分布式系統的時間問題
序
一些技術點仿佛俯拾皆是,但很少有時間有精力把他們串起來形成體系,進而系統性地理解它們。象多人共著《深入分布式緩存》那樣多角度認識緩存技術并不多見,“臨淵羨魚,不如退而結網”,石頭兄弟的這篇關于時間的文字成于去年,歷久反而彌新。
目錄
1 什么是時間?
2 物理時間:墻上時鐘
3 邏輯時鐘:為事件定序
4 Turetime:物理時鐘回歸
5 區塊鏈:重新定義時間
6 其他影響
6.1 NTP的時間同步
6.2 有限時間內的不可能性
6.3 延遲
6.4 租約
7 總結
8 參考文獻
1 什么是時間?
時間是困擾了無數哲人的一個很抽象的概念。
偉人牛頓的絕對時空原理,可能代表了多數人的觀點——時間在整個宇宙中是一個不變常量:
- 在牛頓的時空觀念中,時間和空間是各自獨立的,沒有關聯的兩個事物。
- 絕對空間就像一間空房子,它區分物理事件發生的地點,用3維坐標來描述。
- 絕對時間就像一個滴答作響的秒表,它區別物理事件發生的先后次序,用不可逆轉的1維坐標來描述。
“牛頓以為他知道時間是什么”——有人調侃說。在牛頓的絕對時空里,時間的概念是恒定的,在整個宇宙中是一致的,時間是度量事件先后的依據。這非常像我們的一個單一計算機或者緊耦合的計算機集群里,時間是明確的,事件進行的順序也是明確的。在計算機科學最初的幾十年里,我們從來沒有想過計算機之間的時間問題。
另一位科學巨匠愛因斯坦,在他的狹義相對論中,主要有兩點:
- ? 物理定律,包括時間,對所有的觀察者來說是相同的。
- ? 光速不變。
而廣義相對論說,整個時空都是一個引力場,時間和空間都不是連續的。
狹義相對論的主要意義是沒有概念上的同時性,同時的概念相對于觀察者,時間的推移也相對于觀察者。同時,這一理論也說明了當事情發生在遙遠的地方,我們需要時間去發現事情是否真的發生了。這個等待的時間可能很長。
分布式系統可能比愛因斯坦的宇宙還要糟糕。在分布式系統中,信息傳播所需要的時間范圍是不可預知的,可能遠超過了陽光到達地球的8分鐘。在這段時間內,無法知道網絡另一端的計算機發生了什么。就算你可以通過發送消息來詢問或探測,消息的投遞和反饋總是要花費時間的。因此,系統延遲時間和超時值的設置是分布式系統的重要設計點之一。
“一切抽象都是數學,一切結論都是概率”,我們可以獲得一個信息傳播的統計結果,但無法知道每一次消息投遞的準確時間。從這個角度上理解,分布式系統的正確運行都是運氣很好的概率上,概率小到我們認為是高可靠的。
關于時間的本質,馬赫(Ernst Mach)說:我們根本沒有能力以時間來測量事物的變化,相反的,我們是透過事物的變化因而產生時間流動的抽象概念。
在《七堂極簡物理課》中,作者指出:只有存在熱量的時候,過去和未來才有區別。能將過去和未來區分開來的基本現象就是熱量總是從熱的物體跑到冷的物體上。
所以,愛因斯坦說時間是幻像。從文學意義上說,不是時間定義了我們的生命,而是我們的生命定義了時間。
或許,這就是我們放棄物理時鐘,使用邏輯時鐘的背景吧!
2 物理時間:墻上時鐘
物理時間,在英文文獻中也稱為wall clock。wall time,也稱為真實世界的時間或掛鐘時間,是指由鐘表或掛鐘等計時器確定的經過時間。(“wall”一詞最初得名于對掛鐘的引用。)
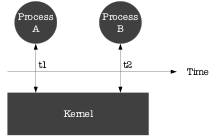
在計算機的世界里,中心化系統的時間是明確的。例如進程A和B分別在t1,t2時刻向系統的內核發起獲得時間的系統調用,得到時間必然是t1
? ?
