MySQL性能優(yōu)化之骨灰級(jí)高階神技!
原創(chuàng)【51CTO.com原創(chuàng)稿件】在程序,語(yǔ)言,架構(gòu)更新?lián)Q代頻繁的今天,MySQL 恐怕是大家使用最多的存儲(chǔ)數(shù)據(jù)庫(kù)了。
圖片來(lái)自 Pexels
大量信息的存儲(chǔ)和查詢(xún)都會(huì)用到 MySQL,因此它的優(yōu)化就對(duì)系統(tǒng)性能提升就尤為重要了。
由于 MySQL 的優(yōu)化范圍較廣,從軟件到硬件,從配置到應(yīng)用,無(wú)法一一道來(lái)。
今天就從開(kāi)發(fā)者的角度介紹一下 MySQL 應(yīng)用優(yōu)化。包括數(shù)據(jù)類(lèi)型,數(shù)據(jù)表查詢(xún)/修改,索引和查詢(xún)等幾個(gè)方面。
數(shù)據(jù)類(lèi)型優(yōu)化
字段是用來(lái)存放數(shù)據(jù)的單元,設(shè)計(jì)好字段是設(shè)計(jì)數(shù)據(jù)庫(kù)的第一步,同樣會(huì)影響到系統(tǒng)的性能。
設(shè)計(jì)字段有一個(gè)基本的原則,保小不保大,也就是能夠用字節(jié)少的字段就不用字節(jié)數(shù)大的字段,目的是為了節(jié)省空間,提高查詢(xún)效率。
更小的字段,占用更小的磁盤(pán)空間,內(nèi)存空間,更小的 IO 消耗。下面針對(duì)使用場(chǎng)景,說(shuō)一些字段類(lèi)型選取的經(jīng)驗(yàn),供大家參考。
數(shù)值類(lèi)型
手機(jī)號(hào):通常我們?cè)诖鎯?chǔ)手機(jī)號(hào)的時(shí)候,喜歡用 Varchar 類(lèi)型。
如果是 11 位的手機(jī)號(hào),假設(shè)我們用 utf8 的編碼,每位字節(jié)就需要 3 個(gè)字節(jié),那么就需要 11*33=33 個(gè)字節(jié)來(lái)存放;如果我們使用 bigint,只需要 8 個(gè)字節(jié)就可以存放。
IP 地址:同上,IP 地址也可以通過(guò) int(4 字節(jié))在存放,可以通過(guò) INET_ATON() 函數(shù)把 IP 地址轉(zhuǎn)成數(shù)字。這里需要注意溢出的問(wèn)題,需要用無(wú)符號(hào)的 int。
年齡,枚舉類(lèi)型:可以用 tinyint 來(lái)存放,它只占用 1 個(gè)字節(jié),無(wú)符號(hào)的 tinyint 可以表示 0-255 的范圍,基本夠用了。
字符類(lèi)型
Char 和 Varchar 是我們常用的字符類(lèi)型。char(N) 用來(lái)記錄固定長(zhǎng)度的字符,如果長(zhǎng)度不足 N 的,用空格補(bǔ)齊。
varchar(N) 用來(lái)保存可變長(zhǎng)度的字符,它會(huì)額外增加 1-2 字節(jié)來(lái)保存字符串的長(zhǎng)度。
Char 和 Varchar 占用的字節(jié)數(shù),根據(jù)數(shù)據(jù)庫(kù)的編碼格式不同而不同。Latin1 占用 1 個(gè)字節(jié),gbk 占用 2 個(gè)字節(jié),utf8 占用 3 個(gè)字節(jié)。
用法方面,如果存儲(chǔ)的內(nèi)容是可變長(zhǎng)度的,例如:家庭住址,用戶描述就可以用 Varchar。
如果內(nèi)容是固定長(zhǎng)度的,例如:UUID(36 位),或者是 MD5 加密串(32 位),就可以使用 Char 存放。
時(shí)間類(lèi)型
Datetime 和 Timestamp 都是可以精確到秒的時(shí)間類(lèi)型,但是 Datetime 占用 8 個(gè)字節(jié),而 Timestamp 占用 4 個(gè)字節(jié)。
所以在日常建表的時(shí)候可以有限選擇 Timestamp。不過(guò)他們有下面幾個(gè)小區(qū)別,需要注意的。
區(qū)別一:存儲(chǔ)數(shù)據(jù)方式不一樣。
