Kubernetes研究:網絡原理及方案(網絡原理基礎經典版)
說到容器、Docker,大家一定會想到Kubernetes,確實如此,在2016年ClusterHQ容器技術應用調查報告顯示,Kubernetes的使用率已經達到了40%,成為容器編排工具;那么Kubernetes到底是什么呢?它是一個用于容器集群的自動化部署、擴容以及運維的開源平臺;那么通過Kubernetes能干什么呢?它能快速而有預期地部署你的應用,極速地擴展你的應用,無縫對接新的應用功能,節省資源,優化硬件資源的使用。
隨著Kubernetes王者時代的到來,計算、網絡、存儲、安全是Kubernetes繞不開的話題,本次主要分享Kubernetes網絡原理及方案,后續還會有Kubernetes其它方面的分享,另外有容云5.22發布了基于Kubernetes的容器云平臺產品UFleet,想要獲取新品試用,歡迎聯系有容云。
一、Kubernetes網絡模型
在Kubernetes網絡中存在兩種IP(Pod IP和Service Cluster IP),Pod IP 地址是實際存在于某個網卡(可以是虛擬設備)上的,Service Cluster IP它是一個虛擬IP,是由kube-proxy使用Iptables規則重新定向到其本地端口,再均衡到后端Pod的。下面講講Kubernetes Pod網絡設計模型:
1、基本原則:
每個Pod都擁有一個獨立的IP地址(IPper Pod),而且假定所有的pod都在一個可以直接連通的、扁平的網絡空間中。
2、設計原因:
用戶不需要額外考慮如何建立Pod之間的連接,也不需要考慮將容器端口映射到主機端口等問題。
3、網絡要求:
所有的容器都可以在不用NAT的方式下同別的容器通訊;所有節點都可在不用NAT的方式下同所有容器通訊;容器的地址和別人看到的地址是同一個地址。
二、Docker網絡基礎
Linux網絡名詞解釋:
1、網絡的命名空間:Linux在網絡棧中引入網絡命名空間,將獨立的網絡協議棧隔離到不同的命令空間中,彼此間無法通信;docker利用這一特性,實現不容器間的網絡隔離。
2、Veth設備對:Veth設備對的引入是為了實現在不同網絡命名空間的通信。
3、Iptables/Netfilter:Netfilter負責在內核中執行各種掛接的規則(過濾、修改、丟棄等),運行在內核 模式中;Iptables模式是在用戶模式下運行的進程,負責協助維護內核中Netfilter的各種規則表;通過二者的配合來實現整個Linux網絡協議棧中靈活的數據包處理機制。
4、網橋:網橋是一個二層網絡設備,通過網橋可以將linux支持的不同的端口連接起來,并實現類似交換機那樣的多對多的通信。
5、路由:Linux系統包含一個完整的路由功能,當IP層在處理數據發送或轉發的時候,會使用路由表來決定發往哪里。
- Docker生態技術棧
下圖展示了Docker網絡在整個Docker生態技術棧中的位置:
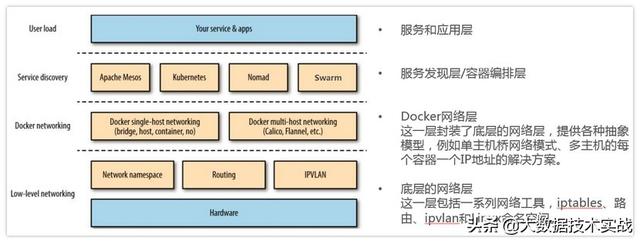
