













誰說RL智能體只能在線訓練?谷歌發(fā)布離線強化學習新范式
為了避免 distribution mismatch,強化學習的訓練一定要在線與環(huán)境進行交互嗎?谷歌的這項最新研究從優(yōu)化角度,為我們提供了離線強化學習研究新思路,即魯棒的 RL 算法在足夠大且多樣化的離線數(shù)據(jù)集中訓練可產生高質量的行為。該論文的訓練數(shù)據(jù)集與代碼均已開源。機器之心友情提示,訓練數(shù)據(jù)集共包含 60 個雅達利游戲環(huán)境,谷歌宣稱其大小約為 ImageNet 的 60 x 3.5 倍。
「異策略學習的潛力依然很誘人,但實現(xiàn)它的最佳方式依然是個謎。」—Sutton & Barto(兩人為《強化學習導論》一書的作者)
多數(shù)強化學習算法都假設一個智能體主動與在線環(huán)境交互,從它自己搜集的經驗中學習。這些算法在現(xiàn)實問題中的應用困難重重,因為從現(xiàn)實世界中進一步搜集的數(shù)據(jù)可能樣本效率極低,還會帶來意想不到的行為。而那些在仿真環(huán)境中運行的算法需要高保真模擬器,因此構建起來非常困難。然而,對于許多現(xiàn)實世界中的強化學習應用來說,之前已經搜集了很多交互數(shù)據(jù),可以用于訓練在上述現(xiàn)實問題中可行的強化學習智能體,同時通過結合之前的豐富經驗來提高泛化性能。
現(xiàn)有的交互數(shù)據(jù)可以實現(xiàn)離線強化學習的有效訓練,后者是完全的異策略(off-policy)強化學習設置,智能體從一個固定的數(shù)據(jù)集中學習,不與環(huán)境進行交互。
離線強化學習有助于:
