













Python 從業(yè)十年是種什么體驗?老程序員的一篇萬字經(jīng)驗分享
一、概述
本文起源于我在 Twitter 上發(fā)布的關(guān)于 Python 經(jīng)歷的一系列話題。
出于某些原因,想記錄一下我過去數(shù)年使用 Python 的經(jīng)驗和一些感悟。畢竟算是一門把我?guī)牖ヂ?lián)網(wǎng)行業(yè)的語言,而我近期已經(jīng)幾乎不再寫 Py 代碼, 做一個記錄,也許會對他人起到些微的幫助,也算是紀念與感恩了。
二、摘錄
推文地址:https://twitter.com/ppcelery/status/1159620182089728000
最早接觸 py 是 2010 年左右,那之前主要是使用 c、fortran 和 matlab 做數(shù)值運算。當(dāng)時在做一些文件文本處理時覺得很麻煩,后來看到 NASA 說要用 py 取代 matlab,就去接觸了 py。
python 那極為簡潔與優(yōu)美的語法給了當(dāng)時的我極大的震撼,時至今日,寫 py 代碼對我而言依然是一種帶有藝術(shù)意味的享受。
首先開宗明義的說一句:python 并不慢,至少不夠慢。拿一個 web 后端來說,一臺垃圾 4 核虛機,跑 4 個同步阻塞的 django,假設(shè) django 上合理利用線程分擔(dān)了阻塞操作,假設(shè)每節(jié)點每秒可以處理 50 個請求(超低估),在白天的 10 小時內(nèi)就可以處理 720 萬請求。而這種機器跑一天僅需要 20 塊錢。

在學(xué)習(xí) Python 以前需要強調(diào)的是:基礎(chǔ)語法非常重要。雖然我們都不推崇過多的死記硬背,但是少量必要的死背是以后所有復(fù)雜思維活動的基礎(chǔ),就像五十音對于日語,通假字和常用動名詞對于文言文,你不會就是不行。
一般認為,這包括數(shù)據(jù)類型(值/引用)、作用域(scope)、keyword、builtin 函數(shù)等
關(guān)于 Python 版本的選擇,很多公司老項目依然在用 2.6、2.7,新項目的話建議至少選擇 3.6(擁有穩(wěn)定的 asyncio)。
-
從 2.7 到 3.4 https://blog.laisky.com/p/whats-new-in-python3-4/
-
從 3.4 到 3.5 https://blog.laisky.com/p/whats-new-in-python3-5/
-
從 3.5 到 3.6 https://blog.laisky.com/p/whats-new-in-python3-6/
-
從 3.6 到 3.7 https://docs.python.org/zh-cn/3/whatsnew/3.7.html
關(guān)于版本最后在說幾點,建議在本地和服務(wù)器上都通過 pyenv 來管理版本,而不要去動系統(tǒng)自帶的 python(以免引起額外的麻煩) https://blog.laisky.com/p/pyenv/
另外一點就是,如果你想寫一個兼容 2、3 的工具包,你可以考慮使用 future http://python-future.org/compatible_idioms.html
最后提醒一下,2to3 這個腳本是有可能出錯的。
學(xué)完基礎(chǔ)就可以開始動手寫代碼了,這時候應(yīng)該謹記遵守一些“通行規(guī)范”,幾年前給公司內(nèi)分享時做過一個摘要:
-
風(fēng)格指引 https://laisky.github.io/style-guide-cn/style-guides/source-code-style-guides/
-
一些注意事項 https://laisky.github.io/style-guide-cn/style-guides/consensuses/
有了一定的實踐經(jīng)驗后,你應(yīng)該學(xué)習(xí)更多的包來提高自己的代碼水平。
-
值得學(xué)習(xí)的內(nèi)建包 https://pymotw.com/3/
-
值得了解的第三方包 https://github.com/vinta/awesome-python
因為 py 的哲學(xué)(import this)建議應(yīng)該有且僅有一個完美的方式做一件事,所以建議優(yōu)先采用且完善既有項目而不建議過多的造輪子。
一個小插曲,寫這段的 Tim Peters 就是發(fā)明 timsort 的那位。
https://en.wikipedia.org/wiki/Tim_Peters_(software_engineer)
有空時候,建議盡可能的完整讀教材和文檔,建立系統(tǒng)性的知識體系,這可以極大的提升你的眼界和思維能力。我自己讀過且覺得值得推薦的針對 py 的書籍有:
-
https://docs.python.org/3/
-
learning python
-
核心編程
-
改進Python的91個建議
-
Python高手之路
-
