3行代碼提速模型訓(xùn)練:這個(gè)算法讓你的GPU老樹(shù)開(kāi)新花
百度和Nvidia研究院結(jié)合N卡底層計(jì)算優(yōu)化,提出了一種有效的神經(jīng)網(wǎng)絡(luò)訓(xùn)練加速方法,不僅是預(yù)訓(xùn)練,在全民finetune BERT的今天變得異常有用。
一切還要從2018年ICLR的一篇論文說(shuō)起。
《MIXED PRECISION TRAINING》是百度&Nvidia研究院一起發(fā)表的,結(jié)合N卡底層計(jì)算優(yōu)化,提出了一種灰常有效的神經(jīng)網(wǎng)絡(luò)訓(xùn)練加速方法,不僅是預(yù)訓(xùn)練,在全民finetune BERT的今天變得異常有用哇。
而且調(diào)研發(fā)現(xiàn),不僅百度的paddle框架支持混合精度訓(xùn)練,在Tensorflow和Pytorch中也有相應(yīng)的實(shí)現(xiàn)。下面我們先來(lái)講講理論,后面再分析混合精度訓(xùn)練在三大深度學(xué)習(xí)框架中的打開(kāi)方式。
理論原理
訓(xùn)練過(guò)神經(jīng)網(wǎng)絡(luò)的小伙伴都知道,神經(jīng)網(wǎng)絡(luò)的參數(shù)和中間結(jié)果絕大部分都是單精度浮點(diǎn)數(shù)(即float32)存儲(chǔ)和計(jì)算的,當(dāng)網(wǎng)絡(luò)變得超級(jí)大時(shí),降低浮點(diǎn)數(shù)精度,比如使用半精度浮點(diǎn)數(shù),顯然是提高計(jì)算速度,降低存儲(chǔ)開(kāi)銷的一個(gè)很直接的辦法。
然而副作用也很顯然,如果我們直接降低浮點(diǎn)數(shù)的精度直觀上必然導(dǎo)致模型訓(xùn)練精度的損失。但是呢,天外有天,這篇文章用了三種機(jī)制有效地防止了模型的精度損失。待小夕一一說(shuō)來(lái)o(* ̄▽ ̄*)ブ
權(quán)重備份(master weights)
我們知道半精度浮點(diǎn)數(shù)(float16)在計(jì)算機(jī)中的表示分為1bit的符號(hào)位,5bits的指數(shù)位和10bits的尾數(shù)位,所以它能表示的最小的正數(shù)即2^-24(也就是精度到此為止了)。當(dāng)神經(jīng)網(wǎng)絡(luò)中的梯度灰常小的時(shí)候,網(wǎng)絡(luò)訓(xùn)練過(guò)程中每一步的迭代(灰常小的梯度 ✖ 也黑小的learning rate)會(huì)變得更小,小到float16精度無(wú)法表示的時(shí)候,相應(yīng)的梯度就無(wú)法得到更新。
論文統(tǒng)計(jì)了一下在Mandarin數(shù)據(jù)集上訓(xùn)練DeepSpeech 2模型時(shí)產(chǎn)生過(guò)的梯度,發(fā)現(xiàn)在未乘以learning rate之前,就有接近5%的梯度直接悲劇的變成0(精度比2^-24還要高的梯度會(huì)直接變成0),造成重大的損失呀/(ㄒoㄒ)/~~
還有更難的,假設(shè)迭代量逃過(guò)一劫準(zhǔn)備奉獻(xiàn)自己的時(shí)候。。。由于網(wǎng)絡(luò)中的權(quán)重往往遠(yuǎn)大于我們要更新的量,當(dāng)?shù)啃∮贔loat16當(dāng)前區(qū)間內(nèi)能表示的最小間隔的時(shí)候,更新也會(huì)失敗(哭瞎┭┮﹏┭┮我怎么這么難鴨)
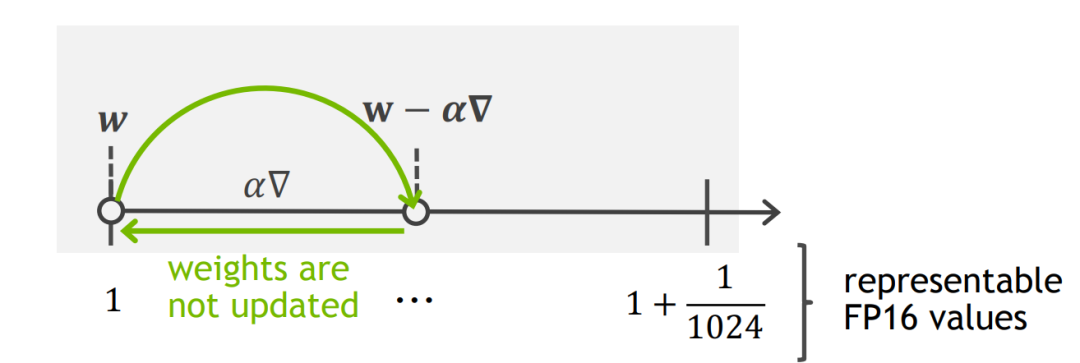
所以怎么辦呢?作者這里提出了一個(gè)非常simple but effective的方法,就是前向傳播和梯度計(jì)算都用float16,但是存儲(chǔ)網(wǎng)絡(luò)參數(shù)的梯度時(shí)要用float32!這樣就可以一定程度上的解決上面說(shuō)的兩個(gè)問(wèn)題啦~~~
我們來(lái)看一下訓(xùn)練曲線,藍(lán)色的線是正常的float32精度訓(xùn)練曲線,橙色的線是使用float32存儲(chǔ)網(wǎng)絡(luò)參數(shù)的learning curve,綠色滴是不使用float32存儲(chǔ)參數(shù)的曲線,兩者一比就相形見(jiàn)絀啦。
損失放縮(loss scaling)
有了上面的master weights已經(jīng)可以足夠高精度的訓(xùn)練很多網(wǎng)絡(luò)啦,但是有點(diǎn)強(qiáng)迫癥的小夕來(lái)說(shuō)怎么還是覺(jué)得有點(diǎn)不對(duì)呀o((⊙﹏⊙))o.
