要及時「緩存」你們的珍貴時光

1.緩存概述
在很久很久以前人類和洪水作斗爭的過程中,水庫發揮了至關重要的作用 : 在發洪水時可以蓄水,緩解洪水對下游的沖擊;在干旱時可以把庫存的水釋放出來以供人們使用。這里的水庫就起著緩存的作用。在如今互聯網的世界里隨著互聯網的普及,內容信息越來越復雜,用戶數和訪問量越來越大,我們的應用需要支撐更多的并發量,同時我們的應用服務器和數據庫服務器所做的計算也越來越多。
但是往往我們的應用服務器資源是有限的,且服務器技術變革是緩慢的,數據庫每秒能接受的請求次數也是有限的,那么如何能夠有效利用有限的資源來提供盡可能大的吞吐量呢?一個有效的辦法就是引入緩存,打破標準流程,每個環節中請求可以從緩存中直接獲取目標數據并返回,從而減少計算量,有效提升響應速度,讓有限的資源服務更多的用戶。
2.緩存的定義
緩存就是數據交換的緩沖區(稱作Cache),這個概念最初是來自于內存和 CPU。當某一硬件要讀取數據時,會首先從緩存中查找需要的數據,如果找到了則直接使用執行,緩存找不到的話則從內存中找。由于緩存的運行速度比內存快得多,故緩存的作用就是幫助硬件更快地運行。
3.緩存的分類
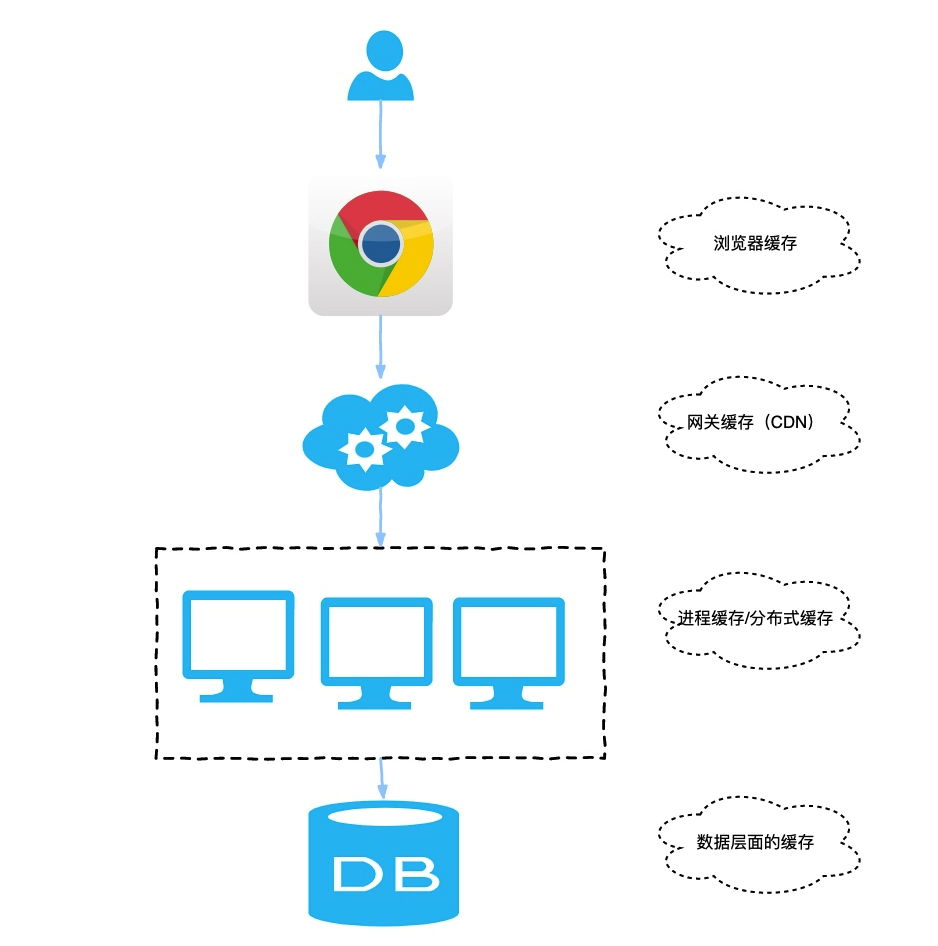
當用戶從鍵入一個地址到頁面的展示過程中通常包含了很多種緩存。有前端緩存、本地緩存(協商緩存,強緩存等)到我們的網關緩存(CDN 緩存)、最后到我們服務端緩存。服務端緩存又區分為進程緩存(本地緩存),還有比較火的分布式緩存,最后到了數據庫層面的緩存。如下圖所示:
4.緩存是一把雙刃劍
在我們通常的軟件設計中,有一些熱點數據需要展示到頁面,我們通常當這些數據緩存到內存或者其他讀寫速度優異的框架中。減少與數據庫進行 I/O 操作。提升數據的響應速度。這一切看起來就是這么完美。
實際上,在緩存系統的設計架構中,還有很多坑。如果設計不當會導致很多嚴重的后果。設計不當,輕則請求變慢、性能降低,重則會數據不一致、系統可用性降低,甚至會導致緩存雪崩,整個系統無法對外提供服務。
接下來我們著重講述一下在緩存設計過程中幾大經典的問題。
緩存失效
先解釋一下什么叫做緩存失效。
我們在存放緩存的時候,可以指定緩存 Key 的失效時間,當失效時間到了,此緩存就會失效,由于在緩存中找不到該數據,所以這個時候如果用戶有請求該數據就繞過緩存直接到數據庫中請求數據。
看到這里小伙伴們肯定有很多問號?
