日均7億交易量,為什么我們要用MySQL?
今天分享的主題是工行“去 O”數據庫選型與分布式架構設計。
圖片來自 Pexels
本次分享分為三個章節:
- 金融行業的需求核心與策略
- 工行數據庫選型的發展歷程,即方案選型歷程
- 轉型中遇到的各種心酸坑
金融行業的核心需求與策略
傳統 IT 架構挑戰
大家可能都知道,工行最早是基于 IBM 大型主機搭建的核心系統,以及基于 Oracle 和 IBM WAS 搭建的 OLTP 系統,在分布式體系大熱之前處于同業領先地位。
當然現在也是處于同業領先的,但是科技成本也相對較高,所謂的一份價錢一分貨就是這個道理。

但是隨著分布式技術的成熟,傳統的 IT 架構面臨著四大挑戰:
①從處理能力層面來看,傳統應用(也叫巨石型應用)系統規模龐大,采用集中式架構設計,使用單一系統垂直擴展模式,擴展能力相對來說是有限的。
另一方面,大數據時代引發海量數據分析處理和存儲處理的問題,對擴展性、可靠性和吞吐量提出了較高要求。
②從運行風險層面來看,客戶對金融行業的系統有著更高的業務連續性保障要求,對不可用問題實際上是零容忍的,比如要求 7*24 小時業務不能中斷。
③從快速交付層面來看,傳統巨石型應用實際上與快速交付是相悖的,應用內部模塊、應用與應用之間耦合度高,使得軟件開發和產品服務交付周期長,無法滿足業務快速上線的需求,從而逐漸泯然眾人矣,淹沒在茫茫的金融行業洪流中。
大家可以看到不論是金融科技還是科技金融,一大堆的金融公司已經淹沒在前浪里。
④從成本控制來看,大型主機運營費用昂貴,商業產品 License 費用高,買個機器和服務隨隨便便就幾千萬上億的支出,真的是太貴了,所以隨著業務系統做大做強,產品成本可能會成為壓死駱駝的最后一根稻草。
為此,我們可以首先得出三點需求:
- 應該優化應用架構、數據架構和技術架構。
- 應該建設靈活開放、高效協同、安全穩定的 IT 架構體系。
- 能夠強化對業務快速創新發展的科技支撐。
雙十一壓力
說到這里,就不得不吐槽阿里的“雙十一”,將購買壓縮到一天,對顧客和金融系統來說造成雙重壓力,相較而言,京東的 618 就比較人性化,每天都可以剁手。

我們可以看下雙十一的峰值變化情況,從 2009 年開始,峰值只有 400 筆/秒,相較主機而言,有很大的差距,當然這也與他們當時的名氣小有關。
但是 2015 年開始,借著云化和分布式的大旗,以及當時 BAT 的領頭羊地位,僅 4 年時間,就從 2015 年的 14 萬筆/秒迅速攀升至 2019 年的 54 萬 4 千筆/秒。
這就給金融行業的系統建設帶來了四個問題:
①高并發問題,我們可以看到,阿里為了提升峰值,做了大量的緩存,鼓勵使用花唄,降低與外系統的交互,但是依然對金融行業產生額外的壓力。
②高可靠性要求,確保系統穩定可靠,客戶可以穩定支付成功,避免因不佳的客戶體現導致用戶流失。
③高成本壓力,大幅擴容的設備,以及隨之產生的運維成本,以及昂貴的商業 liscence,給金融行業帶來一定的成本負擔。
④同業競爭要求,大家都在做競品分析,和同行進行比較,所以別人 ok,你掛了,你面子上還掛的住么,所以各機構在雙十一前進行大量的模擬測試,類似于高考前的黑暗日子。
金融行業分布式的核心訴求及策略

為此,金融行業分布式的核心訴求及策略可以總結為以下五點:
①應該具備企業級的業務支撐能力,支持高并發、可擴展和海量數據庫存儲及訪問;原則上應支持同城雙活,實現集中式向分布式的轉型。工行的兩地三中心容災體系在國有大型銀行中屬于第一梯隊。
