新冠病毒將如何變異?機器學(xué)習(xí)給你答案
本文轉(zhuǎn)載自公眾號“讀芯術(shù)”(ID:AI_Discovery)
病毒和其他微生物一樣,為了在地球上存活,不斷進(jìn)化和變異。這對于人類來說就有點兒可怕了,尤其是新冠病毒肆虐全球的今天,它還想整什么幺蛾子?
事實上,變異已經(jīng)發(fā)生了。先來看一段由人類病毒進(jìn)化而來的蝙蝠病毒的RNA核苷酸序列:
AAAATCAAAGCTTGTGTTGAAGAAGTTACAACAACTCTGGAAGAAACTAAGTT
以及一段新冠病毒的RNA核苷酸序列:
AAAATTAAGGCTTGCATTGATGAGGTTACCACAACACTGGAAGAAACTAAGTT
顯然,新冠病毒為了適應(yīng)新宿主,其原始結(jié)構(gòu)已發(fā)生改變。準(zhǔn)確來說,已經(jīng)有20%的原始結(jié)構(gòu)發(fā)生變異,但因大部分結(jié)構(gòu)并未改變,所以病毒還未發(fā)生變種。
研究者發(fā)現(xiàn)新冠病毒已發(fā)生重復(fù)變異以持續(xù)存活。在與新冠病毒的較量中,我們不僅要知道如何消滅病毒,還要了解病毒如何變異以及怎樣應(yīng)對病毒變異。本文將嘗試用K-Means和PCA探究這一點。
什么是基因組序列?
如果您對RNA核苷酸序列有所了解,那么可直接略過這部分內(nèi)容。
基因組序列,通常我們稱之為“解碼”,是對樣本進(jìn)行DNA分析的重要步驟。一般來說,正常細(xì)胞中有23對攜帶DNA結(jié)構(gòu)的染色體。
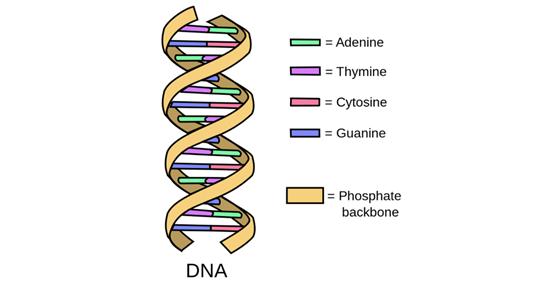
DNA為雙螺旋結(jié)構(gòu),解開后呈梯形,構(gòu)成梯形的是成對出現(xiàn)的堿基。DNA有四種堿基,分別是:腺嘌呤、胸腺嘧啶、鳥嘌呤和胞嘧啶。其中,腺嘌呤只和胸腺嘧啶配對,鳥嘌呤只和胞嘧啶配對。這四種堿基分別用A、T、G、C表示。
這些堿基對通過排列組合可以決定生物體蛋白質(zhì)的具體結(jié)構(gòu),也就是從本質(zhì)上決定病毒如何作用的DNA。
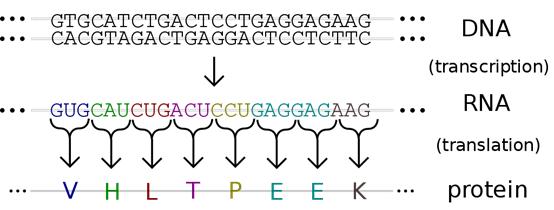
通過使用特殊儀器,比如排序儀器和一些特殊的標(biāo)記法,可以揭開某特殊片段DNA序列的神秘面紗。而由此獲得的信息可以進(jìn)一步地分析和比較,有助于幫助研究者識別基因變化、疾病和表型相關(guān)以及判斷藥物靶標(biāo)。
基因組序列,由A、T、G和C組成的長鏈,是生物體對自然環(huán)境的具體表現(xiàn)。生物體的變異是通過改變DNA來完成的。研究基因組序列是分析病毒變異的有效方式。
了解數(shù)據(jù)
以下數(shù)據(jù)可在 Kaggle找到:
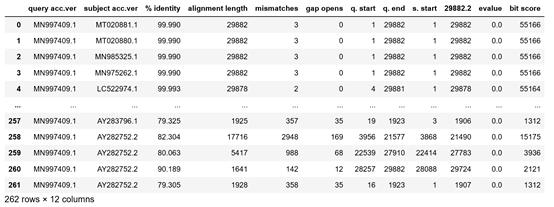
每一行數(shù)據(jù)表示蝙蝠病毒發(fā)生的一次變異。僅僅幾周時間,新冠病毒為提高存活率已經(jīng)發(fā)生了262次變異。
一些重要數(shù)據(jù):
- query acc.ver表示原始病毒的標(biāo)示符。
- Mismatches表示變異病毒和原始病毒的不同項的數(shù)量