這不是很正常的現象嘛?為什么要把這個問題拿出來說呢?莫急看下圖圖示
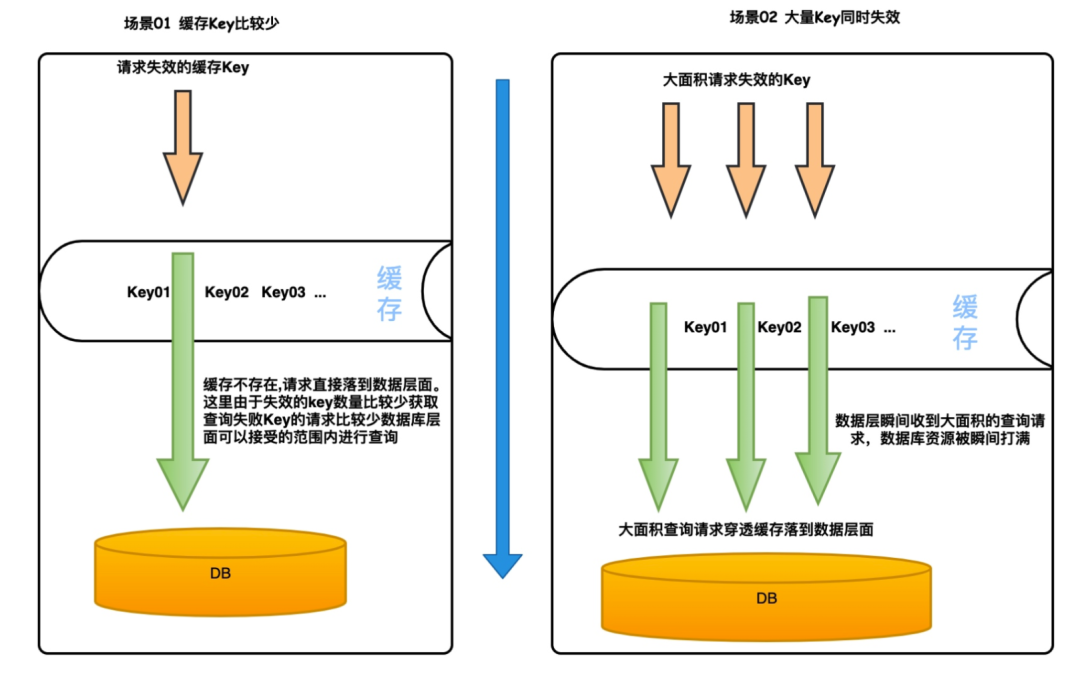
這里我們通過兩個場景來說明一下
- 場景一:這種情況下一般不會對數據庫造成比較嚴重的影響,因為失效的 key 的數量比較少,即使同時請求到數據庫層面也是可以接受的。
- 場景二:在這種場景中,當緩存里面的大量 Key 同時失效,這個時候如果有請求過來,會穿過失效的 Key全部落到數據庫層面。導致數據庫的負荷瞬間添加。可能會出現數據庫宕機等特大事故。
解決方案
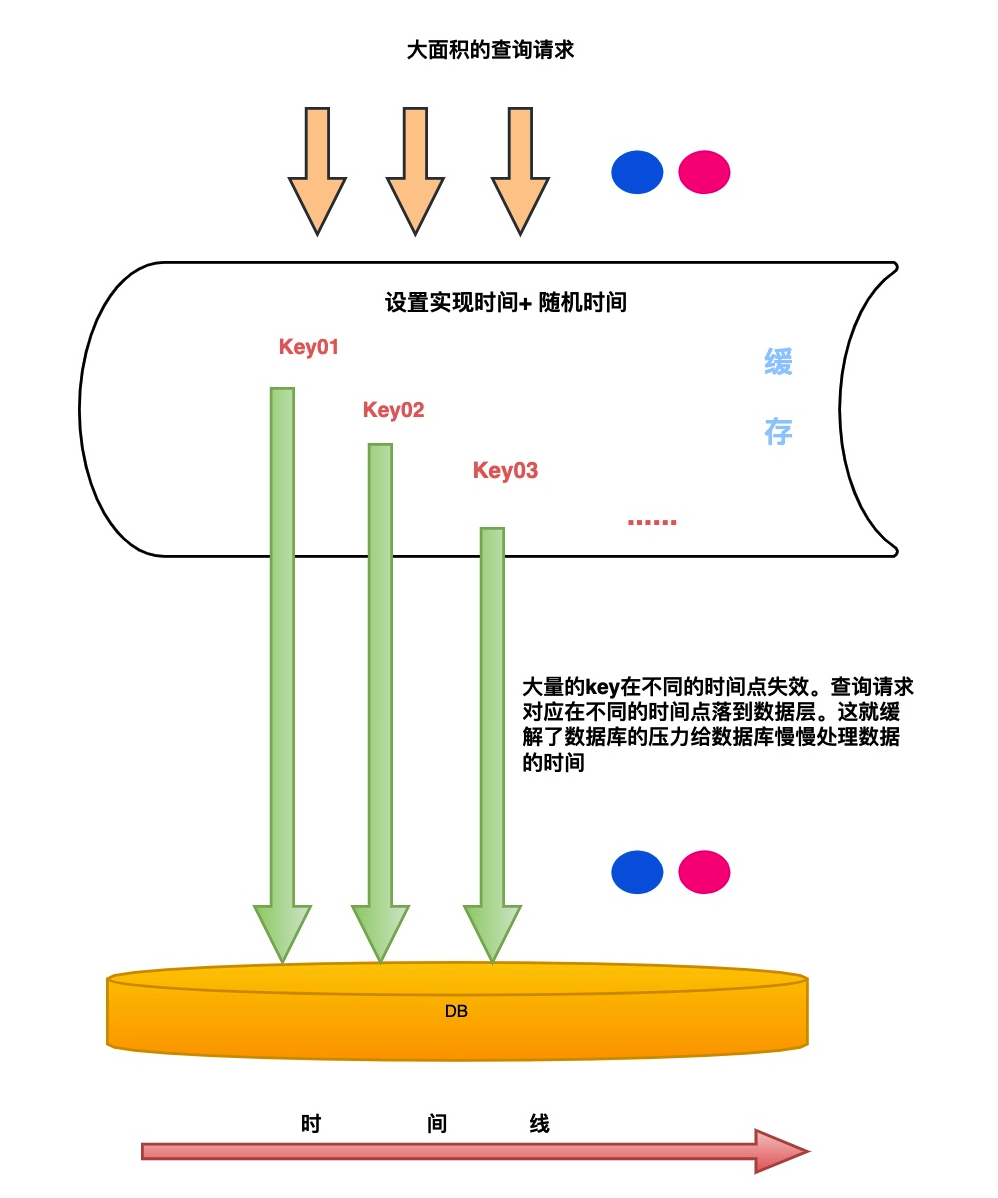
看到這里很多聰明的小伙伴其實已經想到了。場景 2 的事故主要因為很多 key 一起失效的原因,跟我們日常寫緩存的過期時間息息相關。