EB 級(jí)系統(tǒng)空中換引擎:阿里調(diào)度執(zhí)行框架如何全面升級(jí)?
作為阿里巴巴核心大數(shù)據(jù)底座——伏羲調(diào)度和分布式執(zhí)行系統(tǒng),支撐著阿里集團(tuán)內(nèi)部以及阿里云上大數(shù)據(jù)平臺(tái)絕大部分的大數(shù)據(jù)計(jì)算需求,在其上運(yùn)行的 MaxCompute(ODPS) 以及 PAI 等多種計(jì)算引擎,每天為用戶(hù)進(jìn)行海量的數(shù)據(jù)運(yùn)算。為了支撐計(jì)算平臺(tái)下個(gè) 10 年的發(fā)展,伏羲團(tuán)隊(duì)啟動(dòng)了 DAG 2.0 項(xiàng)目,從代碼和功能方面實(shí)現(xiàn)完全的升級(jí)換代,支持更多 DAG 執(zhí)行過(guò)程中的動(dòng)態(tài)性及計(jì)算模式。本文將分享 DAG 2.0 核心架構(gòu)及整體設(shè)計(jì),以及與上層各個(gè)計(jì)算引擎的對(duì)接,較長(zhǎng),同學(xué)們可收藏后再看。
前言
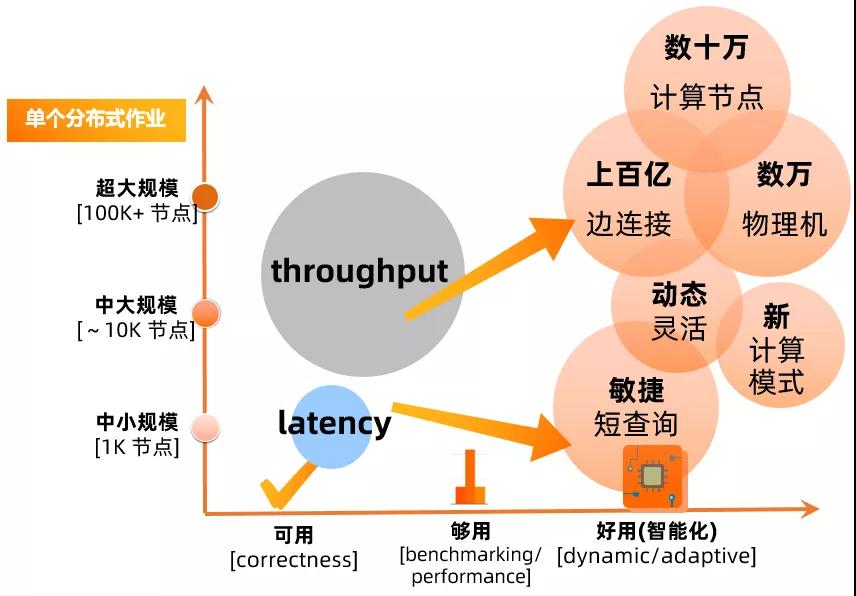
在"阿里體量"的大數(shù)據(jù)生態(tài)中,伏羲系統(tǒng)管理著彈內(nèi)外多個(gè)物理集群,超十萬(wàn)臺(tái)物理機(jī), 以及數(shù)百萬(wàn)的 CPU/GPU cores。每天運(yùn)行在伏羲分布式平臺(tái)上的作業(yè)數(shù)已經(jīng)超過(guò)千萬(wàn), 是業(yè)界少有的,單天處理 EB 級(jí)別數(shù)據(jù)分布式平臺(tái)。其中單個(gè)作業(yè)規(guī)模已經(jīng)高達(dá)數(shù)十萬(wàn)計(jì)算節(jié)點(diǎn),管理著數(shù)百億的邊連接。在過(guò)去的十年中,阿里集團(tuán)以及阿里云上這樣的作業(yè)數(shù)目和規(guī)模,錘煉了伏羲分布式平臺(tái);與此同時(shí),今天平臺(tái)上作業(yè)的日益多樣化,以及向前再發(fā)展的需求,對(duì)于伏羲系統(tǒng)架構(gòu)的進(jìn)一步演化,也都帶來(lái)了巨大挑戰(zhàn)與機(jī)遇。
一 背景
1 伏羲 DAG/AM 組件
從較高的層面來(lái)看整個(gè)分布式系統(tǒng)的體系架構(gòu),物理集群之上運(yùn)行的分布式系統(tǒng),大概可以分成資源管理,作業(yè)分布式調(diào)度執(zhí)行,與多個(gè)計(jì)算節(jié)點(diǎn)的運(yùn)行這三個(gè)層次,如同下圖所示。通常所說(shuō)的 DAG 組件,指的是每個(gè)分布式作業(yè)的中心管理點(diǎn),也就是 application master (AM)。AM 之所以經(jīng)常被稱(chēng)為 DAG (Directional Acyclic Graph, 有向無(wú)環(huán)圖) 組件,是因?yàn)?AM 最重要的責(zé)任,就是負(fù)責(zé)協(xié)調(diào)分布式作業(yè)的執(zhí)行。而現(xiàn)代的分布式系統(tǒng)中的作業(yè)執(zhí)行流程,通常可以通過(guò) DAG 上面的調(diào)度以及數(shù)據(jù)流來(lái)描述[1]。相對(duì)于傳統(tǒng)的 Map-Reduce[2] 執(zhí)行模式, DAG 的模型能對(duì)分布式作業(yè)做更精準(zhǔn)的描述,也是當(dāng)今各種主流大數(shù)據(jù)系統(tǒng) (Hadoop 2.0+, SPARK, FLINK, TENSORFLOW 等) 的設(shè)計(jì)架構(gòu)基礎(chǔ),區(qū)別只在于 DAG 的語(yǔ)義是透露給終端用戶(hù),還是計(jì)算引擎開(kāi)發(fā)者。

與此同時(shí),從整個(gè)分布式系統(tǒng) stack 來(lái)看, AM 肩負(fù)著除了運(yùn)行 DAG 以外更多的責(zé)任。作為作業(yè)的中心管控節(jié)點(diǎn),向下其負(fù)責(zé)與 Resource Manager 之間的交互,為分布式作業(yè)申請(qǐng)計(jì)算資源;向上其負(fù)責(zé)與計(jì)算引擎進(jìn)行交互,并將收集的信息反饋到 DAG 的執(zhí)行過(guò)程中。作為唯一有能力對(duì)每一個(gè)分布式作業(yè)的執(zhí)行大局有最精準(zhǔn)的了解的組件,在全局上對(duì) DAG 的運(yùn)行做準(zhǔn)確的管控和調(diào)整,也是 AM 的重要職責(zé)。從上圖描述的分布式系統(tǒng) stack 圖中,我們也可以很直觀的看出,AM 是系統(tǒng)中唯一需要和幾乎所有分布式組件交互的組件,在作業(yè)的運(yùn)行中起了重要的承上啟下的作用。這一組件之前在伏羲系統(tǒng)中被稱(chēng)為 JobMaster (JM), 在本文中我們統(tǒng)一用 DAG 或者 AM 來(lái)指代。
2 邏輯圖與物理圖
分布式作業(yè)的 DAG,有兩種層面上的表述:邏輯圖與物理圖。簡(jiǎn)單地來(lái)說(shuō) (over-simplified),終端用戶(hù)平時(shí)理解的 DAG 拓?fù)洌蠖鄶?shù)情況下描述的是邏輯圖范疇:比如大家平時(shí)看到的 logview 圖,雖然里面包含了一些物理信息(每個(gè)邏輯節(jié)點(diǎn)的并發(fā)度),但整體上可以認(rèn)為描述的就是作業(yè)執(zhí)行流程的邏輯圖。
準(zhǔn)確一點(diǎn)說(shuō):
- 邏輯圖描述了用戶(hù)想要實(shí)現(xiàn)的數(shù)據(jù)處理流程,從數(shù)據(jù)庫(kù)/SQL 的角度(其他類(lèi)型引擎也都有類(lèi)似之處,比如 TENSORFLOW) 來(lái)看,可以大體認(rèn)為 DAG 的邏輯圖,是對(duì)優(yōu)化器執(zhí)行計(jì)劃的一個(gè)延續(xù)。
- 物理圖更多描述了執(zhí)行計(jì)劃映射到物理分布式集群的具體描述,體現(xiàn)的是執(zhí)行計(jì)劃被物化到分布式系統(tǒng)上,具備的一些特性:比如并發(fā)度,數(shù)據(jù)傳輸方式等等。
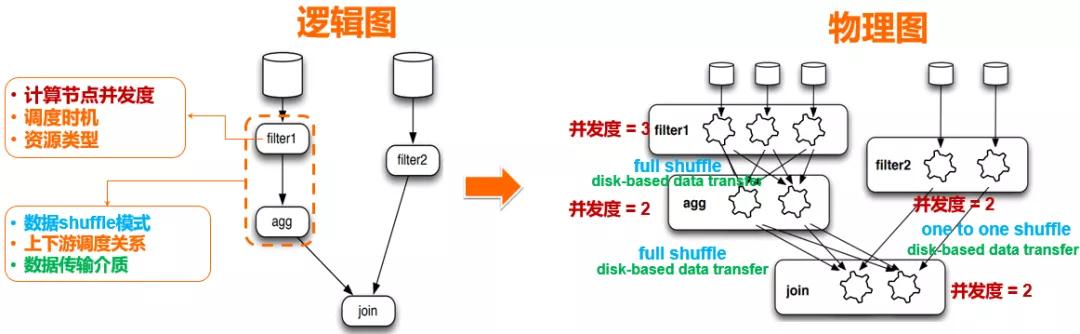
而每個(gè)邏輯圖的"物理化",可以有很多等效方式。選擇合適的方式來(lái)將邏輯圖變成物理化執(zhí)行,并進(jìn)行靈活的調(diào)整,是 DAG 組件的重要職責(zé)之一。從上圖的邏輯圖到物理圖的映射可以看到,一個(gè)圖的物理化過(guò)程,實(shí)際上就是在回答一系列圖節(jié)點(diǎn)以及各個(gè)連接邊物理特性的問(wèn)題,一旦這些問(wèn)題得到確認(rèn),就能得到在分布式系統(tǒng)上實(shí)際執(zhí)行物理圖。
3 為什么需要 DAG 2.0 架構(gòu)升級(jí)?
