Go 服務亂碼引發的線上事故
最近遇到了一起依賴升級 + 異常數據引發的線上事故,教訓慘痛,本文對此進行回故和總結。
背景
起因是我們使用的服務框架版本比較老,GC 次數的 metrics 打點一直為 0,咨詢了相關同學后,決定升級框架。升級的過程中,出現了 useofinternalpackagexxxnotallowed 的報錯,又咨詢了一下相關同學后,嘗試使用 go mod 解決。
從 go vendor 到 go mod 的升級的過程也不太順利,這里按下不表,最終是升級成功了。一同升級的還有 Go 版本,從 1.11 升級到 1.13。
周四上完線后,一切都看似很不錯:內存占用、GC 消耗的 CPU 有了優化,GC 次數的監控也有了。因為涉及到公司內部數據,圖我就不放了。
周五、周六都平安度過,周日出問題了,小組的同學從下午 12 點左右一直肝到凌晨 12 點,才松了一口氣。可憐我們來之不易的一個周日!
現象
周日 11 點 45 左右,端口的調用失敗率報警,同時有業務方反饋調用接口報錯。
同志們,關鍵時刻,完善的報警能給事故的處理和恢復贏得時間啊!
By case 排查,發現服務 shard3 集群的機器報 i/o timeout 錯誤。服務共有 4 個分片集群(根據 ID hash 到對應分片),其他 3 個集群完全正常。接著發現 shard3 集群的機器內存正常、端口還在,但 in/out 流量全部掉到幾十 KB/s,看日志也沒有發現任何異常。
重啟 shard3 集群的服務,重啟后的服務恢復正常,訪問 debug 端口,也是正常的。然而,十幾分鐘后,恢復的服務再次出現異常:in/out 流量再次掉到幾十 KB/s,訪問 debug 端口也沒有任何響應,開始慌了。
處理
上線出問題,第一時間回滾!
穩定性里面很重要的一條就是:有問題,先回滾。先止損,將事故影響降到最低,事后再來追查根因,總結復盤。
于是開始操作回滾, reset 到周四上線之前的一個 commit,重新打包,上線 shard3 集群。之后,對外接口完全恢復,操作回滾其他集群。
服務啟動之前,需要先加載幾十個 G 左右的數據,啟動過程長達 10+ min。我申請了一臺線上問題機器的 root 權限,執行了 strace-p 命令:

發現服務卡在 futex 系統調用上,這很明顯是一個 timer,但是 timer 為何會卡住?正常情況下,會有各種像 write,read 的系統調用,至少打日志、上報 mertrics 打點數據都會有 write 系統調用吧,哈?再執行 perf top 命令:
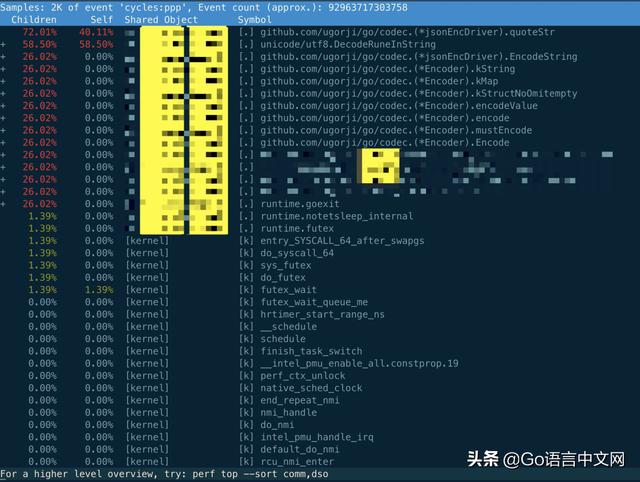
相關的只有 codec 函數,再看服務進程:
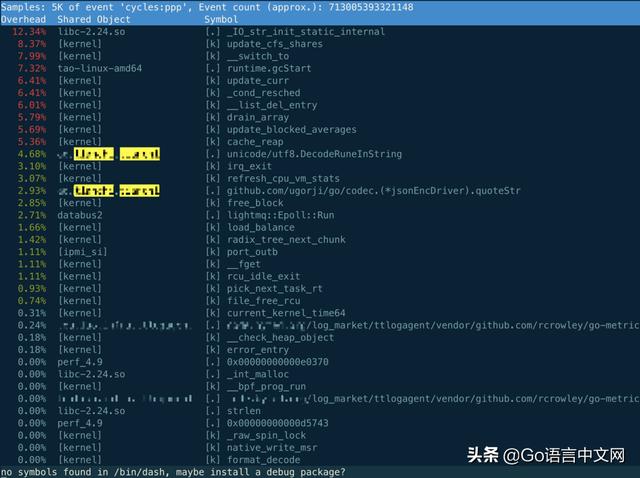
看 perf 輸出的結果,全部聚焦到 codec 這個第三方庫上,主要的兩個函數竟然是 codec.quoteStr 和 utf8.DecodeRuneInString。而我們用 codec 的地方是在程序啟動時加載數據文件以及定時的 dump 文件到本地。現在程序已經啟動了,只可能是 dump 文件出問題了。查看相關日志,果然有開始 dump 文件的日志記錄,卻一直沒有 dump 成功的記錄。
追查
事后追查階段嘗試在 test 集群上重現故障,因為只有單個分片出問題,說明此故障和特定數據有關,是 hash 到分片 3 的數據引起的問題。
又因為 test 集群并沒有分片,所以強行(改代碼 && 改環境變量)將其偽裝成 shard3 集群,然則并沒有復現,猜測可能是計劃下線了。
周二的時候,終于在 test 集群上模擬分片 1 時重現了線上故障。
對比 codec 的版本問題,果然有問題:周四上線前, vendor.json 里的版本是 v1.1.7,上線后,升級到了 v1.1.8,看來找到問題了!修改 codec 的版本,重新編譯、部署,問題依然存在!