1)使用現(xiàn)有數(shù)據(jù)預訓練一個強化學習智能體;
2)基于強化學習算法利用固定交互數(shù)據(jù)集的能力對他們進行實驗評估;
3)對現(xiàn)實世界的問題產生影響。然而,由于在線交互與固定數(shù)據(jù)集中的交互數(shù)據(jù)分布不匹配,離線強化學習面臨很大的挑戰(zhàn)。即,如果一個經過訓練的智能體采取了與數(shù)據(jù)收集智能體不同的行動,我們不知道提供什么樣的獎勵。
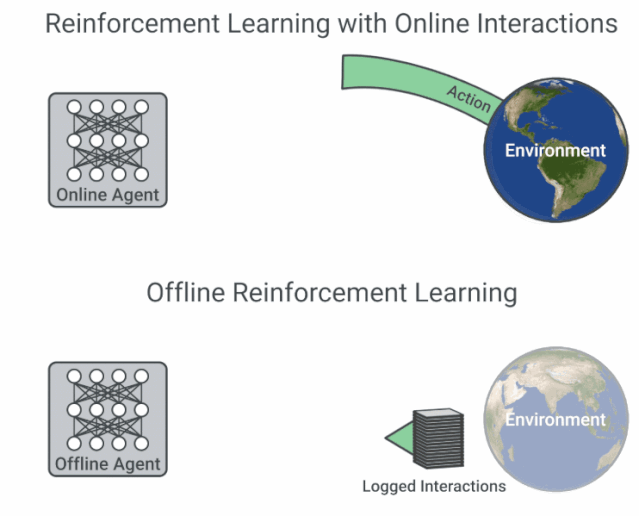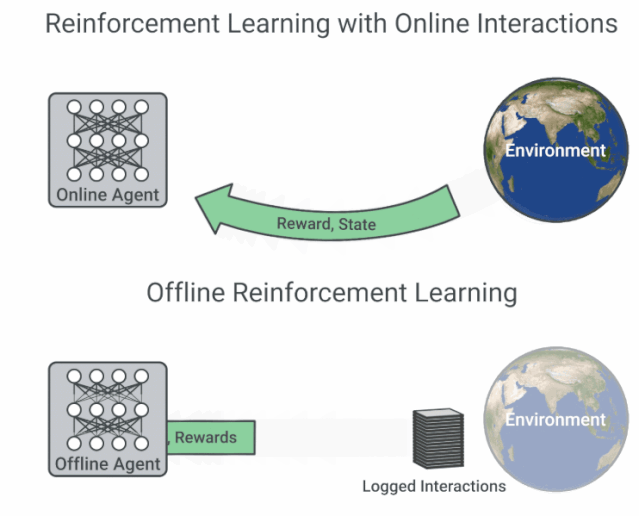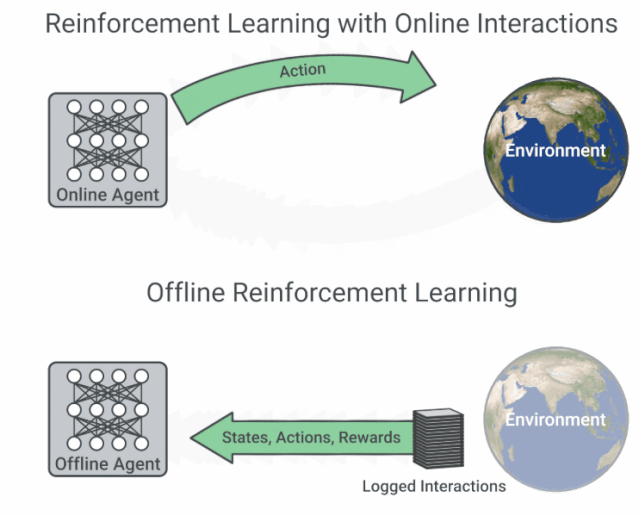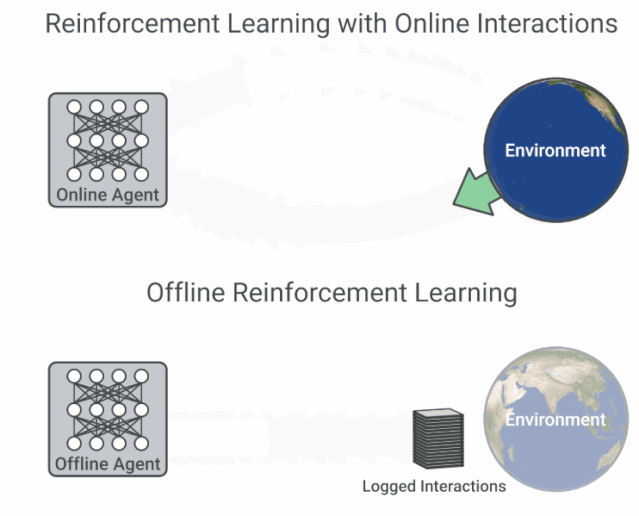
具有在線交互的 RL 與離線 RL 的流程圖比較。
在這篇名為「An Optimistic Perspective on Offline Reinforcement Learning」的論文中,根據(jù) DQN 智能體記錄下的經驗,谷歌大腦團隊的研究者提出了一種在 Atari 2600 游戲中進行離線強化學習的簡單實驗設置。他們展示了不通過對任何錯配分布的顯式修正,仍然可能訓練出性能超越使用標準異策略 RL 算法收集數(shù)據(jù)的智能體。同時,研究者還提出了一種魯棒的 RL 算法,在離線 RL 中表現(xiàn)出可觀的結果,稱作隨機混合集成(random ensemble mixture,REM)。
總的來說,研究者提出一種全新的優(yōu)化角度,即魯棒的 RL 算法在足夠大且多樣化的離線數(shù)據(jù)集中訓練可產生高質量的行為,鞏固了新興的數(shù)據(jù)驅動 RL 范式。為促進離線 RL 方法的開發(fā)與評估,研究者公開了他們的 DQN 回溯數(shù)據(jù)集并開源了論文的代碼。