Python源碼剖析
-
數(shù)據(jù)結(jié)構(gòu)與算法:Python語言描述
如果你真的很喜歡 Python 的話,那我覺得你應(yīng)該也會喜歡閱讀 PEP,記得幾年前我只要有空就會去翻閱 PEP,這相當(dāng)于是 Py 的 RFC,里面記錄了幾乎每一項語法的設(shè)計理念與目的。我特別喜歡的 PEP 有:
-
8
-
3148
-
380
-
484 & 3107
-
492: async
-
440
-
3132
-
495 你甚至能學(xué)到歷史知識
以前聽別人講過一個比喻,靜態(tài)語言是吃冒菜,一次性燙好。而動態(tài)語言是涮火鍋,吃一點涮一點。
那么我覺得,GIL 就是僅有一雙筷子的火鍋,即使你菜很多,一次也只能涮一個。
但是,對于 I/O bound 的操作,你不必一直夾著菜,而是可以夾一些扔到鍋里,這樣就可以同時涮很多,提高并行效率。
GIL 在一個進程內(nèi),解釋器僅能同時解釋執(zhí)行一條語句,這為 py 提供了天然的語句級線程安全,從很多意義上說,這都極大的簡化了并行編程的難度。對于 I/O 型應(yīng)用,多線程并不會受到多大影響。對于 CPU 型應(yīng)用,編寫一個基于 Queue 的多進程 worker 其實也就是幾行的事。
(訂正:應(yīng)為偽指令級的線程安全)
- from time import sleep
- from concurrent.futures import ProcessPoolExecutor, wait
- from multiprocessing import Manager, Queue
- N_PARALLEL = 5
- def worker(i: int, q: Queue) -> None:
- print(f'worker {i} start')
- while 1:
- data = q.get
- if data is None: # 采用毒丸(poison pill)方式來結(jié)束進程池
- q.put(data)
- print(f'worker {i} exit')
- return
- print(f'dealing with data {data}...')
- sleep(1)
- def main:
- executor = ProcessPoolExecutor(max_workers=N_PARALLEL) # 控制并發(fā)量
- with Manager as manager:
- queue = manager.Queue(maxsize=50) # 控制緩存量
- workers = [executor.submit(worker, i, queue) for i in range(N_PARALLEL)]
- for i in range(50):
- queue.put(i)
- print('all task data submitted')
- queue.put(None)
- wait(workers)
- print('all done')
- main
我經(jīng)常給新人講,是否能謹慎的對待并行編程,是一個區(qū)分初級和資深后端開發(fā)的分水嶺。業(yè)界有一句老話:“沒有正確的并行程序,只有不夠量的并行度”,由此可見并行開發(fā)的復(fù)雜程度。
我個人認為思考并行時主要是在考慮兩個問題:同步控制和資源用量。
對于同步控制,你在 thread, multiprocessing, asyncio 幾個包里都會發(fā)現(xiàn)一系列的工具:
-
Lock 互斥鎖
-
RLock 可重入鎖
-
Queue 隊列
-
Condition 條件鎖
-
Event 事件鎖
-
Semaphore 信號量
這個就不展開細談了,屬于另一個語言無關(guān)的大領(lǐng)域。(以前寫過一個很簡略的簡介:并行編程中的各種鎖(https://blog.laisky.com/p/concurrency-lock/))
對于資源控制,一般來說主要就是兩個地方:
-
緩存區(qū)有多大(Queue 長度)
-
并發(fā)量有多大(workers 數(shù)量)
一般來說,前者直接確定了你內(nèi)存的消耗量,最好選擇一個恰好或略高于消費量的數(shù)。后者一般直接決定了你的 CPU 使用率,過高的并發(fā)量會增加切換開銷,得不償失。
既然提到了 workers,稍微簡單展開一下“池”這個概念。我們經(jīng)常提到線程池、進程池、連接池。說白了就是對于一些可重用的資源,不必每次都創(chuàng)建新的,而是使用完畢后回收留待下一個數(shù)據(jù)繼續(xù)使用。比如你可以選擇不斷地開子線程,也可以選擇預(yù)先開好一批線程,然后通過 queue 來不斷的獲取和處理數(shù)據(jù)。
所以說使用“池”的主要目的就是減少資源的消耗。另一個優(yōu)點是,使用池可以非常方便的控制并發(fā)度(很多新人以為 Queue 是用來控制并發(fā)度的,這是錯誤的,Queue 控制的是緩存量)。