Timestamp 是轉(zhuǎn)化成 utc 時(shí)間進(jìn)行存儲(chǔ),查詢(xún)時(shí),轉(zhuǎn)化為客戶端時(shí)間返回的。
區(qū)別二:兩者存儲(chǔ)時(shí)間的范圍不一樣。
Timestamp 為'1970-01-01 00:00:01.000000' 到'2038-01-19 03:14:07.999999'。
Datetime為'1000-01-01 00:00:00.000000'到'9999-12-31 23:59:59.999999'。
數(shù)據(jù)表查詢(xún)/修改優(yōu)化
說(shuō)了如何高效地選擇存儲(chǔ)數(shù)據(jù)的類(lèi)型以后,再來(lái)看看如何高效地讀取數(shù)據(jù)。MySQL 作為關(guān)系型數(shù)據(jù)庫(kù),在處理復(fù)雜業(yè)務(wù)的時(shí)候多會(huì)選擇表與表之間的關(guān)聯(lián)。
這會(huì)導(dǎo)致我們?cè)诓樵?xún)數(shù)據(jù)的時(shí)候,會(huì)關(guān)聯(lián)其他的表,特別是一些多維度數(shù)據(jù)查詢(xún)的時(shí)候,這種關(guān)聯(lián)就尤為突出。
此時(shí),為了提高查詢(xún)的效率,我們會(huì)對(duì)某些字段做冗余處理,讓這些字段同時(shí)存在于多張表中。
但是,這又會(huì)帶來(lái)其他的問(wèn)題,例如:如果針對(duì)冗余字段進(jìn)行修改的時(shí)候,就需要對(duì)多張表進(jìn)行修改,并且需要讓這個(gè)修改保持在一個(gè)事物中。
如果處理不當(dāng),會(huì)導(dǎo)致數(shù)據(jù)的不一致性。這里需要根據(jù)具體情況采取查詢(xún)策略,例如:需要跨多張表查詢(xún)公司銷(xiāo)售額信息。
由于,銷(xiāo)售信息需要連接多張表,并且對(duì)銷(xiāo)售量和金額做求和操作,直接查詢(xún)顯然是不妥當(dāng)?shù)摹?/p>
可以生成后臺(tái)服務(wù),定時(shí)從相關(guān)表中取出信息,計(jì)算出結(jié)果放入一張匯總表中。
將匯總表中需要查詢(xún)的條件字段加上索引信息,提高查詢(xún)的效率。這種做法,限于查詢(xún)數(shù)據(jù)實(shí)時(shí)性不強(qiáng)的情況。
在高速迭代開(kāi)發(fā)過(guò)程中,業(yè)務(wù)變化快,數(shù)據(jù)庫(kù)會(huì)根據(jù)業(yè)務(wù)的變化進(jìn)行迭代。所以,在開(kāi)發(fā)新產(chǎn)品初期,表結(jié)構(gòu)會(huì)面臨頻繁地修改。
MySQL 的 ALTERTABLE 操作性能對(duì)大表來(lái)說(shuō)是個(gè)問(wèn)題。MySQL 執(zhí)行修改表結(jié)構(gòu)操作的方法是,用新的結(jié)構(gòu)創(chuàng)建一個(gè)空表,從舊表中查出所有數(shù)據(jù)插入新表,然后刪除舊表。
這一操作需要花費(fèi)大量時(shí)間,如果內(nèi)存不足而表數(shù)據(jù)很大,并且索引較多的情況,會(huì)造成長(zhǎng)時(shí)間的鎖表。
有極端的情況,有些 ALTERTABLE 操作需要花費(fèi)數(shù)個(gè)小時(shí)甚至數(shù)天才能完成。
這里推薦兩種小技巧:
- 先把數(shù)據(jù)庫(kù)拷貝到一臺(tái)非生產(chǎn)服務(wù)器上,在上面做修改表操作,此時(shí)的修改不會(huì)影響生產(chǎn)庫(kù)。
修改完畢以后在做數(shù)據(jù)庫(kù)的切換,把非生產(chǎn)數(shù)據(jù)庫(kù)切換成生產(chǎn)庫(kù)。不過(guò)需要注意的時(shí)候,在做表結(jié)構(gòu)修改的時(shí)候,生產(chǎn)庫(kù)會(huì)生成一些數(shù)據(jù)。這里需要通過(guò)腳本根據(jù)時(shí)間區(qū)間導(dǎo)入這部分?jǐn)?shù)據(jù)。
