每個(gè)future的結(jié)果累加起來(lái)9。如果相應(yīng)的任務(wù)拋出異常,就會(huì)在future中捕捉到并且調(diào)用get() 時(shí)會(huì)再次拋出異常。最后,在返回總的結(jié)果給調(diào)用者之前要加上最后一個(gè)塊的結(jié)果10。
因此,這就去除了一個(gè)可能的問(wèn)題,工作線程中拋出的異常會(huì)在主線程中再次被拋出。如果多于一個(gè)工作線程拋出異常,只有一個(gè)異常會(huì)被傳播,但是這也不是一個(gè)大問(wèn)題。如果確實(shí)有關(guān)的話,可以使用類(lèi)似
std::nested_exception來(lái)捕捉所有的異常然后拋出它。
如果在你產(chǎn)生第一個(gè)線程和你加入它們之間拋出異常的話,那么剩下的問(wèn)題就是線程泄漏。最簡(jiǎn)單的方法就是捕獲所有異常,并且將它們?nèi)诤系秸{(diào)用joinable()的線程中,然后再次拋出異常。

現(xiàn)在它起作用了。所有線程將被聯(lián)合起來(lái),無(wú)論代碼是如何離開(kāi)塊的。盡管如此, try-catch塊是令人討厭的,并且你有復(fù)制代碼。你將加入正常的控制流以及捕獲塊的線程中。復(fù)制代碼不是一個(gè)好事情,因?yàn)檫@意味著需要改變更多的地方。我們?cè)谝粋€(gè)對(duì)象的析構(gòu)函數(shù)中檢查它,畢竟,這是C++中慣用的清除資源的方法。下面是你的類(lèi)。

這與清單2.3中的thread_guard類(lèi)是相似的,除了它擴(kuò)展為適合所有線程。你可以如清單8.4所示簡(jiǎn)化代碼。
清單8.4 std::accumulate的異常安全并行版本
一旦你創(chuàng)建了你的線程容器,也就創(chuàng)建了一個(gè)新類(lèi)的實(shí)例1來(lái)加入所有在退出的線程。你可以去除你的聯(lián)合循環(huán),只要你知道無(wú)論函數(shù)是否退出,這些線程都將被聯(lián)合起來(lái)。注意調(diào)用 futures[i].get() 2將被阻塞直到結(jié)果出來(lái),因此在這一點(diǎn)并不需要明確地與線程融合起來(lái)。這與清單8.2中的原型不一樣,在清單8.2中你必須與線程聯(lián)合起來(lái)確保正確復(fù)制了結(jié)果向量。你不僅得到了異常安全代碼,而且你的函數(shù)也更短了,因?yàn)閷⒙?lián)合代碼提取到你的新(可再用的)類(lèi)中了。
2. STD::ASYNC()的異常安全
你已經(jīng)知道了當(dāng)處理線程時(shí)需要什么來(lái)實(shí)現(xiàn)異常安全,我們來(lái)看看使用std::async() 時(shí)需要做的同樣的事情。你已經(jīng)看到了,在這種情況下庫(kù)為你處理這些線程,并且當(dāng)future是就緒的時(shí)候,產(chǎn)生的任何線程都完成了。需要注意到關(guān)鍵事情就是異常安全,如果銷(xiāo)毀future的時(shí)候沒(méi)有等待它,析構(gòu)函數(shù)將等待線程完成。這就避免了仍然在執(zhí)行以及持有數(shù)據(jù)引用的泄漏線程的問(wèn)題。清單8.5所示就是使用std::async ()的異常安全實(shí)現(xiàn)。