②應能大幅降低使用成本,可以基于通用的廉價的 X86 硬件基礎設施;降低商業產品依賴,擁抱開源產品,互聯網企業已經給我們做了一個很好的參考。
③應該提升數據庫的運維自動化和智能化能力,支持與自身系統進行適配性定制,工行即實現了行內系統適配定制。
④金融行業還應考慮到社會聲譽性要求,客戶對金融行業的期望很高,特別是對銀行等金融組織,所以要求也更加嚴格,原則上應該是 7*24 小時的不間斷服務。
像當年支付寶在 2015 年的支付癱瘓事件僅僅上了下熱搜,但是 2013 年工行因為 IBM 主機 Bug 的問題卻上了新聞聯播,這就是所謂的愛之深責之切吧。
⑤要考慮到政治因素風險,雖然全球化要求技術無國界,但是從去年開始的貿易戰,以及美國的實體管制清單,我們可以看到技術是有國界的。
近期 HashiCorp 發布公告,其企業版產品禁止中國使用已經引發了一種擔憂。說起 HashCorp ,大家可能不一定熟悉,但是其旗下有大名鼎鼎的產品 Consul,可以簡化分布式環境中的服務注冊與發現流程,大家一定耳熟能詳。
最后中國人民銀行在 2019 年 8 月 23 日發布了《金融科技(FinTech)發展規劃(2019-2021)》中提到“做好分布式數據庫金融應用的長期規劃,加大研發與應用投入力度,妥善解決分布式數據庫產品在數據一致性、實際場景驗證、遷移保障規范、新型運維體系等方面的問題,這也給金融行業指明了方向。
選型的發展歷程(方案選型歷程)
接下來,給大家介紹下如何選型以及工行的選型歷程。
工行分布式轉型發展歷程
大家可以看下工行分布式的發展歷程:

其大致可分為 2 個關鍵階段,2016 年初-2017 年末為基礎研究及試點階段,之后為轉型實施及推廣階段。
大致有如下五個關鍵時點:
- 2016 年初工行進行分布式體系研究,建立了基于 Dubbo 框架的分布式生態服務。
- 2016 年底借著人民銀行對于個人賬戶的管理要求,實行三類賬戶的場景,開始了基于分布式的 OLTP 數據庫研究,并確定了基于開源 MySQL 的 OLTP 數據庫解決方案,因為 MySQL 8.0 的不成熟,所以我們采用了 MySQL 5.7。
- 2017 年末,我們完成開源 MySQL 初步能力體系的建設,涵蓋了基礎研究、配套方法論、應用試點等等。
- 2018 年開始大規模的實施和推廣,我們逐步建立企業級的數據庫服務能力,包括引入了分布式的中間件,在高可用、運維能力的提升,資源使用率的提升,MySQL 上云及自主服務的建設等等,同時開啟了對 OLTP 的分布式數據庫進行了研究。
- 2019 年 11 月我們實現了國產分布式數據庫產品 GaussDB 試點上線。
方案選型調研
大家可以看下工行的選型過程,希望可以給大家帶來一定的參考:

工行的技術規劃是相當嚴謹的,所以當時我們從五個層次進行了考量:OLTP 分布式數據庫、NewSQL 數據庫、支持分布式架構、自主可控、開源抑或商業。
當時我們的第一個疑問是,到底是選 NoSQL、NewSQL 還是關系型數據庫。
當時 MongoDB、Redis、Cassandra、HBASE 等 NoSQL 數據庫開始在某些場景下大熱,但是可用場景不滿足我們的 OLTP 業務場景需求。
NewSQL 隨著 Google 的 Spanner 和 F1 開始進入大家的視野,但是國內可以考據的只有相關的 paper;國產的 TiDB 也是小荷初露尖尖角,但是畢竟還是幼兒期。
