折騰了一周的任務 帶你了解大數據計算原理
最近遇到了一個任務折騰了我一個周多,終于跑成功了,解決的過程就是一個漸漸認清大數據計算原理的過程,希望對大家有幫助。
一、任務背景
1.1 資源一:一個表
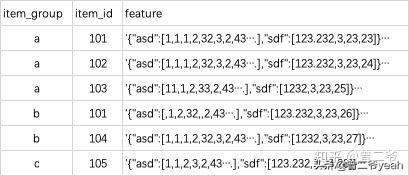
現在有一個表,名為Item 有item_group, item_id, feature 三個字段,分別代表物品所在的類別,物品ID,物品的特征 如下圖:
2.2 資源二:相似度函數
還有一個函數F(feature1, feature2) 輸入兩個物品的feature,返回這兩個物品的相似度。
2.3 目標
現在需要計算的是在同一個類別下物品之間兩兩的相似度。
2.4 相關信息
1.item表總共300萬條記錄,parquet格式來存儲,總大小36G2.總共有1.5萬個item_group,最大的一個item_group有8000多個item3.feature是個json字符串,每個大概有8萬Byte,約80K4.函數F平均一分鐘處理10000條數據
大家可以幫我想想,如果你來做這個任務要怎么進行計算呢。
二、我的嘗試
2.1 方案1:item和item join
上來就啥都沒想,item和item用item_group join一下就能得到同一個item_group下的兩兩組合(這里我們成為item_pair),就可以計算相似度了。so easy。
- select a.item_id id1, b.item_id id2, F(a.feature, b.feature) score from item a join item b on a.item_group = b.item_group and a.item_id>b.item_id
非常完美清晰,簡單即有效,所有的數據基本都只用計算一次。然鵝幾個小時之后:
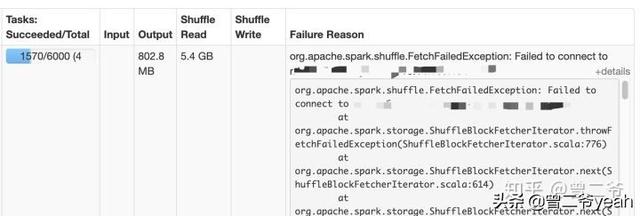
- org.apache.spark.shuffle.MetadataFetchFailedException: Missing an
- output location for shuffle 0
什么鬼讀取shuffle失敗,再仔細一看原來是熟悉的OOM(out of memory)。
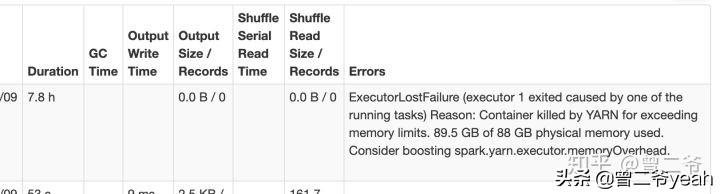
- ExecutorLostFailure (executor 20 exited caused by one of the running
- tasks) Reason: Container killed by YARN for exceeding memory
- limits. 90.4 GB of 88 GB physical memory used. Consider boosting
- spark.yarn.executor.memoryOverhead.
遇到這種狀況加內存、加shuffle分區數(設置spark.sql.shuffle.partitions)這是常規操作
然鵝幾個小時之后又掛了,還是一樣的問題。難道是feature太大了?后來我把feature進行了壓縮,從80k一下子壓縮到了8K,結果又雙叒掛了
方案1徹底卒。
2.2 方案2 先生成pair
冷靜!我要冷靜下來分析。既然是feature占了主要的內存,那我前期可以先不帶上feature,先計算出需要計算的item_pair,第二步在計算的時候join上feature就可以了呀,我真是太聰明了。方案2:
- select a.item_id id1, b.item_id id2,from item ajoin item b on a.item_group = b.item_group and a.item_id>b.item_id