作為從阿里云飛天系統(tǒng)創(chuàng)建伊始就開(kāi)始研發(fā)的伏羲分布式作業(yè)執(zhí)行框架,DAG 1.0 在過(guò)去十年中支撐了阿里集團(tuán)的大數(shù)據(jù)業(yè)務(wù),在系統(tǒng)規(guī)模以及可靠性等方面都走在了業(yè)界領(lǐng)先。另外一方面,作為一個(gè)開(kāi)發(fā)了十年的系統(tǒng),雖然在這個(gè)期間不斷的演進(jìn),DAG 1.0 在基本架構(gòu)上秉承了比較明顯的 Map-Reduce 執(zhí)行框架的一些特點(diǎn),邏輯圖和物理圖之間沒(méi)有清晰的分層,這導(dǎo)致在這個(gè)基本架構(gòu)上要繼續(xù)向前走,支持更多 DAG 執(zhí)行過(guò)程中的動(dòng)態(tài)性,以及同時(shí)支持多種計(jì)算模式等方面,都比較困難。事實(shí)上今天在 MaxCompute SQL 線(xiàn)上,離線(xiàn)作業(yè)模式以及準(zhǔn)實(shí)時(shí)作業(yè)模式 (smode) 兩種執(zhí)行模式,使用了兩套完全分開(kāi)的分布式執(zhí)行框架,這也導(dǎo)致對(duì)于優(yōu)化性能和優(yōu)化系統(tǒng)資源使用之間的取舍,很多情況下只能走兩個(gè)極端,而無(wú)法比較好的 tradeoff。
除此之外,隨著 MaxCompute 以及 PAI 引擎的更新?lián)Q代以及新功能演進(jìn),上層的分布式計(jì)算自身能力在不斷的增強(qiáng)。對(duì)于 AM 組件在作業(yè)管理,DAG 執(zhí)行等方面的動(dòng)態(tài)性,靈活性等方面的需求也日益強(qiáng)烈。在這樣的一個(gè)大的背景下,為了支撐計(jì)算平臺(tái)下個(gè) 10 年的發(fā)展,伏羲團(tuán)隊(duì)啟動(dòng)了 DAG 2.0 的項(xiàng)目,將從代碼和功能方面,完整替代 1.0 的 JobMaster 組件,實(shí)現(xiàn)完全的升級(jí)換代。在更好的支撐上層計(jì)算需求的同時(shí),也同時(shí)對(duì)接伏羲團(tuán)隊(duì)在 shuffle 服務(wù) (shuffle service) 上的升級(jí),以及 fuxi master (Resource Manager) 的功能升級(jí)。與此同時(shí),站在提供企業(yè)化服務(wù)的角度來(lái)看,一個(gè)好的分布式執(zhí)行框架,除了支持阿里內(nèi)部極致的大規(guī)模大吞吐作業(yè)之外,我們需要支持計(jì)算平臺(tái)的向外走,支持云上各種規(guī)模和計(jì)算模式的需求。除了繼續(xù)錘煉超大規(guī)模的系統(tǒng)擴(kuò)展能力以外,我們需要降低大數(shù)據(jù)系統(tǒng)使用的門(mén)檻,通過(guò)系統(tǒng)本身的智能動(dòng)態(tài)化能力,來(lái)提供自適應(yīng)(各種數(shù)據(jù)規(guī)模以及處理模式)的大數(shù)據(jù)企業(yè)界服務(wù),是 DAG 2.0 在設(shè)計(jì)架構(gòu)中考慮的另一重要維度。
二 DAG 2.0 架構(gòu)以及整體設(shè)計(jì)
DAG 2.0 項(xiàng)目,在調(diào)研了業(yè)界各個(gè)分布式系統(tǒng)(包括SPARK/FLINK/Dryad/Tez/Tensorlow)DAG 組件之后,參考了 Dryad/Tez 的框架。新一代的架構(gòu)上,通過(guò)邏輯圖和物理圖的清晰分層,可擴(kuò)展的狀態(tài)機(jī)管理,插件式的系統(tǒng)管理,以及基于事件驅(qū)動(dòng)的調(diào)度策略等基座設(shè)計(jì),實(shí)現(xiàn)了對(duì)計(jì)算平臺(tái)上多種計(jì)算模式的統(tǒng)一管理,并更好的提供了作業(yè)執(zhí)行過(guò)程中在不同層面上的動(dòng)態(tài)調(diào)整能力。
1 作業(yè)執(zhí)行的動(dòng)態(tài)性
傳統(tǒng)的分布式作業(yè)執(zhí)行流程,作業(yè)的執(zhí)行計(jì)劃是在提交之前確定的。以 SQL 執(zhí)行為例,一個(gè) SQL 語(yǔ)句,在經(jīng)過(guò)編譯器和優(yōu)化器后產(chǎn)生執(zhí)行圖,并被轉(zhuǎn)換成分布式系統(tǒng)(伏羲)的執(zhí)行計(jì)劃。
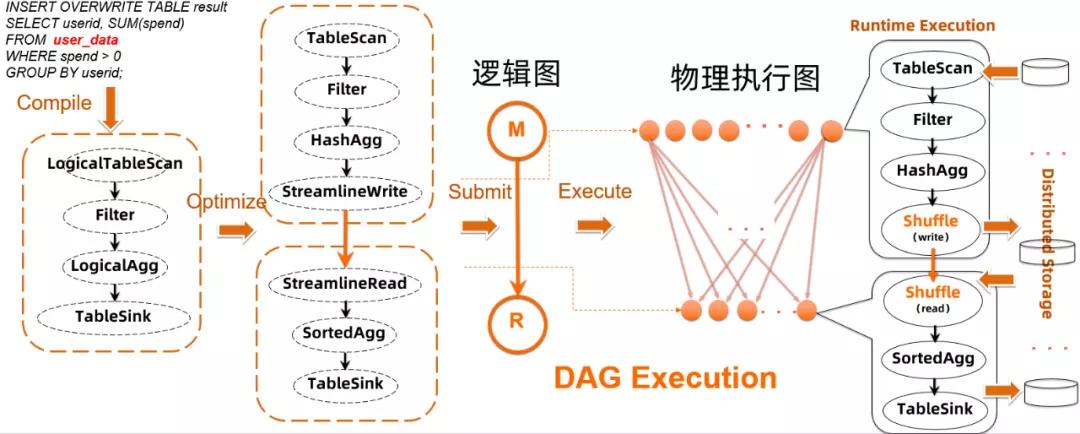
這個(gè)作業(yè)流程在大數(shù)據(jù)系統(tǒng)中是比較標(biāo)準(zhǔn)的操作。然而在具體實(shí)現(xiàn)中,如果在 DAG 的執(zhí)行缺乏自適應(yīng)動(dòng)態(tài)調(diào)整能力的話(huà),整個(gè)執(zhí)行計(jì)劃都需要事先確定,會(huì)使得作業(yè)的運(yùn)行沒(méi)有太多動(dòng)態(tài)調(diào)整的空間。放在 DAG 的邏輯圖與物理圖的背景中來(lái)說(shuō),這要求框架在運(yùn)行作業(yè)前,必須事先了解作業(yè)邏輯和處理數(shù)據(jù)各種特性,并能夠準(zhǔn)確回答作業(yè)運(yùn)行過(guò)程,各個(gè)節(jié)點(diǎn)和連接邊的物理特性問(wèn)題,來(lái)實(shí)現(xiàn)邏輯圖往物理圖的轉(zhuǎn)換。
然而在現(xiàn)實(shí)情況中,許多物理特性相關(guān)的問(wèn)題,在作業(yè)運(yùn)行前是無(wú)法被感知的。以數(shù)據(jù)特性為例,一個(gè)分布式作業(yè)在運(yùn)行前,能夠獲得的只有原始輸入的一些特性(數(shù)據(jù)量等), 對(duì)于一個(gè)較深的 DAG 執(zhí)行而言,這也就意味著只有根節(jié)點(diǎn)的物理計(jì)劃(并發(fā)度選擇等) 是相對(duì)合理的,而下游的節(jié)點(diǎn)和邊的物理特性只能通過(guò)一些特定的規(guī)則來(lái)猜測(cè)。雖然在輸入數(shù)據(jù)有豐富的 statistics 的前提下,優(yōu)化器有可能可以將這些 statistics,與執(zhí)行 plan 中的各個(gè) operator 特性結(jié)合起來(lái),進(jìn)行一些適度的演算:從而推斷在整個(gè)執(zhí)行流程中,每一步產(chǎn)生的中間數(shù)據(jù)可能符合什么樣的特性。但這種推斷在實(shí)現(xiàn)上,尤其在面對(duì)阿里大體量的實(shí)際生產(chǎn)環(huán)境中,面臨著巨大的挑戰(zhàn),例如:
實(shí)際輸入數(shù)據(jù)的 statistics 的缺失
即便是 SQL 作業(yè)處理的結(jié)構(gòu)化數(shù)據(jù),也無(wú)法保證其源表數(shù)據(jù)特性擁有很好的統(tǒng)計(jì)。事實(shí)上今天因?yàn)閿?shù)據(jù)落盤(pán)方式多樣化,以及精細(xì)化統(tǒng)計(jì)方式的缺失,大部分的源表數(shù)據(jù)都是沒(méi)有完整的 statistics 的。此外對(duì)于集群內(nèi)部和外部需要處理的非結(jié)構(gòu)化數(shù)據(jù),數(shù)據(jù)的特性的統(tǒng)計(jì)更加困難。
分布式作業(yè)中存在的大量用戶(hù)邏輯黑盒
作為一個(gè)通用的大數(shù)據(jù)處理系統(tǒng),不可避免的需要支持用戶(hù)邏輯在系統(tǒng)中的運(yùn)行。比如 SQL 中常用的 UDF/UDTF/UDJ/Extractor/Outputer 等等,這些使用 Java/Python 實(shí)現(xiàn)的用戶(hù)邏輯,計(jì)算引擎和分布式系統(tǒng)并無(wú)法理解,在整個(gè)作業(yè)流程中是類(lèi)似黑盒的存在。以 MaxCompute 為例,線(xiàn)上有超過(guò) 20% 的 SQL 作業(yè),尤其是重點(diǎn)基線(xiàn)作業(yè),都包含用戶(hù)代碼。這些大量用戶(hù)代碼的存在,也造成了優(yōu)化器在很多情況下無(wú)法對(duì)中間產(chǎn)出數(shù)據(jù)的特性進(jìn)行預(yù)判。
優(yōu)化器預(yù)判錯(cuò)誤代價(jià)昂貴
在優(yōu)化器選擇執(zhí)行計(jì)劃時(shí),會(huì)有一些優(yōu)化方法,在數(shù)據(jù)符合一定特殊特性的時(shí)候,被合理選中能帶來(lái)性能優(yōu)化。但是一旦選擇的前提假設(shè)錯(cuò)誤(比如數(shù)據(jù)特性不符合預(yù)期),會(huì)適得其反,甚至帶來(lái)嚴(yán)重的性能回退或作業(yè)失敗。在這種前提下,依據(jù)靜態(tài)的信息實(shí)現(xiàn)進(jìn)行過(guò)多的預(yù)測(cè)經(jīng)常得不到理想的結(jié)果。