雖然使用float32來(lái)存儲(chǔ)梯度,確實(shí)不會(huì)丟失精度了,但是計(jì)算過(guò)程中出現(xiàn)的指數(shù)位小于 -24 的梯度不還是會(huì)丟失的嘛!相當(dāng)于用漏水的篩子從河邊往村里運(yùn)水,為了多存點(diǎn)水,村民們把儲(chǔ)水的碗換成了大缸,燃鵝篩子依然是漏的哇,在路上的時(shí)候水就已經(jīng)漏的木有了。。
于是loss scaling方法來(lái)了。首先作者統(tǒng)計(jì)了一下訓(xùn)練過(guò)程中激活函數(shù)梯度的分布情況,由于網(wǎng)絡(luò)中的梯度往往都非常小,導(dǎo)致在使用FP16的時(shí)候右邊有大量的范圍是沒(méi)有使用的。這種情況下, 我們可以通過(guò)放大loss來(lái)把整個(gè)梯度右移,減少因?yàn)榫入S時(shí)變?yōu)?的梯度。
那么問(wèn)題來(lái)了,怎么合理的放大loss呢?一個(gè)最簡(jiǎn)單的方法是常數(shù)縮放,把loss一股腦統(tǒng)一放大S倍。float16能表示的最大正數(shù)是2^15*(1+1-2^-10)=65504,我們可以統(tǒng)計(jì)網(wǎng)絡(luò)中的梯度,計(jì)算出一個(gè)常數(shù)S,使得最大的梯度不超過(guò)float16能表示的最大整數(shù)即可。
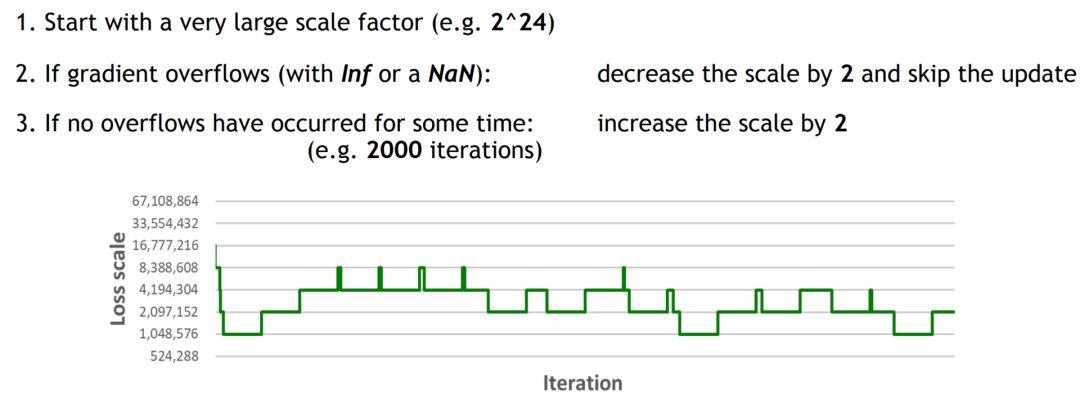
當(dāng)然啦,還有更加智能的動(dòng)態(tài)調(diào)整(automatic scaling) o(* ̄▽ ̄*)ブ
我們先初始化一個(gè)很大的S,如果梯度溢出,我們就把S縮小為原來(lái)的二分之一;如果在很多次迭代中梯度都沒(méi)有溢出,我們也可以嘗試把S放大兩倍。以此類推,實(shí)現(xiàn)動(dòng)態(tài)的loss scaling。
運(yùn)算精度(precison of ops)
精益求精再進(jìn)一步,神經(jīng)網(wǎng)絡(luò)中的運(yùn)算主要可以分為四大類,混合精度訓(xùn)練把一些有更高精度要求的運(yùn)算,在計(jì)算過(guò)程中使用float32,存儲(chǔ)的時(shí)候再轉(zhuǎn)換為float16。
- matrix multiplication: linear, matmul, bmm, conv
- pointwise: relu, sigmoid, tanh, exp, log
- reductions: batch norm, layer norm, sum, softmax
- loss functions: cross entropy, l2 loss, weight decay
像矩陣乘法和絕大多數(shù)pointwise的計(jì)算可以直接使用float16來(lái)計(jì)算并存儲(chǔ),而reductions、loss function和一些pointwise(如exp,log,pow等函數(shù)值遠(yuǎn)大于變量的函數(shù))需要更加精細(xì)的處理,所以在計(jì)算中使用用float32,再將結(jié)果轉(zhuǎn)換為float16來(lái)存儲(chǔ)。
總結(jié):三大深度學(xué)習(xí)框架的打開(kāi)方式
混合精度訓(xùn)練做到了在前向和后向計(jì)算過(guò)程中均使用半精度浮點(diǎn)數(shù),并且沒(méi)有像之前的一些工作一樣還引入額外超參,而且重要的是,實(shí)現(xiàn)非常簡(jiǎn)單卻能帶來(lái)非常顯著的收益,在顯存half以及速度double的情況下保持模型的精度,簡(jiǎn)直不能再厲害啦。
看完了硬核技術(shù)細(xì)節(jié)之后,我們趕緊來(lái)看看代碼實(shí)現(xiàn)吧!如此強(qiáng)大的混合精度訓(xùn)練的代碼實(shí)現(xiàn)不要太簡(jiǎn)單了吧😮
Pytorch
導(dǎo)入Automatic Mixed Precision (AMP),不要998不要288,只需3行無(wú)痛使用!
- from apex import ampmodel, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 這里是“歐一”,不是“零一”with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()