對于連接池,還有另一層好處,那就是端口資源是有限的,而且回收端口的速度很慢,你不斷的創(chuàng)建連接會導(dǎo)致端口迅速耗盡。
這里做一個用語的訂正。Queue 控制的應(yīng)該是緩沖量(buffer),而不是緩存量(cache)。一般來說,我們習(xí)慣上將寫入隊列稱為緩沖,將讀取隊列稱為緩存(有源)。
對前面介紹的 python 中進程/線程做一個小結(jié),線程池可以用來解決 I/O 的阻塞,而進程可以用來解決 GIL 對 CPU 的限制(因為每一個進程內(nèi)都有一個 GIL)。所以你可以開 N 個(小于等于核數(shù))進程池,然后在每一個進程中啟動一個線程池,所有的線程池都可以訂閱同一個 Queue,來實現(xiàn)真正的多核并行。
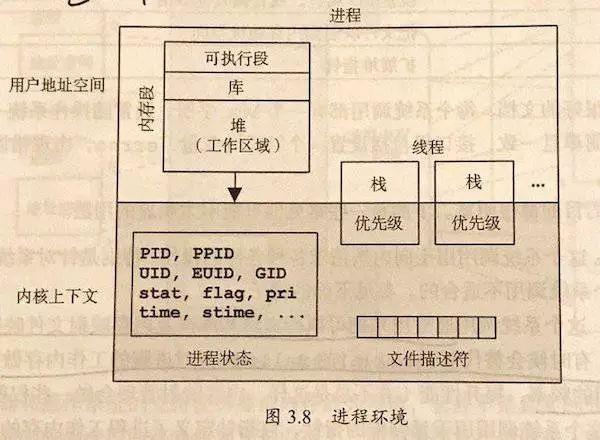
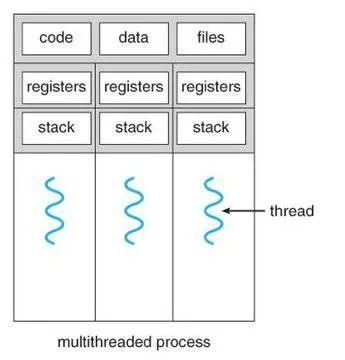
非常簡單的描述一下進程/線程,對于操作系統(tǒng)而言,可以認為進程是資源的最小單位(在 PCB 內(nèi)保存如圖 1 的數(shù)據(jù))。而線程是調(diào)度的最小單位。同一個進程內(nèi)的線程共享除棧和寄存器外的所有數(shù)據(jù)。
所以在開發(fā)時候,要小心進程內(nèi)多線程數(shù)據(jù)的沖突,也要注意多進程數(shù)據(jù)間的隔離(需要特別使用進程間通信)
-
操作系統(tǒng)筆記:進程(https://blog.laisky.com/p/os-process/)
-
操作系統(tǒng)筆記:調(diào)度(https://blog.laisky.com/p/os-scheduler/)
再簡單的補充一下,進程間通信的手段有:管道、信號、消息隊列、信號量、共享內(nèi)存和套接字。不過在 Py 里,單機上最常用的進程間通信就是 multiprocessing 里的 Queue 和 sharedctypes。
順帶一提,因為 CPython 的 refcnt 機制,所以 COW(copy on write)并不可靠。
人們在見到別人的“錯誤寫法”時,傾向于無視或吐槽諷刺。但是這個行為除了讓自己爽一下外沒有任何意義,不懂的還是不懂,最后真正發(fā)揮影響的還是那些能夠描繪一整條學(xué)習(xí)路徑的方法。
我一直希望能看到一個“樸素誠懇”的切合工程實踐的教程,而不是網(wǎng)上流傳的入門大全和網(wǎng)課兜售騙錢的框架調(diào)參速成。
關(guān)于進程間的內(nèi)存隔離,補充一個簡單直觀的例子。可以看到普通變量 normal_v在兩個子進程內(nèi)變成了兩個獨立的變量(都輸出 1),而共享內(nèi)存的shared_v仍然是同一個變量,分別輸出了 1 和 2。
- from time import sleep
- from concurrent.futures import ProcessPoolExecutor, wait
- from multiprocessing import Manager, Queue
- from ctypes import c_int64
- def worker(i, normal_v, shared_v):
- normal_v += 1 # 因為進程間內(nèi)存隔離,所以每個進程都會得到 1
- shared_v.value += 1 # 因為使用了共享內(nèi)存,所以會分別得到 1 和 2
- print(f'worker[{i}] got normal_v {normal_v}, shared_v {shared_v.value}')
- def main:
- executor = ProcessPoolExecutor(max_workers=2)
- with Manager as manager:
- lock = manager.Lock
- shared_v = manager.Value(c_int64, 0, lock=lock)
- normal_v = 0
- workers = [executor.submit(worker, i, normal_v, shared_v) for i in range(2)]
- wait(workers)
- print('all done')
- main
從過去的工作經(jīng)驗中,我總結(jié)了一個簡單粗暴的規(guī)矩:如果你要使用多進程,那么在程序啟動的時候就把進程池啟動起來,然后需要任何資源都請在進程內(nèi)自行創(chuàng)建使用。如果有數(shù)據(jù)需要共享,一定要顯式的采用共享內(nèi)存或 queue 的方式進行傳遞。
見過太多在進程間共享不該共享的東西而導(dǎo)致的極為詭異的數(shù)據(jù)行為。
最早,一臺機器從頭到尾只能干一件事情。
后來,有了分時系統(tǒng),我們可以開很多進程,同時干很多事。
但是進程的上下文切換開銷太大,所以又有了線程,這樣一個核可以一直跑一個進程,而僅需要切換進程內(nèi)子線程的棧和寄存器。
直到遇到了 C10K 問題,人們發(fā)覺切換幾萬個線程還是挺重的,是否能更輕?