這時,組里其他同學反饋 2018 年的時候也出過 codec 的問題,當時也是出現了異常數據導致重啟時加載文件不成功。于是我直接將周四上線前 vendor 文件夾里 codec.quoteStr 函數的代碼和 codec 的 v1.1.7 代碼進行對比,并不相同!vendor.json 里的版本并沒有正確反應 vendor 里實際的 codec 版本!!!
進一步查看提交記錄,發現在 2017 年 11 月份的時候有一次提交,修改了 vendor 文件夾里的代碼,但這時 vendor.json 并沒有 codec 記錄。而在 2019 年 11 月的一次提交,則只在 vendor.json 里增加了一條 codec 記錄,vendor 文件夾里的代碼并沒有更改:
- {
- "checksumSHA1": "wfboMqCTVImg0gW31jvyvCymJPE=",
- "path": "github.com/ugorji/go/codec",
- "revision": "e118e2d506a6b252f6b85f2e2f2ac1bfed82f1b8",
- "revisionTime": "2019-07-23T09:17:30Z",
- "tree": true
- }
仔細比對代碼,主要差異在這:
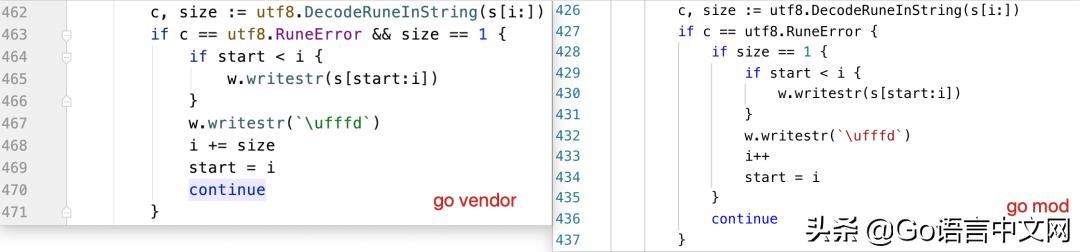
從現象及源碼看,大概率是在 codec.quoteStr 里死循環了!由于 Go 1.14 前都無法搶占正在執行無限循環且沒有任何函數調用的 goroutine,因此一旦出現死循環,將要進行 GC 的時候,其他所有 goroutine 都會停止,并且都在等著無限循環的 goroutine 停下來,遺憾的是,由于 for{} 循環里沒有進行函數調用,無法插入搶占標記并進行搶占。于是,就出現了這樣一幕:

只有 dump 數據文件這一個 goroutine 在干活,而且做的又是無限循環,服務整體對外表現就像是“死機”了一樣。并且這個 goroutine 由一個 timer 觸發工作,所以一開始我們看到的卡在一個 futex 調用上就可以解釋得通。因為 runtime 都停止工作了,timer 自然就沒法“到期”了。
接著,使用 Go 1.14 去編譯有問題的代碼版本,上到 test 集群,果然問題“消失”。服務狀態完全恢復正常,唯一不正常的是數據文件無法 dump 下來了,因為即使是 Go 1.14,也依然在執行無限循環,不干“正事”。