- “影子拷貝”,即生成一張表結(jié)構(gòu)相同的不同名新數(shù)據(jù)表(更改數(shù)據(jù)結(jié)構(gòu)以后的表)。
然后導(dǎo)入原表的數(shù)據(jù)到新表,導(dǎo)入成功以后停止數(shù)據(jù)庫(kù),修改原表和新表的名字,最終將數(shù)據(jù)訪問(wèn)指向新表。
在運(yùn)行正常以后,將原表刪除。這里有現(xiàn)成的工具可以協(xié)助完成上述操作,“online schema change”,”openark toolkit”
如果只是刪除或者更改某一列的默認(rèn)值,那么直接可以使用 Alert table modify column 和 Alert table alert column 來(lái)實(shí)現(xiàn)。
索引優(yōu)化
說(shuō)了字段和表再來(lái)聊聊索引。對(duì)于索引的優(yōu)化網(wǎng)上有很多的說(shuō)法,都是在實(shí)際工作中總結(jié)出來(lái)的,這里沒(méi)有一定的標(biāo)準(zhǔn)。
針對(duì)我們使用比較多的 InnoDB 的存儲(chǔ)引擎(使用的 B-Tree 索引),推薦幾個(gè)方法給大家。
索引獨(dú)立
“索引獨(dú)立”是指索引列不能是表達(dá)式的一部分,也不能是函數(shù)的參數(shù)。例如:假設(shè) User 表中分別把 create_date 和 userId 設(shè)置為索引。
- select *from user where date(create_date)=curdate()
- selectuserId from user where userId+1=5
類(lèi)似上面的語(yǔ)句就是將索引作為了函數(shù)中的參數(shù)和表達(dá)式的一部分,是不推薦這樣使用的。
前綴索引
有時(shí)候索引字段長(zhǎng)度較大,例如:VarChar,Blob,Text。當(dāng)搜索的時(shí)候,這會(huì)讓索引變得大且慢。
通常的做法是,可以索引開(kāi)始的部分字符,這樣可以節(jié)約索引空間,提高索引效率。
既然索引全部字符行不通,那么索引多少字符就是我們要討論的問(wèn)題了。
這里需要引入一個(gè)概念,索引的選擇性。索引的選擇性是指,不重復(fù)的索引值和數(shù)據(jù)表的記錄總數(shù)的比值。
索引的選擇性越高則查詢(xún)效率越高,因?yàn)檫x擇性高的索引可以讓 MySQL 在查找時(shí)過(guò)濾掉更多的行。
例如:有一張 user 表,其中有一個(gè)字段是 FirstName,如何計(jì)算這個(gè)字段的選擇性,如下:
- Select1.0*count(distinct FirstName)/count(*) from user
假設(shè)這個(gè)結(jié)果是 0.75 再用 left 函數(shù)對(duì)該字段取部分字符,例如取從左開(kāi)始的 3,4,5 個(gè)字段。
分別查看其選擇性,目的是看當(dāng)選擇多少字符的時(shí)候,選擇性最接近 0.75。
- 從左取3個(gè)字段的時(shí)候,
- Select 1.0*count(distinct left(FirstName,3))/count(*) from user
- 結(jié)果為0.58
- 從左取4個(gè)字段的時(shí)候,
- Select 1.0*count(distinct left(FirstName,4))/count(*) from user
- 結(jié)果為0.67
- 從左取5個(gè)字段的時(shí)候,
- Select 1.0*count(distinct left(FirstName,5))/count(*) from user
- 結(jié)果為0.74
從上面嘗試發(fā)現(xiàn),字段 FirstName 取左邊字符,從 3-5 的獲取可以看出,當(dāng)從左邊取第 5 個(gè)字符的時(shí)候,選擇性 0.74 最接近 0.75。
