大數據之數據倉庫分層
大數據之數據倉庫分層
- 什么是數據分層?
- 數據分層的好處
- 一種通用的數據分層設計
- 舉例
- 各層會用到的計算引擎和存儲系統
- 分層實現
- 數據分層的一些概念說明 7.大數據相關基礎概念
1. 什么是數據分層?
數據分層是一套行之有效的數據組織和管理方法,使得數據體系更有序。
2. 數據分層的好處
(1)清晰數據結構
每一個數據分層都有它的作用域和職責,在使用表的時候能更方便的定位和理解。
(2)減少重復開發
規范數據分層,開發一些通用的中間層數據,能夠減少極大的重復計算。
(3)統一數據口徑
通過數據分層,提供統一的數據出口,統一對外輸出的數據口徑。
(4)復雜問題簡單化
將一個復雜的任務分解成多個步驟完成,每一層解決特定的問題。
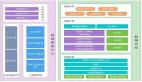
一種通用的數據分層設計
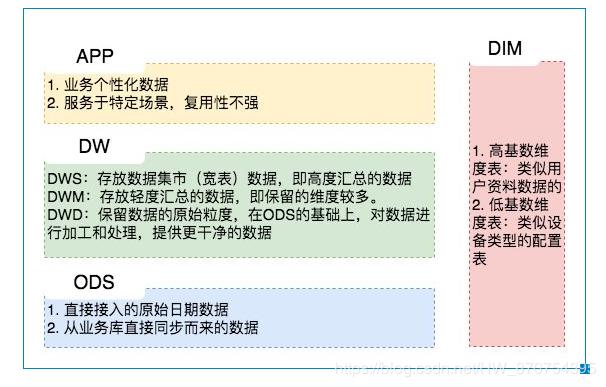
- ODS:存放原始數據
- DW:存放數倉中間層數據
- APP:面向業務定制的應用數據
3. 舉例
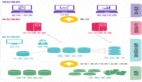
以下是一個電商網站的數據體系設計,只關注用戶訪問日志這部分數據。
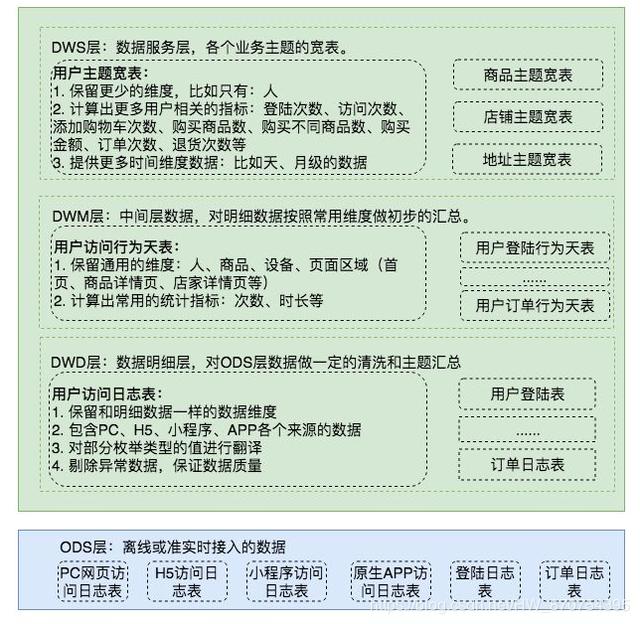
4. 各層會用到的計算引擎和存儲系統
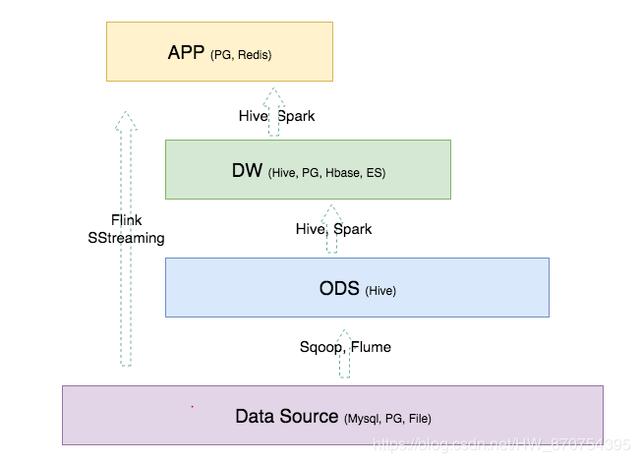
5.分層實現
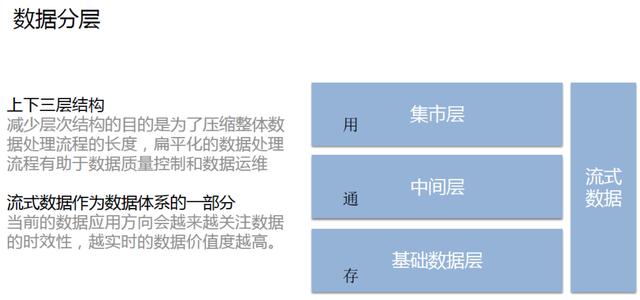
在確定建模思路和模型類型之后,下一步的工作是數據分層。數據分層可以使得數據構建體系更加清晰,便于數據使用者快速對數據進行定位;同時數據分層也可以簡化數據加工處理流程,降低計算復雜度。
我們常用的數據倉庫的數據分層通常分為集市層、中間層、基礎數據層上下三層結構。由傳統的多層結構減少到上下三層結構的目的是為了壓縮整體數據處理流程的長度,同時扁平化的數據處理流程有助于數據質量控制和數據運維。
在上下三層的結構的右側,我們增加了流式數據,將其添加成數據體系的一部分。這是因為當前的數據應用方向會越來越關注數據的時效性,越實時的數據價值度越高。
但是,由于流式數據集的采集、加工和管理的成本較高,一般都會按照需求驅動的方式建設;此外,考慮到成本因素,流式數據體系的結構更加扁平化,通常不會設計中間層。
下面來具體看下每一層的具體作用。
數據基礎層