這里簡單的展開一下,內(nèi)存在操作系統(tǒng)中會被劃分為內(nèi)核態(tài)和用戶態(tài)兩部分,內(nèi)核態(tài)供內(nèi)核運行,用戶態(tài)供普通的程序用。
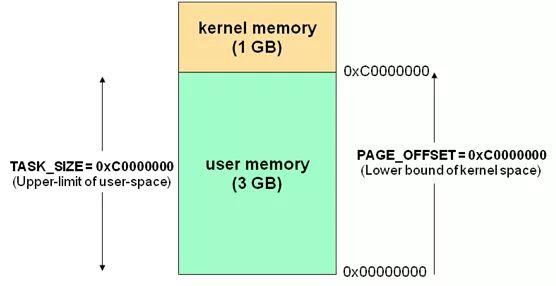
應(yīng)用程序通過系統(tǒng) API(俗稱 syscall)和內(nèi)核發(fā)生交互。拿常見的 HTTP 請求來說,其實就是一次同步阻塞的 socket 調(diào)用,每次調(diào)用都會導(dǎo)致線程阻塞等待內(nèi)核響應(yīng)(內(nèi)核陷入)。
而被阻塞的線程就會導(dǎo)致切換的發(fā)生。所以自然會問,能不能減少這種切換開銷?換句話說,能不能在一個地方把事情做完,而不要切來切去的。
這個問題有兩個解決思路,一是把所有的工作放進內(nèi)核去做(略)。
另一個思路就是把盡可能多的工作放到用戶態(tài)來做。這需要內(nèi)核接口提供額外的支持:異步系統(tǒng)調(diào)用。
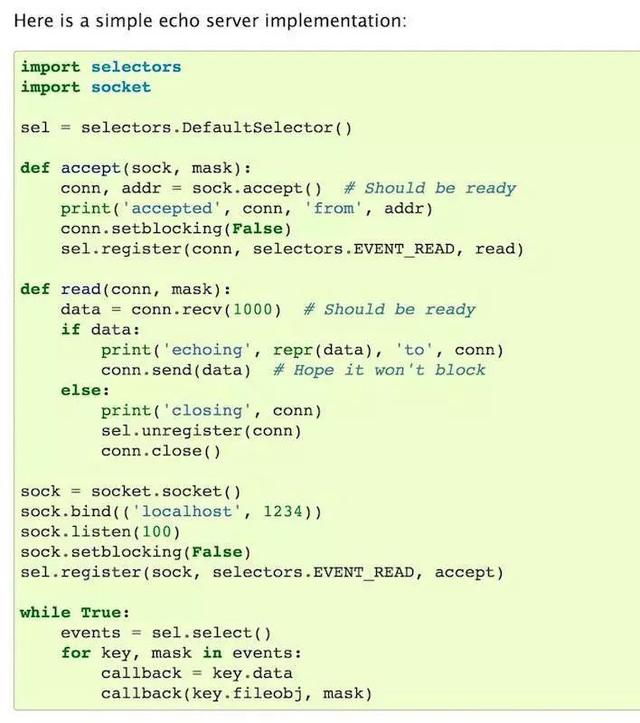
如 socket 這樣的調(diào)用就支持非阻塞調(diào)用,調(diào)用后會拿到一個未就緒的 fp,將這個 fp 交給負責(zé)管理 I/O 多路復(fù)用的 selector,再注冊好需要監(jiān)聽的事件和回調(diào)函數(shù)(或者像 tornado 一樣采用定時 poll),就可以在事件就緒(如 HTTP 請求的返回已就緒)時執(zhí)行相關(guān)函數(shù)。
https://github.com/tornadoweb/tornado/blob/f1824029db933d822f5b0d02583e4e6137f2bfd2/tornado/ioloop.py#L746

這樣就可以實現(xiàn)在一個線程內(nèi),啟動多個曾經(jīng)會導(dǎo)致線程被切換的系統(tǒng)調(diào)用,然后在一個線程內(nèi)監(jiān)聽這些調(diào)用的事件,誰先就緒就處理誰,將切換的開銷降到了最小。
有一個需要特別注意的要點,你會發(fā)現(xiàn)主線程其實就是一個死循環(huán),所有的調(diào)用都發(fā)生在這個循環(huán)之內(nèi)。所以,你寫的代碼一定要避免任何阻塞。

聽上去很美好,這是個萬能方案嗎?