如果我們在日常的開發過程中需要將一批 Key 設置到緩存中并制定失效時間。這個時候就要注意場景 2 發生的情況。我們可以在失效時間 + 隨機時間。避免大量 Key 失效沖擊我們的數據庫。
緩存擊穿
通常情況下,我們去查詢數據都是存在的。那么如果請求去查詢一條壓根兒數據庫中根本就不存在的數據,也就是緩存和數據庫都查詢不到的這條數據會怎么樣呢?這樣會導致每次訪問都會直接打到數據庫上面去。這種查詢不存在數據的現象我們稱為緩存穿透。
下面是緩存失效的場景
很多伙伴看到這里肯定又會覺得這是一件很正常的事情。試想一下,如果有黑客會對你的系統進行攻擊,拿一個不存在的 key 不停的去查詢數據,會產生大量的請求到數據庫去查詢。可能會導致你的數據庫由于壓力過大而宕掉。
解決方案一
- 首先我們能想到的就是在網關參數進行過濾。校驗請求的 key 是否是我們系統 key 的格式等
當然這網關層所能做到的只是一些簡單過濾。每個后端的設計人員應該對服務的可用性和健壯性負責。接下來我們看看服務端應該如何處理
- 服務端可以將不存在的 key 暫時保存到我們的緩存中,再次接收到同樣的請求后如果直接命中緩存并且值為空那么就會直接返回,不會穿透到數據庫層面,這樣就避免了緩存擊穿。
但是黑客/惡意攻擊者是不會這么輕易被打發的。每次請求都會傳不同的 key 來攻擊我們的服務。這個時候這個方案起不到作用了。
解決方案二
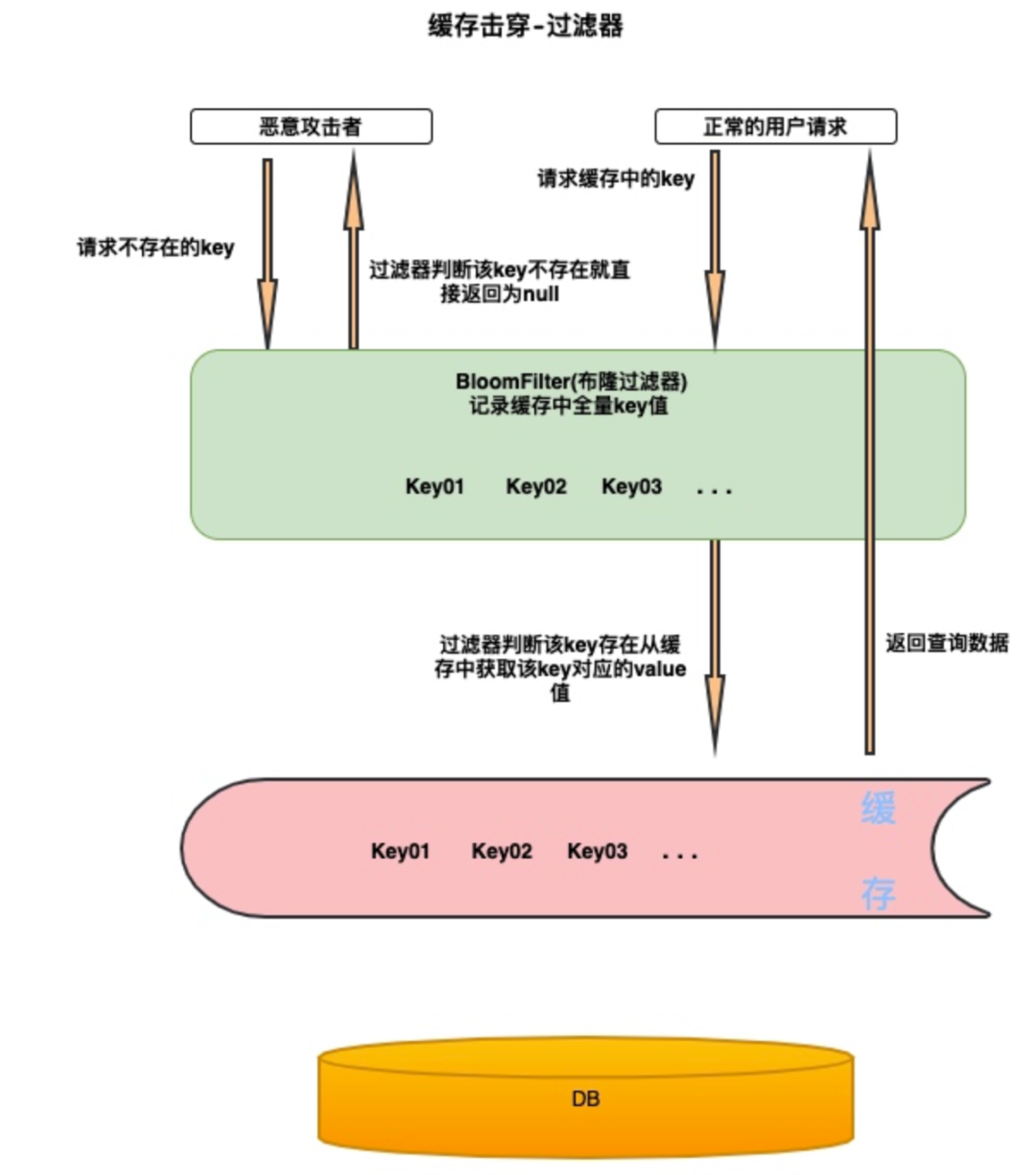
構建一個 BloomFilter(布隆過濾器) 緩存過濾器,記錄全量數據。這樣訪問數據時,可以直接通過 BloomFilter 判斷這個 key 是否存在,如果不存在直接返回即可,根本無需查緩存和 DB。