- subject acc.ver 表示變異病毒的標(biāo)示符。
- % identity表示原始病毒和變異病毒的相似程度。
- alignment length 表示序列中相同或形近數(shù)目的具體數(shù)量。
- bit score表示形近度,分?jǐn)?shù)越高,形近度越高。
下圖為一些數(shù)據(jù)每列的統(tǒng)計數(shù)值(此數(shù)據(jù)用Python通過data.describe()便可輕松得出):
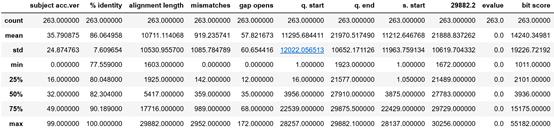
通過觀察 % identity 列的數(shù)據(jù),我們可以發(fā)現(xiàn)一個有趣的現(xiàn)象,每次變異的最小比對值大約為77.6%。對于這列數(shù)據(jù)而言,7%的標(biāo)準(zhǔn)偏差已經(jīng)算相當(dāng)大了,而這么大的標(biāo)準(zhǔn)差也就意味著變異范圍的擴大。bit score的值也表明標(biāo)準(zhǔn)偏差已經(jīng)很大了,竟然比均值還大!
關(guān)聯(lián)熱圖是將數(shù)據(jù)可視化的好方法。每一單元格都表明了各個特性之間的關(guān)聯(lián)。
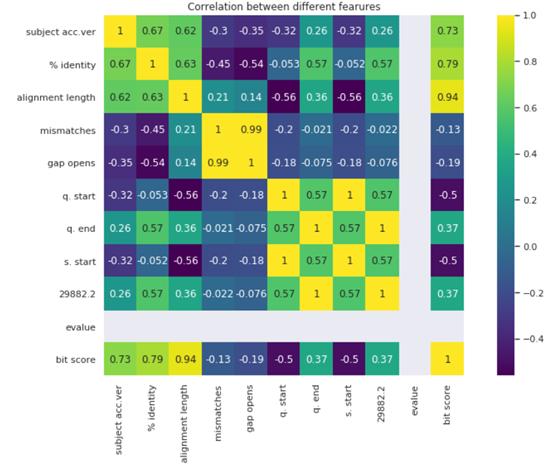
許多數(shù)據(jù)彼此間高度關(guān)聯(lián),因為大多數(shù)數(shù)值的變化是相互影響的。這里需要特別注意的是alignment length 和 bit score的高度關(guān)聯(lián)性。
運用K-Means創(chuàng)造變異集群
K-Means是一種應(yīng)用于機器學(xué)習(xí)的聚類算法,可發(fā)現(xiàn)未來空間內(nèi)的數(shù)據(jù)點群。K-Means的目標(biāo)是發(fā)現(xiàn)變異集群,以此來為病毒本質(zhì)的研究和處理提供依據(jù)。
然而,我們?nèi)匀恍枰x擇集群k的數(shù)量。雖然這和在二維中繪制點一樣簡單,但在高維中是無法實現(xiàn)的(如果我們想保留大部分信息的話)。運用肘部方法選擇k過于主觀、不準(zhǔn)確,所以我們將使用剪影法。
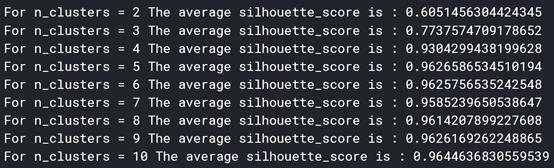
剪影法是k個聚類的分?jǐn)?shù),說明聚類對數(shù)據(jù)的適應(yīng)程度。Python中的sklearn庫令使用K-Means和silouhette方法變得非常簡單。
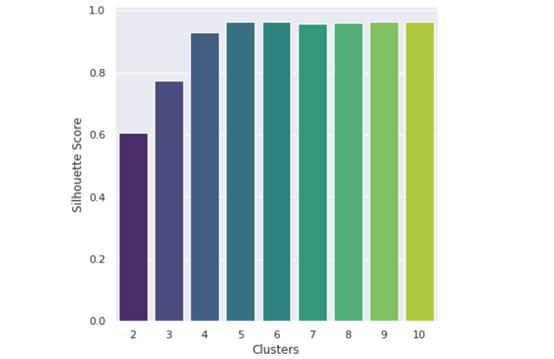
似乎5個集群對數(shù)據(jù)來說是最好的。現(xiàn)在,我們可以確定集群中心了。這些是每個集群圍繞的點,代表了(在本例中)5種主要突變類型的數(shù)值評估。
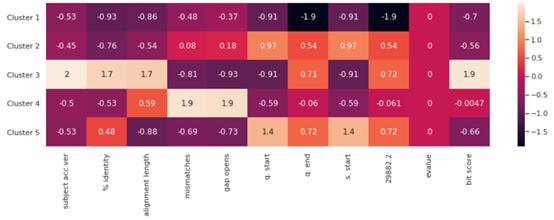
Note: The features have been standardized to put them all on the samescale. Otherwise, columns would not be comparable.
