數(shù)據(jù)太少怎么辦?試試自監(jiān)督學(xué)習(xí),CV訓(xùn)練新利器
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
數(shù)據(jù)少,又沒有預(yù)訓(xùn)練模型,怎么破?
給你個(gè)秘密武器——自監(jiān)督學(xué)習(xí)。

數(shù)據(jù)科學(xué)家 Jeremy Howard 發(fā)布一條Twitter:
在醫(yī)學(xué)圖像領(lǐng)域,我們經(jīng)常需要靠一點(diǎn)點(diǎn)的數(shù)據(jù)來做很多工作。
在這個(gè)問題上,有一種被低估的方法,正是自監(jiān)督學(xué)習(xí),簡(jiǎn)直太神奇!
還附上了與之相關(guān)的最新fast.ai教程。

△地址:https://www.fast.ai/2020/01/13/self_supervised/
這一推文立即引起了大量網(wǎng)友的關(guān)注,可謂是好評(píng)如潮。
這是篇了不起的文章,太酷了!
這是一種簡(jiǎn)單且強(qiáng)大的技術(shù)。
接下來,讓我們一起看下,自監(jiān)督學(xué)習(xí)到底有多厲害。
自監(jiān)督學(xué)習(xí)簡(jiǎn)介
在多數(shù)情況下,訓(xùn)練神經(jīng)網(wǎng)絡(luò)都應(yīng)該從一個(gè)預(yù)訓(xùn)練(pre-trained)模型開始,然后再對(duì)它進(jìn)行微調(diào)。
通過預(yù)訓(xùn)練模型,可以比從頭開始訓(xùn)練,節(jié)省1000倍的數(shù)據(jù)。
那么試想一下,你所在的領(lǐng)域中,要是沒有預(yù)訓(xùn)練模型,該怎么辦?
例如在醫(yī)學(xué)圖像領(lǐng)域,就很少有預(yù)先訓(xùn)練過的模型。
而最近有一篇比較有意思的論文,就對(duì)這方面問題做了研究。

△論文地址:https://arxiv.org/pdf/1902.07208.pdf
研究發(fā)現(xiàn),即便使用ImageNet模型(預(yù)訓(xùn)練過的)中的前幾層(early layers),也可以提高醫(yī)學(xué)成像模型的訓(xùn)練速度和最終準(zhǔn)確性。
所以說,即便某個(gè)通用預(yù)訓(xùn)練模型,不在你的研究領(lǐng)域范圍內(nèi),也可以嘗試使用它。
然而,這項(xiàng)研究也指出了一個(gè)問題:
其改進(jìn)程度并不大。
那有沒有不需要大量數(shù)據(jù),還能取得較好效果的技術(shù)呢?
自監(jiān)督學(xué)習(xí)就是一個(gè)秘密武器。
它可以被看作是機(jī)器學(xué)習(xí)的一種“理想狀態(tài)”,模型直接從無標(biāo)簽數(shù)據(jù)中自行學(xué)習(xí),無需標(biāo)注數(shù)據(jù)。
舉個(gè)例子,ULMFiT(一種NLP訓(xùn)練方法)的關(guān)鍵就是自監(jiān)督學(xué)習(xí),極大的提高了NLP領(lǐng)域的技術(shù)水平。

△論文地址:https://arxiv.org/abs/1801.06146
在基于自監(jiān)督學(xué)習(xí)的方法,首先訓(xùn)練了一個(gè)語言模型,可以預(yù)測(cè)某句話的下一個(gè)單詞。
而當(dāng)把這個(gè)預(yù)訓(xùn)練好的模型,用在另一個(gè)任務(wù)中時(shí)(例如情緒分析),就可以用少量的數(shù)據(jù),得到最新的結(jié)果。
計(jì)算機(jī)視覺中的自監(jiān)督學(xué)習(xí)
在自監(jiān)督學(xué)習(xí)中,用于預(yù)訓(xùn)練的任務(wù)被稱為pretext task(前置/代理任務(wù))。
然后用于微調(diào)的任務(wù)被稱為downstream task(下游任務(wù))。
盡管目前在NLP領(lǐng)域中,自監(jiān)督學(xué)習(xí)的應(yīng)用還算普遍,但是在計(jì)算機(jī)視覺領(lǐng)域中,它卻很少使用。
也許是因?yàn)橹T如ImageNet這樣的預(yù)訓(xùn)練模型比較成功,所以像醫(yī)學(xué)成像領(lǐng)域中的研究人員,可能不太熟悉自監(jiān)督學(xué)習(xí)的必要性。
接下來的內(nèi)容便展示了CV領(lǐng)域中應(yīng)用自監(jiān)督學(xué)習(xí)的論文例子。
希望越來越多的人可以重視這一關(guān)鍵技術(shù)。
圖像著色(Colorization)
Colorful Image Colorization

△論文地址:https://arxiv.org/abs/1603.08511
Learning Representations for Automatic Colorization

△論文地址:https://arxiv.org/pdf/1603.06668
Tracking Emerges by Colorizing Videos

△https://arxiv.org/pdf/1806.09594
效果展示

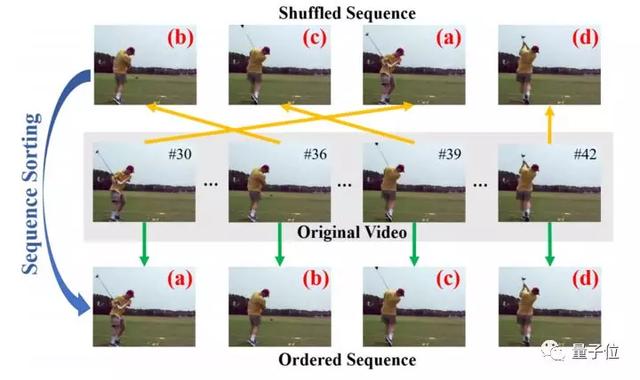
將圖像patch放在正確位置
Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles

△論文地址:https://arxiv.org/pdf/1603.09246
Unsupervised Visual Representation Learning by Context Prediction

△論文地址:https://arxiv.org/pdf/1505.05192
效果展示
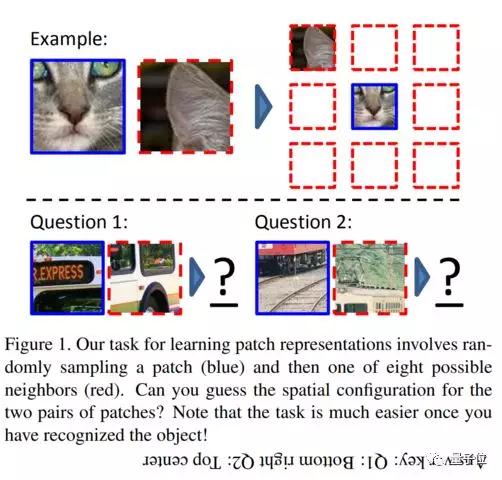
按照正確的順序放置幀
Unsupervised Representation Learning by Sorting Sequences

△論文地址:https://arxiv.org/pdf/1708.01246
Shuffle and Learn: Unsupervised Learning using Temporal Order Verification

△論文地址:https://arxiv.org/pdf/1603.08561
效果展示
圖像修復(fù)(Inpainting)
Context Encoders: Feature Learning by Inpainting

△論文地址:https://arxiv.org/pdf/1604.07379
效果展示
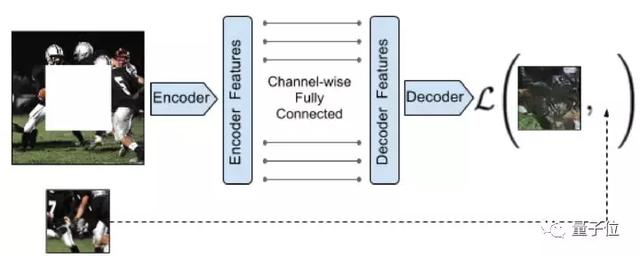
分類損壞的圖像
Self-Supervised Feature Learning by Learning to Spot Artifacts

△論文地址:https://zpascal.net/cvpr2018/Jenni_Self-Supervised_Feature_Learning_CVPR_2018_paper.pdf
效果展示
選擇一個(gè)pretext task
為了在計(jì)算機(jī)視覺中使用自監(jiān)督學(xué)習(xí),需要回答一個(gè)非常重要的問題:
應(yīng)該使用哪種pretext task?
很多人選擇將“自動(dòng)編碼器”作為pretext task。
自動(dòng)編碼器將輸入圖像轉(zhuǎn)換為一種簡(jiǎn)化的形式,然后將其再轉(zhuǎn)換回盡可能接近原始圖像的內(nèi)容。
然而,我們不僅需要再生原始圖像內(nèi)容,還需要再生原始圖像中的所有噪聲。
因此,如果要在下游任務(wù)中生成更高質(zhì)量的圖像,那么這將是一個(gè)不好的選擇。
此外,還需要確保pretext task是人類可以做的事情。
例如,預(yù)測(cè)視頻的下一幀,如果預(yù)測(cè)時(shí)間點(diǎn)過于遙遠(yuǎn),那也是不太可行的。
為下游任務(wù)進(jìn)行微調(diào)
一旦用pretext task預(yù)訓(xùn)練了模型,就可以繼續(xù)進(jìn)行微調(diào)。
在這一點(diǎn)上,應(yīng)該把這個(gè)問題視為一種遷移學(xué)習(xí),不要太多的改變預(yù)訓(xùn)練模型的權(quán)重。
總體而言,Jeremy Howard不建議浪費(fèi)太多時(shí)間來創(chuàng)建“完美”的pretext模型,而要構(gòu)建盡可能快速且容易的模型。
然后,需要確保這個(gè)pretext模型是否可以滿足下游任務(wù)。
并且,事實(shí)證明,通常不需要非常復(fù)雜的pretext 任務(wù),就可以在下游任務(wù)中取得較好的結(jié)果。
Yann LeCun更好的方法建議
Jeremy Howard在發(fā)出這條Twitter之后,深度學(xué)習(xí)三巨頭之一的Yann LeCun對(duì)其回復(fù)。
Yann LeCun提出了更好的建議:
現(xiàn)在,學(xué)習(xí)視覺特征最佳SSL方法是使用孿生神經(jīng)網(wǎng)絡(luò)(Siamese network)來學(xué)習(xí)嵌入。
相關(guān)研究包括:
Self-Supervised Learning of Pretext-Invariant Representations

△論文地址:https://arxiv.org/pdf/1912.01991
Jeremy Howard對(duì)LeCun回復(fù)道:
將PiRL添加到任意pretext task中是非常好的一件事情。
Jeremy Howard
△Jeremy Howard
Jeremy Howard,澳大利亞數(shù)據(jù)科學(xué)家和企業(yè)家。fast.ai創(chuàng)始研究人員之一,fast.ai是一家致力于使深度學(xué)習(xí)更易用的研究所。
在此之前,他曾是Enlitic(位于舊金山的高級(jí)機(jī)器學(xué)習(xí)公司)的首席執(zhí)行官兼創(chuàng)始人。