這樣在緩存之前加了一層校驗。如果key 值不存在,就不會請求到我們的緩存更加不會到我們的數據庫中。
布隆過濾器可以理解為一個不怎么精確的 set結構,當你使用它的 contains 方法判斷某個對象是否存在時,它可能會誤判。但是布隆過濾器也不是特別不精確,只要參數設置的合理,它的精確度可以控制的相對足夠精確,只會有小小的誤判概率。當布隆過濾器說某個值存在時,這個值可能不存在;當它說不存在時,那就肯定不存在。即使誤判不存在走到緩存和后端服務也是可以接受的。
緩存雪崩
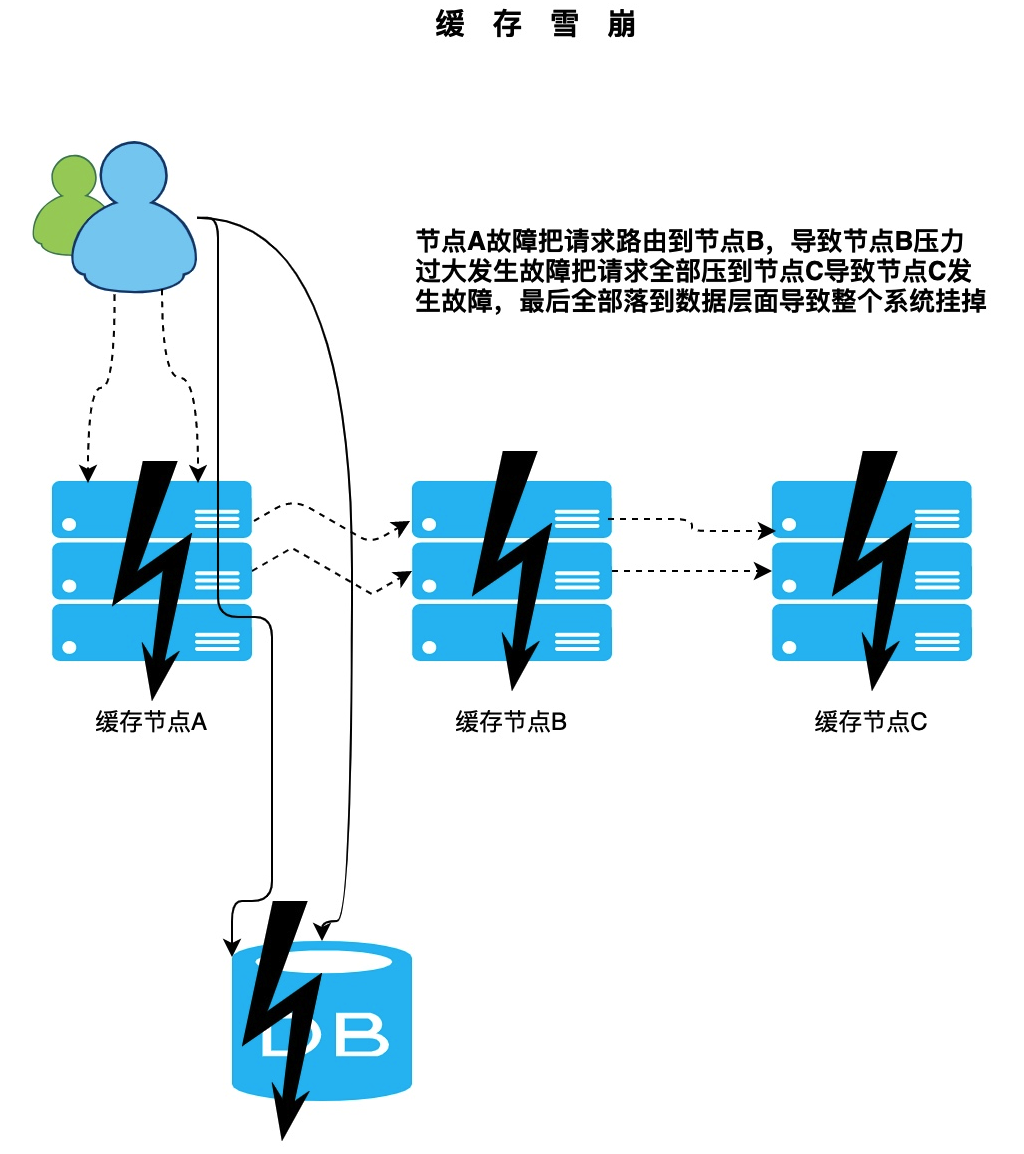
緩存雪崩是指緩存的部分節點不可用導致整個緩存體系甚至整個服務系統不可用。
那么你可能會有疑問,緩存雪崩和緩存擊穿有什么關系呢?