清單8.5 使用std::async的std::accumulate的異常安全并行版本
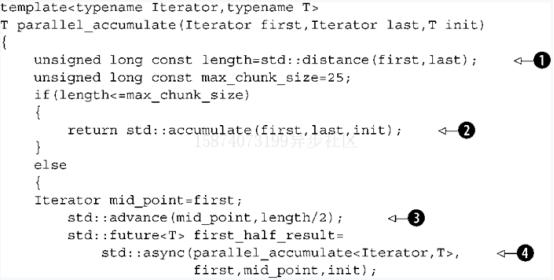

這個(gè)版本使用遞歸將數(shù)據(jù)劃分為塊而不是重新計(jì)算將數(shù)據(jù)劃分為塊,但是它比之前的版本要簡(jiǎn)單一些,并且是異常安全的。如以前一樣,你以計(jì)算序列長(zhǎng)度開(kāi)始1,如果它比最大的塊尺寸小的話,就直接調(diào)用
std::accumuate 2。如果它的元素比塊尺寸大的話,就找到中點(diǎn)3然后產(chǎn)生一個(gè)異步任務(wù)來(lái)處理前半部分![序號(hào)4。范圍內(nèi)的第二部分就用一個(gè)直接的遞歸調(diào)用來(lái)處理5。,然后將這兩個(gè)塊的結(jié)果累加6。庫(kù)確保了std::async調(diào)用使用了可獲得的硬件線程,并且沒(méi)有創(chuàng)造很多線程。一些"異步”調(diào)用將在調(diào)用get()的時(shí)候被異步執(zhí)行6。
這種做法的好處在于它不僅可以利用硬件并發(fā),而且它也是異常安全的。如果遞歸調(diào)用拋出異常5,當(dāng)異常傳播時(shí),調(diào)用std::async 4創(chuàng)造的future就會(huì)被銷(xiāo)毀。它會(huì)輪流等待異步線程結(jié)束,因此避免了懸掛線程。另一方面,如果異步調(diào)用拋出異常,就會(huì)被future捕捉,并且調(diào)用get() 6將再次拋出異常。
當(dāng)設(shè)計(jì)并發(fā)代碼的時(shí)候還需要考慮哪些方面呢?讓我們來(lái)看看可擴(kuò)展性。如果將你的代碼遷移到更多處理器系統(tǒng)中會(huì)提高多少性能呢?
8.4.2可擴(kuò)展性和阿姆達(dá)爾定律
可擴(kuò)展性是關(guān)于確保你的應(yīng)用可以利用系統(tǒng)中增加的處理器。一種極端情況就是你有一個(gè)完全不能擴(kuò)展的單線程應(yīng)用,即使你在系統(tǒng)中增加100個(gè)處理器也不會(huì)改變性能。另一種極端情況是你有類(lèi)似SETI@Home[3]的項(xiàng)目,被設(shè)計(jì)用來(lái)利用成千上萬(wàn)的附加的處理器(以用戶(hù)將個(gè)人計(jì)算機(jī)增加到網(wǎng)絡(luò)中的形式)。
對(duì)于任何給定的多線程程序,當(dāng)程序運(yùn)行時(shí),執(zhí)行有用工作的線程的數(shù)量會(huì)發(fā)生變化。即使每個(gè)線程都在做有用的操作,初始化應(yīng)用的時(shí)候可能只有一個(gè)線程,然后就有一個(gè)任務(wù)生成其他的線程。但是即使那樣也是一個(gè)不太可能發(fā)生的方案。線程經(jīng)常花時(shí)間等待彼此或者等待I/O操作完成