這種種原因造成的作業(yè)運(yùn)行過(guò)程中的非確定性,要求一個(gè)好的分布式作業(yè)執(zhí)行系統(tǒng),需要能夠根據(jù)中間運(yùn)行結(jié)果的特點(diǎn),來(lái)進(jìn)行執(zhí)行過(guò)程中的動(dòng)態(tài)調(diào)整。因?yàn)橹挥性谥虚g數(shù)據(jù)已經(jīng)在執(zhí)行過(guò)程中產(chǎn)生后,其數(shù)據(jù)特性才能被最準(zhǔn)確的獲得,動(dòng)態(tài)性的缺失,可能帶來(lái)一系列的線(xiàn)上問(wèn)題,比如:
- 物理資源的浪費(fèi):比如計(jì)算節(jié)點(diǎn)事先選擇的資源類(lèi)型的不合理,或者大量的計(jì)算被消耗用于處理后繼會(huì)被丟棄的無(wú)效數(shù)據(jù)。
- 作業(yè)的嚴(yán)重長(zhǎng)尾:比如中間數(shù)據(jù)分布傾斜或不合理編排,導(dǎo)致一個(gè) stage 上計(jì)算節(jié)點(diǎn)需要處理的數(shù)據(jù)量極端化。
- 作業(yè)的不穩(wěn)定:比如由于優(yōu)化器靜態(tài)計(jì)劃的錯(cuò)判,導(dǎo)致不合理的執(zhí)行計(jì)劃無(wú)法完成。
而 DAG/AM 作為分布式作業(yè)唯一的中心節(jié)點(diǎn)和調(diào)度管控節(jié)點(diǎn),是唯一有能力收集并聚合相關(guān)數(shù)據(jù)信息,并基于這些數(shù)據(jù)特性來(lái)做作業(yè)執(zhí)行的動(dòng)態(tài)調(diào)整,的分布式組件。這包括簡(jiǎn)單的物理執(zhí)行圖調(diào)整(比如動(dòng)態(tài)的并發(fā)度調(diào)整),也包括復(fù)雜一點(diǎn)的調(diào)整比如對(duì) shuffle 方式和數(shù)據(jù)編排方式重組。除此以外,數(shù)據(jù)的不同特點(diǎn)也會(huì)帶來(lái)邏輯執(zhí)行圖調(diào)整的需求:對(duì)于邏輯圖的動(dòng)態(tài)調(diào)整,在分布式作業(yè)處理中是一個(gè)全新的方向,也是我們?cè)?DAG 2.0 里面探索的新式解決方案。
點(diǎn),邊,圖的清晰物理邏輯分層,和基于事件的數(shù)據(jù)收集和調(diào)度管理,以及插件式的功能實(shí)現(xiàn),方便了 DAG 2.0 在運(yùn)行期間的數(shù)據(jù)收集,以及使用這些數(shù)據(jù)來(lái)系統(tǒng)性地回答,邏輯圖向物理圖轉(zhuǎn)化過(guò)程中需要確定的問(wèn)題。從而在必要的時(shí)候?qū)崿F(xiàn)物理圖和邏輯圖的雙重動(dòng)態(tài)性,對(duì)執(zhí)行計(jì)劃進(jìn)行合理的調(diào)整。在下文中提到幾個(gè)落地場(chǎng)景中,我們會(huì)進(jìn)一步舉例說(shuō)明基于 2.0 的這種強(qiáng)動(dòng)態(tài)性能力,實(shí)現(xiàn)更加自適應(yīng),更加高效的分布式作業(yè)的執(zhí)行。
2 統(tǒng)一的 AM/DAG 執(zhí)行框架
DAG 2.0 抽象分層的點(diǎn),邊,圖架構(gòu)上,也使其能通過(guò)對(duì)點(diǎn)和邊上不同物理特性的描述,對(duì)接不同的計(jì)算模式。業(yè)界各種分布式數(shù)據(jù)處理引擎,包括 SPARK, FLINK, HIVE, SCOPE, TENSORFLOW 等等,其分布式執(zhí)行框架的本源都可以歸結(jié)于 Dryad[1] 提出的 DAG 模型。我們認(rèn)為對(duì)于圖的抽象分層描述,將允許在同一個(gè) DAG 系統(tǒng)中,對(duì)于離線(xiàn)/實(shí)時(shí)/流/漸進(jìn)計(jì)算等多種模型都可以有一個(gè)好的描述。在 DAG 2.0 初步落地的過(guò)程中,首要目標(biāo)是在同一套代碼和架構(gòu)系統(tǒng)上,統(tǒng)一當(dāng)前伏羲平臺(tái)上運(yùn)行的幾種計(jì)算模式,包括 MaxCompute 的離線(xiàn)作業(yè),準(zhǔn)實(shí)時(shí)作業(yè),以及 PAI 平臺(tái)上的 Tensorflow 作業(yè)和其他的非 SQL 類(lèi)作業(yè)。對(duì)更多新穎計(jì)算模式的探索,也會(huì)有計(jì)劃的分步驟進(jìn)行。
1)統(tǒng)一的離線(xiàn)作業(yè)與準(zhǔn)實(shí)時(shí)作業(yè)執(zhí)行框架
首先我們來(lái)看平臺(tái)上作業(yè)數(shù)占到絕大多數(shù)的 SQL 線(xiàn)離線(xiàn)作業(yè) (batch job) 與準(zhǔn)實(shí)時(shí)作業(yè) (smode)。前面提到過(guò),由于種種歷史原因,之前 MaxCompompute SQL 線(xiàn)的這兩種模式的資源管理和作業(yè)執(zhí)行,是搭建在兩套完全分開(kāi)的代碼實(shí)現(xiàn)上的。這除了導(dǎo)致兩套代碼和功能無(wú)法復(fù)用以外,兩種計(jì)算模式的非黑即白,使得彼此在資源利用率和執(zhí)行性能之間無(wú)法 tradeoff。而在 2.0 的 DAG 模型上,我們實(shí)現(xiàn)了這兩種計(jì)算模式比較自然的融合和統(tǒng)一,如下圖所示:
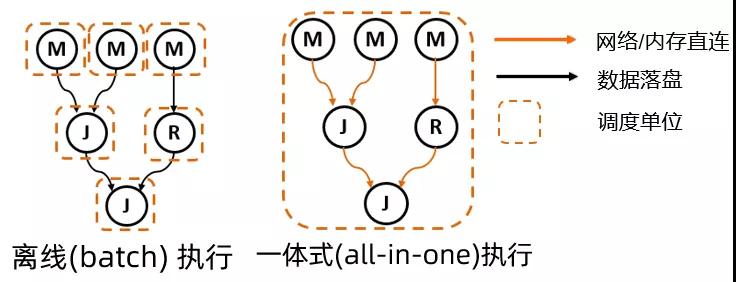
在通過(guò)對(duì)邏輯節(jié)點(diǎn)和邏輯邊上映射不同的物理特性,離線(xiàn)作業(yè)和準(zhǔn)實(shí)時(shí)作業(yè)都能得到準(zhǔn)確的描述:
- 離線(xiàn)作業(yè):每個(gè)節(jié)點(diǎn)按需去申請(qǐng)資源,一個(gè)邏輯節(jié)點(diǎn)代表一個(gè)調(diào)度單位;節(jié)點(diǎn)間連接邊上傳輸?shù)臄?shù)據(jù),通過(guò)落盤(pán)的方式來(lái)保證可靠性;
- 準(zhǔn)實(shí)時(shí)作業(yè):整個(gè)作業(yè)的所有節(jié)點(diǎn)都統(tǒng)一在一個(gè)調(diào)度單位內(nèi)進(jìn)行 gang scheduling;節(jié)點(diǎn)間連接邊上通過(guò)網(wǎng)絡(luò)/內(nèi)存直連傳輸數(shù)據(jù),并利用數(shù)據(jù) pipeline來(lái)追求最優(yōu)的性能。
今天在線(xiàn)上,離線(xiàn)模式因?yàn)槠?on-demand 的資源申請(qǐng)以及中間數(shù)據(jù)落盤(pán)等特點(diǎn),作業(yè)在資源利用率,規(guī)模性和穩(wěn)定性方面都有明顯的優(yōu)勢(shì)。而準(zhǔn)實(shí)時(shí)模式則通過(guò)常駐的計(jì)算資源池以及 gang scheduling 這種 greedy 資源申請(qǐng),降低了作業(yè)運(yùn)行過(guò)程中的 overhead,并使得數(shù)據(jù)的 pipelined 傳輸處理成為可能,達(dá)到加速作業(yè)運(yùn)行的效果,但其資源使用的特點(diǎn),也使其無(wú)法在廣泛范圍內(nèi)來(lái)支持大規(guī)模作業(yè)。DAG 2.0 的升級(jí),不僅在同一套架構(gòu)上統(tǒng)一了這兩種計(jì)算模式,更重要的是這種統(tǒng)一的描述方式,使得探索離線(xiàn)作業(yè)高資源利用率,以及準(zhǔn)實(shí)時(shí)作業(yè)的高性能之間的 tradeoff 成為可能:當(dāng)調(diào)度單位可以自由調(diào)整,就可以實(shí)現(xiàn)一種全新的混合的計(jì)算模式,我們稱(chēng)之為 Bubble 執(zhí)行模式。