?
單機系統中的時間依賴于石英鐘,并且具有極小的時鐘漂移。
3 邏輯時鐘:為事件定序
分布式系統中的同步和異步都是對物理時間做的假設,但是,邏輯時鐘第一次擺脫了物理時鐘的限制。
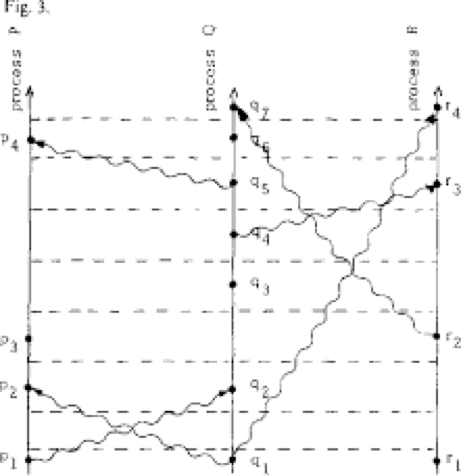
邏輯時鐘認為分布式系統中的機器可以無法對時間達成一致,但是對時間發生順序是一致認同的。一個消息不能在被發送之前收到,這樣,如果一個進程A向進程B發送了消息,我們可以認為A發生在B之前。
? ?
?
這樣就定義了分布式系統中不同節點上不同事件之間的因果關系,后來衍生的向量時鐘也是同樣的道理。
本質上來說,邏輯時鐘定義了事件到整數值的映射。所以很多邏輯時鐘的實現都采用單調遞增的軟件計數器,這個計數器的值與任何物理時鐘都沒有關系。分布式系統中的節點和進程在使用邏輯時鐘時,為事件加上邏輯時鐘的時間戳,比如文件讀寫和數據庫更新等。
邏輯時鐘的貢獻來自于Leslie Lamport在1978年發表的一篇論文《Time, Clocks, and the Ordering of Events in a Distributed System》。
? ?
?
4 Truetime:物理時鐘回歸
Google的Spanner提出了一種新的思路,在不進行通信的情況下,利用高精度和可觀測誤差的本地時鐘 (TrueTime API)給事件打上時間戳,并且以此比較分布式系統中兩個事件的先后順序。利用這個方法,Spanner實現了事務之間的外部一致性(external consistency,如下圖所示)。
? ?
?
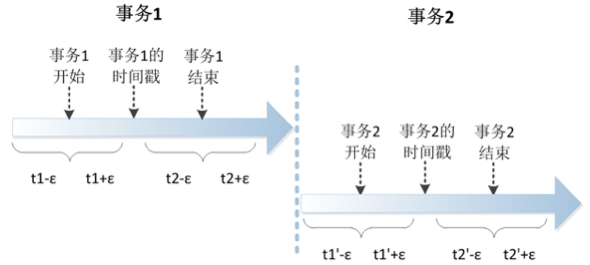
也就是說,一個事務結束后另一個事務才開始,Spanner可以保證第一個事務的時間戳比第二個事務的時間戳要早,從而兩個事務被序列化后也一定能保持正確的順序。
TrueTime API是一個提供本地時間的接口,但與Linux上gettimeofday接口不一樣,它除了可以返回一個時間戳t,還會給出一個誤差ε。例如,返 回的時間戳是1分30秒350毫秒,而誤差是5毫秒,那么真實的時間在1分30秒345毫秒到355毫秒之間。真實的系統中ε平均下來是4毫秒。
利用TrueTime API,Spanner可以保證給出事務標記的時間戳介于事務開始的真實時間和事務結束的真實時間之間。假如事務開始時TrueTime API返回的時間是{t1, ε1},此時真實時間在 t1-ε1到t1+ε1之間;事務結束時TrueTime API返回的時間是{t2, ε2},此時真實時間在t2-ε2到t2+ε2之間。Spanner會在t1+ε1和t2-ε2之間選擇一個時間點作為事務的時間戳,但這需要保證 t1+ε1小于t2-ε2,為了保證這點,Spanner會在事務執行過程中等待,直到t2-ε2大于t1+ε1時才提交事務。由此可以推導出,Spanner中一個事務至少需要2ε的時間(平均8毫秒)才能完成。
由此可見,這種新方法雖然避免了通信開銷,卻引入了等待時間。為了保證外部一致性,寫延遲是不可避免的,這也印證了CAP定理所揭示的法則,一致性與延遲之間是需要權衡的。
? ?