而 DB-Egines 發布的《2016 年全球數據庫大盤點》,Oracle、MySQL 和 SQL Server 三大數據庫產品遙遙領先。
MySQL 當時在互聯網公司的名氣是越來越響,谷歌、淘寶、百度、騰訊、豆瓣、網易、臉書等都使用了 MySQL。
一方面 MySQL 提供了免費版,另一方面 Oracle 收購 Sun 后,可以很明顯的看到 MySQL 越來越規范,5.5、5.6、5.7 均可以看到很明顯的提升,5.7 號稱性能是 5.6 的 3 倍,5.6 號稱是 5.5 的 2 倍。
為此,我們經過謹慎的驗證,選取了 MySQL 作為分布式數據庫的第一選型,畢竟業界有很多豐富的案例。
而且在互聯網企業里面得到了很好的實踐,在業界資源案例和周邊產品都很豐富,能應對我行的高并發、彈性擴展需求。
同時其具有如下特點:
- 開源,基于 GPL(GNU 通用許可證)可以免費使用修改,當時很多公司都基于 MySQL 進行了深入定制,但是在與他們的交流過程中,發現版本歸并真的是一種夢魘。
- 高可用,具有優秀的架構設計及相當豐富的周邊產品,實現了企業級的高可用性和高擴展性。
- 免費,有效降低企業運行成本。
- 趨勢,產品成熟度、排名一直遙遙領先,占行業應用的比重增大,產業鏈豐富,從業人員有規模效應。
然后我們選擇了 MySQL 5.7,其相較之前的版本有六個優點:
- InnoDB 增強,在線修改 ibp,快速擴展 VARCHAR,UNDO 可回收,可關閉死鎖檢測。
- 復制增強,多源復制,基于 WRITESET 的并行復制,增強半同步,在線設置 repl filter。
- 優化器增強,幾乎重構優化器,EXPLAIN 增強,引入 Optimizer Hints。
- 安全性增強,新增密碼過期機制,支持賬號鎖定等。
- 功能增強,默認開啟 PFS,新增 sys schema 等。
- 其他增強,支持多個觸發器,新增 Query Rewrite,支持設置 SQL 執行最長時間。
方案技術棧
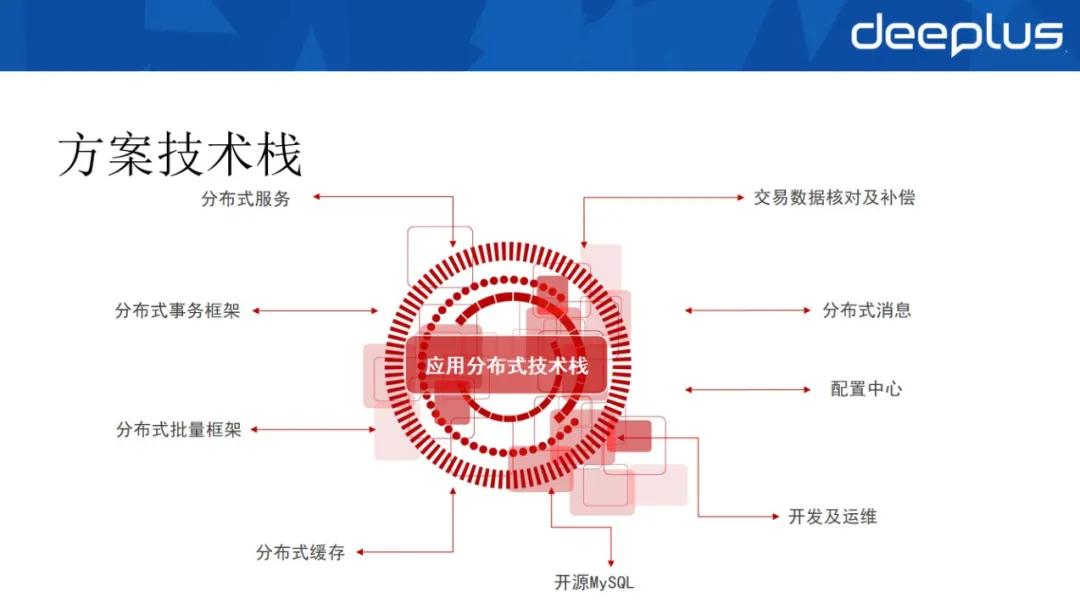
基于 MySQL 選型,還應考慮一系列的分布式架構技術棧,包括分布式服務、分布式事務框架、分布式批量框架、分布式緩存、交易數據核對及補償、分布式消息、配置中心、開發及運維管理。
這里提醒下大家,在選型上沒有最好的產品,只有最適合自己的產品:
①分布式事務,業界實際上有多種解決方案,2PC(2 階段式事務提交)、3PC、TCC 和 SAGA 模型等等,我們這 4 種方案我行都有應用在使用,互為補充,滿足不同業務場景對事務強一致性或最終一致性的要求。
②業務層面,在交易或者應用級層面進行數據核對及補償,有些場景就是在傳統的 OLTP 的情況下,也會對應用上下游進行核對和補償。
③分布式消息,我們選取了 Kafka 作為分布式消息中間件。
④分布式批量框架,在大規模的數據結點上進行批量操作的一個整體的解決方案。
⑤運維層面,我行建立了統一的運維管理平臺,納入所有數據庫節點,實現一鍵式的數據庫安裝、版本升級、基線參數配置等等。并且實現了多種高可用策略配置,包括自動、人工一鍵式切換。
為什么要有自動化和人工的兩種切換方式?這里我要解釋下,一種新的事務上線之前,都會面臨一些挑戰和懷疑的,都是一個循序漸進的過程,特別是是在金融行業,自動真的好么?萬一搞錯了怎么辦?決策因素和模型是否設計正確?設計正確了是否編碼正確?
