在生產(chǎn)環(huán)境運(yùn)行Elasticsearch深度指南
在本文,我不是來告訴你 Elasticsearch 強(qiáng)大,快速并且?guī)缀蹩梢哉_\(yùn)行。
在本文,我也是來告訴你 Elasticsearch 可能是不透明的,讓人困擾,并且似乎無緣無故地出問題。在這篇
在本文,我想分享我的經(jīng)驗(yàn)和技巧,了解如何正確配置 Elasticsearch 并避免常見的陷阱。
我寫文章目的也不是為了贏利,所以我會(huì)將全部內(nèi)容放到這一篇文章中,而不是將它分解成一系列。你可以隨意跳過不感興趣的章節(jié)。
基礎(chǔ)知識(shí):集群,節(jié)點(diǎn),索引和分片
如果你是 Elasticsearch(ES)新手,我想先解釋一些基本概念。本節(jié)完全不涉及最佳實(shí)踐,主要側(cè)重于解釋術(shù)語。大多數(shù)人可以直接跳過本節(jié)。
Elasticsearch 是用于運(yùn)行 Apache Lucene(基于 Java 的搜索引擎)分布式管理框架。Lucene 是實(shí)際保存數(shù)據(jù)并進(jìn)行索引和搜索的地方。ES 位于它之上,讓你可以并行運(yùn)行數(shù)千個(gè) Lucene 實(shí)例。
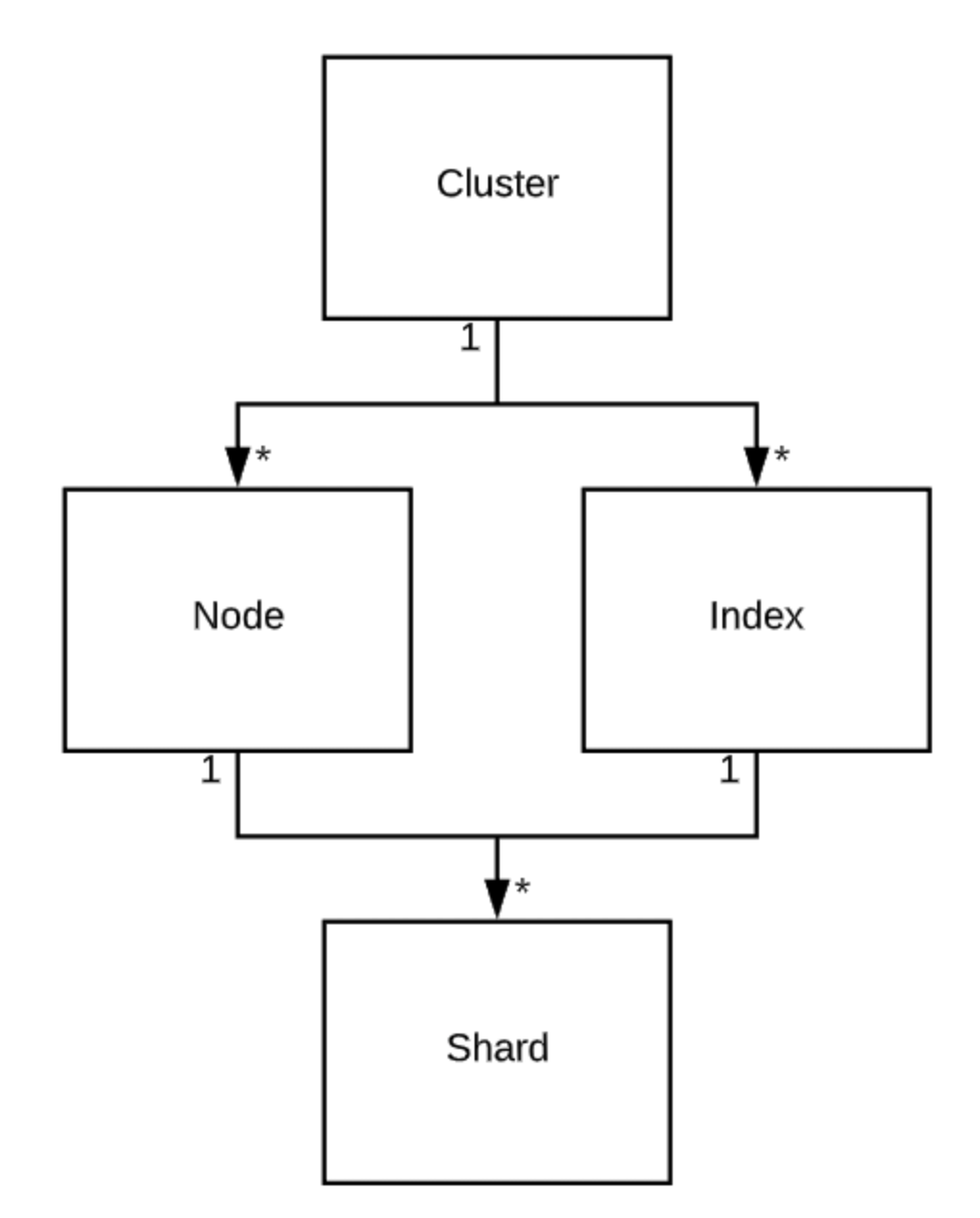
ES 的最高級(jí)別單元是集群(cluster)。集群是 ES 節(jié)點(diǎn) 和索引的集合。
節(jié)點(diǎn) (Node) 是 ES 的實(shí)例。它可以是單個(gè)服務(wù)器,也可以是服務(wù)器上運(yùn)行的 一個(gè) ES 進(jìn)程。服務(wù)器和節(jié)點(diǎn)不同,一個(gè) VM 或物理服務(wù)器可以包含許多 ES 進(jìn)程,每個(gè) ES 進(jìn)程是一個(gè)節(jié)點(diǎn)。