?
為什么Google要采用這樣設計呢?
Truetime根本上解決了什么問題?
Spanner是要解決全球規模分布式系統中關于時間的兩大難題:
- 在數據中心之間同步時間是超級困難和不確定的
- 在全球規模范圍內序列化請求是不可能的
解決這些問題的辦法是接受不確定性,使用GPS和原子時鐘,把不確定性減低到最小。對于 Spanner這樣全球部署或者跨地域部署的系統,如何來為事務分配 timestamp, 才能保證系統的響應時間在可接受的范圍內? 如果整個系統采用一個中心節點來分配時間戳, 那么系統的響應時間就變得非常不可控,對于離中心節點隔了半圈地球的用戶來說, 響應時間估計會是100ms 級別。
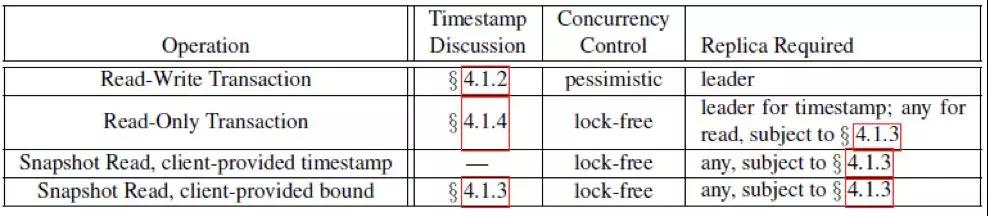
如何理解turetime 呢?要弄明白truetime在事務操作中作用,首先看一下Spanner支持的幾種事務類型:
? ?
?
簡單只讀事務。Spanner設計的只讀事務有以下要求:
? 客戶程序自己實現重試動作
? 讀操作要顯式的聲明沒有寫(例如只讀打開一個文件)
? 系統無需獲得鎖,不阻塞讀過程中進來的寫操作
? 系統自己選擇一個時間戳,用來確定讀取副本的時間戳
? 任何一個滿足時間戳的副本都可以用作讀操作
當然,快照讀就更簡單了,無鎖的讀取過去的快照,客戶可以指定時間戳,也可以讓系統選擇一個時間戳,無需贅述。
讀寫事務則使用兩階段鎖,來保證外部一致性:
?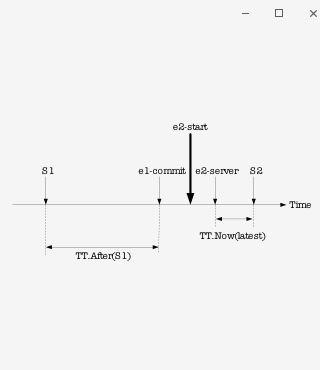 ?
?
Spanner 利用truetime機制,把系統中的操作按照發生的先后順序,構造一個 Linearizability 的運行記錄。所以,我們說Spanner是實現Linearizability的系統。
總結來說,Spanner 是采用全球同步(有一定誤差)的物理時間truttime戳作為系統的時間戳,并且作為系統內各種操作的版本號。
5 區塊鏈:重新定義時間
中本聰在比特幣一文——《Bitcoin: A Peer-to-Peer Electronic Cash System》中提出了時間戳服務器模型,并奠定了區塊鏈的基礎。為了解決雙花問題,中本聰設想了一個去中心化的自驗證體系:
在基于鑄幣的模型中,鑄幣方知道所有的交易并決定哪個先到達。要在沒有可信方的情況下完成此任務,必須公開宣布交易,并且我們需要一個系統,讓參與者就接收它們的順序的單一歷史記錄達成共識。收款人需要一個證明:對于一個交易,大多數節點都同意該交易是第一個收到的。
我們建議的解決方案是從時間戳服務器開始的。時間戳服務器的工作方式是獲取要加蓋時間戳的數據塊的散列,并廣泛地發布散列,就像在報紙或Usenet post上發布一樣。顯然,時間戳證明了數據必須在那個時候存在,以便進入散列。每個時間戳散列包含前一個時間戳的散列,由此形成一個鏈,每個后續的時間戳都會增強前一個時間戳的有效性。
? ?