很可惜不是的,最直接的一個問題是,并不是所有的 syscall 都提供了異步方法,對于這種調(diào)用,可以用線程池進行封裝。對于 CPU 密集型調(diào)用,可以用進程池進行封裝,asyncio 里提供了 executor 和協(xié)程進行聯(lián)動的方法,這里提供一個線程池的簡單例子,進程池其實同理。
- from time import sleep
- from asyncio import get_event_loop, sleep as asleep, gather, ensure_future
- from concurrent.futures import ThreadPoolExecutor, wait, Future
- from functools import wraps
- executor = ThreadPoolExecutor(max_workers=10)
- ioloop = get_event_loop
- def nonblocking(func) -> Future:
- @wraps(func)
- def wrapper(*args):
- return ioloop.run_in_executor(executor, func, *args)
- return wrapper
- @nonblocking # 用線程池封裝沒法協(xié)程化的普通阻塞程序
- def foo(n: int):
- """假裝我是個很耗時的阻塞調(diào)用"""
- print('start blocking task...')
- sleep(n)
- print('end blocking task')
- async def coroutine_demo(n: int):
- """我就是個普通的協(xié)程"""
- # 協(xié)程內(nèi)不能出現(xiàn)任何的阻塞調(diào)用,所謂一朝協(xié)程,永世協(xié)程
- # 那我偏要調(diào)一個普通的阻塞函數(shù)怎么辦?
- # 最簡單的辦法,套一個線程池…
- await foo(n)
- async def coroutine_demo_2:
- print('start coroutine task...')
- await asleep(1)
- print('end coroutine task')
- async def coroutine_main:
- """一般我們會寫一個 coroutine 的 main 函數(shù),專門負責(zé)管理協(xié)程"""
- await gather(
- coroutine_demo(1),
- coroutine_demo_2
- )
- def main:
- ioloop.run_until_complete(coroutine_main)
- print('all done')
- main
-
Python3 asyncio 簡介(https://blog.laisky.com/p/asyncio/)
上面的例子全部都基于 3.7,如果你還在使用 Py2,那么你也可以通過 gevent、tornado 用上協(xié)程。
我個人傾向于 tornado,因為更為白盒,而且寫法和 3 接近,如果你也贊同,那么可以試試我以前給公司寫的 kipp 庫,基于 tornado 封裝了更多的工具。
https://github.com/Laisky/kipp/blob/2bc5bda6e7f593f89be662f46fed350c9daabded/kipp/aio/__init__.py
Gevent Demo:
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- """
- Gevent Pool & Child Tasks
- =========================
- You can use gevent.pool.Pool to limit the concurrency of coroutines.
- And you can create unlimit subtasks in each coroutine.
- Benchmark
- =========
- cost 2.675039052963257s for url http://httpbin.org/
- cost 2.66813588142395s for url http://httpbin.org/ip
- cost 2.674264907836914s for url http://httpbin.org/user-agent
- cost 2.6776888370513916s for url http://httpbin.org/get
- cost 3.97711181640625s for url http://httpbin.org/headers
- total cost 3.9886841773986816s
- """
- import time
- import gevent
- from gevent.pool import Pool
- import gevent.monkey
- pool = Pool(10) # set the concurrency limit
- gevent.monkey.patch_socket
- try:
- import urllib2
- except ImportError:
- import urllib.request as urllib2
- TARGET_URLS = (
- 'http://httpbin.org/',
- 'http://httpbin.org/ip',
- 'http://httpbin.org/user-agent',
- 'http://httpbin.org/headers',
- 'http://httpbin.org/get',
- )
- def demo_child_task:
- """Sub coroutine task"""
- gevent.sleep(2)
- def demo_task(url):
- """Main coroutine
- You should wrap your each task into one entry coroutine,
- then spawn its own sub coroutine tasks.
