













10倍!微軟開源史上最大NLG模型,可訓練1000億參數的模型
人工智能的最新趨勢是,更大的自然語言模型可以提供更好的準確性,但是由于成本、時間和代碼集成的障礙,較大的模型難以訓練。
微軟日前開源了一個深度學習優化庫 DeepSpeed,通過提高規模、速度、可用性并降低成本,可以在當前一代的 GPU 集群上訓練具有超過 1000 億個參數的深度學習模型,極大促進大型模型的訓練。同時,與最新技術相比,其系統性能可以提高 5 倍以上。
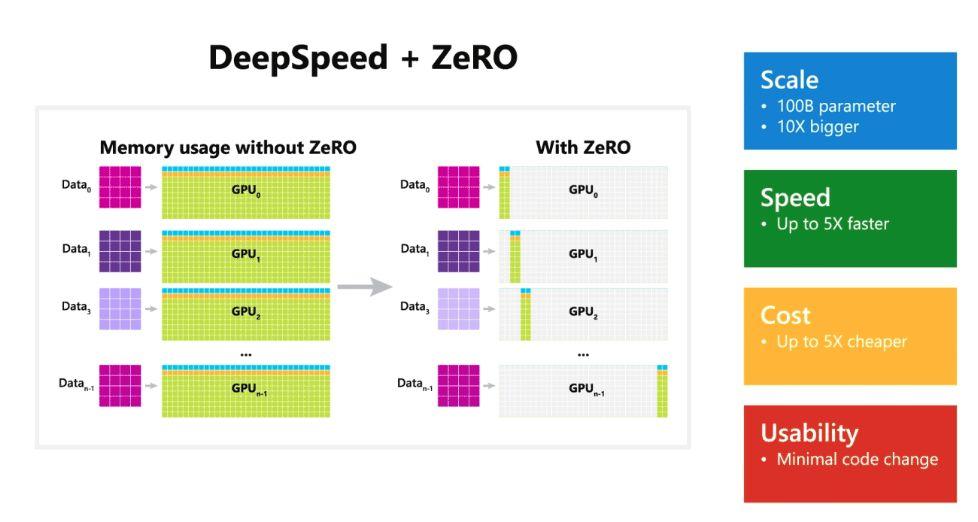
根據微軟的介紹,DeepSpeed 庫中有一個名為 ZeRO(零冗余優化器,Zero Redundancy Optimizer)的組件,這是一種新的并行優化器,它可以大大減少模型和數據并行所需的資源,同時可以大量增加可訓練的參數數量。
研究人員利用這些突破創建了圖靈自然語言生成模型(Turing-NLG),這是最大的公開語言模型,參數為 170 億。
ZeRO 作為 DeepSpeed 的一部分,是一種用于大規模分布式深度學習的新內存優化技術,它可以在當前的 GPU 集群上訓練具有 1000 億個參數的深度學習模型,其吞吐量是當前最佳系統的 3 到 5 倍。它還為訓練具有數萬億個參數的模型提供了一條清晰的思路。
ZeRO 具有三個主要的優化階段,分別對應于優化器狀態、梯度和參數分區。
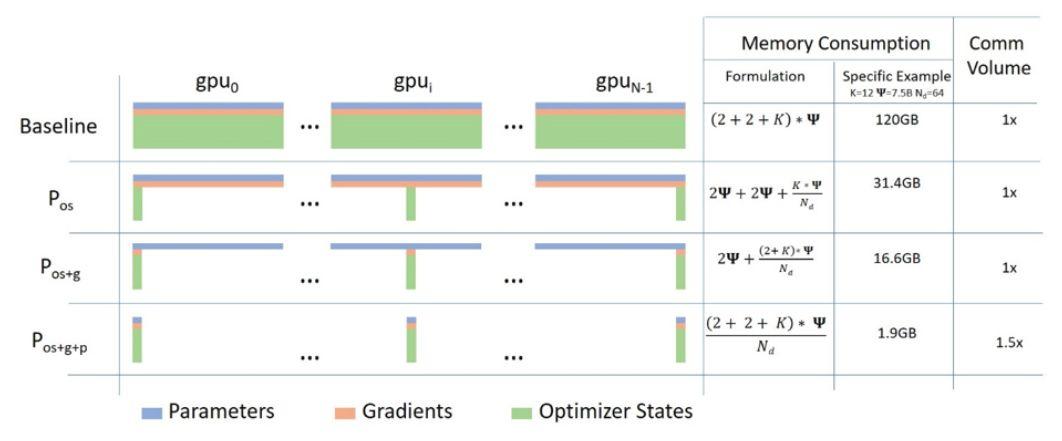
ZeRO 克服了數據并行和模型并行的局限性,同時實現兩者的優點,它通過跨數據并行進程將模型狀態劃分為上圖所示的參數、梯度和優化器狀態分區,而不是復制它們,從而消除了數據并行進程之間的內存冗余。
在訓練期間使用動態通信規劃(dynamic communication schedule),在分布式設備之間共享必要的狀態,以保持數據并行的計算粒度和通信量。
目前實施了 ZeRO 的第一階段,即優化器狀態分區(簡稱 ZeRO-OS),具有支持 1000 億參數模型的強大能力,此階段與 DeepSpeed 一起發布。
DeepSpeed 與 PyTorch 兼容,DeepSpeed API 是在 PyTorch 上進行的輕量級封裝,這意味著開發者可以使用 PyTorch 中的一切,而無需學習新平臺。此外,DeepSpeed 管理著所有樣板化的 SOTA 訓練技術,例如分布式訓練、混合精度、梯度累積和檢查點,開發者可以專注于模型開發。