最難的是還要應對不同應用場景的需求,有的應用要求 RPO 優先,有的應用又要求 RTO 優先。
我們之前經過充分調研,預見到該種情況,所以我們提供了多種高可用策略的靈活配置,以便滿足不同應用的個性化要求。
我們的高可用整體上面基于 MySQL 的復制技術,通過半同步復制和多數派共識機制實現冗余備份,基于 MySQL binlog 日志實現自動數據補全,保障數據的一致性。
其他考量
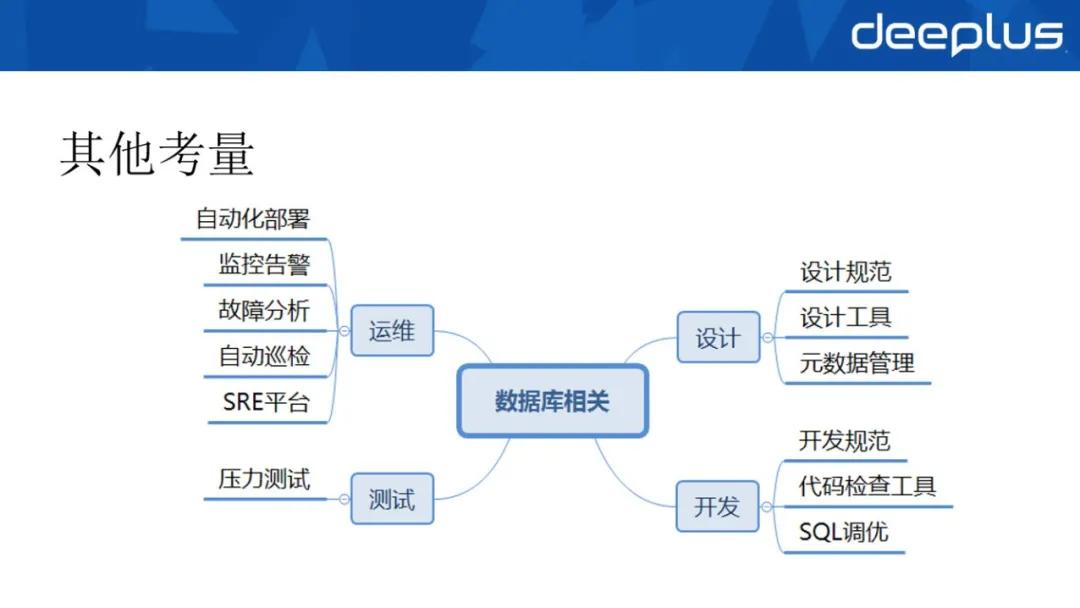
除此以外,數據庫選型后,還應完善相關體系,規范設計、開發、測試和運維,實現管控的體系化和自動化,才能避免眼高手低,減少生產安全風險。
①在設計層面,在驗證功能、新特性和配置基線,數據備份恢復的基礎上,我們參考了愛可生、阿里等公司的規約,建立了 MySQL 設計指引,可以說,我們是站在巨人的肩膀上成長的。
加強元數據管理,提出元數據完備性、明確性、具象性和前瞻性的要求,建立應用的元數據標準,統一數據架構設計,架構師設計表結構時均基于元數據進行設計,提升數據架構質量。
此外,我們還開發了表結構設計工具,將其融合在 Excel 中,實現對元數據的自動應用,支持自動生成腳本,簡化架構師的貫標操作,將人員成熟度的要求降至最低,提升設計效能和質量。
②在開發層面,我們制訂了開發規范和 SQL 調優指引,同時基于 sonar 開發了 MySQL 檢查工具,支持對基于 myBatis 的 mapper 文件進行解析,提前發現 SQL 不規范的寫法。
同時將 sonarlint 插件納入開發人員必備插件,實現規則的云化部署和本地聯動掃描分析,將規范融入開發過程中,提升開發人員的 SQL 編寫能力。
③在測試層面,我們自研壓力測試服務平臺,盡量減少性能瓶頸,提前發現 SQL 性能問題。
④在運維層面,感覺應該是最重要的一個層面,我們需要考慮自動化部署、監控告警、故障分析、自動巡檢以及 SRE 平臺,還有數據遷移、備份恢復、配置管理、版本升級、多租戶等等。
隨著節點的增加,運維實際上是一個很大的挑戰,幾千幾萬個節點,安裝、監控、報警、故障、人工處理等非常麻煩。
必須要實現自動化的安裝部署,進行批量安裝部署,同時批量串行還不行,時間太長了,要并行,并行太高了,網絡的流量又會受到很大的影響,所以很多場景都需要細細打磨,還要按照博弈論的思路建立納什均衡。
監控告警里有事件等級,如何劃分各種等級,都需要靈活定制支持,建立基線告警,建立應急流程。
像華為等公司都有基于設備的網絡拓撲圖,問題在哪個節點,可以快速分析和定位,所以說運維是一個很麻煩的事情,像故障分析,完善日志記錄、采集和分析,建立故障分析規范。
自動巡檢,自動化的巡檢和評分報告,對實例狀態進行健康評分。在這個階段我們實現了同城 RPO=0,RTO=分鐘級目標,RPO 為 0 的切換,問題可監控,實現了人工或自動的一鍵式切換。