- """
- start_ts = time.time
- r = urllib2.urlopen(url)
- demo_child_task
- print('cost {}s for url {}'.format(time.time - start_ts, url))
- def main:
- start_ts = time.time
- pool.map(demo_task, TARGET_URLS)
- print('total cost {}s'.format(time.time - start_ts))
- if __name__ == '__main__':
- main
tornado demo:
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- """
- cost 0.5578329563140869s, get http://httpbin.org/get
- cost 0.5621621608734131s, get http://httpbin.org/ip
- cost 0.5613000392913818s, get http://httpbin.org/user-agent
- cost 0.5709919929504395s, get http://httpbin.org/
- cost 0.572376012802124s, get http://httpbin.org/headers
- total cost 0.5809519290924072s
- """
- import time
- import tornado
- import tornado.web
- import tornado.httpclient
- TARGET_URLS = [
- 'http://httpbin.org/',
- 'http://httpbin.org/ip',
- 'http://httpbin.org/user-agent',
- 'http://httpbin.org/headers',
- 'http://httpbin.org/get',
- ]
- @tornado.gen.coroutine
- def demo_hanlder(ioloop):
- for i, url in enumerate(TARGET_URLS):
- demo_task(url, ioloop=ioloop)
- @tornado.gen.coroutine
- def demo_task(url, ioloop=None):
- start_ts = time.time
- http_client = tornado.httpclient.AsyncHTTPClient
- r = yield http_client.fetch(url)
- # r is the response object
- end_ts = time.time
- print('cost {}s, get {}'.format(end_ts - start_ts, url))
- TARGET_URLS.remove(url)
- if not TARGET_URLS:
- ioloop.stop
- def main:
- start_ts = time.time
- ioloop = tornado.ioloop.IOLoop.instance
- ioloop.add_future(demo_hanlder(ioloop), lambda f: None)
- ioloop.start
- # total cost will equal to the longest task
- print('total cost {}s'.format(time.time - start_ts))
- if __name__ == '__main__':
- main
kipp demo:
- from time import sleep
- from kipp.aio import coroutine2, run_until_complete, sleep, return_in_coroutine
- from kipp.utils import ThreadPoolExecutor, get_logger
- executor = ThreadPoolExecutor(10)
- logger = get_logger
- @coroutine2
- def coroutine_demo:
- logger.info('start coroutine_demo')
- yield sleep(1)
- logger.info('coroutine_demo done')
- yield executor.submit(blocking_func)
- return_in_coroutine('yeo')
- def blocking_func:
- logger.info('start blocking task...')
- sleep(1)
- logger.info('blocking task return')
- return 'hard'
- @coroutine2
- def coroutine_main:
- logger.info('start coroutine_main')
- r = yield coroutine_demo
- logger.info('coroutine_demo return: {}'.format(r))
- yield sleep(1)
- return_in_coroutine('coroutine_main yo')
- def main:
- f = coroutine_main
- run_until_complete(f)
- logger.info('coroutine_main return: {}'.format(f.result))
- if __name__ == '__main__':
- main
使用 tornado 時需要注意,因為它依賴 generator 來模擬協(xié)程,所以函數(shù)無法返回,只能用 raise gen.Return 來模擬。3.4 里引入了 yield from 到 3.6 的 async/await 才算徹底解決了這個問題。還有就是小心 tornado 里的 Future 不是線程安全的。
至于 gevent,容我吐個槽,求別再提 monkey_patch 了…
https://docs.python.org/3/library/asyncio-task.html 官方文檔對于 asyncio 的描述很清晰易懂,推薦一讀。一個小提示,async 函數(shù)被調(diào)用后會創(chuàng)建一個 coroutine,這時候該協(xié)程并不會運行,需要通過 ensure_future 或 create_task 方法生成 Task 后才會被調(diào)度執(zhí)行。
另外,一個進程內(nèi)不要創(chuàng)建多個 ioloop。
做一個小結(jié),一個簡單的做法是,啟動程序后,分別創(chuàng)建一個進程池(進程數(shù)小于等于可用核數(shù))、線程池和 ioloop,ioloop 負責(zé)調(diào)度一切的協(xié)程,遇到阻塞的調(diào)用時,I/O 型的扔進線程池,CPU 型的扔進進程池,這樣代碼邏輯簡單,還能盡可能的利用機器性能。一個簡單的完整示例:
- """
- ✗ python process_thread_coroutine.py
- [2019-08-11 09:09:37,670Z - INFO - kipp] - main running...
- [2019-08-11 09:09:37,671Z - INFO - kipp] - coroutine_main running...
- [2019-08-11 09:09:37,671Z - INFO - kipp] - io_blocking_task running...
- [2019-08-11 09:09:37,690Z - INFO - kipp] - coroutine_task running...
- [2019-08-11 09:09:37,691Z - INFO - kipp] - coroutine_error running...
- [2019-08-11 09:09:37,691Z - INFO - kipp] - coroutine_error end, cost 0.00s
- [2019-08-11 09:09:37,693Z - INFO - kipp] - cpu_blocking_task running...
- [2019-08-11 09:09:38,674Z - INFO - kipp] - io_blocking_task end, cost 1.00s
- [2019-08-11 09:09:38,695Z - INFO - kipp] - coroutine_task end, cost 1.00s
- [2019-08-11 09:09:39,580Z - INFO - kipp] - cpu_blocking_task end, cost 1.89s
- [2019-08-11 09:09:39,582Z - INFO - kipp] - coroutine_main got [None, AttributeError('yo'), None, None]
- [2019-08-11 09:09:39,582Z - INFO - kipp] - coroutine_main end, cost 1.91s
- [2019-08-11 09:09:39,582Z - INFO - kipp] - main end, cost 1.91s
- """
- from time import sleep, time
- from asyncio import get_event_loop, sleep as asleep, gather, ensure_future, iscoroutine
- from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor, wait
- from functools import wraps
- from kipp.utils import get_logger
- logger = get_logger
- N_FORK = 4
- N_THREADS = 10
- thread_executor = ThreadPoolExecutor(max_workers=N_THREADS)
- process_executor = ProcessPoolExecutor(max_workers=N_FORK)
- ioloop = get_event_loop
- def timer(func):
- @wraps(func)
- def wrapper(*args, **kw):
- logger.info(f"{func.__name__} running...")