除非每次線程等待事情(無(wú)論是什么事情)的時(shí)候都有另一個(gè)線程在處理器上代替它,否則就有一個(gè)可以進(jìn)行有用工作的處理器處于閑置狀態(tài)
一種簡(jiǎn)單的方法就是將程序劃分為只有一個(gè)線程在做有用的工作"串行的"部分和所有可以獲得的處理器都在做有用工作的"并行的"部分。如果你在有更多處理器的系統(tǒng)上運(yùn)行你的應(yīng)用,理論上就可以更快地完成"并行"部分,因?yàn)榭梢栽诟嗟奶幚砥鏖g劃分工作,但是"串行的"部分仍然是串行的。在這樣一種簡(jiǎn)單假設(shè)下,你可以通過(guò)增加處理器數(shù)量來(lái)估計(jì)可以獲得的性能。如果“連續(xù)的"部分組成程序的一個(gè)部分fs,那么使用N個(gè)處理器獲得的性能P就可以估計(jì)為
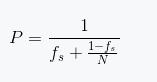
這就是阿姆達(dá)爾定律(Amdahl'slaw ) ,當(dāng)談?wù)摬l(fā)代碼性能的時(shí)候經(jīng)常被引用。如果所有事情都能被并行,那么串行部分就為0,加速就是N,或者,如果串行部分是三分之一,即使有無(wú)限多的處理器,你也不會(huì)得到超過(guò)3的加速
盡管如此,這是一種很理想的情況。因?yàn)槿蝿?wù)很少可以像方程式所需要的那樣被無(wú)窮劃分,并且所有事情都達(dá)到它所假設(shè)的CPU界限是很少出現(xiàn)的。正如你看到的,線程執(zhí)行的時(shí)候會(huì)等待很多事情。
阿姆達(dá)爾定律中有一點(diǎn)是明確的,那就是當(dāng)你為性能使用并發(fā)的時(shí)候,值得考慮總體應(yīng)用的設(shè)計(jì)來(lái)最大化并發(fā)的可能性,并且確保處理器始終有有用的工作來(lái)完成。如果你可以減少“串行”部分或者減少線程等待的可能性,你就可以提高在有更多處理器的系統(tǒng)上的性能。或者,如果你可以為系統(tǒng)提供更多的數(shù)據(jù),并且保持并行部分準(zhǔn)備工作,就可以減少串行部分,增加性能P的值。
從根本上說(shuō),可擴(kuò)展性就是當(dāng)增加更多的處理器的時(shí)候,可以減少它執(zhí)行操作的時(shí)間或者增加在一段時(shí)間內(nèi)處理的數(shù)據(jù)數(shù)量。有時(shí)這兩點(diǎn)是相同的(如果每個(gè)元素可以處理得更快,那么你就可以處理更多數(shù)據(jù)) ,但是并不總是一樣的。在選擇在線程間劃分工作的方法之前,識(shí)別出可擴(kuò)展性的哪些方面對(duì)你很重要是很必要的。
在這部分的開(kāi)始我就提到過(guò)線程并不是總有有用的工作來(lái)做。有時(shí)它們必須等待別的線程,或者等待I/O操作完成,或者別的事情。如果在等待中你給系統(tǒng)一些有用的事情,你就可以有效的"隱藏等待。
8.4.3用多線程隱藏遲
在很多關(guān)于多線程代碼性能的討論中,我們都假設(shè)當(dāng)它們真正在處理器上運(yùn)行時(shí),線程在"全力以赴的運(yùn)行并且總是有有用的工作來(lái)做。這當(dāng)然不是正確的,在應(yīng)用代碼中,線程在等待的時(shí)候總是頻繁地被阻塞。例如,它們可能在等待一些I/O操作的完成,等待獲得互斥元,等待另一個(gè)線程完成一些操作并且通知一個(gè)條件變量,或者只是休眠一段時(shí)間。