因此,可以將 FirstName 的前面 5 個(gè)字符作為前綴索引,這樣建立索引的效果基本和 FirstName 全部字符建立索引的效果一致。而又不用將 FirstName 整個(gè)字段都當(dāng)成索引。
于是可以用下面語(yǔ)句修改索引信息:
- Alter tableuser add key(FirstName(5))
多列索引及其順序
多列索引,顧名思義就是將多列字段作為索引。假設(shè)在 user 表中通過(guò)搜索 LastName 和 FirstName 條件來(lái)查找數(shù)據(jù)。
可能出現(xiàn)以下語(yǔ)句:
- Select *from user where LastName = ‘Green’
- Select *from user where LastName = ‘Green’ and FirstName = ‘Jack’
- Select *from user where LastName = ‘Green’ and (FirstName = ‘Jack’ or FirstName =‘Michael’
- Select *from user where LastName = ‘Green’ and FirstName >=‘M’ and FirstName<‘N’
如果分別在 LastName 和 FirstName 上面建立索引:
- Select *from user where LastName = ‘Green’ and FirstName = ‘Jack’
當(dāng)運(yùn)行上面這段代碼的時(shí)候,系統(tǒng)會(huì)讓選擇性高的 SQL 的索引生效,另外一個(gè)索引是用不上的。因此我們就需要建立多列索引(合并索引)。
語(yǔ)句如下:
- Alter table user add key(LastName, FirstName)
既然定義了多列索引,那么其中的索引順序是否也需要考慮呢?在一個(gè)多列 B-Tree 索引中,索引列的順序意味著,索引首先按照最左列進(jìn)行排序,其次是第二列。
索引可以按照升序或者降序進(jìn)行掃描,以滿足精確符合列順序的 ORDERBY、GROUPBY 和 DISTINCT 等子句的查詢(xún)需求。
所以,多列索引的順序是需要考慮的。這里給出的建議是,將選擇性最高的索引列放在前面。
接上面的例子,還是 LastName 和 FirstName 作為多列索引。看誰(shuí)應(yīng)該放前面。
通過(guò)按照選擇性規(guī)則,寫(xiě)如下 SQL 語(yǔ)句:
- 先計(jì)算LastName的選擇性
- Selectcount(disctinc LastName)/count(*) from user
- 結(jié)果為0.02
- 再計(jì)算FirstName的選擇性
- Selectcount(disctinc FirstName)/count(*) from user
- 結(jié)果0.05
FirstName 的選擇性要高于 LastName 的選擇性。因此調(diào)整多列索引的順序如下:
- Alter tableuser add key(FirstName ,LastName)
覆蓋索引
當(dāng)使用 Select 的數(shù)據(jù)列只用從索引中取得,而不必從數(shù)據(jù)表中讀取,換句話說(shuō)查詢(xún)列要被所使用的索引覆蓋。
例如:User 表中將 LastName 作為索引。如果寫(xiě)以下查詢(xún)語(yǔ)句:
- Select LastName from user
LastName 及作為索引,又在查詢(xún)內(nèi)容中顯示出來(lái),那么 LastName 就是覆蓋索引。
覆蓋索引是高效查找行方法,通過(guò)索引就可以讀取數(shù)據(jù),就不需要再到數(shù)據(jù)表中讀取數(shù)據(jù)了。
而且覆蓋索引會(huì)以 Usingindex 作為標(biāo)示,可以通過(guò) Explain 語(yǔ)句查看。

Explain 查看覆蓋索引標(biāo)示
