淺談分布式存儲系統的數據分布算法,來了解一下吧!
前言
分布式存儲系統 面臨著的首要問題,就是如何將 大量的數據 分布在 不同的存儲節點 上。無論上層接口是 KV 存儲、對象存儲、塊存儲、亦或是 列存儲,在這個問題上大體是一致的。本文將介紹如何 分布式存儲系統 中 做數據分布目標 及可選的 方案,并試著總結和權衡他們之間的關系。
正文
(一) 指標
這里假設 目標數據 是以 key 標識的 數據塊 或 對象。在一個包含 多個存儲節點 的集群中,數據分布算法 需要為每一個給定的 key 指定 一個 或 多個 對應的 存儲節點 負責,數據分布算法 有兩個基本目標:
- 均勻性(Uniformity):不同存儲節點的 負載 應該 均衡;
- 穩定性(Consistency):每次一個 key 通過 數據分布算法 得到的 分布結果應該保持 基本穩定,即使再有存儲節點發生變化的情況下。
可以看出,這兩個目標在一定程度上是 相互矛盾 的。當有 存儲節點增加或刪除時,為了保持穩定應該 盡量少 的進行 數據的移動 和 重新分配,而這樣又勢必會帶來 負載不均衡。同樣追求 極致均勻 也會導致較多的 數據遷移。
所以我們希望在這兩個極端之間,找到一個點以獲得合適的均勻性和穩定性。除了上述兩個基本目標外,工程中還需要從以下幾個方面考慮數據分布算法的優劣:
- 性能可擴展性:這個主要考慮的是算法相對于 存儲節點規模 的 時間復雜度。為了整個系統的可擴展性,數據分布算法不應該在集群規模擴大后顯著的增加運行時間。
- 考慮節點異構:實際工程中,不同 存儲節點 之間可能會有很大的 性能 或 容量差異,好的數據分布算法應該能很好的應對這種 異構,提供 加權的數據均勻。
- 隔離故障域:為了 數據的高可用,數據分布算法應該為每個 key 找到 一組存儲節點,這些節點可能提供的是 數據的鏡像副本,也可能是類似 擦除碼的副本方式。數據分布算法應該盡量 隔離 這些副本的故障域,如 不同機房、不同機架、不同交換機、不同機器。
(二) 演進
看完算法的評價指標后,接下來介紹一些可能的方案演進,并分析他們的優劣。這里假設 key 的值足夠分散。
1. Hash
一個簡單直觀的想法是直接用 Hash 來計算,簡單的以 Key 做 哈希 后 對節點數取模。可以看出,在 key 足夠分散的情況下,均勻性 可以獲得,但一旦有 節點加入或 退出 時,所有的原有節點都會受到影響。穩定性 無從談起。
2. 一致性Hash
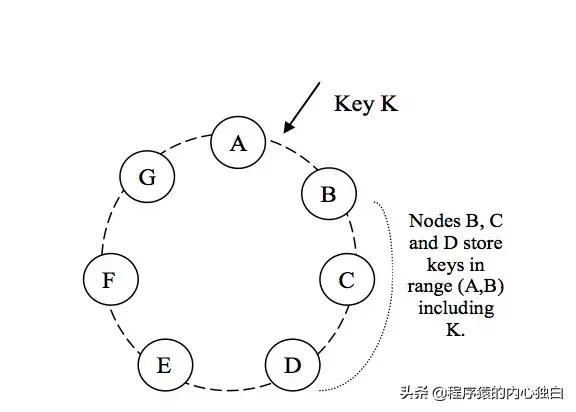
一致性 Hash 可以很好的解決 穩定性問題,可以將所有的 存儲節點 排列在收尾相接的 Hash 環上,每個 key 在計算 Hash 后會 順時針 找到先遇到的 存儲節點 存放。而當有節點 加入 或 退出 時,僅影響該節點在 Hash 環上 順時針相鄰 的 后續節點。但這有帶來 均勻性 的問題,即使可以將存儲節點等距排列,也會在 存儲節點個數 變化時帶來 數據的不均勻。而這種可能 成倍數的不均勻 在實際工程中是不可接受的。