- 論文鏈接:https://arxiv.org/pdf/1907.04543.pdf
- 項目地址:https://github.com/google-research/batch_rl
異策略與離線強化學習基礎
不同 RL 算法匯總如下:

在線的異策略 RL 智能體(如 DQN),僅通過接收來自游戲屏幕的圖像信息,不需要其他任何關于此游戲的知識,在 Atari 2600 游戲中取得了與人類玩家同等的表現(xiàn)。在一個給定的環(huán)境狀態(tài)下,DQN 根據(jù)如何最大化未來獎勵(如 Q-values),對動作的有效性進行估計。
此外,當前使用價值函數(shù)分布的 RL 算法(如 QR-DQN)對所有可能的未來獎勵的分布進行估計,而不是為每個狀態(tài)-動作對估計單一的期望價值。DQN 與 QR-DQN 這樣的智能體被看作是「在線」的算法,這是因為它們在優(yōu)化策略與使用優(yōu)化后的策略去收集更多數(shù)據(jù)之間不斷交替迭代。
理論上異策略的 RL 智能體可以從任意策略收集的數(shù)據(jù)中進行學習,而不僅限于被優(yōu)化的那個策略。然而,最近的研究工作顯示,標準的異策略智能體在離線 RL 設定下將會發(fā)散或性能表現(xiàn)較差。為解決以上問題,之前的研究提出了一種正則化學習到的策略的方法,來使其策略更新在離線交互數(shù)據(jù)集附近。
為離線 RL 設計的 DQN 回溯數(shù)據(jù)集