覆蓋索引主要應(yīng)用在 Count 等一些聚合操作上,提升查詢(xún)的效率。例如上面提到的 Selectcount(LastName) from user 就可以把 LastName 設(shè)置為索引。
還有可以進(jìn)行列查詢(xún)的回表優(yōu)化,如下:
- Select LastName, FirstName from user where LastName=‘Jack’
如果此時(shí) LastName 設(shè)置為索引,可以將 LastName 和 FirstName 設(shè)置為多列索引(聯(lián)合索引)。
避免回表行為的發(fā)生。這里的回表是指二級(jí)索引搜索到以后,再找到聚合索引,然后在查找 PK 的過(guò)程。
這里需要通過(guò)兩次搜索完成。簡(jiǎn)單點(diǎn)說(shuō)就是使用了覆蓋索引以后,一次就可以查到想要的記錄,不用在查第二次了。

回表示意圖
查詢(xún)優(yōu)化
作為程序開(kāi)發(fā)人員來(lái)說(shuō),使用得最多的就是 SQL 語(yǔ)句了,最多的操作就是查詢(xún)了。
我們一起來(lái)看看,哪些因素會(huì)影響查詢(xún)記錄,查詢(xún)基本原理是什么,以及如何發(fā)現(xiàn)和優(yōu)化 SQL 語(yǔ)句。
影響查詢(xún)效率的因素
一般來(lái)說(shuō),影響查詢(xún)的因素有三部分組成,如下:
- 響應(yīng)時(shí)間,由兩部分組成,他們分別是,服務(wù)時(shí)間和排隊(duì)時(shí)間。服務(wù)時(shí)間是指數(shù)據(jù)庫(kù)處理查詢(xún)花費(fèi)的時(shí)間。
排隊(duì)時(shí)間是指服務(wù)器因?yàn)榈却承┵Y源花費(fèi)的時(shí)間。例如:I/O 操作,等待其他事務(wù)釋放鎖的時(shí)間。
- 掃描記錄行數(shù),在查詢(xún)過(guò)程中數(shù)據(jù)庫(kù)鎖掃描的行記錄。理想情況下掃描的行數(shù)和返回的行數(shù)是相同的。不過(guò)通常來(lái)說(shuō),掃描的行數(shù)都會(huì)大于返回記錄的行數(shù)。
- 返回記錄行數(shù),返回實(shí)際要查詢(xún)的結(jié)果。
查詢(xún)基礎(chǔ)
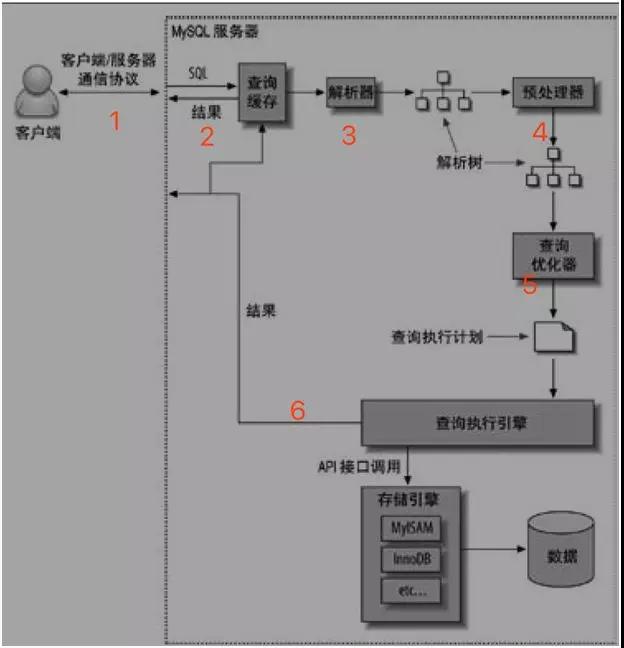
查詢(xún)流程圖
說(shuō)了影響查詢(xún)效率的因素以后,來(lái)看看查詢(xún)這件事情在 MySQL 中是如何運(yùn)作的,可以幫助我理解,查詢(xún)優(yōu)化工作是在哪里進(jìn)行的:
- 客戶端發(fā)送一條查詢(xún)給服務(wù)器。
- 服務(wù)器先檢查查詢(xún)緩存,如果命中了緩存,則立刻返回存儲(chǔ)在緩存中的結(jié)果。
- 解析器對(duì) SQL 進(jìn)行解析,它通過(guò)關(guān)鍵字將 SQL 語(yǔ)句進(jìn)行解析,并生成一棵對(duì)應(yīng)的“解析樹(shù)”。MySQL 解析器將使用 MySQL 語(yǔ)法規(guī)則驗(yàn)證和解析查詢(xún)。
- 預(yù)處理器則根據(jù)一些 MySQL 規(guī)則進(jìn)一步檢查解析樹(shù)是否合法,并且驗(yàn)證權(quán)限。例如,檢查數(shù)據(jù)表和數(shù)據(jù)列是否存在,解析名字和別名看是否有歧義。
- MySQL 根據(jù)優(yōu)化器生成的執(zhí)行計(jì)劃,調(diào)用存儲(chǔ)引擎的 API 來(lái)執(zhí)行查詢(xún)。
- 將結(jié)果返回給客戶端。
如何發(fā)現(xiàn)查詢(xún)慢的 SQL
說(shuō)了影響查詢(xún)緩慢的因素以及查詢(xún)的基本流程以后,再來(lái)看看如何發(fā)現(xiàn)查詢(xún)慢的 SQL。這里 MySQL 提供了日志,其中可以查詢(xún)執(zhí)行比較慢的 SQL。
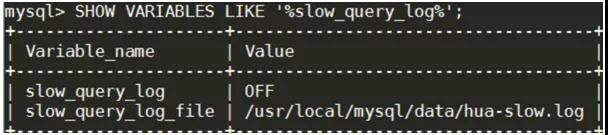
①查看慢查詢(xún)?nèi)罩臼欠耖_(kāi)啟
SHOWVARIABLESLIKE'%slow_query_log%';