節(jié)點(diǎn)只可以加入一個(gè)集群。節(jié)點(diǎn)有不同類型(type),其中最值得關(guān)注的兩個(gè)類型是數(shù)據(jù)節(jié)點(diǎn)(data node)和主候選節(jié)點(diǎn)( Master-Eligible node)。一個(gè)節(jié)點(diǎn)可以同時(shí)具有多種類型。數(shù)據(jù)節(jié)點(diǎn)運(yùn)行所有數(shù)據(jù)操作,即存儲(chǔ)、索引和檢索數(shù)據(jù)。主候選節(jié)點(diǎn)具有投票 master 的權(quán)限,用于管理集群和索引。
索引(Index)是對(duì)數(shù)據(jù)的高級(jí)抽象,索引本身不保存數(shù)據(jù),它們只是實(shí)際存儲(chǔ)數(shù)據(jù)的另一種抽象。對(duì)數(shù)據(jù)執(zhí)行的任何操作(例如插入,刪除,建立索引和搜索)都會(huì)對(duì)索引產(chǎn)生影響。索引可以完全屬于一個(gè)集群,并且由分片( shard) 組成。
分片(Shard)是 Apache Lucene 的實(shí)例。一個(gè)分片可以容納許多文檔。分片是數(shù)據(jù)存儲(chǔ),索引和搜索的實(shí)際對(duì)象。分片只屬于一個(gè)節(jié)點(diǎn)和索引。分片有兩種類型:primary 和 replica,它們基本上是完全相同的,擁有相同的數(shù)據(jù),并且搜索并行運(yùn)行在所有分片。在擁有相同數(shù)據(jù)的所有分片中,其中一個(gè)屬于 primary。這是唯一可以接受索引請(qǐng)求的分片。如果節(jié)點(diǎn)中的主分片掛了,副本將接管并成為主分片。然后,ES 將創(chuàng)建一個(gè)新的副本并復(fù)制數(shù)據(jù)。
總結(jié)一下,我們整理得到下圖:
更深入了解 Elasticsearch