最后我們不得不提到 SRE,很多人會聯想到運維工程師、系統工程師,其實不然,SRE 本質上仍然是軟件工程師。
SRE 最早在十多年前 Google 提出并應用,近幾年逐步在國內外 TOP 互聯網公司都開始廣泛應用。
其中 Google 締造了 SRE,并奠定了其權威的地位,而 Netflix 將 SRE 的實踐做到了極致,Netflix 僅有的個位數的 Core SRE 支持了 190 個國家、數億用戶、數萬微服務實例業務規模的運維。
像數據庫瓶頸,頂配數據庫空間仍然無法支撐業務半年發展;慢 SQL 數量爆發式增長,應用穩定性岌岌可危;人工運維風險極高;人工運維頻率高,研發幸福感下降這些大家都會遇到的問題也會逐漸地遇到。
他山之石,可以攻玉,我們完全可以把別人的挫折拿過來,避免自己走彎路。
MySQL 上云
在逐步推進的過程中,完善選型體系建設后,為了確保資源的有效利用,上云實際上是一種必然的選擇。
從工行來看,經歷 1-2 年的發展,MySQL 數據庫節點就已經增至幾千套,機房和設備實際上已成為一個瓶頸,再這么玩兒下去機房容量不足了,所以必須提升資源的使用效率。
我行新建應用時,一般都會進行 1-3 年的一個超前規劃,業界也是同樣的做法,為了穩定運行,避免出現資源瓶頸,基本上提交資源申請時,都選擇物理機。
但是大規模的申請物理機,而當前應用的交易量又無法達標,所以資源浪費非常嚴重。
根據評測,相較 Oracle,MySQL 數據庫實例單體性能容量較小,數據容量普遍小于 500G,同時超過一定容量的就要進行分庫,但是一臺物理機部署 1 個數據庫的方式并未發生變化,MySQL 的服務器資源密度較低。
同時運維效率低,在服務器、存儲、網絡等基礎設施環節的運維和交付仍然需要大量手工操作。
業界普遍的做法就是將 MySQL 上云,實現云化部署,借助成熟的云體系實現彈性伸縮和動態擴容。
工行有個優勢,IAAS 和 PAAS 云處于同業領先地位,有著豐富的經驗積累,為此結合行內對于云戰略的規劃,MySQL 上云是一種必然趨勢。
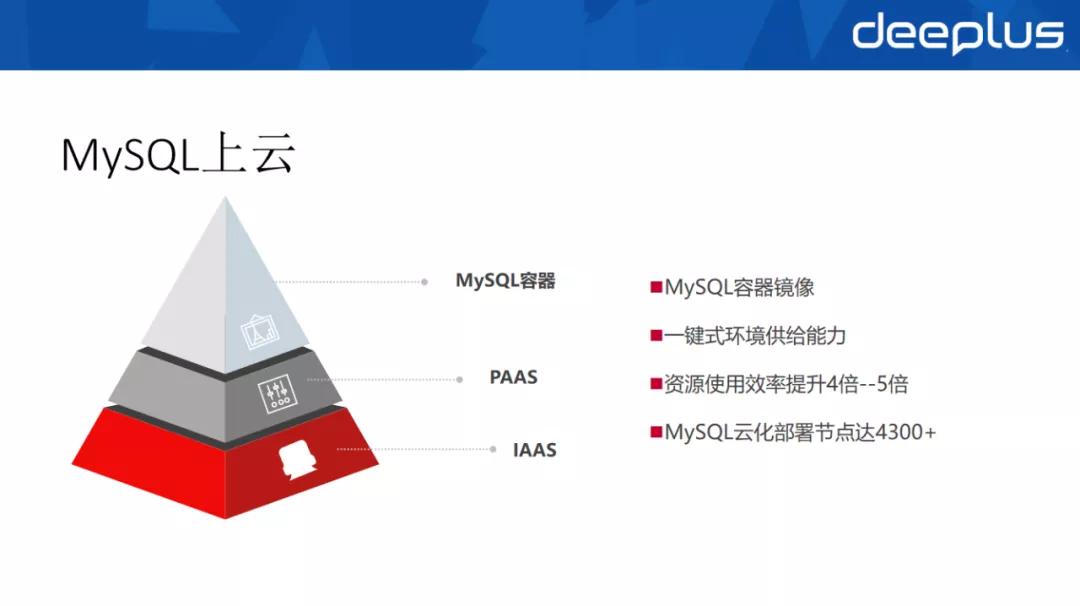
我們提供了 MySQL 的容器鏡像,提供了一鍵式的環境供給能力,通過上容器把 IAAS、PAAS 全部打通,支持快速搭建符合行內標準的基礎環境,提升環境支持能力。
工行基于 K8S、SDN、IAAS 建設持久性的狀態容器運行集群,通過 SDN 實現容器網絡資源的自動化申請,通過底層擴展 K8S 實現容器的固定 IP,業界一般會采用 K8S Operator 實現容器的有狀態資源綁定,也包含了固定 IP 綁定。