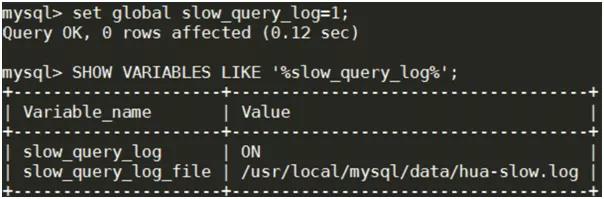
②如果沒(méi)有開(kāi)啟,通過(guò)命令開(kāi)啟慢查詢(xún)?nèi)罩?/strong>
- SETGLOBAL slow_query_log=1;
③設(shè)置慢查詢(xún)?nèi)罩镜臅r(shí)間,這里的單位是秒,意思是只要是執(zhí)行時(shí)間超過(guò) X 秒的查詢(xún)語(yǔ)句被記錄到這個(gè)日志中。這里的 X 就是你要設(shè)置的。(下面的例子設(shè)置的是 3 秒)
- SETGLOBAL long_query_time=3;
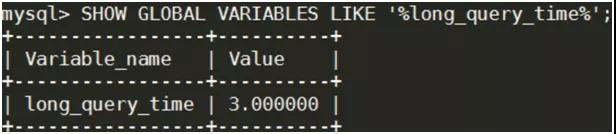
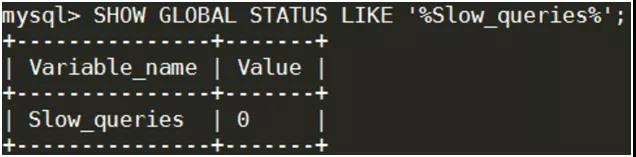
④查看多少 SQL 語(yǔ)句是超過(guò)查詢(xún)閥值的(3 秒)
Explain 分析 SQL 查詢(xún)
通過(guò)上面的方法可以知道哪些 SQL 花費(fèi)了較多的時(shí)間,那么如何對(duì)這些 SQL 語(yǔ)句進(jìn)行分析呢。畢竟,我們的目的是通過(guò)分析以后,優(yōu)化 SQL 從而提高其性能。
將 Explain 關(guān)鍵字放在要執(zhí)行的 SQL 語(yǔ)句前面,可以模擬優(yōu)化器執(zhí)行 SQL 語(yǔ)句,從而知道 MySQL 是如何處理你的 SQL 語(yǔ)句的。

Explain 執(zhí)行 SQL 示意圖
上面每個(gè)字段的含義,在這里不展開(kāi)描述。
SQL 優(yōu)化建議
如果發(fā)現(xiàn)慢查詢(xún)的 SQL,我們就需要針對(duì)其問(wèn)題進(jìn)行優(yōu)化。這里針對(duì)幾個(gè)常見(jiàn)的 SQL 給出一些優(yōu)化建議。
類(lèi)似 SQL 優(yōu)化的文章和例子在網(wǎng)上種類(lèi)繁多,千奇百怪。建議在優(yōu)化之前,先查看慢查詢(xún)?nèi)罩竞?Explain 的語(yǔ)句,再進(jìn)行優(yōu)化,做到有的放矢。
①Count 優(yōu)化
從 user 表中搜索 id 大于 7 的所有用戶。如果是 InnoDB 存儲(chǔ)引擎會(huì)進(jìn)行逐行掃描,如果表中記錄比較多,性能就是問(wèn)題了。
- Select count(*) from user where id>7
如果先將所有的行數(shù) Count 出來(lái),再減去 id<=7 的記錄,這樣速度就會(huì)快一些。
- Select (select count(*) - (select count(*) from user where id <=7) from user)
如果有一個(gè)貨物表 items,其中有一個(gè) color 字段來(lái)表示貨物的顏色,如果需要知道顏色是藍(lán)色或者紅色的貨物的數(shù)量,可以這么寫(xiě):
- Select count(color=‘blue’ or color=‘red’) from items
- Select count(*) from items where color=‘blue’ and color=‘red’
不過(guò)顏色本身是除斥的字段,所以可以?xún)?yōu)化成下面的 SQL。
- Select count(color=‘blue’ or null) as blue, count(color=‘red’ or null) as red from items
②GROUPBY 優(yōu)化
MySQL 通過(guò)索引來(lái)優(yōu)化 GROUPBY 查詢(xún)。在無(wú)法使用索引的時(shí)候,會(huì)使用兩種策略?xún)?yōu)化:臨時(shí)表和文件排序分組。
可以通過(guò)兩個(gè)參數(shù) SQL_BIG_RESULT 和 SQL_SMALL_RESULT 提升其性能。
這兩個(gè)參數(shù)只對(duì) Select 語(yǔ)句有效。它們告訴優(yōu)化器對(duì) GROUPBY 查詢(xún)使用臨時(shí)表及排序。