從概念上來看,緩存擊穿是因為查詢不存在的 key 穿透緩存直接訪問我們的數據庫。而緩存雪崩是因為我們的緩存節點不可用,請求未經過緩存就直到了我們的數據庫層面。然而兩者都會影響我們的服務穩定性。
緩存節點的不可用會導致緩存雪崩,那么我們緩存組件集群部署是不是就解決了這個問題呢?
集群部署有兩種情況:
- 一種就是簡單的主從例如 redis 的哨兵之殤
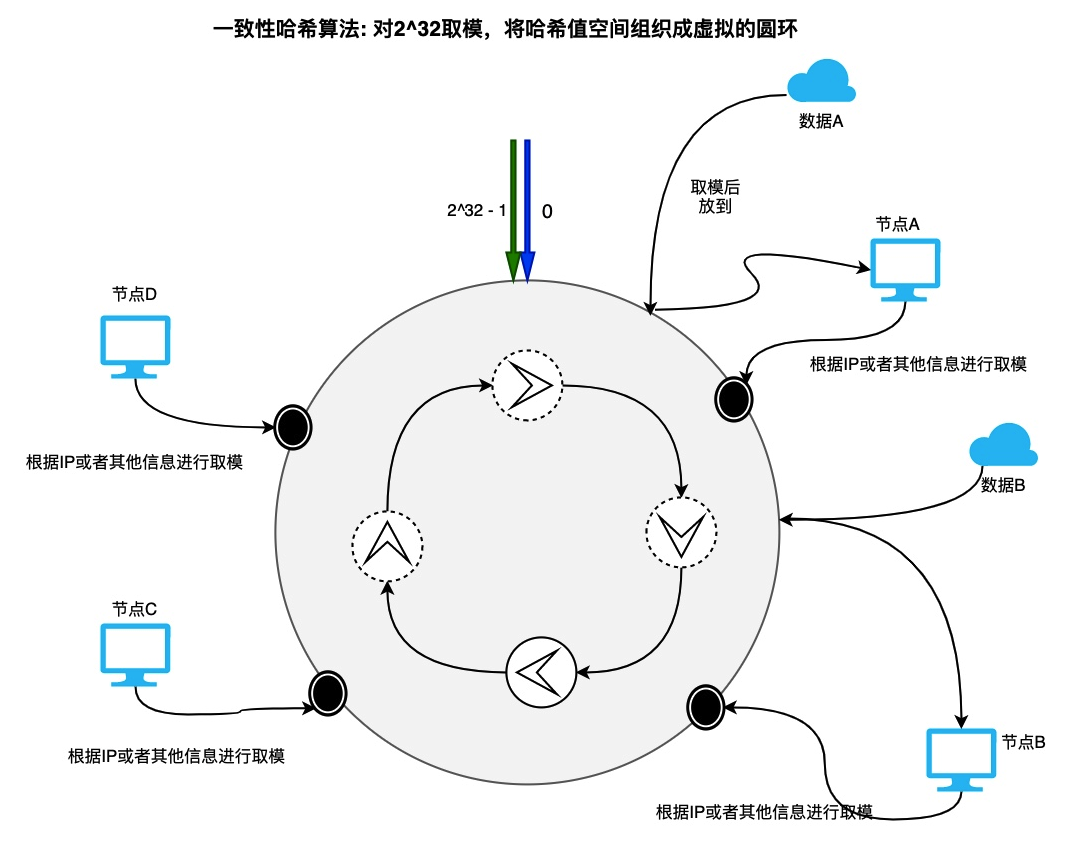
- 采取一致性 hash 算法集群部署例如 redis 的分片集群
第一種情況:發送雪崩的時候一般是多個節點同時不可用,例如我們的節點服務器內容不足,雖然分主從節點都是存儲的數據都是一樣的。如果緩存中的數據過大導致節點不可用。那大部分節點也會存在這個問題。請求會大面積的落到數據庫層面導致后端系統崩潰。
第二種情況: 首先看一下下圖雖然數據根據會根據取模算法分配到不同的節點中,假設節點 A 不可用,數據 A 會按照逆時針找到節點 B,會因為本來應該存放到節點 A 的數據存放到節點 B,以此類推會導致整個緩存節點不可用。請求也會大面積落到我們后端的數據庫層面導致系統崩潰。