此熱圖中的每列表示每個群集的屬性。因為這些點是按比例縮放的,所以實際的注釋值在數(shù)量上并沒有意義。
但是,可以比較每列中的縮放值。你可以很直觀地感受到每個變異集群的相對屬性。如果科學(xué)家要研發(fā)一種疫苗,則應(yīng)該解決virii的主要病毒群。
下一步是運用PCA將集群可視化。
運用PCA將集群可視化
PCA是一種降維方法,選擇多維空間中的正交向量來表示軸,這樣一來就保留了大部分信息(方差)。
使用流行的Python庫sklearn,可以用兩行代碼實現(xiàn)PCA。首先,我們可以檢查解釋的方差比。這是原始數(shù)據(jù)集中保留的統(tǒng)計信息的百分比。在這種情況下,解釋的方差比是0.9838548580740327,這簡直是天文數(shù)字!
可以確信的是,我們從PCA中得到的任何分析都將是真實的數(shù)據(jù)。
每個新特征(主成分)都是幾個其他列的線性組合。我們可以用熱圖直觀地看到一個列對兩個主要組件中的任何一個都很重要。
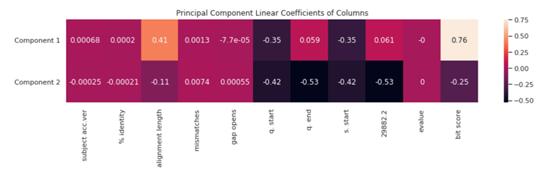
重要的是要理解第一個組件中的高值意味著什么——在這種情況下,其特征是對齊長度較長,也就是更接近原始病毒,而組件2的特征主要是對齊長度較短,也就是突變后更遠(yuǎn)離原始值,這也反映在bit score較大的差異上。
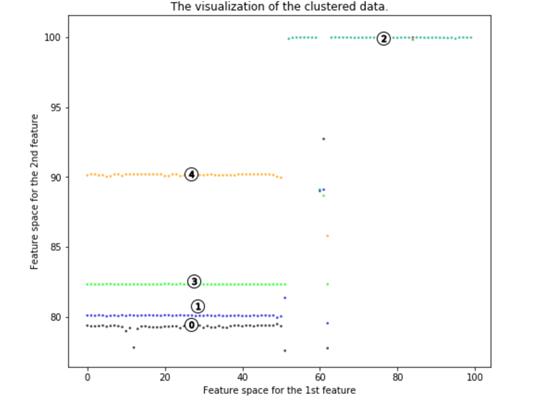
很明顯,病毒突變有5條主線。我們可以從中得到很多信息。
其中有四個病毒突變位于第一主成分的左側(cè),一個位于右側(cè)。第一主成分的特征是高對齊長度。這表示第一主成分的較高值對應(yīng)較高的對齊長度(更接近原始病毒)。
因此,組件1的較低值與原始病毒的基因差距較大。大多數(shù)病毒集群與原始病毒有很大不同。因此,試圖制造疫苗的科學(xué)家應(yīng)該意識到這種病毒會發(fā)生大規(guī)模變異。
通過使用K-Means和PCA,我們可以識別出五種主要的新冠病毒變異集群,研制疫苗的科學(xué)家可以運用這些集群中心獲得的每種集群特征。通過PCA,我們可以在兩個維度上看到這些集群中心,并且發(fā)現(xiàn)冠狀病毒具有非常高的突變率。
這可能就是新冠病毒如此致命的原因。