這種混合 Bubble 模式,使得 DAG 的用戶(hù),也就是上層計(jì)算引擎的開(kāi)發(fā)者(比如 MaxCompute 的優(yōu)化器),能夠結(jié)合執(zhí)行計(jì)劃的特點(diǎn),以及引擎終端用戶(hù)對(duì)資源使用和性能的敏感度,來(lái)靈活選擇在執(zhí)行計(jì)劃中切出 Bubble 子圖。在 Bubble 內(nèi)部充分利用網(wǎng)絡(luò)直連和計(jì)算節(jié)點(diǎn)預(yù)熱等方式提升性能,沒(méi)有切入 Bubble 的節(jié)點(diǎn)則依然通過(guò)傳統(tǒng)離線(xiàn)作業(yè)模式運(yùn)行。回過(guò)頭來(lái)看,現(xiàn)有的離線(xiàn)作業(yè)模式和準(zhǔn)實(shí)時(shí)作業(yè)模式,分別可以被描述成 Bubble 執(zhí)行模式的兩個(gè)極端特例,而在統(tǒng)一的新模型之上,計(jì)算引擎和執(zhí)行框架可以在兩個(gè)極端之間,根據(jù)具體需要,選擇不同的平衡點(diǎn),典型的幾個(gè)應(yīng)用場(chǎng)景包括:
Greedy Bubble
在可用的資源(集群規(guī)模,quota 等)受限,一個(gè)大規(guī)模作業(yè)無(wú)法實(shí)現(xiàn) gang scheduling 時(shí),如果用戶(hù)對(duì)資源利用率不敏感,唯一的目標(biāo)是盡快跑完一個(gè)大規(guī)模作業(yè)。這種情況下,可以實(shí)現(xiàn)基于可用計(jì)算節(jié)點(diǎn)數(shù)目,實(shí)施 greedy 的 bubble 切割的策略, 盡量切出大的 bubble。
Efficient Bubble
在作業(yè)的運(yùn)行過(guò)程中,節(jié)點(diǎn)間的運(yùn)算可能存在天然的 barrier (比如 sort 運(yùn)算, 建 hash 表等等)。如果把兩個(gè)通過(guò) barrier 邊連接的節(jié)點(diǎn)切到一個(gè) bubble 中,雖然作業(yè) e2e 性能上還是會(huì)有調(diào)度 overhead 降低等帶來(lái)的提升,但是因?yàn)閿?shù)據(jù)無(wú)法完全 pipeline 起來(lái),資源的利用率達(dá)不到最高。那么在對(duì)資源的利用率較為敏感時(shí),可以避免 bubble 內(nèi)部出現(xiàn) barrier 邊。這同樣是計(jì)算引擎可以根據(jù)執(zhí)行計(jì)劃做出決定的。
這里只列舉了兩個(gè)簡(jiǎn)單的策略,其中還有更多可以細(xì)化以及針對(duì)性?xún)?yōu)化的地方。在不同的場(chǎng)景上,通過(guò) DAG 層面提供的這種靈活按照 bubble 執(zhí)行計(jì)算的能力,允許上層計(jì)算可以在不同場(chǎng)景上挑選合適的策略,更好的支持各種不同計(jì)算的需求。
2)支持新型計(jì)算模式的描述
1.0 的執(zhí)行框架的底層設(shè)計(jì)受 Map-Reduce 模式的影響較深,節(jié)點(diǎn)之間的邊連接,同時(shí)混合了調(diào)度順序,運(yùn)行順序,以及數(shù)據(jù)流動(dòng)的多種語(yǔ)義。通過(guò)一條邊連接的兩個(gè)節(jié)點(diǎn),下游節(jié)點(diǎn)必須在上游節(jié)點(diǎn)運(yùn)行結(jié)束,退出,并產(chǎn)生數(shù)據(jù)后才能被調(diào)度。這種描述對(duì)于新型的一些計(jì)算模式并不適用。比如對(duì)于 Parameter Server 計(jì)算模式,Parameter Server(PS) 與 Worker 在運(yùn)行過(guò)程中有如下特點(diǎn):
- PS 作為 parameter 的 serving entity, 可以獨(dú)立運(yùn)行。
- Worker 作為 parameter 的 consumer 和 updater, 需要 PS 在運(yùn)行后才能有效的運(yùn)行,并且在運(yùn)行過(guò)程中需要和 PS 持續(xù)的進(jìn)行數(shù)據(jù)交互。
這種運(yùn)行模式下,PS 和 worker 之間天然存在著調(diào)度上的前后依賴(lài)關(guān)系。但是因?yàn)?PS 與 worker 必須同時(shí)運(yùn)行,不存在 PS 先退出 worker 才調(diào)度的邏輯。所以在 1.0 框架上, PS 與 worker 只能作為兩個(gè)孤立無(wú)聯(lián)系的 stage 來(lái)分開(kāi)調(diào)度和運(yùn)行。此外所有 PS 與 worker 之間,也只能完全通過(guò)計(jì)算節(jié)點(diǎn)間直連通訊,以及在外部 entity (比如 zookeeper 或 nuwa) 協(xié)助來(lái)進(jìn)行溝通與協(xié)調(diào)。這導(dǎo)致 AM/DAG 作為中心管理節(jié)點(diǎn)作用的缺失,作業(yè)的管理基本被下放計(jì)算引擎上,由計(jì)算節(jié)點(diǎn)之間自行試圖協(xié)調(diào)來(lái)完成。這種無(wú)中心化的管理,對(duì)稍微復(fù)雜的情況下 (failover 等) 無(wú)法很好的處理。
在 DAG 2.0 的框架上,為了更準(zhǔn)確的描述節(jié)點(diǎn)之間的調(diào)度和運(yùn)行關(guān)系,引入并且實(shí)現(xiàn)了 concurrent edge 的概念:通過(guò) concurrent edge 連接的上下游節(jié)點(diǎn),在調(diào)度上存在先后,但是可以同時(shí)運(yùn)行。而調(diào)度的時(shí)機(jī)也可以靈活配置:可以上下游同步調(diào)度,也可以在上游運(yùn)行到一定程度后,通過(guò)事件來(lái)觸發(fā)下游的調(diào)度。在這種靈活的描述能力上, PS 作業(yè)可以通過(guò)如下這種 DAG 來(lái)描述,這不僅使得作業(yè)節(jié)點(diǎn)間的關(guān)系描述更加準(zhǔn)確,而且使得 AM 能夠理解作業(yè)的拓?fù)洌M(jìn)行更加有效的作業(yè)管理,包括在不同計(jì)算節(jié)點(diǎn)發(fā)生 failover 時(shí)不同的處理策略等。

此外,DAG 2.0 新的描述模型,也允許 PAI 平臺(tái)上的 Tensorflow/PS 作業(yè)實(shí)現(xiàn)更多的動(dòng)態(tài)優(yōu)化,并進(jìn)行新的創(chuàng)新性工作。在上圖的 dynamic PS DAG 中,就引進(jìn)了一個(gè)額外的 control 節(jié)點(diǎn),這一節(jié)點(diǎn)可以在作業(yè)運(yùn)行過(guò)程中(包括 PS workload 運(yùn)行之前和之后),對(duì)作業(yè)的資源申請(qǐng),并發(fā)度等進(jìn)行動(dòng)態(tài)的調(diào)整,確保作業(yè)的優(yōu)化執(zhí)行。
事實(shí)上 concurrent edge 這個(gè)概念,描述的是上下游節(jié)點(diǎn)運(yùn)行/調(diào)度時(shí)機(jī)的物理特性,也是我們?cè)谇逦倪壿嬑锢矸謱拥募軜?gòu)上實(shí)現(xiàn)的一個(gè)重要擴(kuò)展。不僅對(duì)于 PS 作業(yè)模式,在之前描述過(guò)的對(duì)于通過(guò) bubble 來(lái)統(tǒng)一離線(xiàn)與準(zhǔn)實(shí)時(shí)作業(yè)計(jì)算模式,這個(gè)概念也有重要的作用。
三 DAG 2.0 與上層計(jì)算引擎的集成
DAG 2.0 作為計(jì)算平臺(tái)的分布式運(yùn)行基座,它的升級(jí)換代,為上層的各種計(jì)算引擎提供了更多靈活高效的執(zhí)行能力,而這些能力的落地,需要通過(guò)與具體計(jì)算場(chǎng)景的緊密結(jié)合來(lái)實(shí)現(xiàn)。接下來(lái)通過(guò) 2.0 與上層各個(gè)計(jì)算引擎(包括 MaxCompute 以及 PAI 平臺(tái)等)的一些對(duì)接場(chǎng)景,具體舉例說(shuō)明 2.0 新的調(diào)度執(zhí)行框架,如何賦能平臺(tái)上層的計(jì)算與應(yīng)用。
1 運(yùn)行過(guò)程中的 DAG 動(dòng)態(tài)調(diào)整
作為計(jì)算平臺(tái)上的作業(yè)大戶(hù),MaxCompute 平臺(tái)上多種多樣的計(jì)算場(chǎng)景,尤其是離線(xiàn)作業(yè)中的各種復(fù)雜邏輯,為動(dòng)態(tài)圖能力的落地提供了豐富多樣的場(chǎng)景,這里從動(dòng)態(tài)物理圖和邏輯圖幾個(gè)方面討論幾個(gè)例子。
1)動(dòng)態(tài)并發(fā)度調(diào)整