解決方案
- 對緩存體系進行實時監控,當請求訪問的慢速比超過閥值時,及時報警,通過機器替換、服務替換進行及時恢復。
- 對緩存增加多個副本,緩存異常或請求 miss 后,再讀取其他緩存副本。
- ehcache 本地緩存 + Hystrix 限流&降級,避免 MySQL被打死
- 業務 DB 的訪問增加讀寫開關,當發現 DB 請求變慢、阻塞,慢請求超過閥值時,就會關閉讀開關,部分或所有讀 DB 的請求進行 failfast 立即返回,待 DB 恢復后再打開讀開關。
數據不一致
數據不一致的概念很簡單:就是緩存中的數據和數據庫中的數據不一致。
那為什么會不一致呢?我們的數據被緩存之后,一旦數據被修改(修改時也是刪除緩存中的數據)或刪除,我們就需要同時操作緩存和數據庫。這時就會存在一個數據不一致的問題。
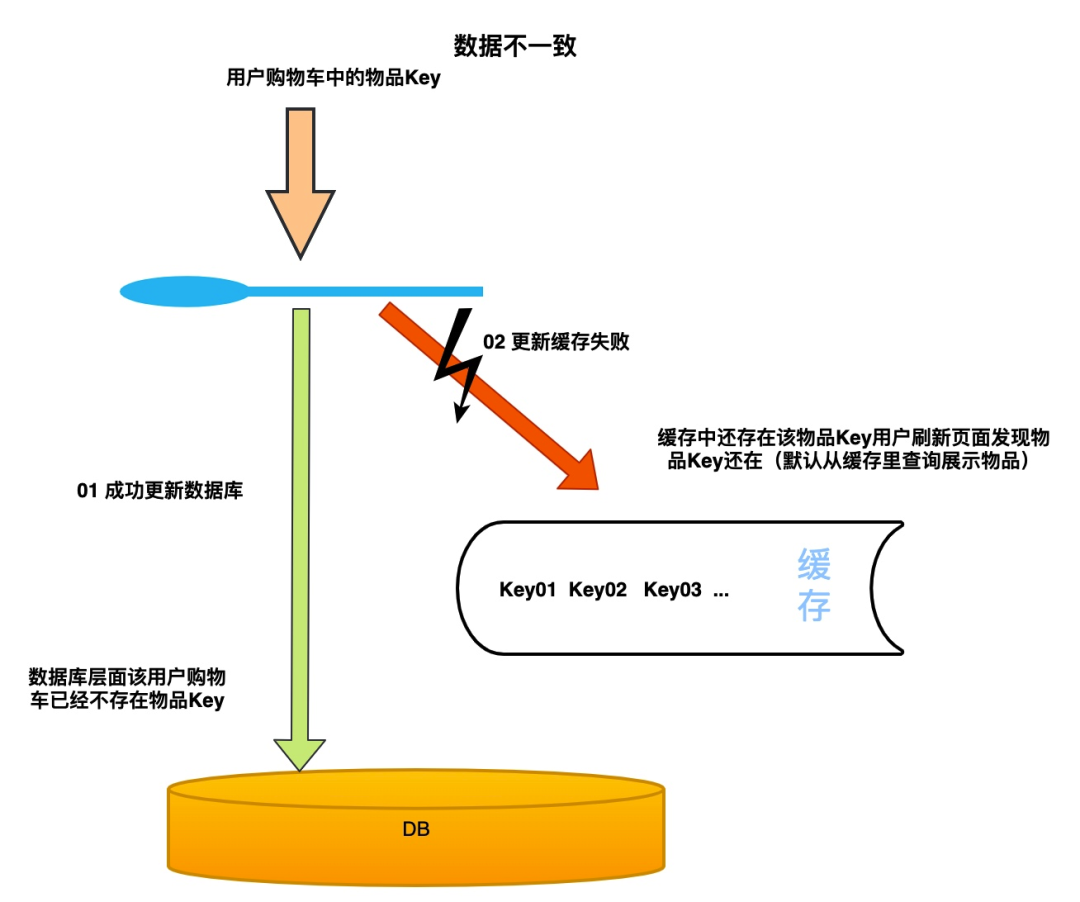
如上圖所示當我們先刪除數據庫再去操作緩存,緩存中未刪除數據庫其實已經不存在該數據了。這個時候就會出現緩存不一致的情況。