研究者首先建立了 DQN 回溯數(shù)據(jù)集來重新審視離線 RL。該數(shù)據(jù)集使用 DQN 智能體在 60 個 Atari 2600 游戲中各訓練兩億步得到,并使用了粘滯動作(sticky action)來使問題更具挑戰(zhàn)性,即有 25% 的概率執(zhí)行智能體之前的動作,而不是當前的動作。
在這 60 個游戲中,對于每一個游戲,研究者訓練 5 個具有不同初始化參數(shù)的 DQN 智能體,并將訓練中產生的所有 (state, action, reward, next state) 元組儲存在 5 個回溯數(shù)據(jù)集中,總共產生 300 個數(shù)據(jù)集。
這個 DQN 回溯數(shù)據(jù)集之后被用于訓練離線 RL 智能體,訓練過程中并不需要任何與環(huán)境的交互。每一個游戲回溯數(shù)據(jù)集大約是 ImageNet 的 3.5 倍,包含在優(yōu)化在線 DQN 時中間策略產生的所有樣本。

在 Atari 游戲中使用 DQN 回溯數(shù)據(jù)集的離線 RL。
在 DQN 回溯數(shù)據(jù)集上訓練離線智能體
研究者在 DQN 回溯數(shù)據(jù)集上對 DQN 和值函數(shù)分布 QR-DQN 的變體進行訓練。盡管離線數(shù)據(jù)集包含了 DQN 智能體經歷過的數(shù)據(jù),并且這些數(shù)據(jù)會隨著訓練進程的推移而相應地改善,研究者對離線智能體和訓練后得到的 best-performing 在線 DQN 智能體(即完全訓練好的 DQN)的性能進行了比較。對于每一次游戲,他們使用在線 returns 對訓練的 5 個離線智能體展開了評估,并得出了最佳的平均性能。