?
這樣,區塊鏈作為時間機器的滴答機制就形成了,一個區塊高度對應一個時間窗口,這是為什么區塊鏈也被稱為時間機器的原因。為了讓時鐘跳動均勻,POW區塊鏈會自動調整算法難度,維持滴答周期在一個平均的物理時間范圍內,比如比特幣是在10分鐘左右,以太坊在15秒左右。非POW的區塊鏈也維護這樣的時鐘滴答,比如filecoin測試網維護在45秒左右。
進一步,非POW的區塊鏈維護固定的時鐘滴答是很難的,再以filecoin為例,采用在全網采用UTC時間戳(類似前面谷歌的做法)來實現固定的物理時間間隔,這要求全網的服務器都和NTP服務器同步,并限制了嚴格的時鐘飄移范圍(1s)。因為區塊鏈這樣的時間機器特性,才讓鏈上的數據在沒有分叉的情況下無法篡改。也正因為這樣,區塊鏈才讓人聯想到物理時間的消逝,熵的增加,能量的耗散,以及“青春散場、昨日不再”。
? ?
?
由區塊鏈的本質引申開來,研究者試圖找到替代的解決方案。其中一個非常有吸引力的方案是VDF。VDF是 Verifiable Delay Function的縮寫,可驗證延遲函數VDF的概念是斯坦福大學計算機科學和電子工程教授、計算機安全實驗室聯合主任Dan Boneh在Crypto 2018大會發布的《Verifiable Delay Functions》論文中首次提出的。Function說明了VDF是一個函數,對每一個輸入都有一個唯一的輸出。Delay 可以用一個時間T(wall time)來表示,延遲函數在時間T完成計算,但不能通過并行加速在小于時間T完成計算。Verifiable 要求延遲函數的輸出非常容易驗證。詳細請閱讀《Paxos、PoW、VDF:一條美麗的黃金線》一文。
Function:
§ unique output for everyinput
Delay:
§ can be evaluated in time T
§ can not be evaluated intime
Verifiable:
?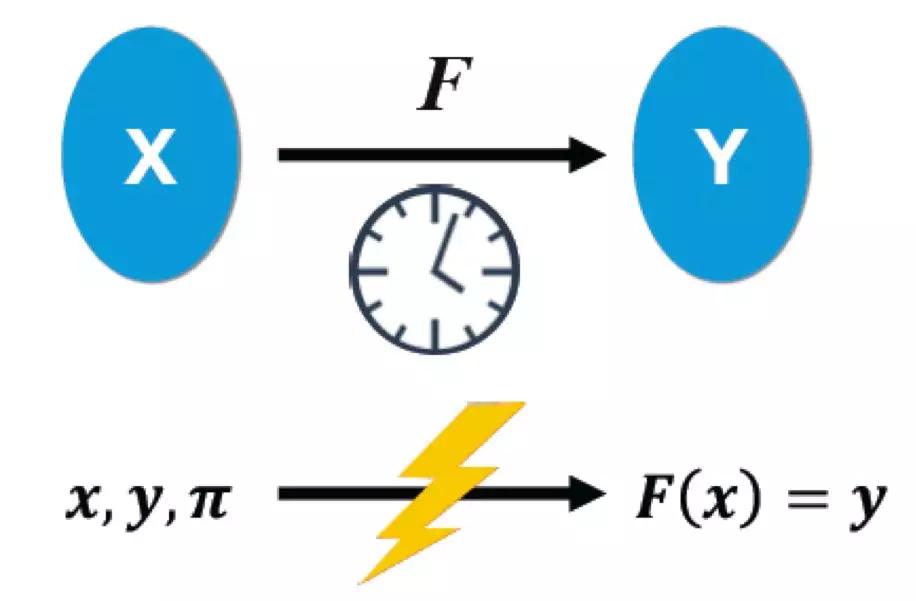 ?