如果你想運(yùn)行一個(gè)系統(tǒng),相信你需要了解該系統(tǒng)。在本節(jié)中,我將解釋 Elasticsearch 的各個(gè)部分,如果想在生產(chǎn)中進(jìn)行管理,我相信你需要理解它。本節(jié)也不牽涉到具體建議,后文會(huì)介紹。本節(jié)目的只是為了介紹必要的背景。
Quorum
理解 Elasticsearch 是一個(gè)(有缺陷的)選舉體系非常重要。節(jié)點(diǎn)投票決定誰應(yīng)該管理它們,即主節(jié)點(diǎn)。主節(jié)點(diǎn)運(yùn)行大量集群管理進(jìn)程,并且在許多事務(wù)方面擁有最終決策權(quán)。ES 選舉是有缺陷的,是因?yàn)橹挥幸恍〔糠止?jié)點(diǎn),即主候選(master-eligible)節(jié)點(diǎn)才具有投票權(quán)。主候選節(jié)點(diǎn)是通過以下配置啟用:
node.master: true
在集群啟動(dòng)或主節(jié)點(diǎn)離開群集時(shí),所有符合主選舉條件的節(jié)點(diǎn)都會(huì)開始選舉新的主節(jié)點(diǎn)。為此,你需要具有 2n + 1 個(gè)主候選節(jié)點(diǎn)。否則,可能會(huì)出現(xiàn)腦裂情況,比如同時(shí)兩個(gè)節(jié)點(diǎn)獲得 50% 的選票,將會(huì)導(dǎo)致兩個(gè)分區(qū)之一中的所有數(shù)據(jù)丟失。為了不發(fā)生這種情況。你需要 2n + 1 個(gè)符合主候選的節(jié)點(diǎn)。
節(jié)點(diǎn)如何加入集群
當(dāng) ES 節(jié)點(diǎn)啟動(dòng)時(shí),它在廣闊世界中獨(dú)自存在。它怎么知道它屬于哪個(gè)集群?有不同的方法可以完成此操作,如今大多使用種子主機(jī)(Seed Host)的方法來實(shí)現(xiàn)。