保守估計,資源的使用效率至少提升了 4 到 5 倍。而且,我們的工作成果也相當喜人,截止當前工行的 MySQL 云化部署節點已達 4300 多個。
工行實施效果
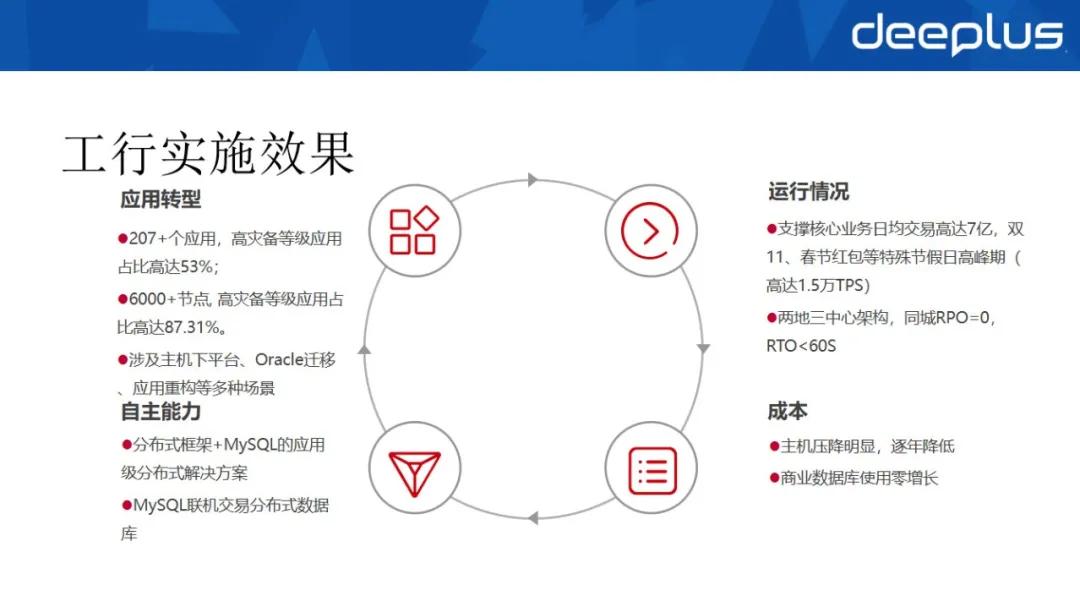
我們可以看下工行的轉型成效,首先看下數據:
①我們已實施 200 多個應用,高災備等級應用占比高達 53%。
②6000 多個 MySQL 節點,高災備等級應用占比高達 87.31%。
③實施的應用涉及很多核心業務,包括個人、對公、基金以及很多高災備等級應用,大多數為主機下平臺遷移應用,少量應用是從 Oracle 遷移過來的,因為工行將 PLSQL 存儲過程用到了極致,所以應用層也因此需要重構。
④我們通過 MySQL 支持的核心交易可以達到日均 7 億的交易量,經歷過雙十一和春節的多重考驗,峰值 TPS 至少可以達到 1.5 萬 TPS,同時支持橫向擴展,理論上通過擴展設備還可以無限地增加。
而如果通過主機想達成這個目標,那么挑戰就會比較大,這就是建摩天大廈和建排屋的區別。
⑤通過良好的架構設計,我們可以滿足兩地三中心的架構要求,做到同城 RPO=0,RTO<60s。
⑥在自主能力方面,初步建立了企業級的基于 MySQL 的分布式解決的自主能力:首先是分布式框架+MySQL 的應用級分布式解決方案,該方案承載了我行很多主機下平臺應用。
其次是基于分布式中間件 DBLE(原型為 MyCat,后經愛可生公司優化為 DBLE,同時我行進行了深度優化和開發)建立數據訪問層,支持應對一些不是很復雜的場景,通過良好設計的分庫分表方案即可滿足需求。
⑦在成本方面,我行在主機上的成本投入明顯下降,近幾年我行的業務交易量每年以 20% 的速度增長,但是主機并沒有進行擴容,投入還逐年降低。
商業產品的數據庫的使用不僅實現零增長,還有所下降。從整個經費上來說,有非常大的降幅。
典型實施案例:信息輔助服務
介紹一下我行的典型案例:信息輔助系統。
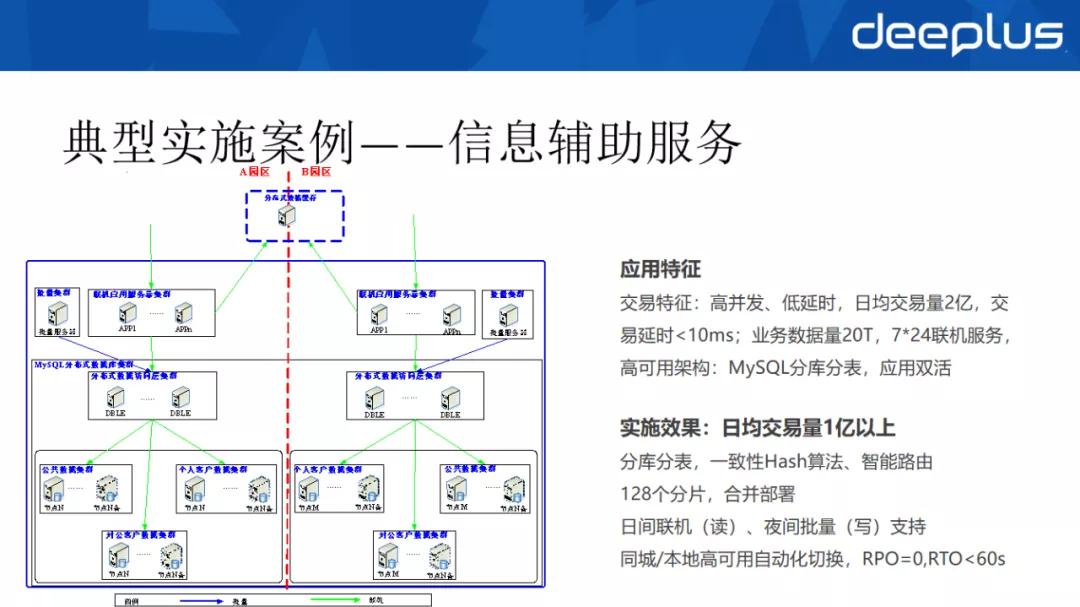
從應用場景分析其需求,需要支持高并發、低延時,日均交易量為 2 億,交易響應延時要求 10ms 以內,業務數據量大概 20T 左右,要求 7×24 小時的聯機服務,這就對應用的高可用提出了新的要求。
為此,通過統一運維管理平臺,吸納所有節點,實現一鍵式的安裝、版本的升級、參數的配置。
①設計層面通過分布式數據中間件 DBLE,進行分庫分表,規劃了 128個 分片,并對分片進行了合并部署,雖然相較于阿里的 1024 分片來說較少,但是我們使用了一致性 hash 算法,在資源使用上收益很大。
②DBLE 中間件在日間進行聯機服務,夜間進行批量變更,把主機上的一些數據同步下來,減少批量作業對聯機作業的影響。