無(wú)論等待的原因是什么,如果你只有和系統(tǒng)中物理處理單元一樣多的線程,那么有阻塞的線程就意味著你在浪費(fèi)CPU時(shí)間。運(yùn)行一個(gè)被阻塞的線程的處理器不做任何事情。因此,如果你知道一個(gè)線程將會(huì)有相當(dāng)一部分時(shí)間在等待,那么你就可以通過(guò)運(yùn)行一個(gè)或多個(gè)附加線程來(lái)使用那個(gè)空閑的CPU時(shí)間。
考慮一個(gè)病毒掃描應(yīng)用,它使用管道在線程間劃分工作。第一個(gè)線程搜索文件系統(tǒng)來(lái)檢查文件并且將它們放到隊(duì)列中。同時(shí),另一個(gè)線程獲得隊(duì)列中的文件名,載入文件,并且掃描它們的病毒。你知道搜索文件系統(tǒng)的文件來(lái)掃描的線程肯定會(huì)達(dá)到I/O界限,因此你就可以通過(guò)運(yùn)行一個(gè)附加的掃描線程來(lái)使用“空閑的"CPU時(shí)間。那么你就有一個(gè)搜索文件線程,以及與系統(tǒng)中的物理核或者處理器相同數(shù)量的掃描線程。因?yàn)閽呙杈€程可能也不得不從磁盤(pán)讀取文件的重要部分來(lái)掃描它們,擁有更多掃描線程也是很有意義的。但是在某個(gè)時(shí)刻會(huì)有太多線程,系統(tǒng)會(huì)再次慢下來(lái)因?yàn)樗烁鄷r(shí)間切換程序,正如8.2.5節(jié)所描述的。
仍然,這是一個(gè)最優(yōu)化問(wèn)題,因此測(cè)量線程數(shù)量改變前后的性能時(shí)很重要的;最有的線程數(shù)量將很大程度上取決于工作的性質(zhì)和線程等待的時(shí)間所占的比例。
取決于應(yīng)用,它也可能用完空閑的CPU時(shí)間而沒(méi)有運(yùn)行附加的線程。例如,如果一個(gè)線程因?yàn)榈却齀/O操作的完成而被阻塞,那么使用可獲得的異步I/O操作就很有意義了。那么當(dāng)在背后執(zhí)行I/O操作的時(shí)候,線程就可以執(zhí)行別的有用的工作了。在別的情況下,如果一個(gè)線程在等待另一個(gè)線程執(zhí)行一個(gè)操作,那么等待的線程就可以自己執(zhí)行那個(gè)操作而不是被阻塞,正如第7章中的無(wú)鎖隊(duì)列。在一個(gè)極端的情況下,如果線程等待完成一個(gè)任務(wù)并且該任務(wù)沒(méi)有被其他線程執(zhí)行,等待的線程可以在它內(nèi)部或者另一個(gè)未完成的任務(wù)中執(zhí)行這個(gè)任務(wù)。清單8.1中你看到了這個(gè)例子,在排序程序中只要它需要的塊沒(méi)有排好序就不停地排序它。
有時(shí)它增加線程來(lái)確保外部事件及時(shí)被處理來(lái)增加系統(tǒng)響應(yīng)性,而不是增加線程來(lái)確保所有可得到的處理器都被應(yīng)用了。
8.4.4 用并發(fā)提高響應(yīng)性