?
VDF計算過程最重要的一點是:在計算時要求大量計算資源,但驗證時只需花費相對少的計算資源。這樣的計算和驗證的非對稱關系乍看起來有點像工作量證明(PoW)。于是,批評接踵而至:“ 聽起來我們又回到了工作量證明 ”,“ 不再燒一輪 CPU 我們就干不了這事是嗎 ?”——文獻《VDF不是工作量證明》一文指出:雖然 VDF 和傳統的 PoW 算法都擁有“難以計算”且“易于驗證”這樣的屬性,最核心的區別在于,區塊鏈工作量證明的共識算法是可并行化的工作量證明,并且只是有概率會成功,不是一種函數。相反,VDF 是連續工作量證明,是確定的函數。
關于VDF和PoW的區別,已有很多爭論。總體來說,PoW 直接作為隨機數的來源是有缺陷的,同時,VDF 也無法直接替代 PoW。但是,這并不能說明 VDF 不可以被用到共識協議里。原因如下:
? PoW 不抵抗并行計算加速而 VDF 是抵抗的。實際上,PoW 不抗并行計算加速是符合中本聰關于“一個 CPU 一票”的設想的,而抗并行加速的性質只會與這個目的背道而馳。VDF 會使得多 CPU 的計算者和單 CPU 的計算者相比幾乎沒有什么優勢。
? 對于固定的難度設定 d,PoW 可以有很多合法的解,這也是保證 PoW 共識網絡擁有穩定的吞吐量以及刺激礦工進行競爭的前提。而對于給定輸入 x,VDF 擁有唯一的輸出(這也是為什么它被稱作函數)。
總體來說,VDF很好的刻畫了區塊鏈對于時間滴答機制的本質需求。在一些非PoW區塊鏈和非區塊鏈的領域,都有大量研究和探索,比如協議實驗室和以太坊聯合成立的實驗室,以及大量對VDF感興趣的項目。
注:filecoin的協議實現也在考慮VDF:
Future versions of the Filecoin protocol may use Verifiable Delay Functions (VDFs) to strongly enforce block time and fulfill this leader election requirement; we choose to explicitly assume clock synchrony until hardware VDF security has been proven more extensively.
? ?
?
6 其他影響
和影響人們的生活一樣,時間更是影響了計算機系統的方方面面,也自然影響了我們。
6.1 NTP的時間同步
在分布式系統中,關于時間的共識是非常困難的。不同機器中石英鐘的頻率可能不一致,這會導致不同機器中時間并不一致。為了同步不同機器中的時間,人們提出了NTP協議。這樣,一個機器的時間就會依賴于另外一個外部時鐘。
?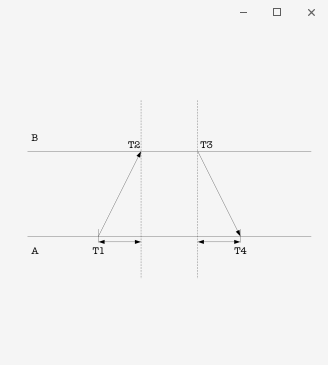 ?
?