除了在少數(shù)游戲中相同數(shù)據(jù)量下得分高于完全訓練(fully-trained)的在線 DQN 之外,離線 DQN 的表現(xiàn)均弱于后者。另一方面,離線 QR-DQN 在大多數(shù) game 中的表現(xiàn)優(yōu)于離線 DQN 和完全訓練的 DQN。這些結果表明,利用標準深度 RL 算法來優(yōu)化強大的離線智能體是可能實現(xiàn)的。并且,離線 QR-DQN 和 DQN 的表現(xiàn)差距表明它們利用離線數(shù)據(jù)的能力也存在著差異。
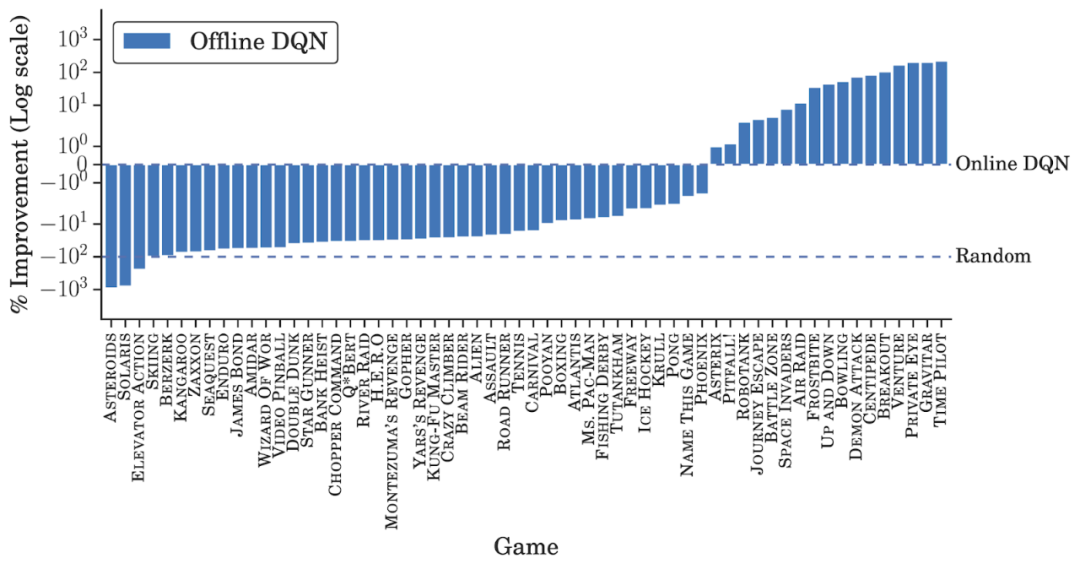
離線 DQN 結果。
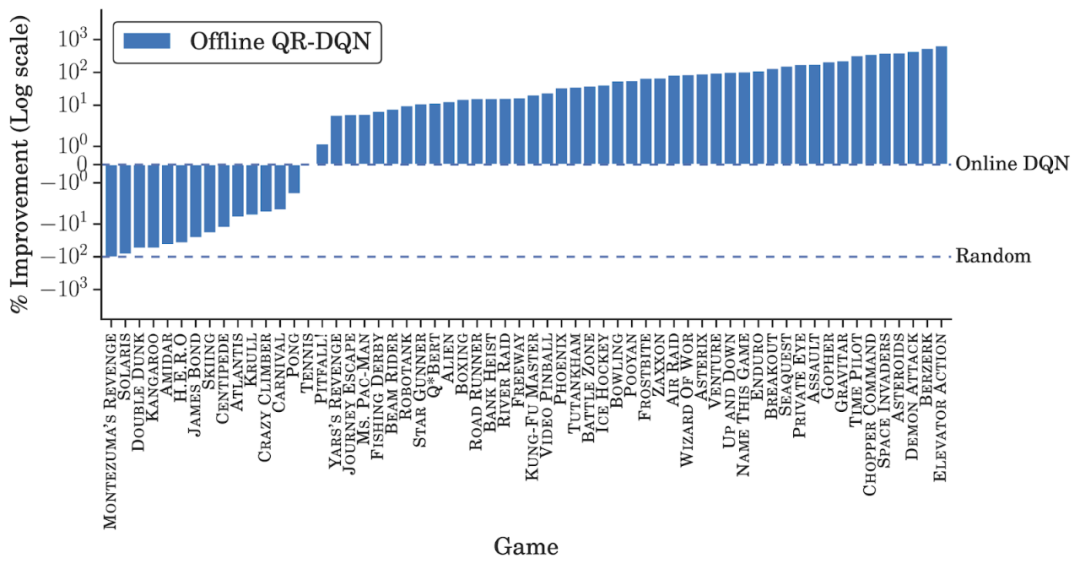
離線 QR-DQN 結果。
兩種魯棒的離線 RL 智能體
在在線 RL 中,一個智能體選擇它認為會帶來高獎勵(high reward)的動作,然后會接收糾錯性反饋(corrective feedback)。此外,由于在離線 RL 中無法收集額外數(shù)據(jù)(additional data),所以有必要使用一個固定的數(shù)據(jù)集來推理出泛化能力。借助于使用模型集成來提升泛化能力的監(jiān)督學習方法,研究者提出了以下兩個新的離線 RL 智能體:
- 集成 DQN 是 DQN 的一個簡單擴展,它訓練多個 Q 值估計并取平均值來進行評估;
- 隨機集成混合(Random Ensemble Mixture,REM)是一個易于實現(xiàn)的 DQN 擴展,它受到了 Dropout 的啟發(fā)。REM 的核心理念是,如果可以得到 Q 值的多個估計,則 Q 值估計的加權組合(weighted combination)也成為 Q 值的一個估計。因此,REM 在每次迭代中隨機組合多個 Q 值估計,并將這種隨機組合用于魯棒訓練。