基于作業(yè)運(yùn)行期間中間數(shù)據(jù)大小進(jìn)行動(dòng)態(tài)并發(fā)度調(diào)整,是 DAG 動(dòng)態(tài)調(diào)整中最基本的能力。以傳統(tǒng) MR 作業(yè)為例,對(duì)于一個(gè)靜態(tài) MR 作業(yè)而言,能根據(jù)讀取數(shù)據(jù)量來(lái)比較準(zhǔn)確判斷 Mapper 的并發(fā),但是對(duì)于 Reducer 的并發(fā)只能簡(jiǎn)單推測(cè),比如下圖中對(duì)于處理 1TB 的 MR 作業(yè)而言,提交作業(yè)時(shí),只能根據(jù) Mapper 1000 并發(fā),來(lái)猜測(cè)給出 500 的 Reducer 并發(fā)度,而如果數(shù)據(jù)在 Mapper 經(jīng)過(guò)大量過(guò)濾導(dǎo)致最終只產(chǎn)出 10MB 中間數(shù)據(jù)時(shí),500 并發(fā)度 Redcuer 顯然是非常浪費(fèi)的,動(dòng)態(tài)的 DAG 必須能夠根據(jù)實(shí)際的 Mapper 產(chǎn)出來(lái)進(jìn)行 Reducer 并發(fā)調(diào)整(500 -> 1)。
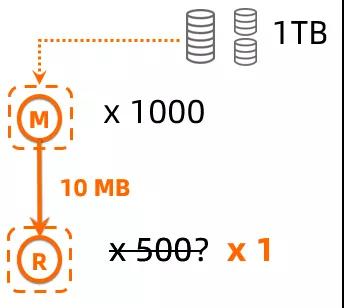
而實(shí)際實(shí)現(xiàn)中,最簡(jiǎn)單的動(dòng)態(tài)調(diào)整,會(huì)直接按照并發(fā)度調(diào)整比例來(lái)聚合上游輸出的 partition 數(shù)據(jù),如下圖這個(gè)并發(fā)度從 10 調(diào)整到 5 的例子所示,在調(diào)整的過(guò)程中,可能產(chǎn)生不必要的數(shù)據(jù)傾斜。
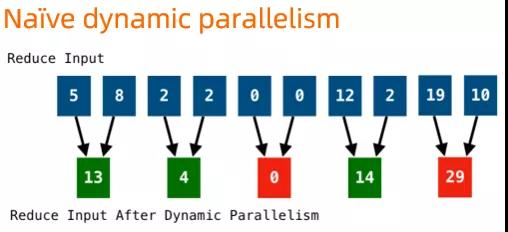
DAG 2.0 基于中間數(shù)據(jù)的動(dòng)態(tài)并發(fā)調(diào)整實(shí)現(xiàn),充分考慮了數(shù)據(jù) partition 可能存在傾斜的情況,對(duì)動(dòng)態(tài)調(diào)整的策略進(jìn)行了優(yōu)化,使得動(dòng)態(tài)調(diào)整的策略后數(shù)據(jù)的分布更加均勻,可以有效避免由于動(dòng)態(tài)調(diào)整可能引入的數(shù)據(jù)傾斜。
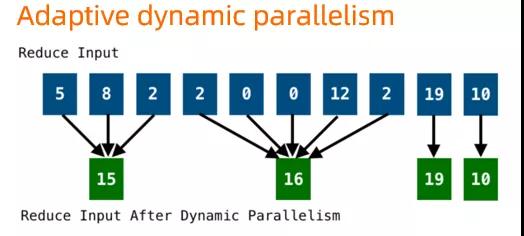
這種最常見(jiàn)下游并發(fā)調(diào)整方式是 DAG 2.0 動(dòng)態(tài)物理圖能力的一個(gè)直觀展示。在 2.0 中項(xiàng)目中,結(jié)合計(jì)算引擎的數(shù)據(jù)處理的特點(diǎn),還探索了基于源數(shù)據(jù)的動(dòng)態(tài)并發(fā)調(diào)整。例如對(duì)于最常見(jiàn)的兩個(gè)原表數(shù)據(jù)的 join (M1 join M2 at J), 如果用節(jié)點(diǎn)大小來(lái)表示其處理數(shù)據(jù)的的多少,那對(duì)于下圖這么一個(gè)例子,M1 處理的是中等的一個(gè)數(shù)據(jù)表(假設(shè) M1 需要并發(fā)度為 10),M2 處理的是較大的數(shù)據(jù)表(并發(fā)度為1000),naïve 的執(zhí)行方式會(huì)將按照 10 + 1000 的并發(fā)度調(diào)度,同時(shí)因?yàn)?M2 輸出需要全量 shuffle 到 J, J 需要的并發(fā)度也會(huì)較大 (~1000)。
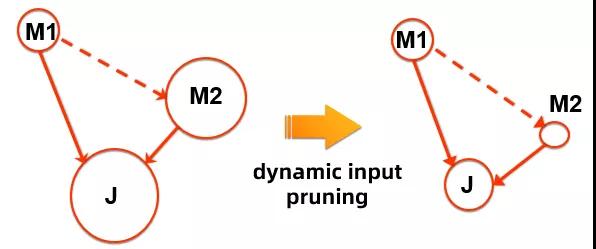
而實(shí)際上,對(duì)于這種計(jì)算 pattern 而言,M2 需要讀取(并進(jìn)行處理)的,應(yīng)該只有能和 M1 的輸出 join 得上的數(shù)據(jù),也就是說(shuō)在考慮了整體執(zhí)行 cost 后,在這種 M1 期望的輸出數(shù)據(jù)要比 M2 小的多的情況下,可以先行調(diào)度 M1 完成計(jì)算,將 M1 輸出數(shù)據(jù)的 statistics 在 AM/DAG 端進(jìn)行聚合,然后只挑選出 M2 的有效數(shù)據(jù)進(jìn)行處理。這里 "M2 的有效數(shù)據(jù)"的選擇本質(zhì)上是一個(gè) predicate push down 的過(guò)程,可以由計(jì)算引擎的優(yōu)化器和運(yùn)行時(shí)聯(lián)合進(jìn)行判斷。也就是說(shuō),這種情況下 M2 的并發(fā)度調(diào)整,是和上層計(jì)算緊密結(jié)合的。
一個(gè)最直觀的例子是,如果 M2 是一個(gè) 1000 個(gè)分區(qū)的分區(qū)表,并且分區(qū)的 key 和 join 的 key 相同,那么可以只讀取 M2 能和 M1 輸出 join 上的有效數(shù)據(jù)的 partition 進(jìn)行讀取處理。假如 M1 的輸出只包含了 M2 原表數(shù)據(jù)的 3 個(gè) partition keys, 那么在 M2 就只需要調(diào)度 3 個(gè)計(jì)算節(jié)點(diǎn)來(lái)處理這 3 個(gè)分區(qū)的數(shù)據(jù)。也就是說(shuō) M2 的并發(fā)度從默認(rèn)的 1000,可以降低到 3,這在保證同樣的邏輯計(jì)算等效性與正確性的前提下,能大大降低計(jì)算資源的消耗,并數(shù)倍加速作業(yè)的運(yùn)行。這里的優(yōu)化來(lái)自幾個(gè)方面:
- M2 的并發(fā)度 (1000 -> 3) 以及處理的數(shù)據(jù)量大大降低
- M2 需要 shuffle 到 J 的數(shù)據(jù)量以及 shuffle 需要的計(jì)算量大大降低
- J 需要處理的數(shù)據(jù)量以及其并發(fā)度能大大降低
從上圖這個(gè)例子中我們也可以看到,為了保證 M1 -> M2 的調(diào)度順序上,DAG 中在 M1 和 M2 間引入了一條依賴(lài)邊,而這條邊上是沒(méi)有數(shù)據(jù)流動(dòng)的,是一條只表示執(zhí)行先后的依賴(lài)邊。這與傳統(tǒng) MR/DAG 執(zhí)行框架里,邊的連接與數(shù)據(jù)流動(dòng)緊綁定的假設(shè)也有不同,是在 DAG 2.0 中對(duì)于邊概念的一個(gè)拓展之一。
DAG 執(zhí)行引擎作為底層分布式調(diào)度執(zhí)行框架,其直接的對(duì)接"用戶(hù)"是上層計(jì)算引擎的開(kāi)發(fā)團(tuán)隊(duì),其升級(jí)對(duì)于終端用戶(hù)除了性能上的提升,直接的體感可能會(huì)少一點(diǎn)。這里我們舉一個(gè)終端用戶(hù)體感較強(qiáng)的具體例子,來(lái)展示 DAG 更加動(dòng)態(tài)的執(zhí)行能力,能夠給終端用戶(hù)帶來(lái)的直接好處。就是在 DAG 動(dòng)態(tài)能力的基礎(chǔ)上,實(shí)現(xiàn)的 LIMIT 的優(yōu)化。
對(duì)于 SQL 用戶(hù)來(lái)說(shuō),對(duì)數(shù)據(jù)進(jìn)行一些基本的 at hoc 操作,了解數(shù)據(jù)表的特性,一個(gè)非常常見(jiàn)的操作是 LIMIT,比如:
- SELECT * FROM tpch_lineitem WHERE l_orderkey > 0 LIMIT 5;
在分布式執(zhí)行框架上,這個(gè)操作對(duì)應(yīng)的執(zhí)行計(jì)劃,是通過(guò)將源表做切分后,然后調(diào)度起所需數(shù)目的 mapper 去讀取全部數(shù)據(jù),再將 mapper 的輸出匯總到 reducer 后去做最后的 LIMIT 截?cái)嗖僮鳌<僭O(shè)源表 (這里的 tpch_lineitem) 是一個(gè)很大的表,需要 1000 個(gè) mapper 才能讀取,那么在整個(gè)分布式執(zhí)行過(guò)程中,涉及的調(diào)度代價(jià)就是要調(diào)度 1000 mapper + 1 reducer。這個(gè)過(guò)程中會(huì)有一些上層計(jì)算引擎可以?xún)?yōu)化的地方,比如每個(gè) mapper 可以最多輸出 LIMIT 需要的 record 數(shù)目(這里的 LIMIT 5)提前退出,而不必處理完所有分配給它的數(shù)據(jù)分片等等。但是在一個(gè)靜態(tài)的執(zhí)行框架上,為了獲取這樣簡(jiǎn)單的信息,整體 1001 個(gè)計(jì)算節(jié)點(diǎn)的調(diào)度無(wú)法避免。這給這種 ad hoc query 執(zhí)行,帶來(lái)了巨大的 overhead, 在集群資源緊張的時(shí)候尤其明顯。
