機器學習免費跑分神器:集成各大數據集,連接GitHub就能用
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
搞機器學習的小伙伴們,免不了要在各種數據集上,給AI模型跑分。
現在,Papers with Code (那個以論文搜代碼的神器) 團隊,推出了自動跑分服務,名叫sotabench,以跑遍所有開源模型為己任。
有了它,不用上傳代碼,只要連接GitHub項目,就有云端GPU幫你跑分;每次提交了新的commit,系統又會自動更新跑分。還有世界排行榜,可以觀察各路強手的成績。
除了支持各大主流數據集,還支持用戶上傳自己的數據集。
也可以看看,別人的論文結果,到底靠譜不靠譜。
比如說,fork一下Facebook的FixRes這個項目,配置一下評估文件:

然后一鍵關聯,讓Sotabench的GPU跑一下ImageNet的圖像分類測試。
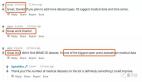
就能得到這樣的結果:
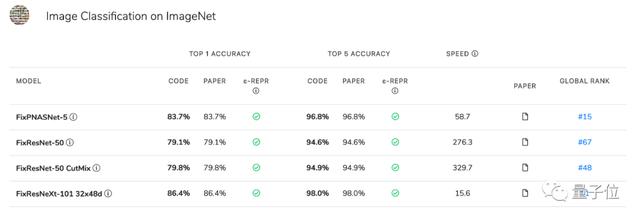
Top-1準確率,Top-5準確率,跟論文的結果有何差距(見注),運行速度,全球排名,全部一目了然。
注:ε-REPR,結果與論文結果差距在0.3%以內時打勾,差距≥0.3%且比論文結果差顯示為紅叉,比論文結果好顯示為勾+
這個免費的跑分神器,發布一天,便受到熱烈歡迎:推特點贊600+,Reddit熱度270+。
網友紛紛表示:這對開發者社區來說太有用了!
那么,先來看一下sotabench的功能和用法吧。
用法簡單,海納百川
團隊說,sotabench就是Papers with Code的雙胞胎姐妹:
Papers with Code大家很熟悉了,它觀察的是論文報告的跑分。可以用來尋找高分模型對應的代碼,是個造福人類的工具。

與之互補,sotabench觀察的是開源項目,代碼實際運行的結果。可以測試自己的模型,也能驗證別家的模型,是不是真有論文說的那么強。
它支持跟其他模型的對比,支持查看速度和準確率的取舍情況。
那么,sotabench怎么用?簡單,只要兩步。
第一步,先在本地評估一下模型:
在GitHub項目的根目錄里,創建一個sotabench.py文件。里面可以包含:加載、處理數據集和從中得出預測所需的邏輯。每提交一個commit,這個文件都會運行。然后,用個開源的基準測試庫來跑你的模型。這個庫可以是sotabench-eval,這個庫不問框架,里面有ImageNet等等數據集;也可以是torchbench,這是個PyTorch庫,和PyTorch數據集加載器搭配食用更簡單。

一旦成功跑起來,就可以進入下一步。
第二步,連接GitHub項目,sotabench會幫你跑:

點擊這個按鈕,連到你的GitHub賬號,各種項目就顯現了。選擇你要測試的那個項目來連接。連好之后,系統會自動測試你的master,然后記錄官方結果,一切都是跑在云端GPU上。測試環境是根據requirement.txt文件設置的,所以要把這個文件加進repo,讓系統捕捉到你用的依賴項。
從此,每當你提交一次commit,系統都會幫你重新跑分,來確保分數是最新的,也確保更新的模型依然在工作。
這樣一來,模型出了bug,也能及時知曉。
如果要跑別人家的模型,fork到自己那里就好啦。
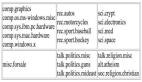
目前,sotabench已經支持了一些主流數據集:

列表還在持續更新中,團隊也在盛情邀請各路豪杰,一同充實benchmark大家庭。
既支持創建一個新的benchmark,也支持為現有benchmark添加新的實現。
你可以給sotabench-eval或torchbench項目提交PR,也可以直接創建新的Python包。
一旦準備就緒,就在sotabench官網的論壇上,發布新話題,團隊會把你的benchmark加進去的:
好評如潮
這樣的一項服務推出,網友們紛紛點贊,好評如潮,推特點贊600+。
有網友表示:
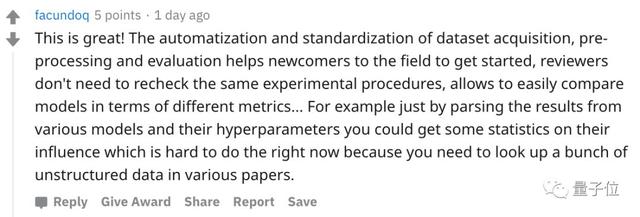
太棒了!對剛入門的新手來說,數據集獲取、預處理和評估的自動化和標準化很有用。通過分析不同模型及其超參數結果,來評估這些模型,本身是挺困難的一件事,你得在各種論文中查閱大量的非結構化數據。有了這個,這件事就輕松多了。(部分意譯)
許多網友對這個項目進行了友好的探討及建議,而開發人員也在線積極回應。
比如這位網友建議:能在每次提交的時候報告模型的超參數嗎?
作者很快回復說:英雄所見略同。下次更新就加上!
并且,他們還考慮在將來的更新中,讓使用者把鏈接添加到生成模型的訓練參數中。

傳送門
sotabench官網:
https://sotabench.com/
基準測試庫通用版:
https://github.com/paperswithcode/sotabench-eval
基準測試庫PyTorch版:
https://github.com/paperswithcode/torchbench