數據基礎層主要完成的工作包括以下幾點:
- 數據采集:把不同數據源的數據統一采集到一個平臺上;
- 數據清洗,清洗不符合質量要求的數據,避免臟數據參與后續數據計算;
- 數據歸類,建立數據目錄,在基礎層一般按照來源系統和業務域進行分類;
- 數據結構化,對于半結構化和非結構化的數據,進行結構化;
- 數據規范化,包括規范維度標識、統一計量單位等規范化操作。
數據中間層

數據中間層最為重要的目標就是把同一實體不同來源的數據打通起來,這是因為當前業務形態下,同一實體的數據可能分散在不同的系統和來源,且這些數據對同一實體的標識符可能不同。此外,數據中間層還可以從行為中抽象關系。從行為中抽象出來的基礎關系,會是未來上層應用一個很重要的數據依賴。例如抽象出的興趣、偏好、習慣等關系數據是推薦、個性化的基礎生產資料。
在中間層,為了保證主題的完整性或提高數據的易用性,經常會進行適當的數據冗余。比如某一實事數據和兩個主題相關但自身又沒有成為獨立主題,則會放在兩個主題庫中;為了提高單數據表的復用性和減少計算關聯,通常會在事實表中冗余部分維度信息。
數據集市層

數據集市層是上下三層架構的最上層,通常是由需求場景驅動建設的,并且各集市間垂直構造。在數據集市層,我們可以深度挖掘數據價值。值得注意的是,數據集市層需要能夠快速試錯。
數據架構
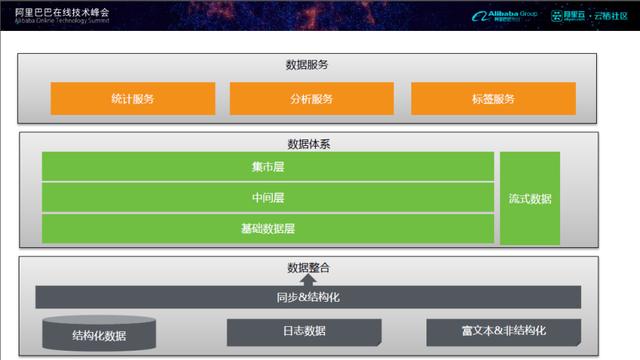
數據架構包括數據整合、數據體系、數據服務三部分。其中,數據整合又可以分為結構化、半結構化、非結構化三類。
數據整合

結構化數據采集又可細分為全量采集、增量采集、實時采集三類。三種采集方式的各自特點和適應場合如上圖所示,其中全量采集的方式最為簡單;實時采集的采集質量最難控制。
在傳統的架構中,日志的結構化處理是放在數倉體系之外的。在大數據平臺倉庫架構中,日志在采集到平臺之前不做結構化處理;在大數據平臺上按行符分割每條日志,整條日志存儲在一個數據表字段;后續,通過UDF或MR計算框架實現日志結構化。
在我們看來,日志結構越規范,解析成本越低。在日志結構化的過程中,并不一定需要完全平鋪數據內容,只需結構化出重要常用字段;同時,為了保障擴展性,我們可以利用數據冗余保存原始符合字段(如useragent字段)。

非結構化的數據需要結構化才能使用。非結構化數據特征提取包括語音轉文本、圖片識別、自然語言處理、圖片達標、視頻識別等方式。盡管目前數倉架構體系中并不包含非結構化數據特征提取操作,但在未來,這將成為可能。
數據服務化