SQL_SMALL_RESULT 告訴優(yōu)化器結(jié)果集會(huì)很小,可以將結(jié)果集放在內(nèi)存中的索引臨時(shí)表,以避免排序操作。
如果是 SQL_BIG_RESULT,則告訴優(yōu)化器結(jié)果集可能會(huì)非常大,建議使用磁盤(pán)臨時(shí)表做排序操作。
例如:
- SelectSQL_BUFFER_RESULTfield1, count(*) from table1 groupby field1
假設(shè)兩個(gè)表做關(guān)聯(lián)查詢(xún),選擇查詢(xún)表中的標(biāo)識(shí)列(主鍵)分組效率會(huì)高。
例如 actor 表和 film 表通過(guò) actorId 做關(guān)聯(lián),查詢(xún)?nèi)缦拢?/p>
- Select actor.FirstName, actor.LastName,count(*) from film inner join actor using(actorId)
- Group by actor.FirstName,actor.LastName
就可以修改為:
- Select actor.FirstName, actor.LastName, count(*) from film inner join actor using(actorId)
- Group by film.actorId
③Limit
Limit 對(duì)我們?cè)偈煜ひ膊贿^(guò)了,特別是在做分頁(yè)操作的時(shí)候,經(jīng)常會(huì)用到它。但在偏移量非常的時(shí)候問(wèn)題就來(lái)了。
例如,Limit 1000,20 就需要偏移 1000 條數(shù)據(jù)以后,再返回后面的 20 條記錄,前面的 1000 條數(shù)據(jù)是被拋棄掉的。
按照上例 SQL 代碼如下:
- Select name from user order by id limit1000,20
這里通過(guò) id 索引到第 1001 條記錄,然后取 20 條記錄。這里利用 id 的索引的優(yōu)勢(shì)直接跳過(guò)了前面 1000 條記錄。
- Select name from user where id>=1001order by id limit 20
總結(jié)
從開(kāi)發(fā)者的角度了解 MySQL 的應(yīng)用優(yōu)化。從數(shù)據(jù)類(lèi)型的選擇開(kāi)始,針對(duì)數(shù)值類(lèi)型,字符類(lèi)型,時(shí)間類(lèi)型進(jìn)行了舉例說(shuō)明。
接下來(lái)談到,作為數(shù)據(jù)表的查詢(xún),修改的優(yōu)化,我們應(yīng)該注意哪些細(xì)節(jié)。然后,聊了索引獨(dú)立,前綴索引,多列索引,覆蓋索引的優(yōu)化方法。
最后,針對(duì)使用最多的查詢(xún)優(yōu)化進(jìn)行了探討。從影響查詢(xún)的因素到查詢(xún)基礎(chǔ),再到如何發(fā)現(xiàn)慢查詢(xún),用幾個(gè) SQL 優(yōu)化的建議結(jié)束了我們的 MySQL 應(yīng)用優(yōu)化之旅。
寫(xiě)完全文感覺(jué) MySQL 博大精深,需要學(xué)習(xí)的東西很多,一文不能面面俱到,還需不斷學(xué)習(xí)。
作者:崔皓
簡(jiǎn)介:十六年開(kāi)發(fā)和架構(gòu)經(jīng)驗(yàn),曾擔(dān)任過(guò)惠普武漢交付中心技術(shù)專(zhuān)家,需求分析師,項(xiàng)目經(jīng)理,后在創(chuàng)業(yè)公司擔(dān)任技術(shù)/產(chǎn)品經(jīng)理。善于學(xué)習(xí),樂(lè)于分享。目前專(zhuān)注于技術(shù)架構(gòu)與研發(fā)管理。

【51CTO原創(chuàng)稿件,合作站點(diǎn)轉(zhuǎn)載請(qǐng)注明原文作者和出處為51CTO.com】