基本上,Elasticsearch 節(jié)點(diǎn)會(huì)不斷地就他們所見過的所有其他節(jié)點(diǎn)進(jìn)行通訊。因此一個(gè)節(jié)點(diǎn)最初只需要了解幾個(gè)其他節(jié)點(diǎn)即可了解整個(gè)集群。讓我們來看一個(gè)三節(jié)點(diǎn)集群的示例:
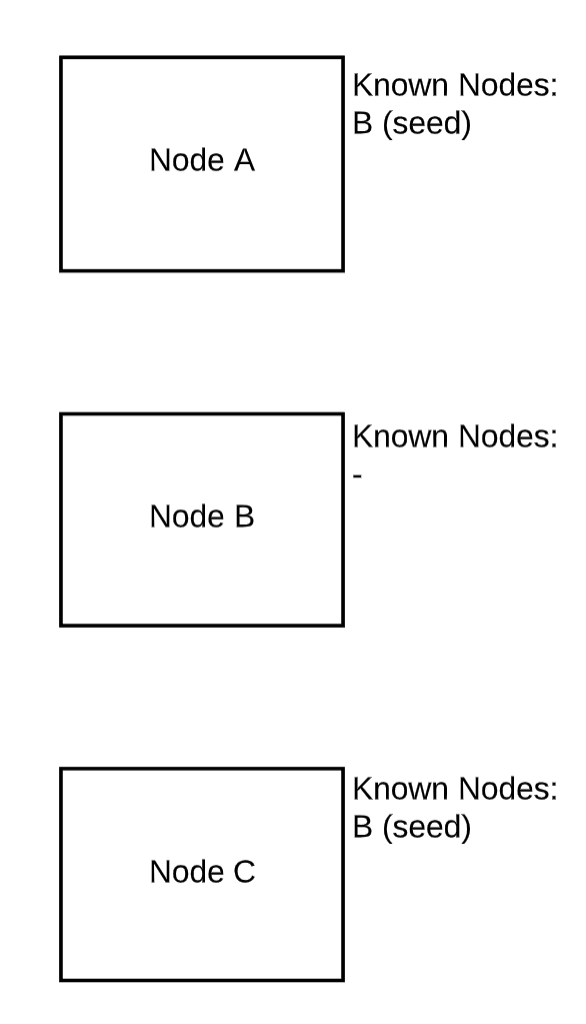
初始狀態(tài)
最初,節(jié)點(diǎn) A 和 C 只知道 B。B 是種子主機(jī)。種子主機(jī)要么以配置文件的形式提供給 ES,要么直接放入 elasticsearch.yml 中。
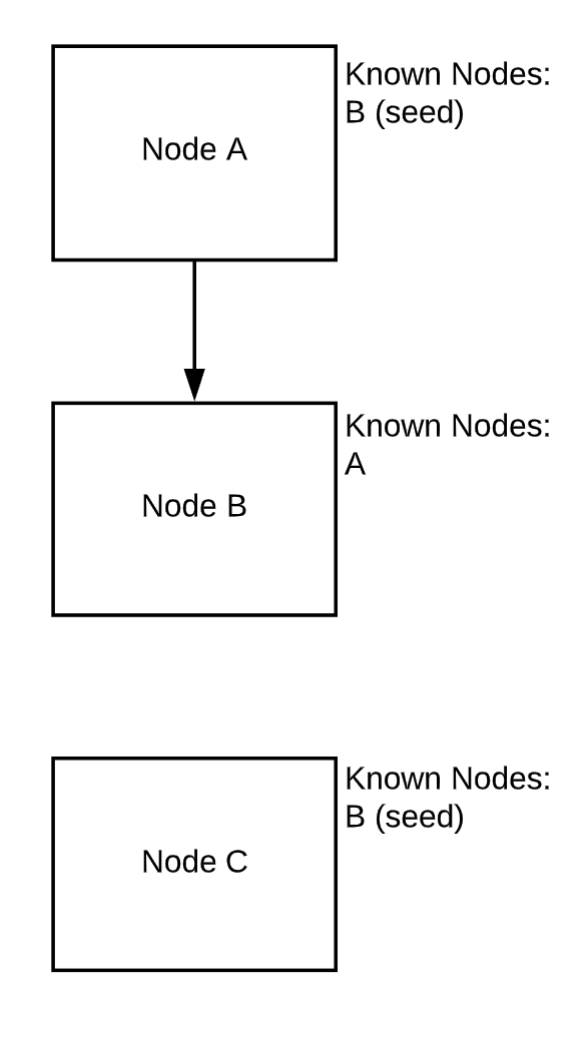
節(jié)點(diǎn) A 與 B 連接并交換信息
一旦節(jié)點(diǎn) A 連接到 B,B 就知道 A 的存在。對(duì)于 A 而言,沒有任何變化。
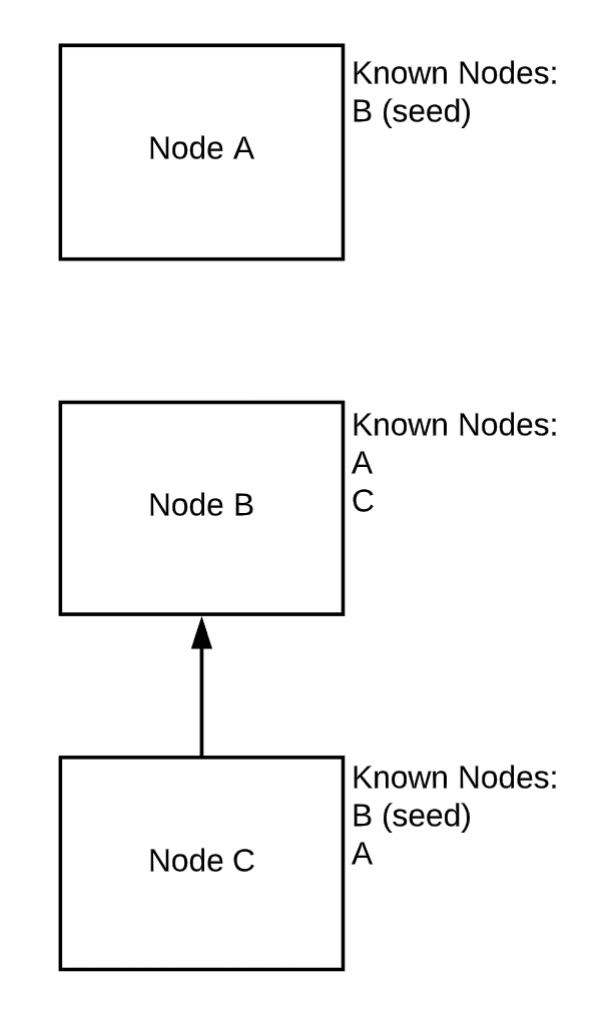
節(jié)點(diǎn) C 連接并與 B 共享信息
現(xiàn)在,C 連上來。一旦發(fā)生這種情況,B 就會(huì)告訴 C 有 A 的存在。C 和 B 現(xiàn)在知道群集中的所有節(jié)點(diǎn)。一旦 A 重新連接到 B,它也將了解 C 的存在。
段和段合并
上面我說過數(shù)據(jù)存儲(chǔ)分片中,這只是部分正確。最終數(shù)據(jù)是以文件的形式存儲(chǔ)在文件系統(tǒng)中。在 Lucene 和 Elasticsearch 中,這些文件稱為段(Segment)。一個(gè)分片將具有一到數(shù)千個(gè)段。