3. 帶負載上限的一致性Hash
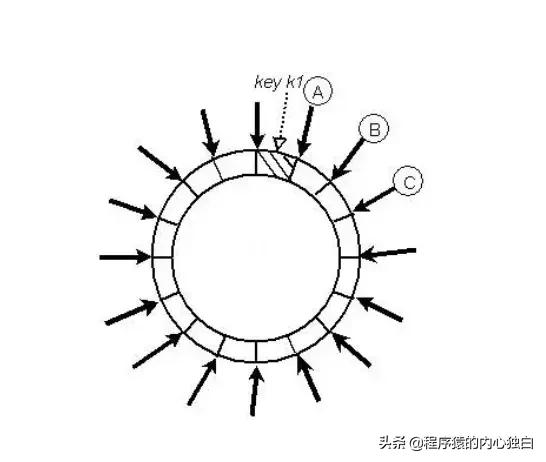
一致性 Hash 有 節點變化時不均勻的問題。Google 在 2017 年提出了 Consistent Hashing with Bounded Loads 來控制這種 不均勻的程度。簡單的說,該算法給 Hash 環上的每個節點一個 負載上限 為 1 + e 倍的 平均負載,這個 e可以自定義。當 key 在 Hash 環上 順時針 找到合適的節點后,會判斷這個節點的 負載 是否已經 到達上限,如果 已達上限,則需要繼續找 之后的節點 進行分配。
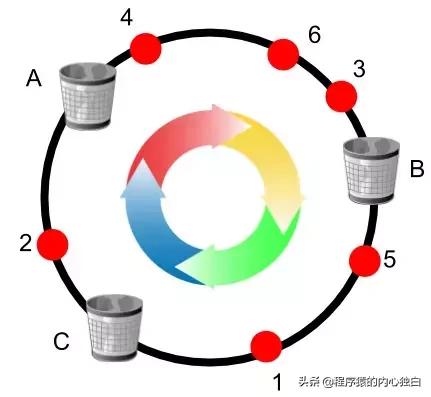
如上圖所示,假設每個桶 當前上限 是 2,紅色的小球按序號訪問,當編號為 6 的紅色小球到達時,發現順時針首先遇到的 B(3,4),C(1,5)都已經 達到上限,因此最終放置在桶 A 里。
這個算法最吸引人的地方在于 當有節點變化 時,需要遷移的數據量是 1/e^2 相關,而與 節點數 或 數據數量 均無關。
也就是說當 集群規模擴大 時,數據遷移量 并不會隨著顯著增加。另外,使用者可以通過調整 e 的值來控制 均勻性 和 穩定性 之間的權衡,就是一種 以時間換空間的算法。總體來說,無論是 一致性 Hash 還是 帶負載限制 的 一致性 Hash,都無法解決 節點異構 的問題。
4. 帶虛擬節點的一致性Hash
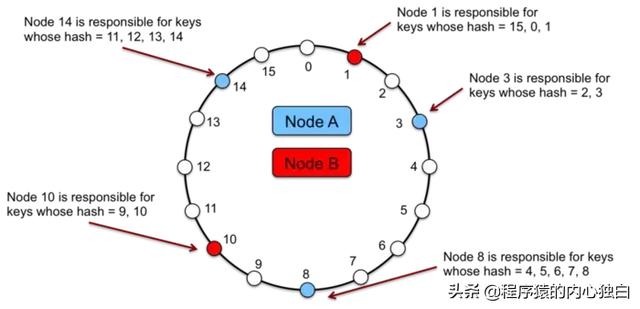
為了解決 負載不均勻 和 異構 的問題,可以在 一致性 Hash 的基礎上引入 虛擬節點。即 hash 環上的 每個節點 并不是 實際 的 存儲節點,而是一個 虛擬節點。實際的 存儲節點 根據其 不同的權重,對應 一個 或 多個虛擬節點,所有落到相應虛擬節點上的 key 都由該 存儲節點負責。
如下圖所示,存儲節點 A 負責 (1,3],(4,8],(10, 14],存儲節點 B 負責 (14,1],(8,10]。
這個算法的問題在于,一個 實際存儲節點 的 加入 或 退出,會影響 多個虛擬節點的重新分配,進而引起 很多節點 參與到 數據遷移 中來。
另外,實踐中將一個 虛擬節點 重新分配給 新的實際節點 時,需要將這部分數據 遍歷 出來 發送給新節點。我們需要一個更合適的 虛擬節點切分 和 分配方式,那就是 分片。
5. 分片
分片 將 哈希環 切割為 相同大小的分片,然后將這些 分片 交給 不同的節點 負責。
注意這里跟上面提到的 虛擬節點 有著很 本質的區別:分片的劃分和分片的分配被解耦。