DAG 2.0 上, 針對(duì)這種 LIMIT 的場(chǎng)景,依托新執(zhí)行框架的動(dòng)態(tài)能力,實(shí)現(xiàn)了一些優(yōu)化,這主要包括幾方面:
- 上游 Exponential start:對(duì)于這種大概率下上游 mapper 計(jì)算節(jié)點(diǎn)不需要全部運(yùn)行的情況,DAG 框架將對(duì) mapper 進(jìn)行指數(shù)型的分批調(diào)度,也就是調(diào)度按照 1, 10 ... FULL 的分批執(zhí)行
- 下游的 Early scheduling:上游產(chǎn)生的 record 數(shù)目作為執(zhí)行過(guò)程中的統(tǒng)計(jì)數(shù)據(jù)上報(bào)給 AM, AM 在判斷上游已經(jīng)產(chǎn)生足夠的 record 條數(shù)后,則提前調(diào)度下游 reducer 來(lái)消費(fèi)上游的數(shù)據(jù)。
- 上游的 Early termination:下游 reducer 在判斷最終輸出的 LIMIT 條數(shù)已經(jīng)滿(mǎn)足條件后,直接退出。這時(shí)候 AM 可以觸發(fā)上游 mapper 整個(gè)邏輯節(jié)點(diǎn)的提前退出(在這種情況下,大部分 mapper 可能都還沒(méi)有調(diào)度起來(lái)),整個(gè)作業(yè)也能提前完成。
這種計(jì)算引擎和 DAG 在執(zhí)行過(guò)程中的靈活動(dòng)態(tài)交互,能夠帶來(lái)大量的資源節(jié)省,以及加速作業(yè)的執(zhí)行。在線(xiàn)下測(cè)試和實(shí)際上線(xiàn)效果上,基本上絕大多數(shù)作業(yè)在 mapper 執(zhí)行完 1 個(gè)計(jì)算節(jié)點(diǎn)后就能提前退出,而無(wú)需全量調(diào)起 (1000 vs 1)。
下圖是在線(xiàn)下測(cè)試中,當(dāng) mapper 并發(fā)為 4000 時(shí),上述 query 優(yōu)化前后的區(qū)別:
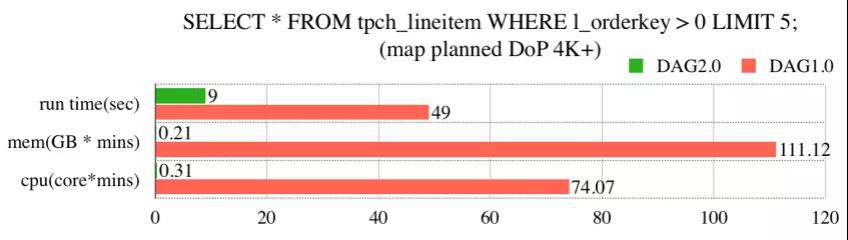
可以看到,執(zhí)行時(shí)間優(yōu)化后增速了 5X+, 計(jì)算資源的消耗更是減小了數(shù)百倍。
這個(gè)線(xiàn)下測(cè)試結(jié)果作為比較典型的例子,稍微有些理想化。為了評(píng)估真實(shí)的效果,在 DAG 2.0 上線(xiàn)后,選取了 LIMIT 優(yōu)化生效的線(xiàn)上作業(yè),統(tǒng)計(jì)了一星期結(jié)果如下:這個(gè)優(yōu)化平均為每個(gè)作業(yè)節(jié)省了 (254.5 cores x min CPU + 207.3 GB x min) 的計(jì)算資源,同時(shí)每個(gè)作業(yè)上,平均能節(jié)省 4349 個(gè)(無(wú)效)計(jì)算節(jié)點(diǎn)的調(diào)度。
LIMIT 執(zhí)行上的改進(jìn),作為一個(gè)針對(duì)特殊場(chǎng)景上實(shí)現(xiàn)的優(yōu)化,涉及了整個(gè) DAG 執(zhí)行不同策略的調(diào)整,這種細(xì)化的改進(jìn)能力,能更直觀的體現(xiàn) DAG 2.0 架構(gòu)升級(jí)諸多好處:靈活的架構(gòu)使得 DAG 的執(zhí)行中擁有了更多的動(dòng)態(tài)調(diào)整能力,也能和計(jì)算引擎在一起進(jìn)行更多有針對(duì)性的優(yōu)化。
不同情況下的動(dòng)態(tài)并發(fā)度調(diào)整,以及具體調(diào)度執(zhí)行策略的動(dòng)態(tài)調(diào)整,只是圖的物理特性動(dòng)態(tài)調(diào)整的幾個(gè)例子。事實(shí)上對(duì)于物理特性運(yùn)行時(shí)的調(diào)整,在 2.0 的框架之上有各種各樣的應(yīng)用,比如通過(guò)動(dòng)態(tài)數(shù)據(jù)編排/shuffle 來(lái)解決各種運(yùn)行期間的skew問(wèn)題等,這里不再做進(jìn)一步的展開(kāi)。接下來(lái)我們?cè)賮?lái)看看 DAG 2.0 上對(duì)于邏輯圖的動(dòng)態(tài)調(diào)整做的一些探索。
2)動(dòng)態(tài)邏輯圖的調(diào)整
分布式 SQL 中,map join 是一個(gè)比較常見(jiàn)的優(yōu)化,其實(shí)現(xiàn)原理是在 join 的兩個(gè)表中,如果有一個(gè)超小的表(可以 fit 到單個(gè)計(jì)算節(jié)點(diǎn)的內(nèi)存中),那對(duì)于這個(gè)超小表可以不做 shuffle,而是直接將其全量數(shù)據(jù) broadcast 到每個(gè)處理大表的分布式計(jì)算節(jié)點(diǎn)上。通過(guò)在內(nèi)存中直接建立 hash 表,完成 join 操作。map join 優(yōu)化能大量減少 (大表) shuffle 和排序,非常明顯的提升作業(yè)運(yùn)行性能。但是其局限性也同樣顯著:如果"超小表"實(shí)際不小,無(wú)法 fit 進(jìn)單機(jī)內(nèi)存,那么在試圖建立內(nèi)存中的 hash 表時(shí)就會(huì)因?yàn)? OOM 而導(dǎo)致整個(gè)分布式作業(yè)的失敗,而需要重跑。所以雖然 map join 在正確使用時(shí),可以帶來(lái)較大的性能提升,但實(shí)際上優(yōu)化器在產(chǎn)生 map join 的 plan 時(shí)需要偏保守,很多情況下需要用戶(hù)顯式的提供 map join hint 來(lái)產(chǎn)生這種優(yōu)化。此外不管是用戶(hù)還是優(yōu)化器的選擇,對(duì)于非源表的輸入都無(wú)法做很好的判斷,因?yàn)橹虚g數(shù)據(jù)的大小往往需要在作業(yè)運(yùn)行過(guò)程中才能準(zhǔn)確得知。

而 map join 與默認(rèn) join 方式 (sorted merge join) 對(duì)應(yīng)的其實(shí)是兩種不同優(yōu)化器執(zhí)行計(jì)劃,在 DAG 層面,其對(duì)應(yīng)的是兩種不同的邏輯圖。要支持這種運(yùn)行過(guò)程中根據(jù)中間數(shù)據(jù)特性的動(dòng)態(tài)優(yōu)化,就需要 DAG 框架具備動(dòng)態(tài)邏輯圖的執(zhí)行能力,這也是在 DAG 2.0 上開(kāi)發(fā)的 conditional join 功能。
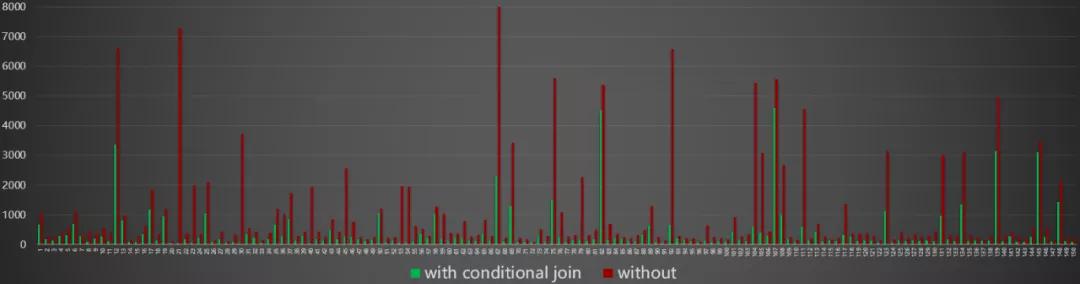
如同下圖展示,在對(duì)于 join 使用的算法無(wú)法被事先確定的時(shí)候,允許優(yōu)化器提供一個(gè) conditional DAG,這樣的 DAG 同時(shí)包括使用兩種不同 join 的方式對(duì)應(yīng)的不同執(zhí)行計(jì)劃支路。在實(shí)際執(zhí)行時(shí),AM 根據(jù)上游產(chǎn)出數(shù)據(jù)量,動(dòng)態(tài)選擇一條支路執(zhí)行 (plan A or plan B)。這樣子的動(dòng)態(tài)邏輯圖執(zhí)行流程,能夠保證每次作業(yè)運(yùn)行時(shí)都能根據(jù)實(shí)際作業(yè)數(shù)據(jù)特性,選擇最優(yōu)的執(zhí)行計(jì)劃。

conditional join 是動(dòng)態(tài)邏輯圖的第一個(gè)落地場(chǎng)景,在線(xiàn)上選擇一批適用性作業(yè),動(dòng)態(tài)的 conditional join 相比靜態(tài)的執(zhí)行計(jì)劃,整體獲得了將近 3X 的性能提升。
2 混合 Bubble 模式
Bubble 模式是我們?cè)?DAG 2.0 架構(gòu)上探索的一種全新的作業(yè)運(yùn)行方式,通過(guò)對(duì)于 bubble 大小以及位置的調(diào)整,可以獲取性能和資源利用率的不同 tradeoff 點(diǎn)。這里通過(guò)一些更加直觀的例子,來(lái)幫助大家理解 Bubble 執(zhí)行在分布式作業(yè)中的實(shí)際應(yīng)用。
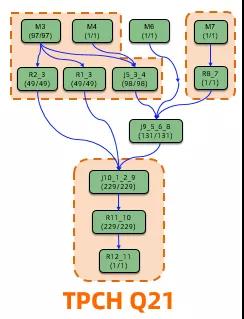