③目前我們的高可用架構采用一主三從(1 主庫、1 本地半同步庫、2 同城半同步庫)架構,基于 MySQL 的半同步復制,實現園區級的 RPO=0。
通過 DBLE 中間件和管理平臺聯動完成實現了本地和同城的自動化切換,RPO=0,RTO<60S,完全滿足工行的業務要求。
最后補充說明下,為了實現數據庫層面的高可用, DBLE 到數據庫的訪問同一配置為實 IP。
④這里我補充下我們高可用的發展史,其實我們對高可用方案進行了持續的優化。
同時學習和借鑒互聯網包括分布式數據庫的一些方案,從 1 主 2 備,本地 1 備和同城 1 備,擴展成 1 主 3 備,通過半同步的機制,做到真正的在系統級去保證 RPO=0。
⑤在異地災備方面。最開始采用磁盤復制實現災備,一方面成本比較高,另一方面是冷備,無法熱切換,RTO 至少半個小時以上。所以我們后期用了 MySQL 異步復制。
在存儲方面采用集中存儲,一套集中存儲上面需要同時支撐上百個 MySQL 實例,IO 性能直接成為瓶頸,為了應對高并發場景時的 IO 瓶頸,我們直接引入 SSD 盤,基本上把 MySQL 的 IO 瓶頸給解決了。
轉型中遇到的各種心酸坑
最后我們說下我行轉型過程中遇到的心酸坑。
其實如果使用過 MySQL 5.7 的企業,肯定都遇到過相似的問題,比如超過 MySQL 的默認閑置時間導致的連接超時、dependent subquery 導致的語句效率差、字符集亂碼等等。
以及 MySQL 的自身 Bug,比如 Intel PAUSE 指令周期的迭代引發 MySQL 的性能瓶頸。
畢竟免費的午餐并不是那么完美,總是會有或多或少的問題需要規避。

我這里說下讓我痛心疾首的幾個心酸坑吧:
坑一:慢 SQL 數量爆發式增長,應用隱患逐步暴露,在阿里等互聯網公司和我行都是一個痛點,值得大家警醒和重視。
我行 OLTP 之前為 Oracle 數據庫,借助于 Oracle 良好的優化器,大家習慣于 5 張表左右的連接,但是遷移至 MySQL 后,習慣沒有及時轉換過來,一個慢 SQL 可能就導致服務不可用,降低用戶幸福指數。
為此我們規劃了三個方面的改善措施:
①設計層面制定了規范,強調數據設計的合理性,組織 DBA 進行內部復核,提前規避設計問題,比如 3NF、BCNF 的設計遵循、可控性冗余處理(空間換時間或時間環空)等等,通過輔助工具的自動化手段,從源頭扼殺風險。
②開發層面我們基于 Sonar 開發了自動化檢查工具,支持分析 mapper 文件,既然開發人員沒空看規范,那我們工具輔助,增加質量門禁,強制將規范融合至開發過程中,進一步降低風險。
但是對新人可能不友好,以前看到一個新人的朋友圈的哭訴,被質量門禁卡的無法提交代碼,一直苦逼的加班整改。