- Docker網絡實現
1、單機網絡模式:Bridge 、Host、Container、None,這里具體就不贅述了。
2、多機網絡模式:一類是 Docker 在 1.9 版本中引入Libnetwork項目,對跨節點網絡的原生支持;一類是通過插件(plugin)方式引入的第三方實現方案,比如 Flannel,Calico 等等。
三、Kubernetes網絡基礎
1、容器間通信:
同一個Pod的容器共享同一個網絡命名空間,它們之間的訪問可以用localhost地址 + 容器端口就可以訪問。
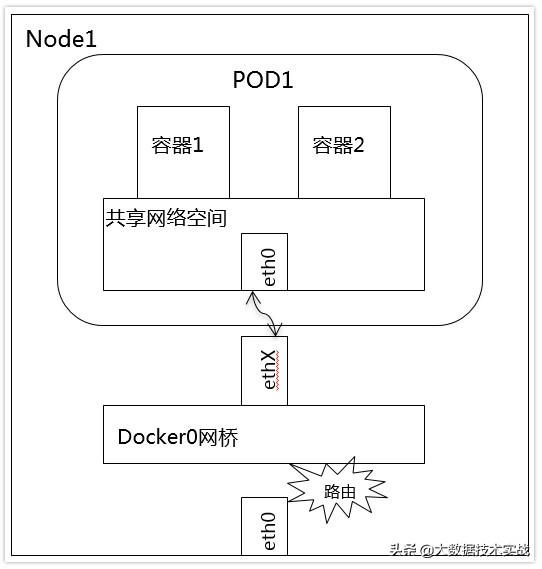
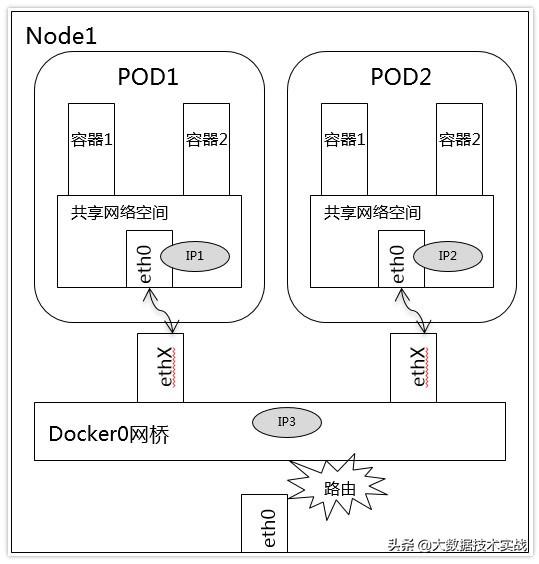
2、同一Node中Pod間通信:
同一Node中Pod的默認路由都是docker0的地址,由于它們關聯在同一個docker0網橋上,地址網段相同,所有它們之間應當是能直接通信的。
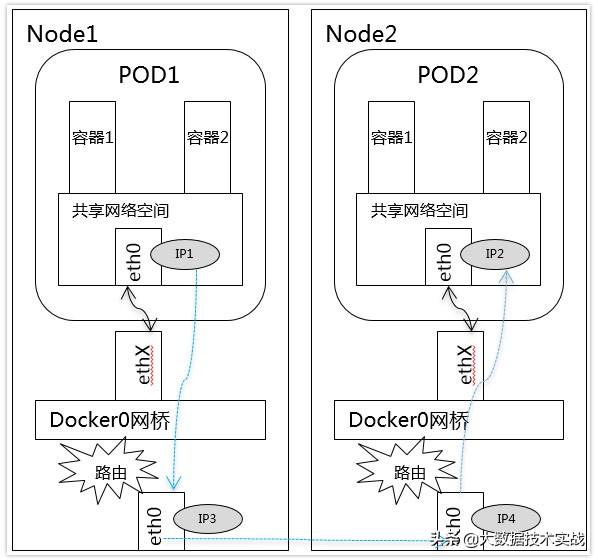
3、不同Node中Pod間通信:
不同Node中Pod間通信要滿足2個條件: Pod的IP不能沖突; 將Pod的IP和所在的Node的IP關聯起來,通過這個關聯讓Pod可以互相訪問。
4、Service介紹:
Service是一組Pod的服務抽象,相當于一組Pod的LB,負責將請求分發給對應的
Pod;Service會為這個LB提供一個IP,一般稱為ClusterIP。


5、Kube-proxy介紹:
Kube-proxy是一個簡單的網絡代理和負載均衡器,它的作用主要是負責Service的實現,具體來說,就是實現了內部從Pod到Service和外部的從NodePort向Service的訪問。
實現方式:
- userspace是在用戶空間,通過kuber-proxy實現LB的代理服務,這個是kube-proxy的最初的版本,較為穩定,但是效率也自然不太高。
- iptables是純采用iptables來實現LB,是目前kube-proxy默認的方式。
下面是iptables模式下Kube-proxy的實現方式:
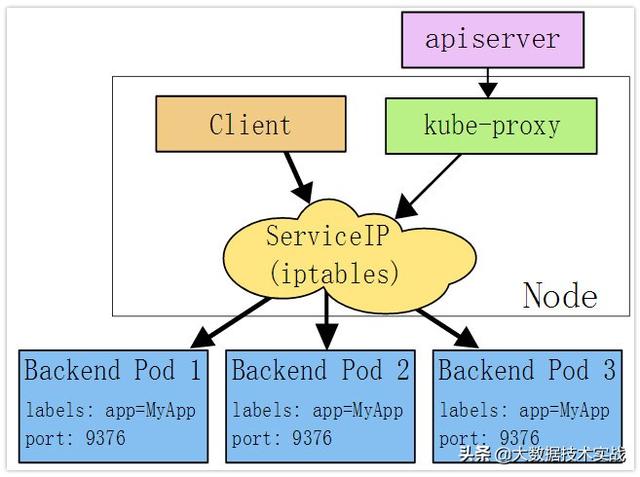
在這種模式下,kube-proxy監視Kubernetes主服務器添加和刪除服務和端點對象。對于每個服務,它安裝iptables規則,捕獲到服務的clusterIP(虛擬)和端口的流量,并將流量重定向到服務的后端集合之一。對于每個Endpoints對象,它安裝選擇后端Pod的iptables規則。
默認情況下,后端的選擇是隨機的。可以通過將service.spec.sessionAffinity設置為“ClientIP”(默認為“無”)來選擇基于客戶端IP的會話關聯。
與用戶空間代理一樣,最終結果是綁定到服務的IP:端口的任何流量被代理到適當的后端,而客戶端不知道關于Kubernetes或服務或Pod的任何信息。這應該比用戶空間代理更快,更可靠。然而,與用戶空間代理不同,如果最初選擇的Pod不響應,則iptables代理不能自動重試另一個Pod,因此它取決于具有工作準備就緒探測。