很多現(xiàn)代圖形用戶(hù)接口框架是事件驅(qū)動(dòng)的,使用者通過(guò)鍵盤(pán)輸入或者移動(dòng)鼠標(biāo)在用戶(hù)接口上執(zhí)行操作,這會(huì)產(chǎn)生一系列的事件或者消息,稍后應(yīng)用就會(huì)處理它。系統(tǒng)自己也會(huì)產(chǎn)生消息或者事件。為了確保所有事件和消息都能被正確處理,通常應(yīng)用都有下面所示的一個(gè)事件循環(huán)。

顯然, API的細(xì)節(jié)是不同的,但是結(jié)構(gòu)通常是一樣的,等待一個(gè)事件,做需要的操作來(lái)處理它,然后等待下一個(gè)事件。如果你有單線程應(yīng)用,就會(huì)導(dǎo)致長(zhǎng)時(shí)間運(yùn)行的任務(wù)很難被寫(xiě)入,如8.1.3節(jié)描述的。為了確保用戶(hù)輸入能被及時(shí)處理, get_event()和process()必須以合理的頻率被調(diào)用,無(wú)論應(yīng)用在做什么操作。這就意味著要么任務(wù)必須定期暫停并且將控制交給事件循環(huán),要么方便的時(shí)候在代碼中調(diào)用get_event()/
process()代碼。每一種選擇都將任務(wù)的實(shí)現(xiàn)變得復(fù)雜了。
通過(guò)用并發(fā)分離關(guān)注點(diǎn),你就可以將長(zhǎng)任務(wù)在一個(gè)新線程上執(zhí)行,并且用一個(gè)專(zhuān)用的GUI線程來(lái)處理事件。線程可以通過(guò)簡(jiǎn)單的方法互相訪問(wèn),而不是必須以某種方式將事件處理代碼放到任務(wù)代碼中。清單8.6列出了這種分離的簡(jiǎn)單概括。
清單8.6從任務(wù)線程中分離GUI線程

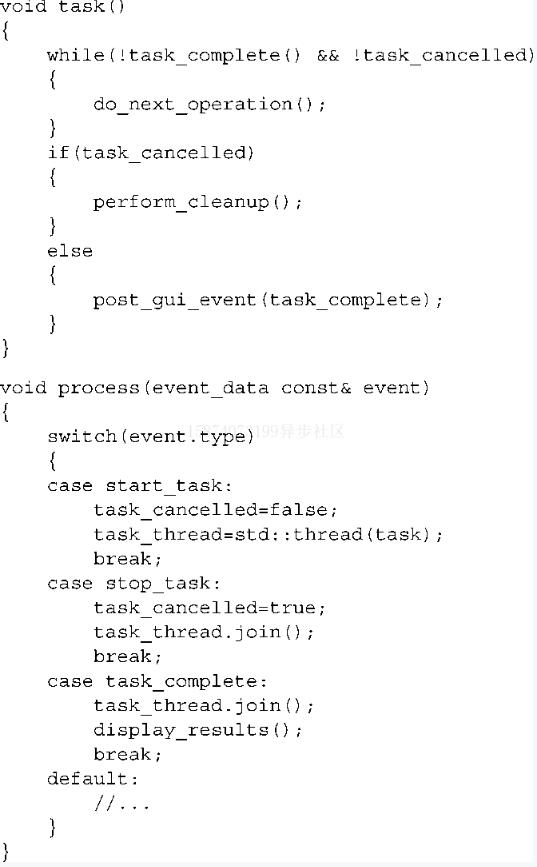
通過(guò)這種方式分離障礙,用戶(hù)線程能夠及時(shí)地響應(yīng)事件,即使任務(wù)要執(zhí)行很長(zhǎng)時(shí)間。這種響應(yīng)性通常是使用應(yīng)用時(shí)用戶(hù)體驗(yàn)的關(guān)鍵。無(wú)論何時(shí)執(zhí)行一個(gè)特定操作(無(wú)論該操作是什么) ,應(yīng)用都會(huì)被完全鎖住,這樣使用起來(lái)就不方便了。通過(guò)提供一個(gè)專(zhuān)用的事件處理線程, GUI可以處理GUI特有的消息(例如調(diào)整窗口大小或者重畫(huà)窗口)而不會(huì)中斷耗時(shí)處理的執(zhí)行,并且當(dāng)它們確實(shí)影響長(zhǎng)任務(wù)時(shí)會(huì)傳遞相關(guān)的消息。
本章你看到了設(shè)計(jì)并發(fā)代碼的時(shí)候需要考慮的問(wèn)題。就整體而言,這些問(wèn)題是很大的,但是當(dāng)你習(xí)慣了"多線程編程",它們就會(huì)變得得心應(yīng)手了。如果這些考慮對(duì)你來(lái)說(shuō)很新,那么希望當(dāng)你看到它們是如何影響多線程代碼的具體例子的時(shí)候,可以變得更清晰。





