在上圖的 TPCH Q21 上。比如在 Q21 上,我們看到了通過(guò)將作業(yè)被切分為三個(gè) "bubble",數(shù)據(jù)能夠有效的在節(jié)點(diǎn)之間 pipeline 起來(lái),并且通過(guò)熱點(diǎn)節(jié)點(diǎn)實(shí)現(xiàn)調(diào)度的加速。最終消耗的資源數(shù) (cpu * time) 是準(zhǔn)實(shí)時(shí)作業(yè)的 35%, 而性能則與一體化調(diào)度的準(zhǔn)實(shí)時(shí)作業(yè)非常相近 (96%), 比離線(xiàn)作業(yè)性能提升 70% 左右。
在標(biāo)準(zhǔn) TPCH 1TB 全量測(cè)試中,混合 bubble 模式體現(xiàn)出了相比離線(xiàn)和準(zhǔn)實(shí)時(shí)的一體化模式 (gang scheduling) 更好的資源/性能 tradeoff。選用 Greedy Bubble(size = 500) 的策略,bubble 相比離線(xiàn)作業(yè)性能提升了 2X (資源消耗僅增加 17%,具體數(shù)值略)。同時(shí)與一體化調(diào)度的準(zhǔn)實(shí)時(shí)作業(yè)比較,bubble 執(zhí)行在只消耗了 40% 不到的資源 (cpu * time) 的前提下,其性能達(dá)到了準(zhǔn)實(shí)時(shí)作業(yè)的 85% (具體數(shù)值略)。可以看到,這種新型的 bubble 執(zhí)行模式,允許我們?cè)趯?shí)際應(yīng)用中獲取很好的性能與資源的平衡,達(dá)到系統(tǒng)資源有效的利用。Bubble 執(zhí)行模式目前正在阿里集團(tuán)內(nèi)部全量上線(xiàn)中,我們?cè)趯?shí)際線(xiàn)上的作業(yè)也看到了與 TPCH 測(cè)試非常相似的效果。
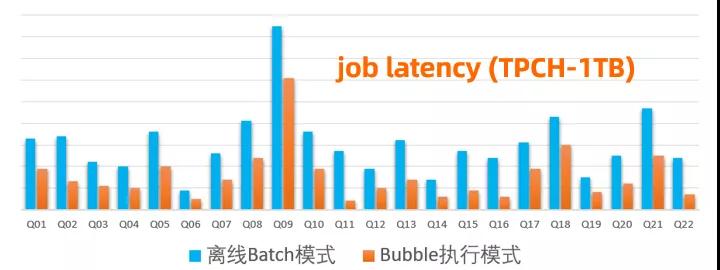
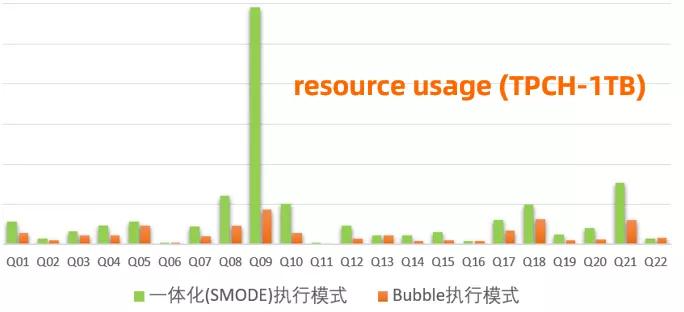
如同之前所述,混合 bubble 模式支持了不同切分策略,這里提供的只是一種切分策略上的效果。在與上層計(jì)算引擎 (e.g., MaxCompute 優(yōu)化器) 緊密結(jié)合時(shí),這種 DAG 分布式調(diào)度 bubble 執(zhí)行的能力,能夠允許我們根據(jù)可用資源和作業(yè)計(jì)算特點(diǎn),來(lái)尋找性能與資源利用率的最佳平衡點(diǎn)。
四 資源的動(dòng)態(tài)配置和動(dòng)態(tài)管理
傳統(tǒng)分布式作業(yè)對(duì)于每個(gè)計(jì)算節(jié)點(diǎn)需要的資源類(lèi)型 (CPU/GPU/Memory) 和大小都是預(yù)先確定下來(lái)的。然而在作業(yè)運(yùn)行之前,對(duì)計(jì)算節(jié)點(diǎn)資源類(lèi)型和大小的合理選擇,是比較困難的。即便對(duì)于計(jì)算引擎的開(kāi)發(fā)者,也需要通過(guò)一些比較復(fù)雜的規(guī)則,才能預(yù)估出大概合理的配置。而對(duì)于需要將這些配置透明給終端用戶(hù)的計(jì)算模式,終端用戶(hù)要做出選擇就更加困難。
在這里以 PAI 的 Tensorflow (TF) 作業(yè)為例,描述 DAG 2.0 的資源動(dòng)態(tài)配置能力,怎樣幫助平臺(tái)的 TF 作業(yè)選擇合理的 GPU 類(lèi)型資源以及提高 GPU 資源的利用率。相比 CPU 而言,GPU 作為一種較新的計(jì)算資源,硬件的更新?lián)Q代較快,同時(shí)普通終端用戶(hù)對(duì)于其計(jì)算特點(diǎn)也相對(duì)不了解。因此終端用戶(hù)在指定 GPU 資源類(lèi)型時(shí),經(jīng)常存在著不合理的情況。與此同時(shí),GPU 在線(xiàn)上又是相對(duì)稀缺資源。今天在線(xiàn)上,GPU 申請(qǐng)量經(jīng)常超過(guò)集群 GPU 總數(shù),導(dǎo)致用戶(hù)需要花很長(zhǎng)時(shí)間排隊(duì)等待資源。而另外一方面,集群中 GPU 的實(shí)際利用率卻偏低,平均只有 20% 左右。這種申請(qǐng)和實(shí)際使用之間存在的 Gap,往往是由于用戶(hù)作業(yè)配置中,事先指定的 GPU 資源配置不合理造成。
在 DAG 2.0 的框架上,PAI TF GPU 作業(yè) (見(jiàn) session 2.2.2 的 dynamic PS DAG) 引入了一個(gè)額外的"計(jì)算控制節(jié)點(diǎn)",可以通過(guò)運(yùn)行 PAI 平臺(tái)的資源預(yù)測(cè)算法,來(lái)判斷當(dāng)前作業(yè)實(shí)際需要的 GPU 資源類(lèi)型,并在必要的時(shí)候,通過(guò)向 AM 發(fā)送動(dòng)態(tài)事件,來(lái)請(qǐng)求修改下游 worker 實(shí)際申請(qǐng)的 GPU 類(lèi)型。這其中資源預(yù)測(cè)算法,可以是根據(jù)算法的類(lèi)型,數(shù)據(jù)的特點(diǎn),以及歷史作業(yè)信息來(lái)做 HBO (history based optimization),也可以通過(guò) dry-run 的方法來(lái)進(jìn)行試運(yùn)行,以此確定合理的資源類(lèi)型。
具體實(shí)現(xiàn)上,這個(gè)場(chǎng)景中 control stage 與 Worker 之間通過(guò) concurrent edge 連接,這條邊上的調(diào)度觸發(fā)條件是在 control stage 已經(jīng)做出資源選擇決定之后,通過(guò)其發(fā)出的事件來(lái)觸發(fā)。這樣的作業(yè)運(yùn)行期間的動(dòng)態(tài)資源配置,在線(xiàn)上功能測(cè)試中,帶來(lái)了 40% 以上的集群 GPU 利用率提升。
作為物理特性一個(gè)重要的維度,對(duì)計(jì)算節(jié)點(diǎn)的資源特性在運(yùn)行時(shí)的動(dòng)態(tài)調(diào)整能力,在 PAI 以及 MaxCompute 上都能找到廣泛的應(yīng)用。以 MaxCompute SQL 為例,對(duì)于下游節(jié)點(diǎn)的 CPU/Memory 的大小,可以根據(jù)上游數(shù)據(jù)的特點(diǎn)進(jìn)行有效的預(yù)判;同時(shí)對(duì)于系統(tǒng)中發(fā)生的 OOM,可以嘗試自動(dòng)調(diào)高 OOM 后重試的計(jì)算節(jié)點(diǎn)的內(nèi)存申請(qǐng),避免作業(yè)的失敗,等等。這些都是在 DAG 2.0 上新的架構(gòu)上實(shí)現(xiàn)的一些新功能,在這里不做具體的展開(kāi)。
五 工程化與上線(xiàn)
作為分布式系統(tǒng)的底座,DAG 本身的動(dòng)態(tài)能力以及靈活度,在與上層計(jì)算引擎結(jié)合時(shí),能夠支持上層計(jì)算實(shí)現(xiàn)更加高效準(zhǔn)確的執(zhí)行計(jì)劃,在特定場(chǎng)景上實(shí)現(xiàn)數(shù)倍的性能提升以及對(duì)資源利用率的提高。在上文中,也集中介紹了整個(gè) DAG 2.0 項(xiàng)目工作中,開(kāi)發(fā)實(shí)現(xiàn)的一些新功能與新的計(jì)算模式。除了對(duì)接計(jì)算引擎來(lái)實(shí)現(xiàn)更高效的執(zhí)行計(jì)劃,調(diào)度本身的敏捷性,是 AM/DAG 執(zhí)行性能的基本素質(zhì)。DAG 2.0 的調(diào)度決策均基于事件驅(qū)動(dòng)框架以及靈活的狀態(tài)機(jī)設(shè)計(jì)來(lái)實(shí)現(xiàn),在這里也交出 DAG 2.0 在基本工程素養(yǎng)和性能方面的成績(jī)單:
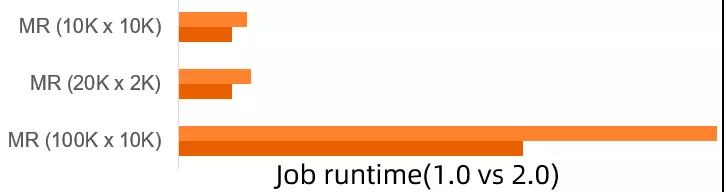
這里選用了最簡(jiǎn)單的 Map-Reduce (MR) 作業(yè)為例,對(duì)于這種作業(yè),調(diào)度執(zhí)行上并無(wú)太多可以取巧的地方,考驗(yàn)的是調(diào)度系統(tǒng)本身的敏捷度和整個(gè)處理流程中的全面去阻塞能力。這個(gè)例子也凸顯了 DAG 2.0 的調(diào)度性能優(yōu)勢(shì),尤其作業(yè)規(guī)模越大,優(yōu)勢(shì)越發(fā)明顯。此外,對(duì)于更接近線(xiàn)上的 work-load 的場(chǎng)景,在 TPCDS 標(biāo)準(zhǔn) benchmark 中,當(dāng)執(zhí)行計(jì)劃和運(yùn)行邏輯完全相同時(shí),2.0 (未打開(kāi)動(dòng)態(tài)執(zhí)行等功能)的高性能調(diào)度也給作業(yè)帶來(lái)了顯著的提升。
