清華本科生開發(fā)強(qiáng)化學(xué)習(xí)平臺「天授」:千行代碼實(shí)現(xiàn),剛剛開源
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
江山代有才人出,開源一波更比一波強(qiáng)。
就在最近,一個(gè)簡潔、輕巧、快速的深度強(qiáng)化學(xué)習(xí)平臺,完全基于Pytorch,在Github上開源。
如果你也是強(qiáng)化學(xué)習(xí)方面的同仁,走過路過不要錯(cuò)過。
而且作者,還是一枚清華大學(xué)的本科生——翁家翌,他獨(dú)立開發(fā)了”天授(Tianshou)“平臺。
沒錯(cuò),名字就叫“天授”。
Why 天授?
主要有四大優(yōu)點(diǎn):
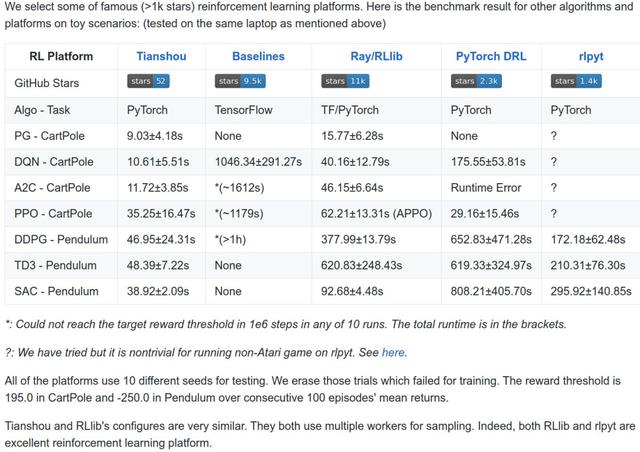
1、速度快,整個(gè)平臺只用1500行左右代碼實(shí)現(xiàn),在已有的toy scenarios上面完勝所有其他平臺,比如3秒訓(xùn)練一個(gè)倒立擺(CartPole)。
2、模塊化,把所有policy都拆成4個(gè)模塊:
init:策略初始化。process_fn:處理函數(shù),從回放緩存中處理數(shù)據(jù)。call:根據(jù)觀測值計(jì)算操作learn:從給定數(shù)據(jù)包中學(xué)習(xí)
只要完善了這些給定的接口就能在100行之內(nèi)完整實(shí)現(xiàn)一個(gè)強(qiáng)化學(xué)習(xí)算法。
3、天授平臺目前支持的算法有:
Policy Gradient (PG)
Deep Q-Network (DQN)
Double DQN (DDQN) with n-step returns
Advantage Actor-Critic (A2C)
Deep Deterministic Policy Gradient (DDPG)
Proximal Policy Optimization (PPO)
Twin Delayed DDPG (TD3)
Soft Actor-Critic (SAC)
隨著項(xiàng)目的開發(fā),會有更多的強(qiáng)化學(xué)習(xí)算法加入天授。
4、接口靈活:用戶可以定制各種各樣的訓(xùn)練方法,只用少量代碼就能實(shí)現(xiàn)。
如何使用天授
以DQN(Deep-Q-Network)算法為例,我們在天授平臺上使用CartPole小游戲,對它的agent進(jìn)行訓(xùn)練。
配置環(huán)境
習(xí)慣上使用OpenAI Gym,如果使用Python代碼,只需要簡單的調(diào)用Tianshou即可。
CartPole-v0是一個(gè)可應(yīng)用DQN算法的簡單環(huán)境,它擁有離散操作空間。配置環(huán)境時(shí),你需要注意它的操作空間是連續(xù)還是離散的,以此選擇適用的算法。
設(shè)置多環(huán)境層
你可以使用現(xiàn)成的gym.Env:

也可以選擇天授提供的三種向量環(huán)境層:VectorEnv、SubprocVectorEnv和RayVectorEnv,如下所示:

示例中分別設(shè)置了8層和100層環(huán)境。
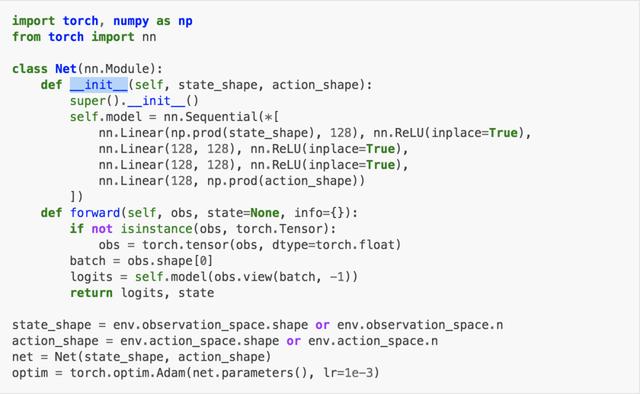
建立網(wǎng)絡(luò)
天授支持任意用戶自主定義的網(wǎng)絡(luò)或優(yōu)化器,但有接口限制。

以下是一個(gè)正確的示例:
設(shè)置策略
我們使用已定義的net和optim(有額外的策略超參數(shù))來定義一個(gè)策略。下方我們用一個(gè)目標(biāo)網(wǎng)絡(luò)來定義DQN算法策略。

設(shè)置收集器
收集器是天授的關(guān)鍵概念,它使得策略能夠高效的與不同環(huán)境交互。每一步,收集器都會將該策略的操作數(shù)據(jù)記錄在一個(gè)回放緩存中。

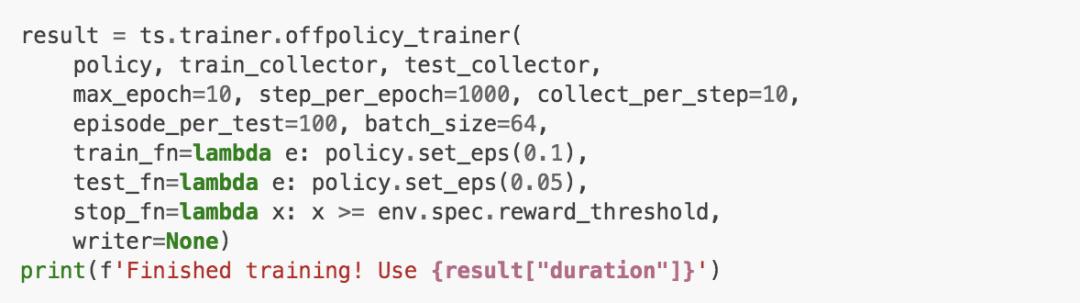
訓(xùn)練
天授提供了訓(xùn)練函數(shù)onpolicy_trainer和offpolicy_trainer。當(dāng)策略達(dá)到終止條件時(shí),他們會自動停止訓(xùn)練。由于DQN是無策略算法,我們使用offpolicy_trainer。
訓(xùn)練器支持TensorBoard記錄,方法如下:

將參數(shù)writer輸入訓(xùn)練器中,訓(xùn)練結(jié)果會被記錄在TensorBoard中。

記錄顯示,我們在幾乎4秒的時(shí)間內(nèi)完成了對DQN的訓(xùn)練。
保存/加載策略
因?yàn)槲覀兊牟呗匝匾u自torch.nn.Module,所以保存/加載策略方法與torch模塊相同。

觀察模型表現(xiàn)
收集器支持呈現(xiàn)功能,以35幀率觀察模型方法如下:

用你自己的代碼訓(xùn)練策略
如果你不想用天授提供的訓(xùn)練器也沒問題,以下是使用自定義訓(xùn)練器的方法。

上手體驗(yàn)
天授需要Python3環(huán)境。以CartPole訓(xùn)練DQN模型為例,輸入test_dqn.py代碼進(jìn)行訓(xùn)練,其結(jié)果統(tǒng)計(jì)如下:

可以看出整個(gè)訓(xùn)練過程用時(shí)7.36秒,與開發(fā)者給出的訓(xùn)練時(shí)間符合。
模型訓(xùn)練結(jié)果如下:
作者介紹
天授的開發(fā)者:翁家翌,清華大學(xué)的在讀大四本科生。
高中畢業(yè)于福州一中,前NOI選手。
大二時(shí)作就作為團(tuán)隊(duì)主要貢獻(xiàn)者獲得了強(qiáng)化學(xué)習(xí)國際比賽vizdoom的冠軍。他希望能將天授平臺深入開發(fā),成為強(qiáng)化學(xué)習(xí)平臺的標(biāo)桿。開源也是希望有更多的小伙伴加入這個(gè)項(xiàng)目。
傳送門:
PyPI提供天授平臺下載,你也可以在Github上找到天授的最新版本和其他資料。
PYPI:
https://pypi.org/project/tianshou/
Github天授主頁:
https://github.com/thu-ml/tianshou