同樣,段是實(shí)際的真實(shí)文件,你可以在 Elasticsearch 安裝的 data 目錄中查看它。這意味著使用段存在開銷。如果要查看段,則必須找到文件并打開它。這意味著需要打開許多文件,并且將會(huì)有很多開銷。Lucene 中的段是不可變的,這是個(gè)問題。它們只能寫一次,然后就不能改了。反過來,這意味著你放入 ES 中的每個(gè)文檔都將創(chuàng)建一個(gè)僅包含這個(gè)文檔的段。顯然,一個(gè)擁有十億個(gè)文檔的集群具有十億個(gè)段,這意味著文件系統(tǒng)上確實(shí)有十億個(gè)文件,這樣理解對(duì)嗎?非也。
在后臺(tái),Lucene 進(jìn)行持續(xù)的段合并,它不能更改段,但是可以使用兩個(gè)較小段的數(shù)據(jù)合并創(chuàng)建新的段。
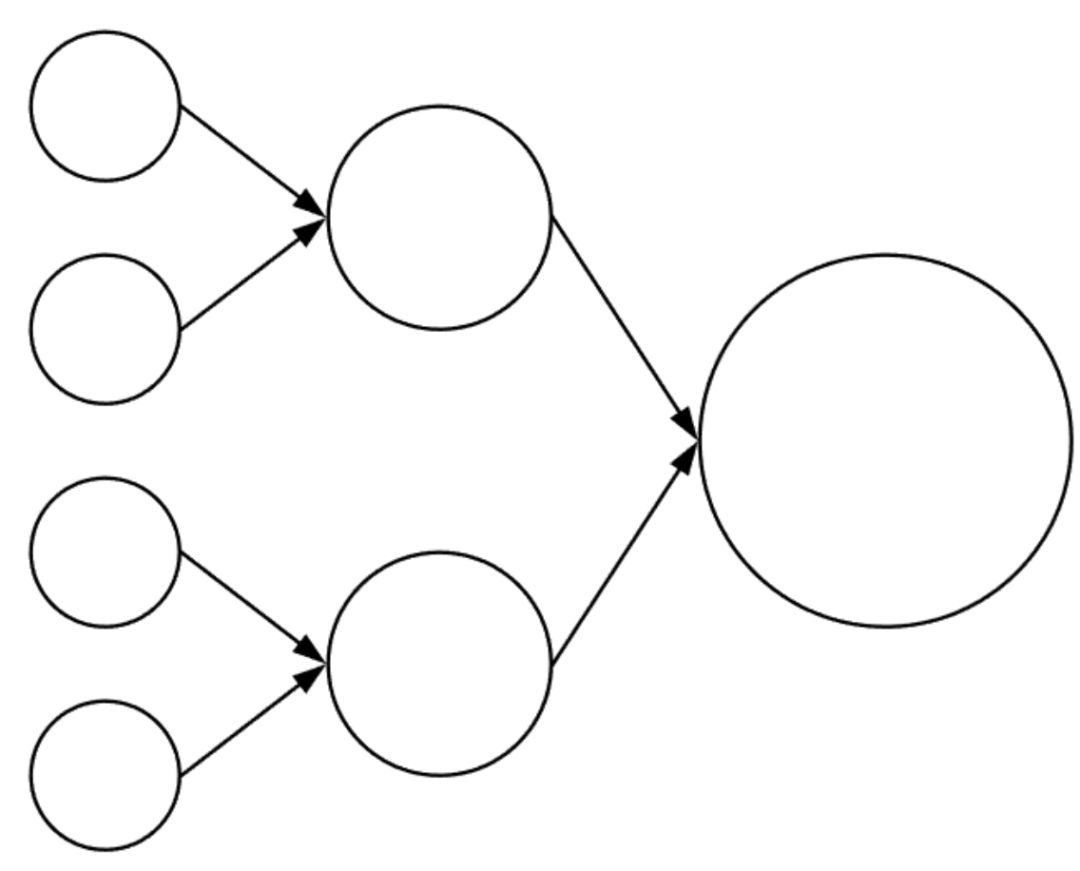
這樣,lucene 會(huì)不斷嘗試使段數(shù)(文件數(shù),即開銷)保持較小。你也可以使用強(qiáng)制合并。
消息路由
在 Elasticsearch 中,你可以對(duì)集群中的任何節(jié)點(diǎn)運(yùn)行任何命令,返回結(jié)果是相同的。有趣的是,文檔最終將只存在于一個(gè)主分片及其副本中,而 ES 不知道它在哪里。沒有一個(gè)映射來記錄某個(gè)文檔位于哪個(gè)分片中。
當(dāng)執(zhí)行搜索時(shí),獲取請(qǐng)求的 ES 節(jié)點(diǎn)會(huì)將其廣播到索引中的所有分片。即主分片及所有副本。這些分片然后會(huì)在包含該文檔的所有段中進(jìn)行查找。
當(dāng)執(zhí)行插入時(shí),ES 節(jié)點(diǎn)將隨機(jī)選擇一個(gè)主分片并將文檔放在其中。然后將其寫入該主分片及其所有副本。
如何在生產(chǎn)環(huán)境運(yùn)行 Elasticsearch?
本節(jié)是實(shí)踐部分。我前面提到,我管理 ES 的主要目的是為了記錄日志,本文將盡力避免這種傾向的影響,但有可能會(huì)失敗。
大小
需要提出并隨后回答自己的第一個(gè)問題是關(guān)于大小調(diào)整。你需要多少規(guī)模的 ES 集群?