來(lái)看個(gè)例子,將上面三行按照正確的位置插入到自己原來(lái)的代碼中就可以實(shí)現(xiàn)酷炫的半精度訓(xùn)練啦!
- import torchfrom apex import ampmodel = ... optimizer = ...#包裝model和optimizermodel, optimizer = amp.initialize(model, optimizer, opt_level="O1")for data, label in data_iter: out = model(data) loss = criterion(out, label) optimizer.zero_grad() #loss scaling,代替loss.backward() with amp.scaled_loss(loss, optimizer) as scaled_loss:scaled_loss.backward() optimizer.step()
Tensorflow
一句話實(shí)現(xiàn)混合精度訓(xùn)練之修改環(huán)境變量,在python腳本中設(shè)置環(huán)境變量
- os.environ[ TF_ENABLE_AUTO_MIXED_PRECISION ] = 1
除此之外,也可以用類似pytorch的方式來(lái)包裝optimizer。
Graph-based示例
- opt = tf.train.AdamOptimizer()#add a lineopt = tf.train.experimental.enable_mixed_precision_graph_rewrite( opt, loss_scale= dynamic ) train_op = opt.miminize(loss)
Keras-based示例
- opt = tf.keras.optimizers.Adam()#add a lineopt = tf.train.experimental.enable_mixed_precision_graph_rewrite( opt, loss_scale= dynamic ) model.compile(loss=loss, optimizer=opt)model.fit(...)
PaddlePaddle
一句話實(shí)現(xiàn)混合精度訓(xùn)練之添加config(驚呆🙃畢竟混合精度訓(xùn)練是百度家提出的,內(nèi)部早就熟練應(yīng)用了叭)
- --use_fp16=true
舉個(gè)栗子,基于BERT finetune XNLI任務(wù)時(shí),只需在執(zhí)行時(shí)設(shè)置use_fp16為true即可。
- export FLAGS_sync_nccl_allreduce=0export FLAGS_eager_delete_tensor_gb=1export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7BERT_BASE_PATH="chinese_L-12_H-768_A-12"TASK_NAME= XNLI DATA_PATH=/path/to/xnli/data/CKPT_PATH=/path/to/save/checkpoints/python -u run_classifier.py --task_name ${TASK_NAME} --use_fp16=true #!!!!!!add a line --use_cuda true --do_train true --do_val true --do_test true --batch_size 32 --in_tokens false --init_pretraining_params ${BERT_BASE_PATH}/params --data_dir ${DATA_PATH} --vocab_path ${BERT_BASE_PATH}/vocab.txt --checkpoints ${CKPT_PATH} --save_steps 1000 --weight_decay 0.01 --warmup_proportion 0.1 --validation_steps 100 --epoch 3 --max_seq_len 128 --bert_config_path ${BERT_BASE_PATH}/bert_config.json --learning_rate 5e-5 --skip_steps 10 --num_iteration_per_drop_scope 10 --verbose true