一套 SQL 搞定數據倉庫?Flink有了新嘗試
數據倉庫是公司數據發展到一定規模后必然需要提供的一種基礎服務,也是“數據智能”建設的基礎環節。迅速獲取數據反饋不僅有利于改善產品及用戶體驗,更有利于公司的科學決策,因此獲取數據的實時性尤為重要。目前企業的數倉建設大多是離線一套,實時一套。業務要求低延時的使用實時數倉;業務復雜的使用離線數倉。架構十分復雜,需要使用很多系統和計算框架,這就要求企業儲備多方面的人才,導致人才成本較高,且出了問題難以排查,終端用戶也需要熟悉多種語法。本文分析目前的數倉架構,探索離線和實時數倉是否能放在一起考慮,探索Flink的統一架構是否能解決大部分問題。
數倉架構
?? 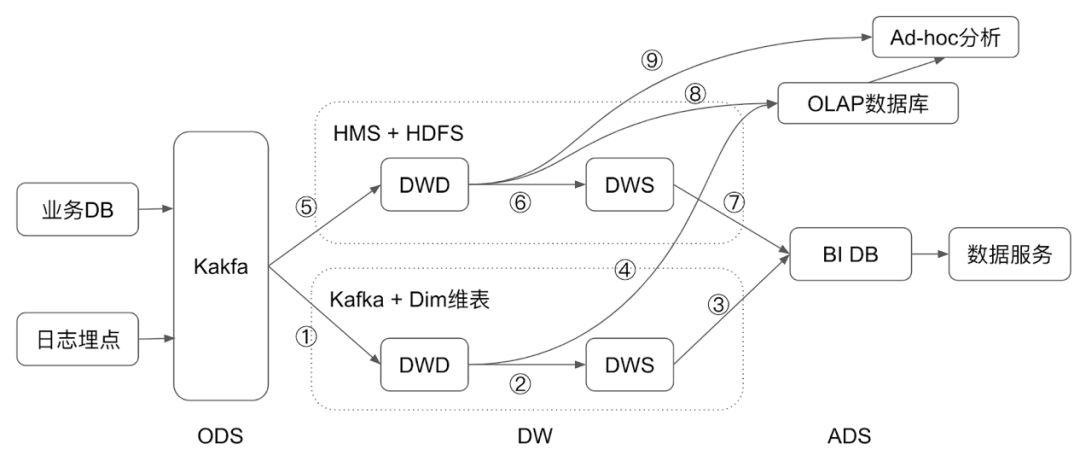
數據倉庫可以分為三層:ODS(原始數據層)、DW(數據倉庫層)、ADS(應用數據層)。
1. ODS (Operation Data Store) 層
從日志或者業務DB傳輸過來的原始數據,傳統的離線數倉做法也有直接用CDC (Change Data Capture) 工具周期同步到數倉里面。用一套統一的Kafka來承接這個角色,可以讓數據更實時的落入數倉,也可以在這一層統一實時和離線的。
2. DW (Data warehouse) 層
DW層一般也分為DWD層和DWS層:
- DWD (Data warehouse detail) 層:明細數據層,這一層的數據應該是經過清洗的,干凈的、準確的數據,它包含的信息和ODS層相同,但是它遵循數倉和數據庫的標準Schema定義。
- DWS (Data warehouse service) 層:匯總數據層,這一層可能經過了輕度的聚合,可能是星型或雪花模型的結構數據,這一層已經做了一些業務層的計算,用戶可以基于這一層,計算出數據服務所需數據。
3. ADS (Application Data Store) 層
和DWS不同的是,這一層直接面向用戶的數據服務,不需要再次計算,已經是最終需要的數據。
主要分為兩條鏈路:
- 業務DB和日志 -> Kafka -> 實時數倉 (Kafka + Dim維表) -> BI DB -> 數據服務
- 業務DB和日志 -> Kafka -> 離線數倉 (Hive metastore + HDFS) -> BI DB -> 數據服務
主流的數倉架構仍然是Lambda架構,Lambda架構雖然復雜,但是它能覆蓋業務上需要的場景,對業務來說,是最靈活的方式。
Lambda架構分為兩條鏈路:
- 傳統離線數據具有穩定、計算復雜、靈活的優點,運行批計算,保證T+1的報表產生和靈活的Ad-hoc查詢。
- 實時數倉提供低延時的數據服務,傳統的離線數倉往往都是T+1的延時,這導致分析人員沒法做一些實時化的決策,而實時數倉整條鏈路的延遲最低甚至可以做到秒級,這不但加快了分析和決策,而且也給更多的業務帶來了可能,比如實時化的監控報警。Flink的強項是實時計算、流計算,而Kafka是實時數倉存儲的核心。
上圖標出了1-9條邊,每條邊代表數據的轉換,就是大數據的計算,本文后續將分析這些邊,探索Flink在其中可以發揮的作用。
Flink一棧式計算
元數據
先說下元數據的管理,離線數倉有Hive metastore來管理元數據,但是單純的Kafka不具備元數據管理的能力,這里推薦兩種做法:
1. Confluent schema registry
搭建起schema registry服務后,通過confluent的url即可獲取到表的schema信息,對于上百個字段的表,它可以省編寫Flink作業時的很多事,后續Flink也正在把它的schema推斷功能結合Confluent schema registry。但是它仍然省不掉創建表的過程,用戶也需要填寫Confluent對應的URL。
2. Catalog
目前Flink內置已提供了HiveCatalog,Kafka的表可以直接集成到Hive metastore中,用戶在SQL中可以直接使用這些表。但是Kafka的start-offset一些場景需要靈活的配置,為此,Flink也正在提供 LIKE [1] 和 Table Hints [2] 等手段來解決。
Flink中離線數倉和實時數倉都使用Hive Catalog:
使用Catalog,后續的計算可以完全復用批和流,提供相同的體驗。
數倉導入
計算①和⑤分別是實時數倉的導入和離線數倉的導入,近來,更加實時的離線數倉導入越來越成為數據倉庫的常規做法,Flink的導入可以讓離線數倉的數據更實時化。
以前主要通過DataStream + StreamingFileSink的方式進行導入,但是不支持ORC和無法更新HMS。
Flink streaming integrate Hive后,提供Hive的streaming sink [3],用SQL的方式會更方便靈活,使用SQL的內置函數和UDF,而且流和批可以復用,運行兩個流計算作業。
數據處理
計算②和⑥分別是實時數倉和離線數倉的中間數據處理,這里面主要有三種計算:
- ETL:和數據導入一樣,批流沒有區別。
- 維表Join:維表補字段是很常見的數倉操作,離線數倉中基本都是直接Join Hive表即可,但是Streaming作業卻有些不同,下文將詳細描述。