內(nèi)存
我首先說的是 RAM,因?yàn)?RAM 將限制所有其他資源。
堆
ES 用 Java 編寫,Java 使用堆,你可以將其視為 Java 保留的內(nèi)存。如果將所有堆的重要因素都列出,會(huì)使這個(gè)文檔的大小增加三倍,所以我將介紹最重要的部分,即堆大小。
盡量使用更多內(nèi)存,但堆大小不得超過 30G。
有一個(gè)很多人都不知道的關(guān)于堆的秘密:堆中的每個(gè)對(duì)象都需要一個(gè)唯一的地址,即一個(gè)對(duì)象指針。該地址的長度是固定的,這意味著可以尋址的對(duì)象數(shù)量是有限的。簡單一點(diǎn)來描述就是,超出某個(gè)范圍時(shí),Java 將開始使用壓縮的對(duì)象指針而不是未壓縮的對(duì)象指針。這意味著每個(gè)內(nèi)存訪問都將涉及其他步驟,這會(huì)嚴(yán)重拖慢速度。因此你 100% 不需要設(shè)置超過此閾值(大約 32G)。
我曾經(jīng)整整一個(gè)星期都呆在一個(gè)黑暗的房間里,沒做別的,只是使用 esrally 基準(zhǔn)化測(cè)試 Elasticsearch 在不同文件系統(tǒng)、堆大小、文件和 BIOS 設(shè)置組合。長話短說,下面就是關(guān)于堆大小如何設(shè)置的內(nèi)容:
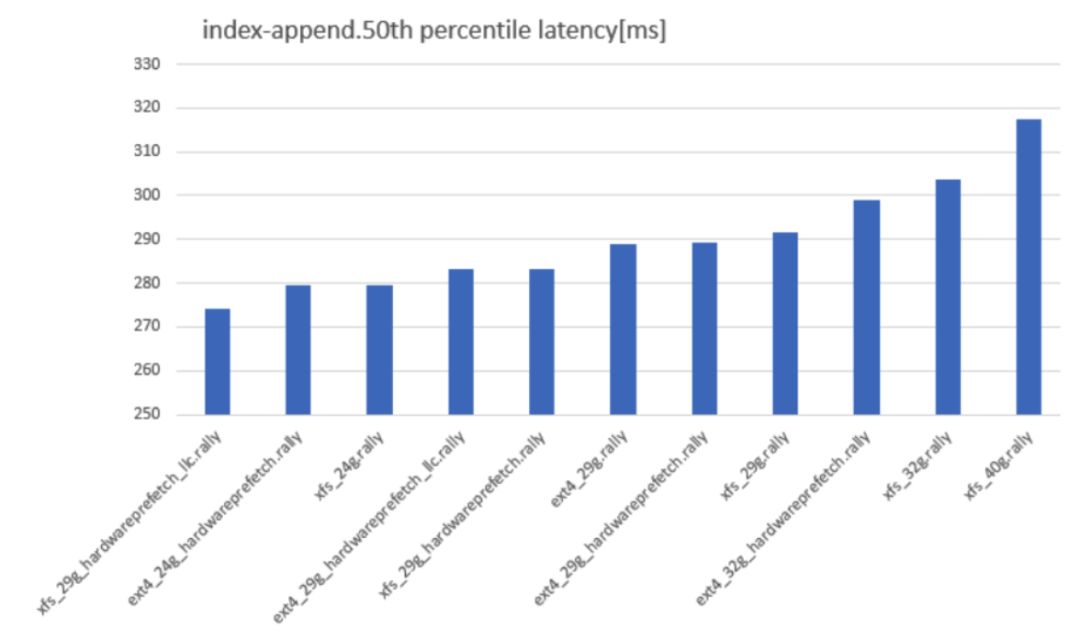
添加索引延遲,越低越好
命名約定為 fs_heapsize_biosflags。如你所見,從 32G 的堆大小開始,性能突然開始變差。吞吐量也同樣情況:
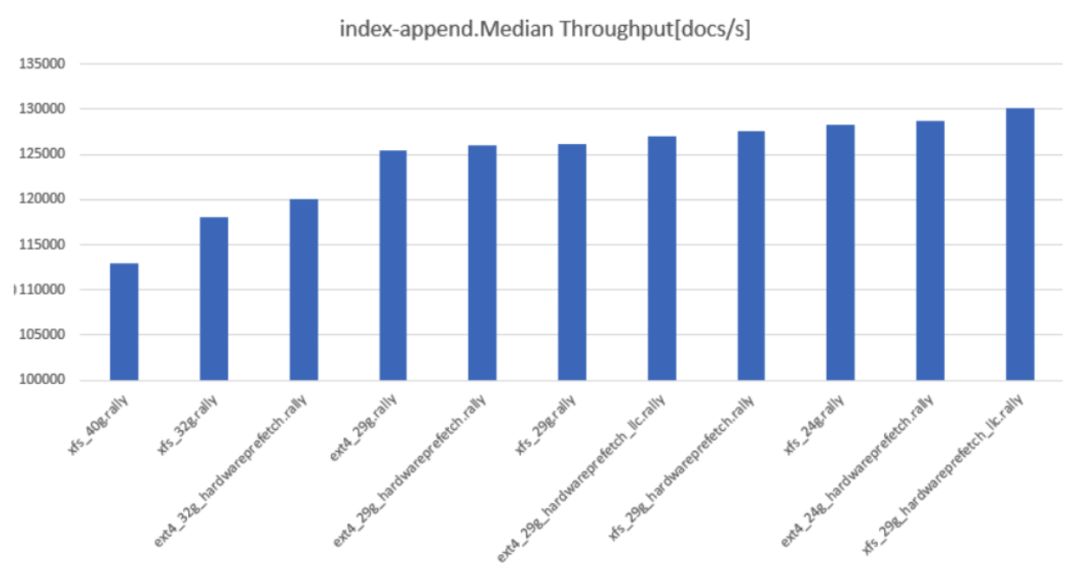
索引附加中值吞吐量。越高越好。
長話短說:如果想幸運(yùn)一點(diǎn),請(qǐng)使用 29G 或 30G 的 RAM,并使用 XFS,并盡可能啟用 hardwareprefetch 和 llc-prefetch。
文件緩存
大多數(shù)人在 Linux 上運(yùn)行 Elasticsearch,Linux 使用內(nèi)存作為文件系統(tǒng)緩存。常見的建議是 ES 服務(wù)器使用 64G 內(nèi)存,這樣的想法是一半用于緩存,一半用于堆。我尚未測(cè)試過文件緩存。但是不難看出,大型 ES 集群(如用于日志記錄)可以從配置大文件緩存中受益匪淺。如果你所有的索引都適合放入內(nèi)存堆,則不會(huì)那么多好處。
CPU
這取決于對(duì)集群執(zhí)行的操作。如果進(jìn)行大量索引,與僅執(zhí)行日志記錄相比,你需要更多更快的 CPU。對(duì)于日志記錄,我發(fā)現(xiàn) 8 個(gè) CPU 核綽綽有余,但是發(fā)現(xiàn)很多人使用更大的配置,但是對(duì)他的使用場景并沒有什么好處。
磁盤
這塊也沒有想像那么直接。首先,如果索引能放入 RAM,則磁盤僅在節(jié)點(diǎn)冷啟動(dòng)時(shí)才重要。其次,實(shí)際可以存儲(chǔ)的數(shù)據(jù)量取決于索引布局。每個(gè)分片都是一個(gè) Lucene 實(shí)例,它們都有內(nèi)存需求。這意味著你可以在堆中容納最大數(shù)量分片是有限的。我將在索引布局部分中詳細(xì)討論這一點(diǎn)。
通常,你可以將所有數(shù)據(jù)磁盤放入 RAID0。你需要在 Elasticsearch 級(jí)別進(jìn)行復(fù)制,因此丟失一個(gè)節(jié)點(diǎn)無關(guān)緊要。請(qǐng)勿將 LVM 與多個(gè)磁盤一起使用,因?yàn)?LVM 一次只能寫入一個(gè)磁盤,根本就不會(huì)帶來多個(gè)磁盤的好處。
關(guān)于文件系統(tǒng)和 RAID 設(shè)置,我整理了以下幾點(diǎn):
