微軟計算機視覺創(chuàng)研論壇首日干貨:3項前沿檢測技術(shù)解讀

5月15日消息,昨日上午9點,微軟亞洲研究院創(chuàng)研論壇CVPR 2020論文分享會線上開幕。會議有19位計算機視覺(CV)領(lǐng)域?qū)W者分享最新研究成果,講解內(nèi)容涉及檢測、多模態(tài)、底層視覺、圖像生成、機器學(xué)習(xí)5大方向。
14日上午,3位計算機視覺檢測方向的研究員做了分享,分別介紹了先進的人臉識別技術(shù)、動作檢測技術(shù)和目標檢測技術(shù)。智東西對這3項先進技術(shù)進行解讀。
微軟亞洲研究院創(chuàng)研論壇CVPR 2020論文分享會是計算機視覺(CV)領(lǐng)域最重要的會議之一,本屆會議共分享近20項CV領(lǐng)域前沿技術(shù)。
一、X射線檢測算法識別假圖像,準確率可達95.4%
Deepfake技術(shù)的濫用輕則造成虛假信息問題,重則會引起金融安全風(fēng)險、侵權(quán)問題等。一些Deepfake圖像可以做到以假亂真,人類肉眼難以判斷出來。這種情況下,人臉識別技術(shù)可以幫我們辨別。
現(xiàn)有的人臉識別工具大多針對某種特定Deepfake技術(shù)訓(xùn)練,用假人臉圖像作為輸入。就是說,人臉識別技術(shù)只能識別出特定方法合成的假圖像。一旦Deepfake技術(shù)進化或換用其他Deepfake技術(shù),人臉識別模型就可能失效。
微軟亞洲研究院研究員鮑建敏講解了人臉X射線識別技術(shù)(Face X-ray),這種技術(shù)用真實人臉圖像進行訓(xùn)練。即使Deepfake技術(shù)進化,X射線人臉檢測算法也能保持較高的準確性。
制作一張假圖像的方法是把兩張圖像疊加,即把一張修改過的人臉圖像(前景)合成到背景圖像(后景)中。研究人員注意到,由于每張圖像拍攝或制作過程中用到不同的硬件(傳感器、透鏡等)或軟件(壓縮、合成算法等),前景圖像和后景圖像的特征不可能完全相同,因此人臉圖像和背景圖像之間存在一個“邊界”。
Face X-ray技術(shù)利用了上述特征,用人臉灰度圖像作為輸入。Face X-ray模型可以識別出不同灰度圖像之間的差異,這樣不僅可以顯示出人臉圖像是真實的還是偽造的,還能確定虛假圖像混合邊界的位置。

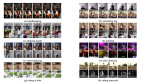
▲左起第一張為真實圖像,其他均為假圖像,F(xiàn)ace X-ray模型檢測出了假圖像混合邊界位置。
研究人員對比了Face X-ray模型與之前人臉識別工具的性能。結(jié)果顯示,模型檢測出來的假臉幀數(shù)比之前的二分類方法更多,識別準確率最高可達95.4%。
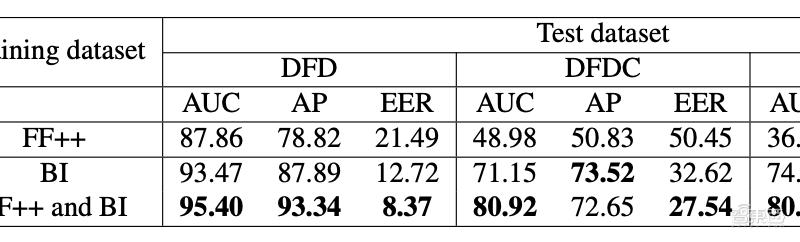
鮑建敏指出,算法還有一定局限性。比如,F(xiàn)ace X-ray主要用人臉圖像數(shù)據(jù)庫FF++進行訓(xùn)練。FF++中大部分圖像都是正臉圖像,所以模型識別側(cè)臉的準確性較低。
二、DAGM模型:區(qū)分動作與上下文,準確識別出動作
微軟亞洲研究院研究員戴琦講解了一種動作檢測技術(shù),該技術(shù)可以從視頻中識別出動作。據(jù)了解,目前的動作檢測技術(shù)可以分為全監(jiān)督方法和弱監(jiān)督方法。
全監(jiān)督方法的動作檢測模型需要在訓(xùn)練過程中需要對動作間隔進行時間注釋,十分昂貴和費時。因此現(xiàn)有的動作檢測工具多采用弱監(jiān)督動作定位(WSAL,weakly-supervised action localization)技術(shù)。
WSAL技術(shù)有兩種類型,第一類建立一個從上到下的管道,學(xué)習(xí)一個視頻級別的分類器,通過檢查生成的時間分類動作地圖(TACM,temporal class activation map)來獲得幀注意力(frame attention)。第二類是從下到上的,直接從原始數(shù)據(jù)中預(yù)測時間注意力(temporal attention),然后從視頻級監(jiān)控的視頻分類中優(yōu)化任務(wù)。
兩種方法都依賴于視頻級別的分類模型,這會導(dǎo)致動作和上下文混淆(action-context confusion)的問題。比如,在一段跳遠的視頻中,跳遠動作(action)僅包括接近、跳躍、著陸3個階段,但是工作檢測模型常把準備和結(jié)束階段(context)也選中。