- Aggregation:Streaming作業在這些有狀態的計算中,產生的不是一次確定的值,而可能是不斷變化的值。
維表Join
與離線計算不同,離線計算只用關心某個時間點的維表數據,而Streaming的作業持續運行,所以它關注的不能只是靜態數據,需要是動態的維表。
另外為了Join的效率,streaming作業往往是join一個數據庫表,而不僅僅是Hive表。
例子:
這里有個非常麻煩的事情,那就是在實時數倉中,需要按時周期調度更新維表到實時維表數據庫中,那能不能直接Join離線數倉的Hive維表呢?目前社區也正在開發Hive維表,它有哪些挑戰:
Hive維表太大,放不進Cache中:
- 考慮Shuffle by key,分布式的維表Join,減少單并發Cache的數據量
- 考慮將維表數據放入State中
維表更新問題:
- 簡單的方案是TTL過期
- 復雜一些的方案是實現Hive streaming source,并結合Flink的watermark機制
有狀態計算和數據導出
例子:
一句簡單的聚合SQL,它在批計算和流計算的執行模式是完全不同的。
Streaming的聚合和離線計算的聚合最大的不同在于它是一個動態表[4],它的輸出是在持續變化的。動態表的概念簡單來說,一個streaming的count,它的輸出是由輸入來驅動的,而不是像batch一樣,獲取全部輸入后才會輸出,所以,它的結果是動態變化的:
- 如果在SQL內部,Flink內部的retract機制會保證SQL 的結果的與批一樣。
- 如果是外部的存儲,這給sink帶來了挑戰。
有狀態計算后的輸出:
- 如果sink是一個可更新的數據庫,比如HBase/Redis/JDBC,那這看起來不是問題,我們只需要不斷的去更新就好了。
- 但是如果是不可更新的存儲呢,我們沒有辦法去更新原本的數據。為此,Flink提出了Changelog的支持[5],想內置支持這種sink,輸出特定Schema的數據,讓下游消費者也能很好的work起來。
例子:
-- batch:計算完成后,一次性輸出到mysql中,同key只有一個數據-- streaming:mysql里面的數據不斷更新,不斷變化insert into mysql_table select age, avg(amount) from order_with_user_age group by age;-- batch: 同key只有一個數據,append即可insert into hive_table select age, avg(amount) from order_with_user_age group by age;-- streaming: kafka里面的數據不斷append,并且多出一列,來表示這是upsert的消息,后續的Flink消費會自動做出機制來處理upsertinsert into kafka_table select age, avg(amount) from order_with_user_age group by age;
AD-HOC與OLAP
離線數倉可以進行計算⑨,對明細數據或者匯總數據都可以進行ad-hoc的查詢,可以讓數據分析師進行靈活的查詢。
目前實時數倉一個比較大的缺點是不能Ad-hoc查詢,因為它本身沒有保存歷史數據,Kafka可能可以保存3天以上的數據,但是一是存儲成本高、二是查詢效率也不好。
一個思路是提供OLAP數據庫的批流統一Sink組件:
- Druid sink
- Doris sink
- Clickhouse sink
- HBase/Phoenix sink
總結
本文從目前的Lambda架構出發,分析了Flink一棧式數倉計算方案的能力,本文中一些Flink新功能還在快速迭代演進中,隨著不斷的探索和實踐,希望朝著計算一體化的方向逐漸推進,將來的數倉架構希望能真正統一用戶的離線和實時,提供統一的體驗:
- 統一元數據
- 統一SQL開發
- 統一數據導入與導出
- 將來考慮統一存儲
參考
[1]https://cwiki.apache.org/confluence/display/FLINK/FLIP-110%3A+Support+LIKE+clause+in+CREATE+TABLE
[2]https://cwiki.apache.org/confluence/display/FLINK/FLIP-113%3A+Supports+Table+Hints
[3]https://cwiki.apache.org/confluence/display/FLINK/FLIP-115%3A+Filesystem+connector+in+Table
[4]https://ci.apache.org/projects/flink/flink-docs-master/dev/table/streaming/dynamic_tables.html
[5]https://cwiki.apache.org/confluence/display/FLINK/FLIP-105%3A+Support+to+Interpret+and+Emit+Changelog+in+Flink+SQL