聰明的小伙伴肯定想到了我們還是需要先做緩存刪除操作,再去完成數據庫操作。則會去數據庫中查詢,如果緩存中沒有該數據,則會去數據庫中查詢,之后再放入到緩存中。這樣就完美了嘛?答案肯定不會這么簡單。請看下圖:
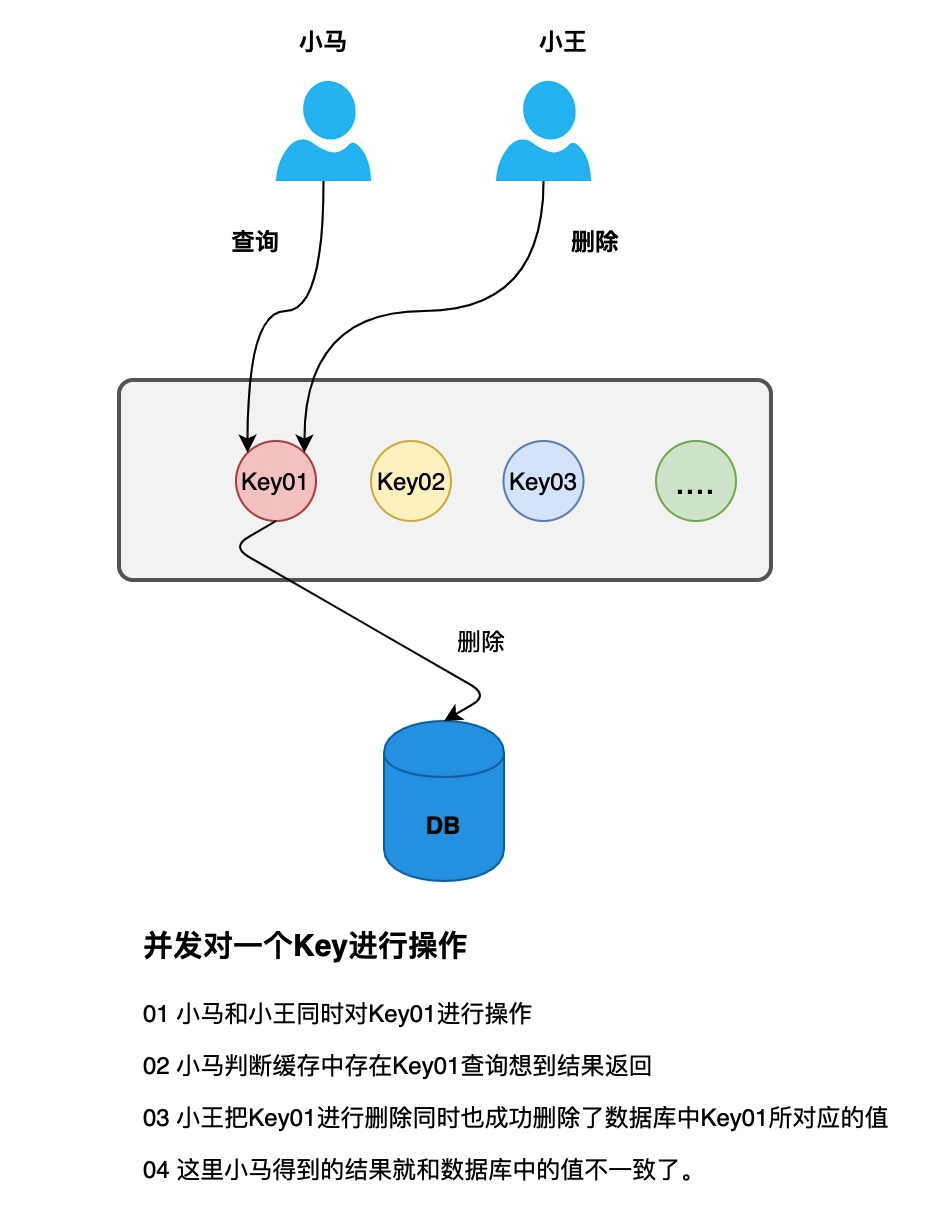
解決方案
這里其實沒有什么很完美的解決方法。可以將變更的 key 添加到安全隊列中。當另一個查詢請求 B 進來時,如果發現緩存中沒有該值,則會先去隊列中查看該數據是否正在被更新或刪除,如果隊列中有該數據,則阻塞等待,直到 A 操作數據庫成功之后,喚醒該阻塞線程,再去數據庫中查詢該數據。這里其實也是有很多缺陷的。線程需要阻塞等待。
最好的解決方案就是如果數據更新比較頻繁且對數據有一定的一致性要求,我通常不建議使用緩存。看到這里是不是發出了一句切!!!!
5.總結
緩存雖然能大幅度的提高服務器的性能以及用戶的體驗感。但是隨著而來的就是各種由于緩存導致的一系列問題。所以當我們使用緩存的過程中需要注意以上的經典問題。