③運維層面我們建立了 SRE 平臺,監測慢 SQL 語句,并分批次要求整改,將結果都擺在臺面上,真的不是我們不給力,而是應用開發不給力啊。
坑二:在 MySQL 5.7 中,表的 TRUNCATE 操作存在 Bug,對應編號 68184,會阻塞整個數據庫實例上的所有其他交易。
所以對大表進行 TRUNCATE 操作會影響整個 MySQL 數據庫的處理性能,即使是訪問不想關的表也會收到影響。
此時你就會收到一群開發人員的請求,哎呀,數據庫夯住了,求救啊,實際上解決方案也很簡單,因為 Drop 語句不受影響,所以映射為 DROP+CREATE 的操作即可規避該 Bug,而 MySQL 8.0 也將其進行了同樣的映射。
所以我們將其固化到設計開發規范中,提醒相關人員進行注意,同時在工具中增加 TRUNCATE 關鍵字識別檢查,做到提前預防。
坑三:MySQL 的超時中斷,wait_timeout 參數,即 MySQL 客戶端的數據庫連接閑置最大時間值(秒),我行設置為 1 小時。
如果長連接的空閑時間超過該參數設置時間,數據庫連接就會被 MySQL 主動斷開,而中間件的連接池的連接就處于“假活“狀態。
一般的建議方法就是增加心跳監測,使用 dbcp 設置 testWhileIdle、validationQuery 等參數,如果跟我行一樣使用 WAS 的,在 WAS 控制臺上設置時效超時的參數即可。
坑四:Replce Into 引發的自增列主鍵沖突 Bug,對應編號 73563,主庫在執行 replace 操作時,如果有數據沖突,會轉換為一筆 delete+一筆 insert。
所以主庫無問題,但是 binglog 記錄的為 update 操作,備庫重做 update 動作,更新主鍵,但由于 update 動作不會更新自增列值,導致更新后記錄值大于自增列值。
當此時發生主備切換時,備庫提升為主庫,插入的自增列主鍵會取自增列的值,從而引發主鍵沖突。
解決方案也屬于應急方案,可以在發生問題時,通過 ALTER 語句將自增列增加。
另一種解決方案,可以在 replace into 之后開啟一個新的事務,插入一條無意義的記錄然后刪除掉,可以保證主備一致。
最后一種解決方案,是直接用雪花算法計算遞增序列號。
作者:魏亞東
簡介:中國工商銀行軟件開發中心三級經理,資深架構師。杭州研發部數據庫專家牽頭人和開發中心安全團隊成員,負責技術管理、數據庫和安全相關工作。2009 年加入中國工商銀行軟件開發中心,致力于推動管理創新、效能提升,提供全面技術管控,推動自動化實施,實現業務價值的高質量快速交付;同時作為技術專家,為生產安全提供技術支持。
編輯:陶家龍
出處:轉載自微信公眾號 DBAplus 社群(ID:dbaplus),本文根據魏亞東老師在〖deeplus 直播第 225 期〗線上分享演講內容整理而成。