同時,開發者僅需對 PyTorch 模型進行幾行代碼的更改,就可以利用 DeepSpeed 獨特的效率和效益優勢來提高速度和規模。
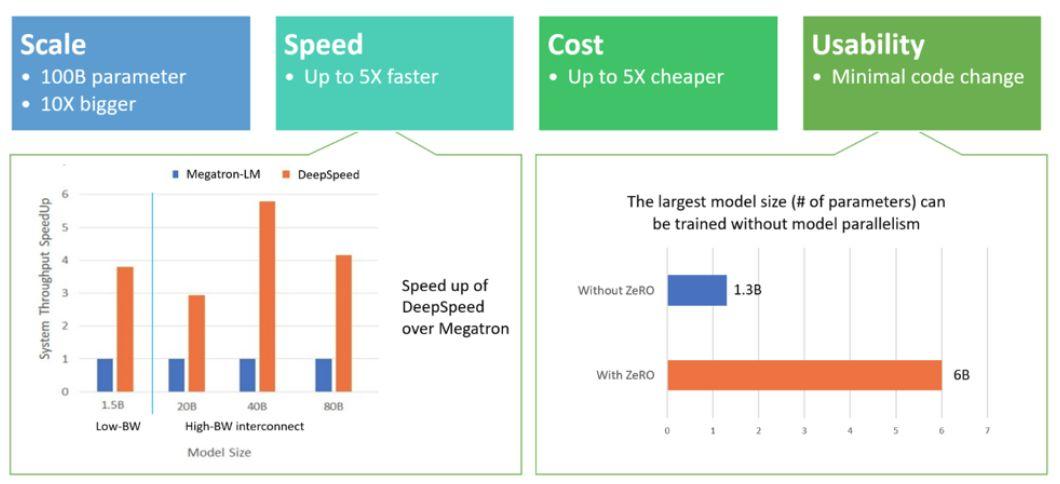
DeepSpeed 在以下四個方面都表現出色:
規模:目前最先進的大型模型,例如 OpenAI GPT-2、NVIDIA Megatron-LM 和 Google T5,分別具有 15 億、83 億和 110 億個參數,而 DeepSpeed 的 ZeRO 第一階段提供系統支持,以運行多達 1000 億個參數的模型,這是比當前最先進的模型大 10 倍。
未來計劃增加對 ZeRO 第二和第三階段的支持,從而提供高達 2000 億個乃至數萬億個參數的模型的能力。
速度:在各種硬件上,目前觀察到的吞吐量比當前最先進技術高出 5 倍。例如,為了在 GPT 系列工作負載上訓練大型模型,DeepSpeed 將基于 ZeRO 的數據并行與 NVIDIA Megatron-LM 模型并行相結合,在具有低帶寬互連的 NVIDIA GPU 集群上(沒有 NVIDIA NVLink 或 Infiniband),與僅對具有 15 億參數的標準 GPT-2 模型使用 Megatron-LM 相比,DeepSpeed 將吞吐量提高了 3.75 倍。
在具有高帶寬互連的 NVIDIA DGX-2 集群上,對于 20 至 800 億個參數的模型,速度要快 3 到 5 倍。這些吞吐量的提高來自 DeepSpeed 更高的內存效率以及使用較低程度的模型并行和較大的批處理量來擬合這些模型的能力。
成本:提高吞吐量意味著大大降低訓練成本,例如,要訓練具有 200 億個參數的模型,DeepSpeed 需要的資源是原來的 3/4。
易用性:只需更改幾行代碼即可使 PyTorch 模型使用 DeepSpeed 和 ZeRO。與當前的模型并行庫相比,DeepSpeed 不需要重新設計代碼或重構模型,它也沒有對模型尺寸、批處理大小或任何其它訓練參數加以限制。
對于參數多達 60 億的模型,可以方便地使用由 ZeRO 提供的數據并行能力,而無需模型并行。而相比之下,對于參數超過 13 億的模型,標準數據并行將耗盡內存。ZeRO 第二和第三階段將進一步增加僅通過數據并行即可訓練的模型大小。此外,DeepSpeed 支持 ZeRO 支持的數據并行與模型并行的靈活組合。
最后附上GitHub地址:https://github.com/microsoft/DeepSpeed



