研究人員認為,解決這一問題的關(guān)鍵在于找到動作和上下文之間的區(qū)別。他們用判別性注意力模型(Discriminative Attention Modeling)和生成性注意力模型(GAM,Generative Attention Modeling)優(yōu)化檢測工具,提出了判別性和生成性注意力模型(DAGM,Discriminative and Gener-ative Attention Modeling)。
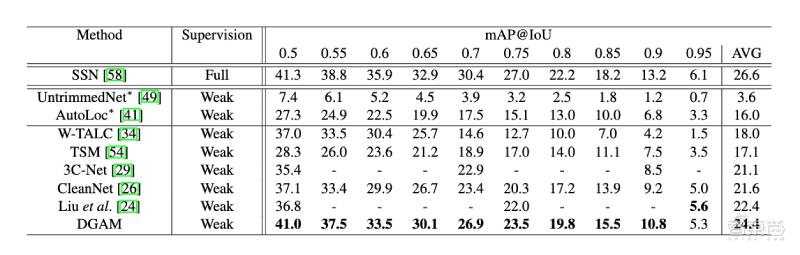
研究人員對比了DAGM模型與其他弱監(jiān)督動作工具的性能。結(jié)果顯示,DAGM模型的性能較好,平均精度最高可達41。
三、TSD算法:把檢測工具精度提高3~5%
目標識別算法一般從兩個維度檢測物體:分類(Classification)和回歸(Localization)。前者指識別物體的屬性,后者指定位物體的位置。
傳統(tǒng)檢測方法通常一起學(xué)習(xí)分類和回歸,共享物體潛在存在的區(qū)域框(Proposal)和特征提取器(Sibling head)。
這種檢測方法的局限性是最終輸出的圖片框的分類置信度和檢測框的準確度不一致,識別準確率較低。
研究人員發(fā)現(xiàn),這是因為分類任務(wù)和回歸任務(wù)存在差別:分類任務(wù)更關(guān)注語義信息豐富的地方,回歸任務(wù)更關(guān)注物體的邊界。因此,共享物體潛在存在的區(qū)域框(Proposal)和特征提取器(Sibling head)會對檢測結(jié)果造成影響。
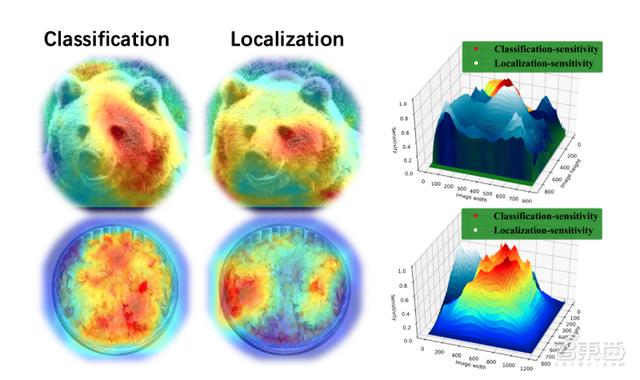
商湯科技X-Lab研究員宋廣錄介紹了基于任務(wù)間空間自適應(yīng)解耦(TSD,task-aware spatial disentanglement)檢測算法,即在檢測器頭部應(yīng)用特定設(shè)計的偏移量生成策略以及聯(lián)合訓(xùn)練優(yōu)化漸進損失。結(jié)果顯示,搭配TSD算法的檢測工具的檢測精度能提高3~5%。
結(jié)語:CV研究面臨語義、魯棒性的挑戰(zhàn)
三位研究人員分享結(jié)束后,美國羅徹斯特大學(xué)羅杰波教授、加州大學(xué)伯克利分校馬毅教授、加州大學(xué)圣地亞哥分校屠卓文教授、美國加州大學(xué)楊明玄教授、Wormpex AI Research華剛教授進行了圓桌論壇。這5位教授都曾擔(dān)任過CVPR會議主席。
在題目選擇、寫作技巧方面,5位教授對CV研究者給出許多建議,比如,他們認為研究者不必盲目追求研究熱點,而應(yīng)該選擇自己感興趣的題目;剛剛起步的研究者可以借鑒成熟研究者的論文結(jié)構(gòu)。他們強調(diào),論文預(yù)印本網(wǎng)站arXiv上的論文質(zhì)量良莠不齊,研究者在借鑒時應(yīng)該注意甄別。
另外,5位教授指出,目前CV研究面臨的兩大主要挑戰(zhàn)來自語義和魯棒性。對語義的理解關(guān)系著模型能否完成更高級別的任務(wù)。在醫(yī)療、無人機、航空航天等領(lǐng)域中,CV模型的魯棒性直接影響到安全。
因此,在之后的CV研究中,提升CV模型對語義的理解能力和魯棒性仍是重點。