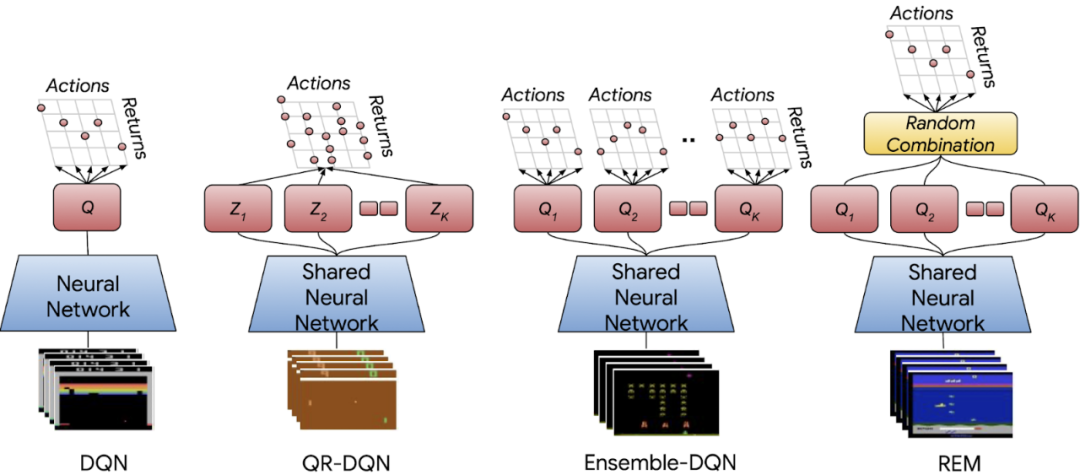
DQN、值函數(shù)分布 QR-DQN、具有相同多頭機制 QR-DQN 架構的期望 RL 變體、集成 DQN 和 REM 的神經網絡架構。
為了更高效地利用 DQN 回溯數(shù)據(jù)集,研究者在訓練離線智能體時將訓練迭代次數(shù)設置為在線 DQN 訓練的 5 倍,性能表現(xiàn)如下圖所示。離線 REM 要優(yōu)于離線 DQN 和離線 QR-DQN。并且,與一個強大的值函數(shù)分布智能體,即完全訓練的在線 C51 的性能比較表明,從離線 REM 獲得的增益要高于 C51。
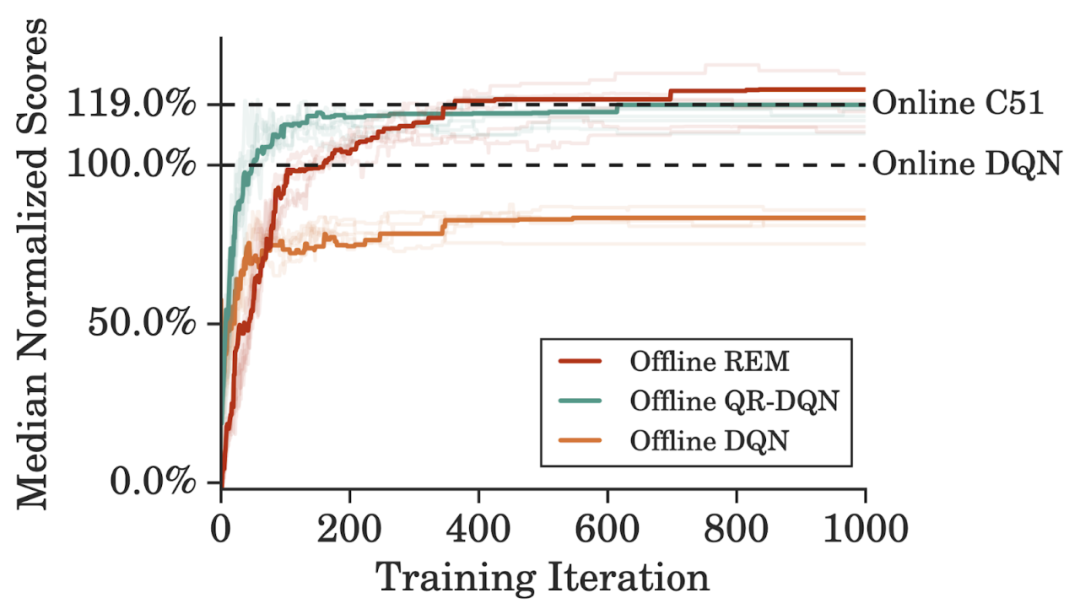
離線 REM 與基線方法的性能比較。
在 Atari 游戲中使用標準訓練方案時,在線 REM 在標準在線 RL 設置下的性能能夠與 QR-DQN 媲美。這表明我們可以利用從 DQN 回溯數(shù)據(jù)集和離線 RL 設置中獲得的 insight 來構建有效的在線 RL 方法。
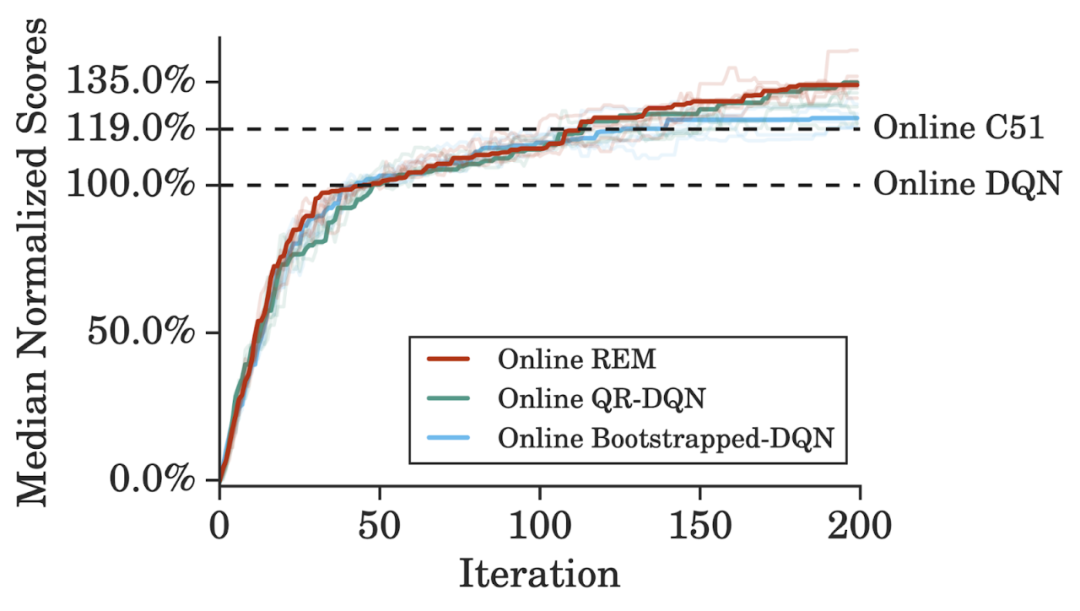
在線 REM 與基線方法的性能比較。
結果對比:離線強化學習中的重要因素
為什么之前的標準強化學習智能體在離線設置下屢屢失敗?谷歌研究者總結了他們的研究與之前研究的幾個重要差異:
- 離線數(shù)據(jù)集大小。谷歌訓練離線 QR-DQN 和 REM 所用的數(shù)據(jù)集是通過隨機下采樣整個 DQN 回溯數(shù)據(jù)集得到的簡化數(shù)據(jù),同時保持了相同的數(shù)據(jù)分布。與監(jiān)督學習類似,模型性能隨著數(shù)據(jù)集大小的增加而提升。REM 和 QR-DQN 只用整個數(shù)據(jù)集的 10% 就達到了與完全的 DQN 接近的性能;