接下來的問題就是找到異常的數據了。使用上線前的版本(使用 go vendor),將 codec 替換為最新的 v1.1.8 版本,并且在 quoteStr 函數里打上了幾行日志:
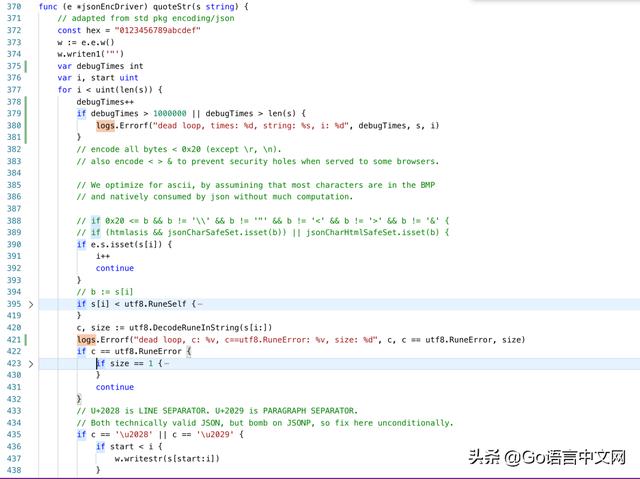
部署到 test 集群,問題復現:
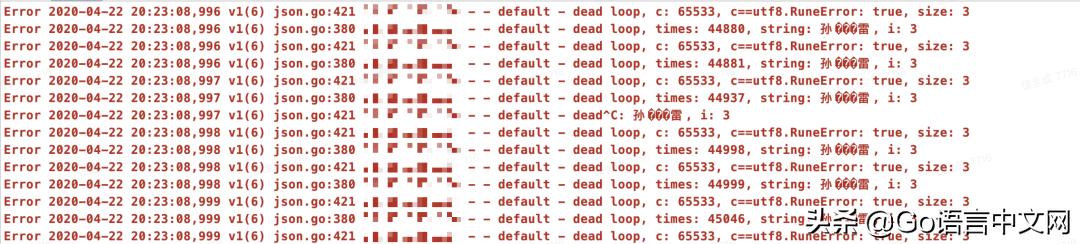
異常數據就是:“孫���雷”:
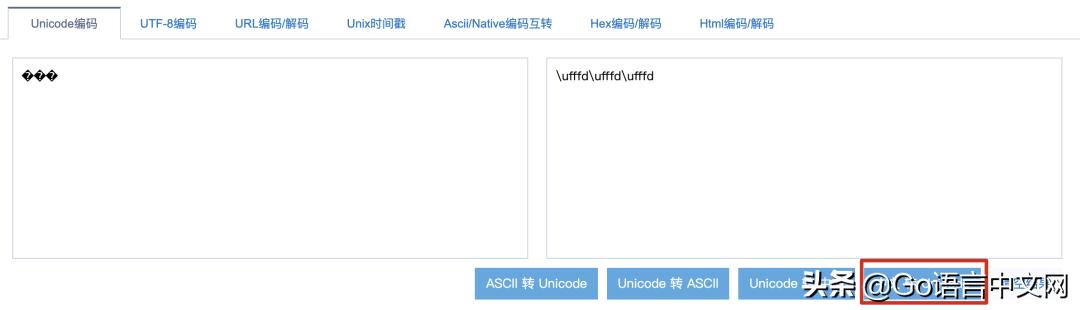
為什么會引發死循環,在調用 utf8.DecodeRuneInString 函數后:
- c == utf8.RuneError
- size == 3
再看 RuneError 的定義:
- const RuneError = '\\uFFFD'
看一下兩個版本的代碼不同之處:
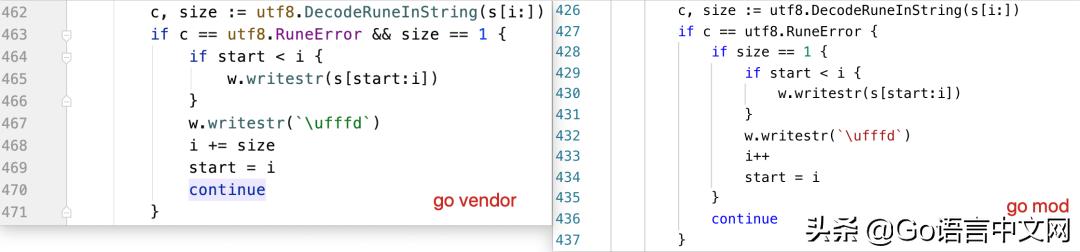
老版本的代碼,不會進入 if 分支,而新版本的代碼,由于 c==utf8.RuneError,所以先進入 if 分支,之后, size==3,不滿足里層分支,直接 continue 了,因此 i 值并沒有發生變化,死循環就這么發生了。
最后就是找到異常數據到底屬于哪個計劃。我嘗試去每個集群的機器上,從數據文件里尋找“孫���雷”。但文件太大了,幾十個 G, grep 搞不定,沒關系,使用 dd 工具:
- dd if=model_20200423155728 bs=1024 skip=3600000 count=1200 | grep '孫���雷'
使用二分法找到了“孫���雷”!關于 dd+grep 的用法,總結了幾點:
- 每次從文件開頭先跳過 skip*bs 大小的內容,復制 count*bs 大小的內容過來用 grep 查詢。
- 如果不設置 count,就會查找整個文件,如果查到,則會有輸出;否則無。
- 對于特別大的文件,可以先把 count 設為跳過一半文件大小的值,采用二分法查找。如果找到,則限定在了前半范圍,否則在后半部分。使用類似的方法繼續查找……
- 如果找到,最后會輸出 count*bs 大小的內容。
反思
- 服務重大版本更新,至少在線下跑一周。
- 有問題,第一時間回滾。
- 對于工具的使用要規范。如不要隨意更改 vendor 文件夾的內容而不同步更新 vendor.json 文件,反之亦然。
- 因為 go mod 的版本選擇以及不遵守開源規范的第三方庫作者會讓使用者不知不覺、被動地引入一些難以發現的問題。可以使用 go mod vendor 代替,如果要鎖死版本的話,使用 replace。