存為item_pair表然后再join feature 計算分數
- select id1, id2, F(a.feature, b.feature) scorefrom item_pairjoin
- item a on item_pair.id1=a.item_idjoin item b on
- item_pair.id2=b.item_id
結果又雙叒叕過了好多個小時,item_pair表跑出來了正高興著,結果第二部分,依舊掛掉,依舊memoryOverhead。懷疑人生了。
三、真正的認真分析
多次的失敗終于使我冷靜了下來,認真回憶起了spark相關的知識。下面是我認真的分析:
3.1 上文方案1的分析:
按照item_group自己和自己join的話,會如下圖。下游會按照item_group聚集起來做join。
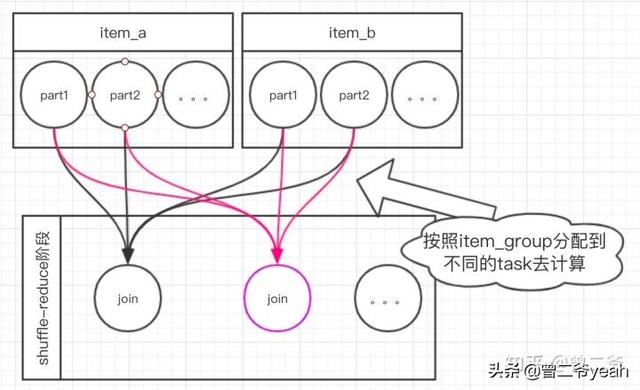
我們來計算一下:
- 表中最大一個group有8000個item。
- 生成不重復的pair也會有組合數C(n,2)=n×(n-1)/2=31996000,3千萬個pair。
- 每個feature優化之后占8K,一個pair就是16K,3千萬就是480G,也就是一個group就要占480G,何況shuffle時一個task里不止一個group。
經過計算內存不爆那是不可能的。
3.2 方案2的分析:
生成item_pair 基本不耗什么內存,最終生成20億條item_pair。到了第二步的時候我們來看看,數據是怎么流動的。如下圖:
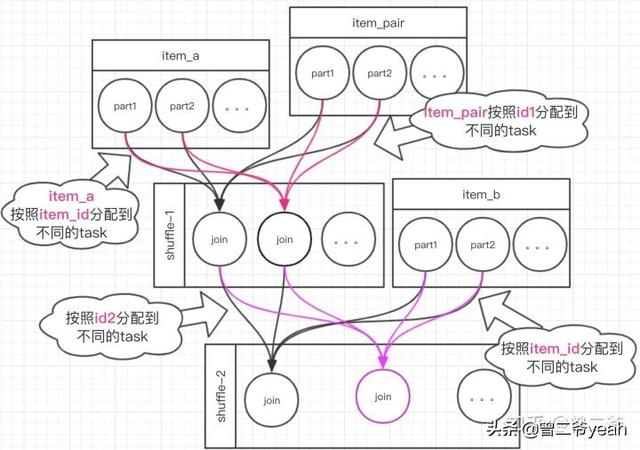
第一階段item_pair按照id1去分組,分發到下游的節點,我們按最做多那個ID計算的話有至少有8000條數據會被分到一個分區結合上feature字段,也就是會生成64M的數據。
這還是單個item_id,總共有300萬個item_id,不可能shuffle的時候用300萬個分區每個分區一個item_id吧,就算每個分區放1000個題目需要占64個G,要3000個分區。
第二階段數據加上id2的feature,數據量會擴大一倍變成128G,3000個分區。看樣子能行,但是實際操作起來耗費的內存可比這個大很多,而且分區太多出現各種奇怪的問題,比如shuffle文件丟失啥的,而且之后group下面的題目增多就只能不斷擴大內存了,實在不是個好辦法。得考慮其他的方案了。
四、最后的解決方案
4.1 在item_group總切分成多個組合數的子任務
item_group總共就1.5萬個,最多的一個有8000個feature,也就64M,麻煩的點就在于要在item_group里求組合數(兩兩配對)。
能不能把求組合數這一步切分成不同的子任務,再在每個子任務里去求組合數,這樣不但能減少內存消耗,還能增加并行度。
我們來畫個組合數的圖。
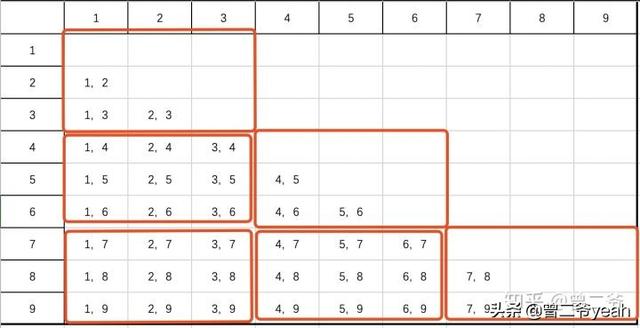
上圖我們可以按照閾值為3進行分割,就可以把整個圖切分成幾個小子圖進行計算了。
實際進行的時候如果我們按500進行分割的話,8000個item的group可以分成136個子任務,子任務中最大的一個會有500×500=250000個pair,但數據的話就只需要傳最多1000個feature也就是8M的數據,子任務數就算在原有不切割的15000個group上擴增1.5倍也就是15000×1.5=22500個,設置2000個分區,每個分區11個子任務,內存耗費11×8M=88M,共計算250000×11次,每1萬次一分鐘,也就是一個分區得跑4個小時左右,實際上也差不多。
五、總結和問題
總結起來就是最開始太自信了。
- 沒有仔細的思考
- 沒有認真調查數據的規模
- 沒有認真考慮在每個方案數據是怎么在spark中流動
- 沒有認真做計算。