NTP協議基于這樣原理:網絡通信延遲來回是相等的。基于此可以獲得兩臺機器時間差值 。在NTP服務器(上)獲得的時間再加上(時間落后本機)或減去(時間領先本機)這個延遲就可以設置為本地的時間,由此獲得時間同步。
6.2 有限時間內的不可能性
1985年,Fischer,Lynch和Patterson發布了他們著名FLP成果(Impossibility of distributed consensus with one faulty process):在異步的系統中,如果存在進程故障,系統是不可能達成一致的。FLP表明,當至少有一個進程可能崩潰時,沒有一種確定性地解決異步環境中共識問題的算法。在工程應用中,這個理論也可以理解為:在不穩定故障的異步系統中,不可能有一個完美的故障檢測器。
根本的原因在于時間。FLP結果并不意味著共識是無法達到的,只是在有限的時間內并不總是可以達到的。同步系統在進程和進程計算之間為消息傳遞提供了一個已知的上限。異步系統沒有固定的上限。
在《分布式系統:概念與設計》一書中,作者針對FLP指出:在分布式系統中,并不是說,如果有一個進程出現了故障,進程就永遠不可能達到共識。它允許我們達到共識的概率大于0,這也是與實際情況相符合的。例如現在運行在廣域網上的分布式系統,都是異步的,但是事務系統這么多年來一直都能達到共識。
所以,FLP表述為:在有限的時間內,不可能達成一致。系統可能或者極有可能達成一致,但這不是保證的。也就是說, 在異步的系統中,有限時間內達到一致性是不可能的。在分布式計算上,試圖在異步系統和不可靠的通道上達到一致性是不可能的。
因此,一般的一致性前提都是要求保證:在這里我們不考慮拜占庭類型的錯誤,同時假設消息系統是可靠的。因此,對一致性的研究一般假設信道是可靠的,或不存在異步系統在運行。
概率,深刻的影響著分布式系統可靠性。世界的概率本質雖然不能讓我們準確的推斷未來,但是對于預測消息是否準確傳遞卻綽綽有余。想一想,我們知道在有限時間內達到絕對的一致性是不可能的,那為什么程序員自信的設置超時值為5秒呢?
就像這個世界的概率本質一樣,分布式系統同樣構建在概率的基礎之上。
6.3 延遲
很多人把延遲歸類到網絡延遲,指數據在傳輸介質中傳輸所用的時間,即從報文開始進入網絡到它開始離開網絡之間的時間。實際上,在計算機世界里,延遲無所不在。
除了VDF之外,程序員可能還要知道下面的這些時間數字:
- L1 cache reference ......................... 0.5 ns
- Branch mispredict ............................ 5 ns
- L2 cache reference ........................... 7 ns
- Mutex lock/unlock ........................... 25 ns
- Main memory reference ...................... 100 ns
- Compress 1K bytes with Zippy ............. 3,000 ns = 3 μs
- Send 2K bytes over 1 Gbps network ....... 20,000 ns = 20 μs
- SSD random read ........................ 150,000 ns = 150 μs
- Read 1 MB sequentially from memory ..... 250,000 ns = 250 μs
- Round trip within same datacenter ...... 500,000 ns = 0.5 ms
- Read 1 MB sequentially from SSD* ..... 1,000,000 ns = 1 ms
- Disk seek ........................... 10,000,000 ns = 10 ms
- Read 1 MB sequentially from disk .... 20,000,000 ns = 20 ms
- Send packet CA->Netherlands->CA .... 150,000,000 ns = 150 ms
- ......
6.4 租約
租約(lease)在分布式系統中的一般描述如下:
- 租約是由授權者授予的在一段時間內的承諾。
- 授權者一旦發出租約,則無論接受方是否收到,也無論后續接收方處于何種狀態,只要租約 不過期,授權者一定遵守承諾,按承諾的時間、內容執行。
- 接收方在有效期內可以使用授權者的承諾,只要租約過期,接收方將放棄授權,不再繼續執行,如果重新執行需要重新申請租約。
- 通過版本號、時間周期,或者到某個固定時間點認為租約的證書失效
租約可以說是分布式系統的心跳機制。在分布式系統中,像分布式鎖,集群leader這樣角色,可能隨時變化。為了避免死鎖,或者錯誤的leader認知,一般都要設計租約機制。
7 總結
本文主要回顧了計算機系統演進過程中的時間問題,特別是古典分布式系統的時間問題,以及由時間帶來的順序問題;探討了最新支持拜占庭容錯的區塊鏈網絡系統的時間本質,以及在可驗證延遲函數方面的最新探索。
目前的分布式系統無法超越時空的限制來運行,系統的設計也受到時空考慮范圍的約束。而未來,量子計算機將會在時空約束方面帶來哪些改變,值得期待。