數據服務化包括統計服務、分析服務和標簽服務:
- 統計服務主要是偏傳統的報表服務,利用大數據平臺將數據加工后的結果放入關系型數據庫中,供前端的報表系統或業務系統查詢;
- 分析服務用來提供明細的事實數據,利用大數據平臺的實時計算能力,允許操作人員自主靈活的進行各種維度的交叉組合查詢。分析服務的能力類似于傳統cube提供的內容,但是在大數據平臺下不需要預先建好cube,更靈活、更節省成本;
- 標簽服務,大數據的應用場景下,經常會對主體進行特征刻畫,比如客戶的消費能力、興趣習慣、物理特征等等,這些數據通過打標簽轉換成KV的數據服務,用于前端應用查詢。
6.數據分層的一些概念說明
大數據數據倉庫是基于HIVE構建的數據倉庫,分布文件系統為HDFS,資源管理為Yarn,計算引擎主要包括MapReduce/Tez/Spark等,分層架構說明如下:
- 數據來源層:日志或者關系型數據庫,并通過Flume、Sqoop、Kettle等etl工具導入到HDFS,并映射到HIVE的數據倉庫表中。
- 事實表是數據倉庫結構中的中央表,它包含聯系事實與維度表的數字度量值和鍵。事實數據表包含描述業務(例如產品銷售)內特定事件的數據。
- 維度表是維度屬性的集合。是分析問題的一個窗口。是人們觀察數據的特定角度,是考慮問題時的一類屬性,屬性的集合構成一個維。數據庫結構中的星型結構,該結構在位于結構中心的單個事實數據表中維護數據,其它維度數據存儲在維度表中。每個維度表與事實數據表直接相關,且通常通過一個鍵聯接到事實數據表中。星型架構是數據倉庫比較流向的一種架構。
星型模式的基本思想就是保持立方體的多維功能,同時也增加了小規模數據存儲的靈活性。
說明:
- 事實表就是你要關注的內容;
- 維度表就是你觀察該事務的角度,是從哪個角度去觀察這個內容的。
例如,某地區商品的銷量,是從地區這個角度觀察商品銷量的。事實表就是銷量表,維度表就是地區表
4、主題表:主題(Subject)是在較高層次上將企業信息系統中的數據進行綜合、歸類和分析利用的一個抽象概念,每一個主題基本對應一個宏觀的分析領域。在邏輯意義上,它是對應企業中某一宏觀分析領域所涉及的分析對象。例如“銷售分析”就是一個分析領域,因此這個數據倉庫應用的主題就是“銷售分析”。
面向主題的數據組織方式,就是在較高層次上對分析對象數據的一個完整并且一致的描述,能刻畫各個分析對象所涉及的企業各項數據,以及數據之間的聯系。所謂較高層次是相對面向應用的數據組織方式而言的,是指按照主題進行數據組織的方式具有更高的數據抽象級別。與傳統數據庫面向應用進行數據組織的特點相對應,數據倉庫中的數據是面向主題進行組織的。例如,一個生產企業的數據倉庫所組織的主題可能有產品訂貨分析和貨物發運分析等。而按應用來組織則可能為財務子系統、銷售子系統、供應子系統、人力資源子系統和生產調度子系統。
5、匯總數據層:聚合原子粒度事實表及維度表,為滿足固定分析需求,以提高查詢性能為目的,形成的高粒度表,如周報、月報、季報、年報等。
6、應用層:
為應用層,這層數據是完全為了滿足具體的分析需求而構建的數據,也是星形結構的數據。應用層為前端應用的展現提現數據,可以為關系型數據庫組成。
7、【補充】
數據緩存層:
- 用于存放接口方提供的原始數據的數據庫層,此層的表結構與源數據保持基本一致,數據存放時間根據數據量大小和項目情況而定,如果數據量較大,可以只存近期數據,將歷史數據進行備份。此層的目的在于數據的中轉和備份。
臨時數據表層:
- 存放臨時測試數據表(Temp表),或者中間結果集的表。
7. 大數據相關基礎概念
- 數據源:業務系統、埋點、爬蟲
- PG:PostgreSQL,一種關系型數據庫
- Sqoop:是一個在結構化數據(mysql/oracle)和Hadoop(Hive)之間進行批量數據遷移的工具
- Flume:是一個分布式、可靠、高可用的海量日志采集、聚合和傳輸的系統。支持在日志系統中定制各類數據發送方,用于收集數據;提供對數據進行簡單處理,并寫到各種數據接受方(HDFS\Hbase)的能力。
- Kafka:是一個分布式、支持分區的、多副本的,基于zookeeper協調的分布式消息系統。
- Flink:一個流式的數據流執行引擎。針對數據流的分布式計算提供了數據分布、數據通信以及容錯機制等功能。
- Kylin:是一個開源的分布式分析引擎,提供Hadoop/Spark之上的SQL查詢接口及多維分析(OLAP)能力一直吃超大規模數據。能在亞秒內查詢巨大的Hive表。
- ES:elasticsSearch,是一個高擴展、開源的全文檢索和分析引擎,可準實時地快速存儲、搜索、分析海量的數據。
- Hadoop:是一個分布式系統基礎架構,可使用戶在不了解分布式底層細節的情況下開發分布式程序,充分利用集群的威力進行高速運算和存儲。兩大核心:HDFS\MapReduce
- HDFS:是可擴展、容錯、高性能的分布式文件系統,異步復制,一次寫入多次讀取,主要負責存儲。
- MapReduce:分布式計算框架。
- Spark:是一個專為大規模數據處理而設計的快速通用的計算引擎。