6、Kube-dns介紹
Kube-dns用來為kubernetes service分配子域名,在集群中可以通過名稱訪問service;通常kube-dns會為service賦予一個名為“service名稱.namespace.svc.cluster.local”的A記錄,用來解析service的clusterip。
Kube-dns組件:
- 在Kubernetes v1.4版本之前由“Kube2sky、Etcd、Skydns、Exechealthz”四個組件組成。
- 在Kubernetes v1.4版本及之后由“Kubedns、dnsmasq、exechealthz”三個組件組成。
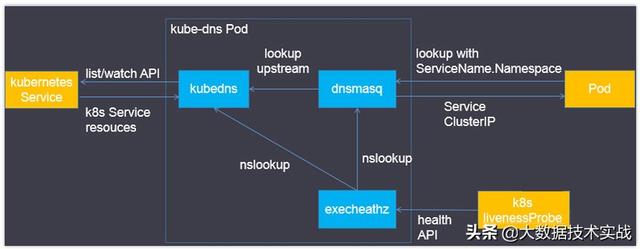
Kubedns
- 接入SkyDNS,為dnsmasq提供查詢服務。
- 替換etcd容器,使用樹形結構在內存中保存DNS記錄。
- 通過K8S API監視Service資源變化并更新DNS記錄。
- 服務10053端口。
Dnsmasq
- Dnsmasq是一款小巧的DNS配置工具。
- 在kube-dns插件中的作用是:
- 通過kubedns容器獲取DNS規則,在集群中提供DNS查詢服務
- 提供DNS緩存,提高查詢性能
- 降低kubedns容器的壓力、提高穩定性
- Dockerfile在GitHub上Kubernetes組織的contrib倉庫中,位于dnsmasq目錄下。
- 在kube-dns插件的編排文件中可以看到,dnsmasq通過參數–server=127.0.0.1:10053指定upstream為kubedns。
Exechealthz
- 在kube-dns插件中提供健康檢查功能。
- 源碼同樣在contrib倉庫中,位于exec-healthz目錄下。
- 新版中會對兩個容器都進行健康檢查,更加完善。
四、Kubernetes網絡開源組件
1、技術術語:
IPAM:IP地址管理;這個IP地址管理并不是容器所特有的,傳統的網絡比如說DHCP其實也是一種IPAM,到了容器時代我們談IPAM,主流的兩種方法: 基于CIDR的IP地址段分配地或者精確為每一個容器分配IP。但總之一旦形成一個容器主機集群之后,上面的容器都要給它分配一個全局唯一的IP地址,這就涉及到IPAM的話題。
Overlay:在現有二層或三層網絡之上再構建起來一個獨立的網絡,這個網絡通常會有自己獨立的IP地址空間、交換或者路由的實現。
IPSesc:一個點對點的一個加密通信協議,一般會用到Overlay網絡的數據通道里。
vxLAN:由VMware、Cisco、RedHat等聯合提出的這么一個解決方案,這個解決方案最主要是解決VLAN支持虛擬網絡數量(4096)過少的問題。因為在公有云上每一個租戶都有不同的VPC,4096明顯不夠用。就有了vxLAN,它可以支持1600萬個虛擬網絡,基本上公有云是夠用的。