- start_at = time
- try:
- r = func(*args, **kw)
- finally:
- logger.info(f"{func.__name__} end, cost {time - start_at:.2f}s")
- return wrapper
- def async_timer(func):
- @wraps(func)
- async def wrapper(*args, **kw):
- logger.info(f"{func.__name__} running...")
- start_at = time
- try:
- return await func(*args, **kw)
- finally:
- logger.info(f"{func.__name__} end, cost {time - start_at:.2f}s")
- return wrapper
- @timer
- def io_blocking_task:
- """I/O 型阻塞調(diào)用"""
- sleep(1)
- @timer
- def cpu_blocking_task:
- """CPU 型阻塞調(diào)用"""
- for _ in range(1 << 26):
- pass
- @async_timer
- async def coroutine_task:
- """異步協(xié)程調(diào)用"""
- await asleep(1)
- @async_timer
- async def coroutine_error:
- """會拋出異常的協(xié)程調(diào)用"""
- raise AttributeError("yo")
- @async_timer
- async def coroutine_main:
- ioloop = get_event_loop
- r = await gather(
- coroutine_task,
- coroutine_error,
- ioloop.run_in_executor(thread_executor, io_blocking_task),
- ioloop.run_in_executor(process_executor, cpu_blocking_task),
- return_exceptions=True,
- )
- logger.info(f"coroutine_main got {r}")
- @timer
- def main:
- get_event_loop.run_until_complete(coroutine_main)
- if __name__ == "__main__":
- main
學(xué)到這一步,你已經(jīng)能夠熟練的運用協(xié)程、線程、進程處理不同類型的任務(wù)。接著拿上面提到的垃圾 4 核虛機舉例,你現(xiàn)在應(yīng)該可以比較輕松的實現(xiàn)達到 1k QPS 的服務(wù),在白天十小時里可以處理超過一億請求,費用依然僅 20元/天。你還有什么借口說是因為 Python 慢呢?
人們在聊到語言/框架/工具性能時,考慮的是“當(dāng)程序員盡可能的優(yōu)化后,工具性能會成為最終的瓶頸,所以我們一定要選一個最快的”。
但事實上是,程序員本身才是性能的最大瓶頸,而工具真正體現(xiàn)出來的價值,是在程序員很爛時,所能提供的兜底性能。
如果你覺得自己并不是那個瓶頸,那也沒必要來聽我講了
在性能優(yōu)化上有兩句老話:
-
一定要針對瓶頸做優(yōu)化
-
過早優(yōu)化是萬惡之源
所以我覺得要開放、冷靜地看待工具的性能。在一套完整的業(yè)務(wù)系統(tǒng)中,框架工具往往是耗時占比最低的那個,在擴容、緩存技術(shù)如此發(fā)達的今天,你已經(jīng)很難說出工具性能不夠這樣的話了。
成長的空間很大,多在自己身上找原因。
一個經(jīng)驗觀察,即使在工作中不斷的實際練習(xí),對于異步協(xié)程這種全新的思維模式,從學(xué)會到能在工作中熟練運用且不犯大錯,比較聰明的人也需要一個月。
換成 go 也不會好很多,await 也能實現(xiàn)同步寫法,而且你依然需要面對我前文提到過的同步控制和資源用量兩個核心問題。
簡單提一下性能分析,py 可以利用 cProfile、line_profiler、memory_profiler、vprof、objgraph 等工具生成耗時、內(nèi)存占用、調(diào)用關(guān)系圖、火焰圖等。
關(guān)于性能分析領(lǐng)域的更多方法論和理念,推薦閱讀《性能之巔》(過去做的關(guān)于性能之巔的部分摘抄 https://twitter.com/ppcelery/status/1051832271001382912)。
必須強調(diào):優(yōu)化必須要有足夠的數(shù)據(jù)支撐,包括優(yōu)化前和優(yōu)化后。
性能優(yōu)化其實是一個非常復(fù)雜的領(lǐng)域,雖然上面提到的工具可以生成各式各樣的看上去就很厲害的圖,但是優(yōu)化不是簡單的你看哪慢就去改哪,而是需要有極其扎實的基礎(chǔ)知識和全局思維的。
而且,上述工具得出的指標(biāo),在性能尚未逼近極限時,可能會有相當(dāng)大的誤導(dǎo)性,使用的時候也要小心。
有一些較為普適的經(jīng)驗:
-
I/O 越少越好,盡量在內(nèi)存里完成