一個 節點退出 時,其所負責的 分片 并不需要 順時針合并 給之后節點,而是可以更靈活的 將整個分片 作為一個 整體 交給 任意節點。在實踐中,一個 分片 多作為 最小的數據遷移 和 備份單位。
而也正是由于上面提到的 解耦,相當于將原先的 key 到 節點 的 映射 拆成了兩層。需要一個 新的機制 來進行 分片 到 存儲節點 的 映射。由于 分片數 相對 key 空間已經很小并且 數量確定,可以更精確地初始設置,并引入 中心目錄服務 來根據 節點存活 修改 分片的映射關系。同時將這個 映射信息 通知給所有的 存儲節點和 客戶端。
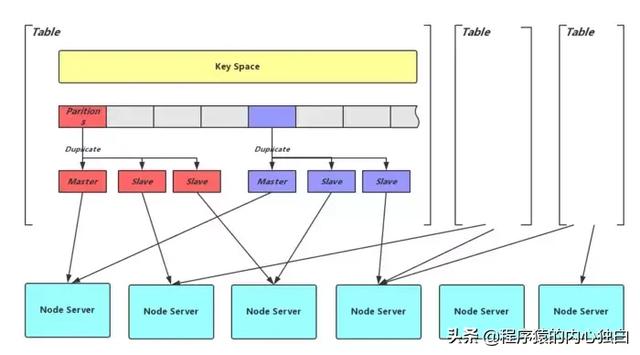
上圖是 分布式KV存儲 Zeppelin中的 分片方式,Key Space 通過 Hash 到 分片,分片及其副本 又通過一層映射到 最終的存儲節點 Node Server。
6. CRUSH算法
CRUSH 算法本質上也是一種 基于分片 的數據分布方式,其試圖在以下幾個方面進行優化:
- 分片映射信息量:避免 中心目錄服務 和 存儲節點 及 客戶端之間 交互大量的 分片映射信息,而改由 存儲節點 或 客戶端 自己根據 少量 且 穩定 的集群節點拓撲和確定的規則自己計算分片映射。
- 完善的故障域劃分:支持 層級 的 故障域控制,將 同一分片 的 不同副本 按照配置劃分到 不同層級 的 故障域中。
客戶端 或 存儲節點 利用 key、存儲節點 的 拓撲結構 和 分配算法,獨立的進行 分片位置 的計算,得到一組負責對應 分片 及 副本 的 存儲位置。
如圖所示是 一次定位 的過程,最終選擇了一個 row 下的 cab21,cab23,cab24 三個機柜下的三個存儲節點。
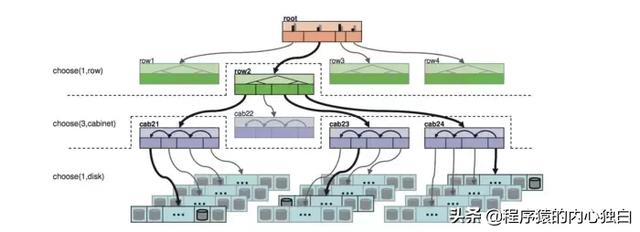
當 節點變化 時,由于 節點拓撲 的變化,會影響 少量分片 數據進行遷移,如下圖是加入 新節點 引起的 數據遷移。通過良好的 分配算法,可以得到很好的 負載均衡和 穩定性,CRUSH 提供了 Uniform、List、Tree、Straw 四種分配算法。
(三) 應用案例
常見的 分布式存儲系統 大多采用類似于 分片 的 數據分布和定位方式:
- Cassandra/Dynamo:采用 分片 的方式并通過 Gossip 協議在對等節點間通信;
- Redis Cluster:將 key Space 劃分為 slots,同樣利用 Gossip 協議通信;
- Zeppelin:將數據分片為 Partition,通過 Meta 集群提供 中心目錄服務;
- Bigtable:將數據切割為 Tablet,類似于可變的分片,Tablet Server 可以進行分片的切割,最終分片信息記錄在 Chubby 中;
- Ceph:采用 CRUSH 方式,由 中心集群 Monitor 提供并維護 集群拓撲 的變化。