1分鐘,啥是數據庫讀寫分離架構?
作者:58沈劍
數據庫讀寫分離雖然不難,但并不是所有的“數據庫扛不住”的場景,都應該用讀寫分離。今天花1分鐘簡單介紹下這個場景。
RD:數據量太大,數據庫扛不住了,幫忙申請一個從庫,讀寫分離。
DBA:數據量多少?
RD:5000w左右。
DBA:讀寫吞吐量呢?
RD:讀QPS約200,寫QPS約30左右。
額,數據庫讀寫分離雖然不難,但并不是所有的“數據庫扛不住”的場景,都應該用讀寫分離。今天花1分鐘簡單介紹下這個場景。
什么是數據庫讀寫分離?
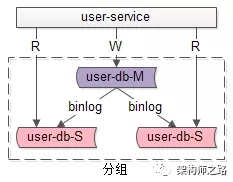
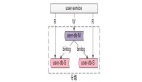
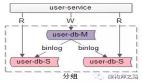
一主多從,讀寫分離,主動同步,是一種常見的數據庫架構,一般來說:
- 主庫,提供數據庫寫服務
- 從庫,提供數據庫讀服務
- 主從之間,通過某種機制同步數據,例如mysql的binlog
一個組從同步集群通常稱為一個“分組”。
分組架構究竟解決什么問題?
大部分互聯網業務讀多寫少,數據庫的讀往往最先成為性能瓶頸,如果希望:
- 線性提升數據庫讀性能
- 通過消除讀寫鎖沖突提升數據庫寫性能
此時可以使用分組架構。
一句話,分組主要解決“數據庫讀性能瓶頸”問題,在數據庫扛不住讀的時候,通常讀寫分離,通過增加從庫線性提升系統讀性能。
什么是數據庫水平切分?
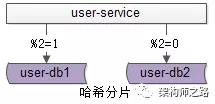
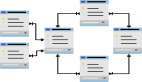
水平切分,也是一種常見的數據庫架構,一般來說:
- 每個數據庫之間沒有數據重合,沒有類似binlog同步的關聯
- 所有數據并集,組成全部數據
- 會用算法,來完成數據分割,例如“取模”
一個水平切分集群中的每一個數據庫,通常稱為一個“分片”。
水平切分架構究竟解決什么問題?
大部分互聯網業務數據量很大,單庫容量容易成為瓶頸,如果希望:
- 線性降低單庫數據容量
- 線性提升數據庫寫性能
此時可以使用水平切分架構。
一句話總結,水平切分主要解決“數據庫數據量大”問題,在數據庫容量扛不住的時候,通常水平切分。
我為什么不喜歡讀寫分離?
對于互聯網大數據量,高并發量,高可用要求高,一致性要求高,前端面向用戶的業務場景,如果數據庫讀寫分離:
- 數據庫連接池需要區分:讀連接池,寫連接池
- 如果要保證讀高可用,讀連接池要實現故障自動轉移
- 有潛在的主庫從庫一致性問題
- 如果面臨的是“讀性能瓶頸”問題,增加緩存可能來得更直接,更容易一點
- 關于成本,從庫的成本比緩存高不少
- 對于云上的架構,以阿里云為例,主庫提供高可用服務,從庫不提供高可用服務
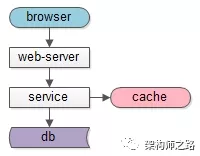
所以,上述業務場景下,建議使用緩存架構來加強系統讀性能,替代數據庫主從分離架構。
當然,使用緩存架構的潛在問題:如果緩存掛了,流量全部壓到數據庫上,數據庫會雪崩。因此,對緩存,一般也會做水平切分,確保不會同一時間全掛。
總結
- 讀寫分離,解決“數據庫讀性能瓶頸”問題
- 水平切分,解決“數據庫數據量大”問題
- 對于互聯網大數據量,高并發量,高可用要求高,一致性要求高,前端面向用戶的業務場景,微服務緩存架構,可能比數據庫讀寫分離架構更合適
【本文為51CTO專欄作者“58沈劍”原創稿件,轉載請聯系原作者】

責任編輯:趙寧寧
來源:
51CTO專欄