-
內(nèi)存分配越少越好,盡量復(fù)用
-
變量盡可能少,gc 友好
-
盡量提高局部性
-
盡量用內(nèi)建函數(shù),不要輕率造輪子
下列方法如非瓶頸不要輕易用:
-
循環(huán)展開
-
內(nèi)存對齊
-
zero copy(mmap、sendfile)
測試是開發(fā)人員很容易忽視的一個環(huán)節(jié),很多人認為交給 QA 即可,但其實測試也是開發(fā)過程中的一個重要組成部分,不但可以提高軟件的交付質(zhì)量,還可以增進你的代碼組織能力。
最常見的劃分可以稱之為黑盒 & 白盒,前者是只針對接口行為的測試,后者是深入了解實現(xiàn)細節(jié),針對實現(xiàn)方式進行的針對性測試。
對 Py 開發(fā)者而言,最簡單實用的工具就是 unitest.TestCase 和 pytest,在包內(nèi)任何以 test*.py 命名的文件,內(nèi)含 TestCase 類的以 test* 命名的方法都會被執(zhí)行。
測試方法也很簡單,你給定入?yún)ⅲ缓笳{(diào)用想要測試的函數(shù),然后檢查其返回是否符合需求,不符合就拋出異常。
https://docs.pytest.org/en/latest/
- """
- test_demo.py
- """
- from unittest import TestCase
- from typing import List
- def demo(l: List[int]) -> int:
- return l[0]
- class DemoTestCase(TestCase):
- def setUp(self):
- print("first run")
- def tearDown(self):
- print("last run")
- def test_demo(self):
- data =
- self.assertRaises(IndexError, demo, data)
開始寫測試后,你才會意識到你的很多函數(shù)非常難以測試。因為它們可能有嵌套調(diào)用,可能有內(nèi)含狀態(tài),可能有外部依賴等等。
但是需要強調(diào)的是,這不但不是不寫測試的理由,這其實正是寫測試的目的!
通過努力地寫測試,會強迫你開始編寫精簡、功能單一、無狀態(tài)、依賴注入、避免鏈?zhǔn)秸{(diào)用的函數(shù)。
一個簡單直觀的“好壞對比”,鏈?zhǔn)秸{(diào)用的函數(shù)很難測試,它內(nèi)含了太多其他函數(shù)的調(diào)用,一旦測試就變成了一個“集成測試”。而將其按照步驟一一拆分后,就可以對其進行精細化的“單元測試”,這可以契合你開發(fā)的步伐,步步為營穩(wěn)步推進。
- """
- 這是很糟糕的鏈?zhǔn)秸{(diào)用
- """
- def main:
- func1
- def func1:
- return func2
- def func2:
- return func3
- def func3:
- return "shit"
- """
- 這樣寫會好很多
- """
- def step1:
- return "yoo"
- def step2(v):
- return f"hello, {v}"
- def step3(v):
- return f"you know nothing, {v}"
- def main:
- r1 = step1
- r2 = step2(r1)
- step3(r2)
順帶一提,對于一些無法繞開的外部調(diào)用,如網(wǎng)絡(luò)請求、數(shù)據(jù)庫請求。單元測試的準(zhǔn)則之一就是“排除一切外部因素”,你不應(yīng)該發(fā)起任何真正的外部調(diào)用的,因為這會引入不可控的數(shù)據(jù)。正確做法是通過依賴注入 Mock 對象,或者通過 patch 去改寫調(diào)用的接口對象。
以前寫過一篇簡介:https://blog.laisky.com/p/unittest-mock/
單元測試應(yīng)該兼顧黑盒、白盒。你既應(yīng)該編寫面對接口的案例,也應(yīng)該盡可能的試探內(nèi)部的實現(xiàn)路徑(增加覆蓋率)。
你還可以逐漸地把線上遇到的各種 bug 都編寫為案例,這些案例會成為項目寶貴的財富,為回歸測試提供強有力的支持。而且有這么多測試案例提供保護,coding 的時候也會安心很多。
在單元測試的基礎(chǔ)上,人們發(fā)展出了 TDD,但是在實踐的過程中,發(fā)現(xiàn)有些“狡猾的”開發(fā)會針對案例的特例進行編程。為此,人們決定應(yīng)該拋棄形式,回歸本源,從方法論的高度來探尋測試的道路。其中光明一方,就是 PBT,試圖通過描述問題的實質(zhì),來自動生成測試案例。
一篇簡介:https://blog.laisky.com/p/pbt-hypothesis/
另一個黑暗的方向就是 Fuzzing,它干脆完全忽略函數(shù)的實現(xiàn),貫徹黑盒到底,通過遺傳算法,隨機的生成入?yún)ⅲ?i class="chrome-extension-mutihighlight chrome-extension-mutihighlight-style-4">測試到宇宙盡頭的決心,對函數(shù)進行死纏爛打,發(fā)掘出正常人根本想不到猜不著的犄角旮旯里的 bug。