網橋Bridge: 連接兩個對等網絡之間的網絡設備,但在今天的語境里指的是Linux Bridge,就是大名鼎鼎的Docker0這個網橋。
BGP: 主干網自治網絡的路由協議,今天有了互聯網,互聯網由很多小的自治網絡構成的,自治網絡之間的三層路由是由BGP實現的。
SDN、Openflow: 軟件定義網絡里面的一個術語,比如說我們經常聽到的流表、控制平面,或者轉發平面都是Openflow里的術語。
2、容器網絡方案:
隧道方案( Overlay Networking )
隧道方案在IaaS層的網絡中應用也比較多,大家共識是隨著節點規模的增長復雜度會提升,而且出了網絡問題跟蹤起來比較麻煩,大規模集群情況下這是需要考慮的一個點。
- Weave:UDP廣播,本機建立新的BR,通過PCAP互通
- Open vSwitch(OVS):基于VxLan和GRE協議,但是性能方面損失比較嚴重
- Flannel:UDP廣播,VxLan
- Racher:IPsec
路由方案
路由方案一般是從3層或者2層實現隔離和跨主機容器互通的,出了問題也很容易排查。
Calico:基于BGP協議的路由方案,支持很細致的ACL控制,對混合云親和度比較高。
Macvlan:從邏輯和Kernel層來看隔離性和性能最優的方案,基于二層隔離,所以需要二層路由器支持,大多數云服務商不支持,所以混合云上比較難以實現。
3、CNM & CNI陣營:
容器網絡發展到現在,形成了兩大陣營,就是Docker的CNM和Google、CoreOS、Kuberenetes主導的CNI。首先明確一點,CNM和CNI并不是網絡實現,他們是網絡規范和網絡體系,從研發的角度他們就是一堆接口,你底層是用Flannel也好、用Calico也好,他們并不關心,CNM和CNI關心的是網絡管理的問題。
CNM(Docker LibnetworkContainer Network Model):
Docker Libnetwork的優勢就是原生,而且和Docker容器生命周期結合緊密;缺點也可以理解為是原生,被Docker“綁架”。
- Docker Swarm overlay
- Macvlan & IP networkdrivers
- Calico
- Contiv
- Weave
CNI(Container NetworkInterface):
CNI的優勢是兼容其他容器技術(e.g. rkt)及上層編排系統(Kubernetes & Mesos),而且社區活躍勢頭迅猛,Kubernetes加上CoreOS主推;缺點是非Docker原生。
- Kubernetes
- Weave
- Macvlan
- Calico
- Flannel
- Contiv
- Mesos CNI
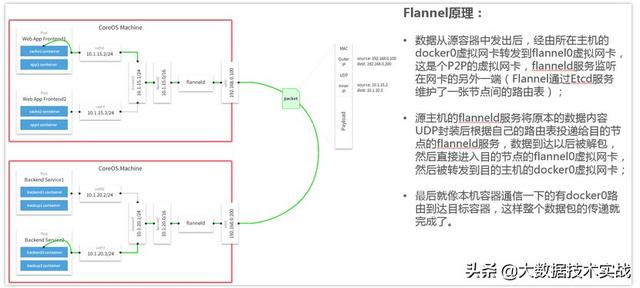
4、Flannel容器網絡:
Flannel之所以可以搭建kubernets依賴的底層網絡,是因為它可以實現以下兩點:
- 它給每個node上的docker容器分配相互不想沖突的IP地址;