- Scheduler:cfq 和 deadline 優(yōu)于 noop。如果你有 nvme,Kyber 可能會(huì)很好,但我還沒有測(cè)試過
- QueueDepth:盡可能高
- 預(yù)讀:請(qǐng)打開
- Raid chunk size:無影響
- FS 塊大小:無影響
- FS 類型:XFS > ext4
索引布局
這在很大程度上取決于你的用例。我只能從日志場景(尤其是使用 Graylog)討論一下。
分片
精簡版:
- 對(duì)于寫入繁重的工作負(fù)載,主分片 = 節(jié)點(diǎn)數(shù)
- 對(duì)于讀取繁重的工作負(fù)載,主分片 * 副本數(shù) = 節(jié)點(diǎn)數(shù)
- 更多副本 = 更高的搜索性能
可以通過以下公式給出最大寫入性能:
- node_throughput * number_of_primary_shards
- 節(jié)點(diǎn)吞吐量 * 主分片數(shù)量
節(jié)點(diǎn)吞吐量 * 主分片數(shù)量
原因很簡單:如果只有一個(gè)主分片,那么寫入速度只類似于單節(jié)點(diǎn),因?yàn)橐粋€(gè)分片只能位于一個(gè)節(jié)點(diǎn)上。如果確實(shí)想優(yōu)化寫入性能,則應(yīng)確保每個(gè)節(jié)點(diǎn)上只有一個(gè)分片(主節(jié)點(diǎn)或副本),因?yàn)樵诖饲闆r下副本可以獲得與主節(jié)點(diǎn)相同的寫入速度,并且寫入很大程度上取決于磁盤 IO。注意:如果有很多索引,那么上述的策略可能有問題,性能瓶頸可能是其他原因。
如果要優(yōu)化搜索性能,可以通過以下公式給出:
- node_throughput * (number_of_primary_shards + number_of_replicas)
- 節(jié)點(diǎn)吞吐量 *(主分片數(shù)量 + 副本數(shù))
節(jié)點(diǎn)吞吐量 *(主分片數(shù)量 + 副本數(shù))
對(duì)于搜索,主分片和副本基本相同。因此,如果想提高搜索性能,只需增加副本的數(shù)量。
大小
關(guān)于索引大小,我已經(jīng)多次討論過。以下是我的經(jīng)驗(yàn):
- 30G of heap = 140 shards maximum per node
- 30G 堆內(nèi)存 = 可以在一個(gè)節(jié)點(diǎn)最多啟動(dòng) 140 個(gè)分片
使用 140 個(gè)以上的分片,Elasticsearch 就會(huì)進(jìn)程崩潰并出現(xiàn)內(nèi)存不足錯(cuò)誤。這是因?yàn)槊總€(gè)分片都是 Lucene 實(shí)例,并且每個(gè)實(shí)例都需要一定數(shù)量的內(nèi)存。這意味著每個(gè)節(jié)點(diǎn)可以擁有的分片數(shù)量是有限制的。
如果你有大量節(jié)點(diǎn),分片和索引大小,則可以容納多少個(gè)索引可以由以下公式計(jì)算:
- number_of_indices = (140 * number_of_nodes) / (number_of_primary_shards * replication_factor)
- 索引數(shù) = (140*節(jié)點(diǎn)數(shù))/(主分片數(shù) * 復(fù)制因子)
根據(jù)磁盤大小,可以很容易地計(jì)算出索引的大小:
- index_size = (number_of_nodes * disk_size) / number_of_indices
- 索引大小 = (節(jié)點(diǎn)數(shù)量 * 磁盤大小)/ 索引數(shù)量