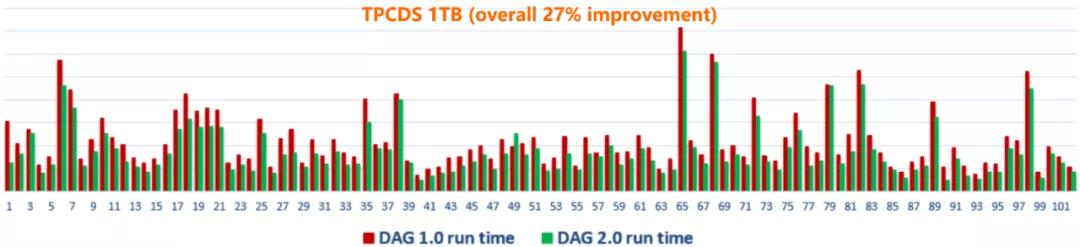
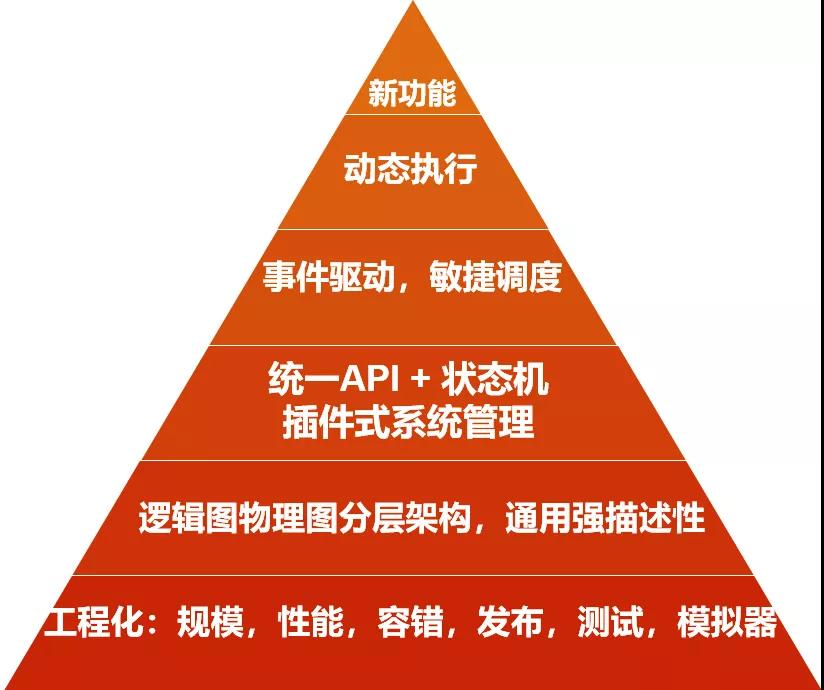
最后,對(duì)于一個(gè)從頭到尾完整替代原有系統(tǒng)的新一代的全新框架,怎樣無(wú)縫對(duì)接線(xiàn)上場(chǎng)景,實(shí)現(xiàn)大規(guī)模的上線(xiàn),是一個(gè)同樣重要(甚至更重要)的話(huà)題,也是對(duì)一個(gè)實(shí)際生產(chǎn)系統(tǒng)進(jìn)行升級(jí),與小范圍的新系統(tǒng) POC 之間最大的區(qū)別。今天的伏羲調(diào)度系統(tǒng),每天支撐著阿里集團(tuán)內(nèi)外大數(shù)據(jù)計(jì)算平臺(tái)千萬(wàn)的分布式作業(yè)。DAG/AM 這一核心分布式調(diào)度執(zhí)行組件的更新?lián)Q代,要完整替換線(xiàn)上已經(jīng)支撐了大數(shù)據(jù)業(yè)務(wù) 10 年的分布式生產(chǎn)系統(tǒng),而不造成現(xiàn)有場(chǎng)景的失敗,這需要的不僅僅是架構(gòu)和設(shè)計(jì)上的先進(jìn)性。如何在"飛行中換引擎", 保質(zhì)保量的實(shí)現(xiàn)系統(tǒng)升級(jí),其挑戰(zhàn)完全不亞于新的系統(tǒng)架構(gòu)本身的設(shè)計(jì)。要實(shí)現(xiàn)這樣的升級(jí),擁有一個(gè)穩(wěn)固的工程基座,以及測(cè)試/發(fā)布框架,都是不可或缺的。沒(méi)有這樣子的底座,上層的動(dòng)態(tài)功能與新計(jì)算模式,都無(wú)從談起。
目前 DAG 2.0 目前已全面覆蓋了阿里集團(tuán) MaxCompute 所有線(xiàn)上的 SQL 離線(xiàn)作業(yè)和所有準(zhǔn)實(shí)時(shí)作業(yè),以及 PAI 平臺(tái)的所有 Tensorflow 作業(yè)(CPU 和 GPU)+ PyTorch 作業(yè)。每天支撐數(shù)千萬(wàn)分布式作業(yè)的運(yùn)行,并經(jīng)受了 19 年雙11 /雙12 的考驗(yàn)。在面對(duì)兩次大促創(chuàng)歷史記錄的數(shù)據(jù)洪峰(相比 18 年增長(zhǎng) 50%+)壓力下,保障了集團(tuán)重點(diǎn)基線(xiàn)在大促當(dāng)天準(zhǔn)時(shí)產(chǎn)出。與此同時(shí),更多種類(lèi)型的作業(yè)(例如跨集群復(fù)制作業(yè)等等)正在遷移到 DAG 2.0 的新架構(gòu),并且依托新的架構(gòu)升級(jí)計(jì)算作業(yè)本身的能力。DAG 2.0 的框架基座的上線(xiàn),為各條計(jì)算線(xiàn)上依托其實(shí)現(xiàn)新功能打下了堅(jiān)實(shí)基礎(chǔ)。
六 展望
伏羲 DAG 2.0 核心架構(gòu)的升級(jí),旨在夯實(shí)阿里計(jì)算平臺(tái)長(zhǎng)期發(fā)展的基礎(chǔ),并支持上層計(jì)算引擎與分布式調(diào)度方面結(jié)合,實(shí)現(xiàn)各種創(chuàng)新和創(chuàng)建新計(jì)算生態(tài)。架構(gòu)的升級(jí)本身是向前邁出的重要一步,但也只是第一步。要支撐企業(yè)級(jí)的,各種規(guī)模,各種模式的全頻譜計(jì)算平臺(tái),需要將新架構(gòu)的能力和上層計(jì)算引擎,以及伏羲系統(tǒng)其他組件進(jìn)行深度整合。依托阿里的應(yīng)用場(chǎng)景,DAG 2.0 除了在作業(yè)規(guī)模等方面繼續(xù)在業(yè)界保持領(lǐng)先之外,架構(gòu)和功能上也有許多創(chuàng)新, 比如前面我們已經(jīng)介紹過(guò)的:
- 在業(yè)界首次在分布式執(zhí)行框架上,實(shí)現(xiàn)了執(zhí)行過(guò)程中邏輯圖和物理圖的雙重動(dòng)態(tài)可調(diào);
- 通過(guò) Bubble 機(jī)制實(shí)現(xiàn)了混合的計(jì)算模式,探索資源利用率和作業(yè)性能間的最佳平衡。
除此之外,2.0 更加清晰的系統(tǒng)封層架構(gòu)帶來(lái)的一個(gè)重要改變就是能有利于新功能更快速開(kāi)發(fā),提速平臺(tái)和引擎向前創(chuàng)新。由于篇幅有限,本文只能由點(diǎn)及面地介紹一部分新功能與新計(jì)算模式,還有許許多多已經(jīng)實(shí)現(xiàn),或正在開(kāi)發(fā)中的功能,在業(yè)界都是全新的探索,暫時(shí)不做進(jìn)一步展開(kāi),比如:
- 準(zhǔn)實(shí)時(shí)作業(yè)體系架構(gòu)的整體升級(jí): 資源管理與多作業(yè)管理的解耦,支持準(zhǔn)實(shí)時(shí)作業(yè)場(chǎng)景上的動(dòng)態(tài)圖功能。
- 常駐的單 container 多 slot 執(zhí)行的 cache-aware 查詢(xún)加速服務(wù) (MaxCompute 短查詢(xún))
- 基于狀態(tài)機(jī)的作業(yè)節(jié)點(diǎn)管理以及失敗下的智能重跑機(jī)制。
- 動(dòng)態(tài)可定義的 shuffle 方式:通過(guò) recursive shuffle 等方式動(dòng)態(tài)解決線(xiàn)上大規(guī)模作業(yè)中的 in-cast 問(wèn)題。
- 基于 adaptive 的中間數(shù)據(jù)動(dòng)態(tài)切分與聚合,解決實(shí)際分布式作業(yè)中各種數(shù)據(jù)傾斜問(wèn)題
- 支持 PAI TF GPU 作業(yè)的多執(zhí)行計(jì)劃選項(xiàng)。
- 通過(guò) DAG 執(zhí)行過(guò)程中與優(yōu)化器的交互,實(shí)現(xiàn)漸進(jìn)式的交互式動(dòng)態(tài)優(yōu)化。
- 支持 Imperative 語(yǔ)言特性,通過(guò) DAG 的動(dòng)態(tài)自增長(zhǎng)等能力,對(duì)接 IF/ELSE/LOOP 等語(yǔ)義。
核心調(diào)度底座能力的提升,能夠?yàn)樯蠈拥母鞣N分布式計(jì)算引擎提供真正企業(yè)級(jí)的服務(wù)能力,提供必須的彈藥。而這些計(jì)算調(diào)度能力提升帶來(lái)的紅利,最終會(huì)通過(guò) MaxCompute 和 PAI 等引擎,透?jìng)鞯浇K端的阿里云計(jì)算服務(wù)的各個(gè)企業(yè)。在過(guò)去的十年,阿里業(yè)務(wù)由內(nèi)向外的驅(qū)動(dòng),鍛造了業(yè)界規(guī)模最大的云上分布式平臺(tái)。而通過(guò)更好服務(wù)集團(tuán)內(nèi)部以及云上的企業(yè)用戶(hù),我們希望能夠提升平臺(tái)的企業(yè)級(jí)服務(wù)能力,可以完成由內(nèi)向外,到由外至內(nèi)的整個(gè)正向循環(huán)過(guò)程,推動(dòng)計(jì)算系統(tǒng)螺旋式上升的不斷創(chuàng)新,并通過(guò)性能/規(guī)模,以及智能化自適應(yīng)能力兩個(gè)維度方面的推進(jìn),降低分布式計(jì)算服務(wù)的使用門(mén)檻,真正實(shí)現(xiàn)大數(shù)據(jù)的普惠。
Reference
[1]Dryad: Distributed Data-parallel Programs from Sequential Building Blocks
Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, Dennis Fetterly, Proceedings of the 2007 Eurosys Conference | March 2007
[2]MapReduce: Simplified data processing on large clusters
Jeff Dean and Sanjay Ghemawat, Proceedings of the 6th Symposium on Operating
Systems Design and Implementation (OSDI)| December 2004
[3]Apache Tez: A Unifying Framework for Modeling and Building Data Processing Applications
Bikas Sahah, Hitesh Shahh etc., Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data| June 2015