- 它能給這些IP地址之間建立一個覆蓋網絡,同過覆蓋網絡,將數據包原封不動的傳遞到目標容器內。
Flannel介紹
- Flannel是CoreOS團隊針對Kubernetes設計的一個網絡規劃服務,簡單來說,它的功能是讓集群中的不同節點主機創建的Docker容器都具有全集群唯一的虛擬IP地址。
- 在默認的Docker配置中,每個節點上的Docker服務會分別負責所在節點容器的IP分配。這樣導致的一個問題是,不同節點上容器可能獲得相同的內外IP地址。并使這些容器之間能夠之間通過IP地址相互找到,也就是相互ping通。
- Flannel的設計目的就是為集群中的所有節點重新規劃IP地址的使用規則,從而使得不同節點上的容器能夠獲得“同屬一個內網”且”不重復的”IP地址,并讓屬于不同節點上的容器能夠直接通過內網IP通信。
- Flannel實質上是一種“覆蓋網絡(overlaynetwork)”,也就是將TCP數據包裝在另一種網絡包里面進行路由轉發和通信,目前已經支持udp、vxlan、host-gw、aws-vpc、gce和alloc路由等數據轉發方式,默認的節點間數據通信方式是UDP轉發。
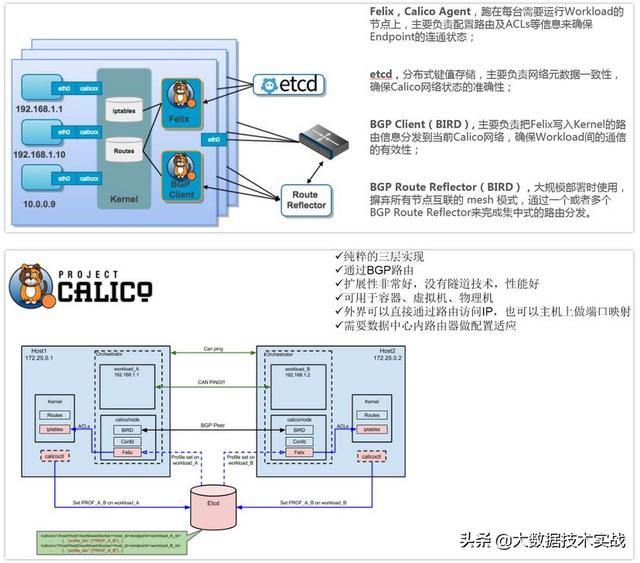
5、Calico容器網絡:
Calico介紹
- Calico是一個純3層的數據中心網絡方案,而且無縫集成像OpenStack這種IaaS云架構,能夠提供可控的VM、容器、裸機之間的IP通信。Calico不使用重疊網絡比如flannel和libnetwork重疊網絡驅動,它是一個純三層的方法,使用虛擬路由代替虛擬交換,每一臺虛擬路由通過BGP協議傳播可達信息(路由)到剩余數據中心。
- Calico在每一個計算節點利用Linux Kernel實現了一個高效的vRouter來負責數據轉發,而每個vRouter通過BGP協議負責把自己上運行的workload的路由信息像整個Calico網絡內傳播——小規模部署可以直接互聯,大規模下可通過指定的BGP route reflector來完成。
- Calico節點組網可以直接利用數據中心的網絡結構(無論是L2或者L3),不需要額外的NAT,隧道或者Overlay Network。
- Calico基于iptables還提供了豐富而靈活的網絡Policy,保證通過各個節點上的ACLs來提供Workload的多租戶隔離、安全組以及其他可達性限制等功能。
Calico架構圖
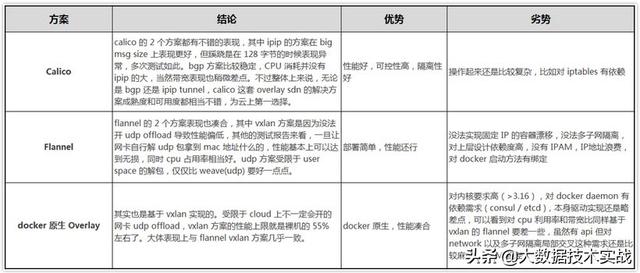
五、網絡開源組件性能對比分析
性能對比分析:
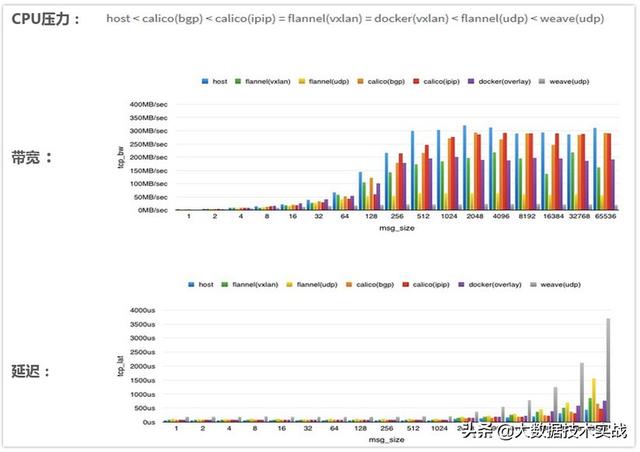
性能對比總結:
CalicoBGP 方案最好,不能用 BGP 也可以考慮 Calico ipip tunnel 方案;如果是 Coreos 系又能開 udp offload,flannel 是不錯的選擇;Docker 原生Overlay還有很多需要改進的地方。