然而索引越大搜索越慢。對(duì)于日志記錄來說,慢一點(diǎn)問題不大,但是對(duì)于真正的搜索量大的應(yīng)用程序,應(yīng)該根據(jù) RAM 大小來調(diào)整索引大小。
段合并
每個(gè)段都是文件系統(tǒng)中的一個(gè)實(shí)際文件,更多的段意味著更大的讀取開銷。基本上,對(duì)于每個(gè)搜索查詢,它都會(huì)轉(zhuǎn)到索引中的所有分片,再轉(zhuǎn)到分片中的所有段。多個(gè)段極大地增加集群讀取 IOPS,直到它變得不可用。因此,需要盡可能減少段的數(shù)量。
force_merge API 允許你將段合并到某個(gè)數(shù)量,比如 1。如果你執(zhí)行索引滾動(dòng)(例如使用 Elasticsearch 做日志記錄),那么在集群未使用時(shí)執(zhí)行常規(guī)強(qiáng)制合并是一個(gè)好建議。強(qiáng)制合并會(huì)占用大量資源,并且會(huì)顯著降低集群的運(yùn)行速度。因此,最好不要讓 Graylog 幫你來做,而是選擇在較少使用集群時(shí)間自己完成。如果你有很多索引的話,你必須定期執(zhí)行段合并。否則,集群運(yùn)行速度將會(huì)非常慢并最終掛掉。
集群布局
對(duì)于除最小設(shè)置外的所有設(shè)置,最好使用專用的候選主節(jié)點(diǎn)。主要原因是確保始終有 2n + 1 個(gè)候選主節(jié)點(diǎn)來確保仲裁。但是對(duì)于數(shù)據(jù)節(jié)點(diǎn),可以在任何時(shí)候添加新節(jié)點(diǎn),而不必?fù)?dān)心這個(gè)需求。另外,我們不希望數(shù)據(jù)節(jié)點(diǎn)上的高負(fù)載影響主節(jié)點(diǎn)。
最后,主節(jié)點(diǎn)是種子節(jié)點(diǎn)的理想候選節(jié)點(diǎn)。請(qǐng)記住,種子節(jié)點(diǎn)是在 Elasticsearch 中進(jìn)行節(jié)點(diǎn)發(fā)現(xiàn)的最簡單方法。由于主節(jié)點(diǎn)很少更改,因此它是最佳選擇,因?yàn)樗芸赡芤呀?jīng)知道集群中的所有其他節(jié)點(diǎn)。
主節(jié)點(diǎn)可以非常小,一個(gè) CPU 核,4G 的 RAM 已經(jīng)足夠大多數(shù)集群使用。當(dāng)然也需要關(guān)注實(shí)際使用情況,并進(jìn)行相應(yīng)調(diào)整。
監(jiān)控
ES 為你提供了大量的指標(biāo),并且以 JSON 的形式提供所有指標(biāo),這使得傳遞給監(jiān)控工具非常容易。以下是一些有用的監(jiān)控指標(biāo):
- 段數(shù)
- 堆使用
- 堆 GC 時(shí)間
- 平均 搜索,索引,合并時(shí)間
- IOPS
- 磁盤利用率
結(jié)論
本文花了我大約 5 個(gè)小時(shí),包含了我對(duì) ES 的所有了解,希望能讓你碰到問題的時(shí)候不那么頭疼。
資源
- https://www.elastic.co/guide/zh-CN/elasticsearch/reference/current/modules-node.html
- https://www.elastic.co/guide/en/elasticsearch/reference/master/modules-discovery-quorums .html
- https://github.com/elastic/rally
- https://tech.ebayinc.com/engineering/elasticsearch-performance-tuning-practice-at-ebay/