- 離線數(shù)據(jù)集的組成。研究者在 DQN 回溯數(shù)據(jù)集每個游戲的前 2000 萬幀上訓練了離線強化學習智能體。離線 REM 和 QR-DQN 在這個低質量數(shù)據(jù)集上的表現(xiàn)優(yōu)于最佳策略(best policy),這表明如果數(shù)據(jù)集足夠多樣,標準強化學習智能體也能在離線設置下表現(xiàn)良好;
- 離線算法的選擇。有人認為,在離線狀態(tài)下訓練時,標準異策略智能體在連續(xù)控制任務中會表現(xiàn)不佳。然而,谷歌研究者發(fā)現(xiàn),最近的連續(xù)控制智能體(如 TD3)在大型、多樣化離線數(shù)據(jù)集上訓練時,其性能與復雜離線智能體相當。
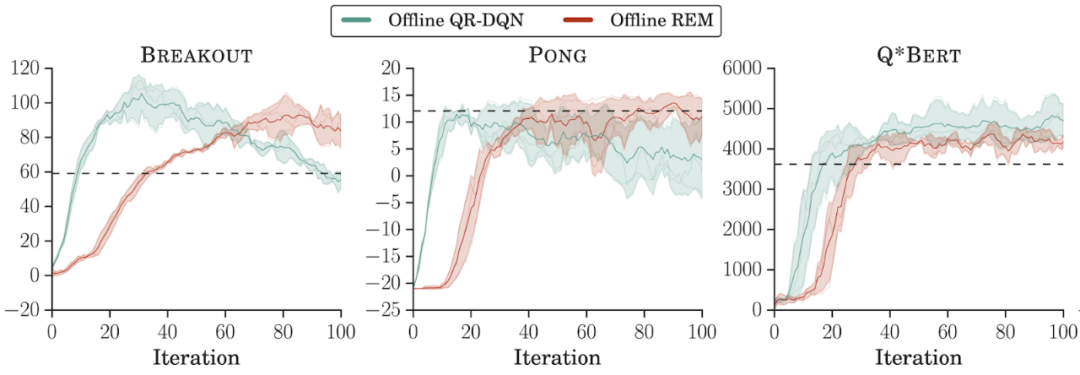
用較低質量數(shù)據(jù)集在離線設置下訓練強化學習智能體。
展望
谷歌的這項研究表明,在從大量不同策略的離線數(shù)據(jù)中學習時,需要對神經網絡泛化的作用進行嚴格描述。另一個重要的方向是通過對 DQN 回溯數(shù)據(jù)集進行下采樣,利用各種數(shù)據(jù)收集策略對離線 RL 進行基準測試。
谷歌研究者目前采用的是在線策略評估,然而「真正的」離線 RL 需要離線策略評估來進行超參數(shù)調優(yōu)和早停。最后,基于模型的 RL 和自監(jiān)督學習方法也有望用于離線 RL。


























