大規模集群故障處理,能抗住這3個靈魂拷問算你贏
我相信每一個集群管理員,在長期管理多個不同體量及應用場景的集群后,都會多少產生情緒。其實這在我看來,是一個很微妙的事,即大家也已經開始人性化的看待每一個集群了。
既然是人性化的管理集群,我總是會思考幾個方向的問題:
- 集群的特別之處在哪兒?
- 集群經常生什么病?
- 對于集群產生的突發疾病如何精準地做到靶向定位?
- 應急處理故障之后如何避免舊除新添?
在長期大規模集群治理實踐過程中,也針對各個集群的各種疑難雜癥形成了自己的西藥(trouble shooting)丶中藥(Returning for analysis)丶健身預防(On a regular basis to optimize)的手段及產品。
下面通過自我的三個靈魂拷問來分享一下自己對于大規模集群治理的經驗及總結。
靈魂拷問1
集群量大,到底有啥特點?
集群數量多,規模大:管理著大小將近20個集群,最大的xxx集群和xx集群達到1000+節點的規模。
靈魂拷問2
平時集群容易生什么病,都有哪些隱患呢?
集群在整體功能性,穩定性,資源的使用等大的方面都會有一些痛點問題。
常見的文件數過多丶小文件過多丶RPC隊列深度過高,到各個組件的版本bug,使用組件時發生嚴重生產故障,以及資源浪費等都是集群治理的常見問題。
靈魂拷問3
對于集群的突發疾病如何精準地解決故障?
對于集群突發的故障,平臺應具備全面及時的監控告警,做到分鐘級發現告警故障,推送告警通知,這是快速解決故障的前提保障。
對于集群的慢性疾病,應該從底層收集可用的詳細數據,分析報告加以利用,通過長期的治理來有效的保障集群的深層次健康(具體請閱讀《運維老司機都想要掌握的大數據平臺監控技巧》),并開發形成能實實在在落地企業的數據資產管理丶數據治理產品。
下面將針對上面的9個集群問題或故障逐一解答如何解決。
1、底層計算引擎老舊,業務加工占用大量資源且異常緩慢。
集群底層使用MR計算引擎,大量任務未進合理優化,大多數任務占用上千core,上百TB內存,且對集群造成了大量的IO讀寫壓力。
解決手段:通過監控“拎大頭”,找出消耗資源巨大的任務,通過業務,計算引擎,參數調優來優化集群資源使用,提高集群算力。
業務優化:從業務角度明確來源數據,減少加載數據量。
計算引擎優化 :MR轉Spark。
參數調優:小文件合并優化,內存內核調優,并發量調優,防止數據傾斜。
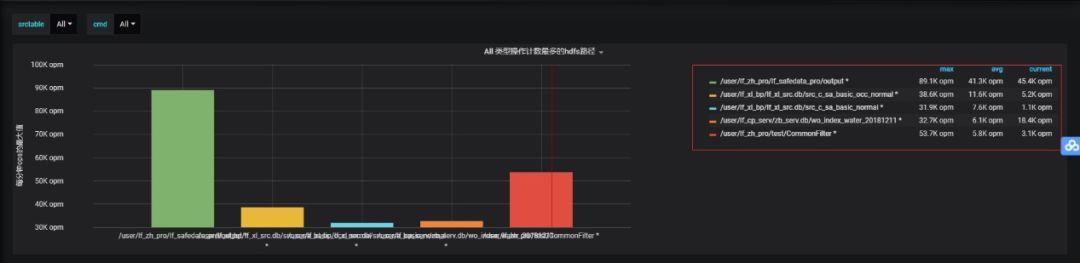
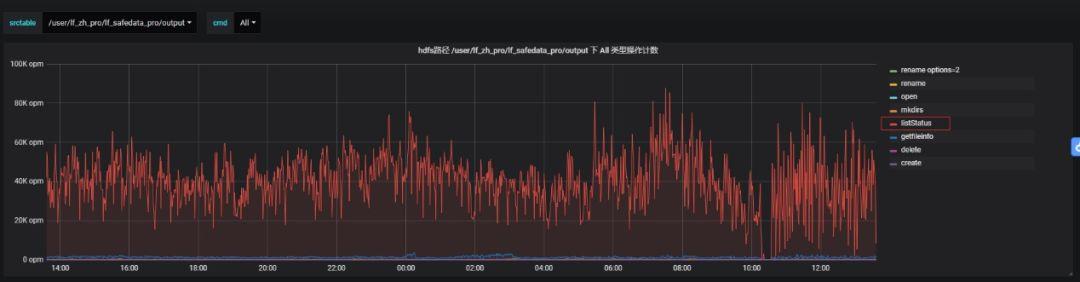
2、xx集群RPC故障問題。
現象概述:XX產線集群提交作業執行慢; 業務數據加工邏輯為讀取HDFS新增文件>>>入庫HBase; 遍歷列表文件周期為5s。
根因分析:

解決方案:
閱讀RPC源碼:動態代理機制+NIO通信模型。
調整NN RPC關鍵參數,做對比實驗。
1)優化系統參數配置:
ipc.server.handler.queue.size;
- dfs.namenode.service.handler.count
2)將HDFS千萬級目錄掃描周期從5s調整為5分鐘
3)增加集群RPC請求分時段分業務模型深度監控
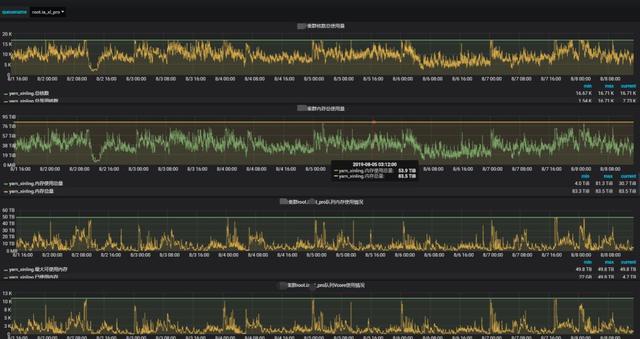
3、xx集群由于承載對外多租戶,面對各個租戶提出的集群生產環境的需求都不一致,造成集群環境復雜化,yarn資源打滿,并且容易出現負載過高的接口機,加重運維成本。
解決手段:
集群環境多版本及異構管理:
配置多版本Python環境,并搭建私有第三方庫。

配置多版本Spark,Kafka環境。

實時監控yarn隊列資源使用,監控yarn應用任務,重點優化。
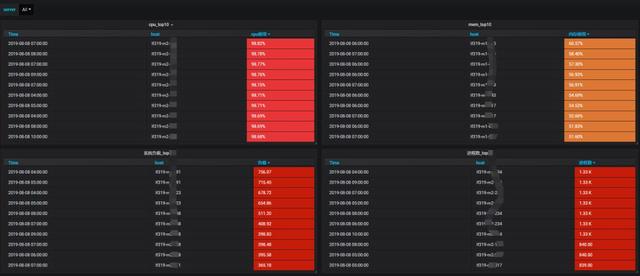
配置明細接口機監控,優化接口機負載。
接口機從基礎指標,top分析,CPU內存消耗過大的進程多維度監控,及時的合理調整優化接口機的調度任務,降低接口機負載。
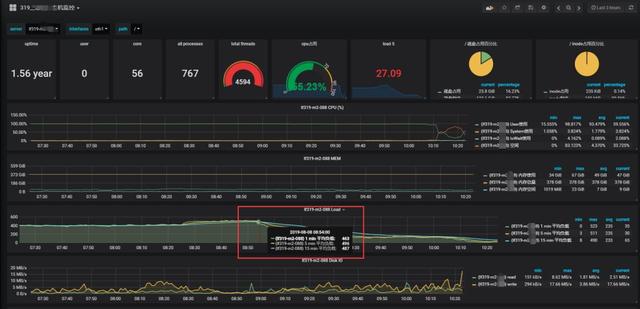
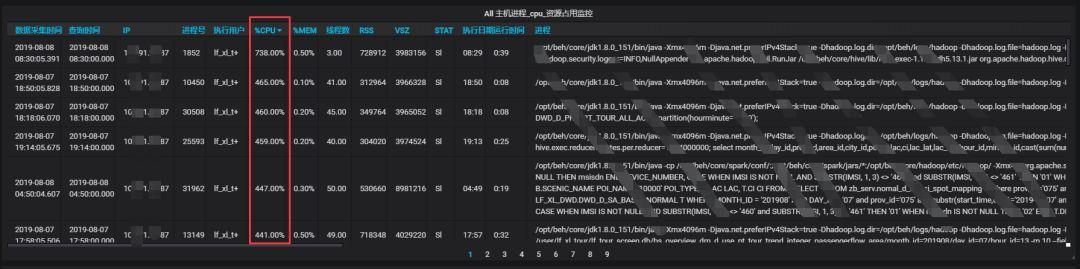
4、xxx集群由于文件數過多,導致集群運行緩慢,NameNode進程掉線。
集群的文件對象達到九千多萬。且集群的讀寫IO是寫多讀少。NameNode啟動需要加載大量的塊信息,啟動耗時過長。
解決手段:
計算引擎優化 :盡量使用Spark,有效率使用內存資源,減少磁盤IO讀寫。
周期性清理:根據HDFS業務目錄存儲增量,定期協調業務人員清理相關無用業務數據。
塊大小管理:小文件做合并,增加block大小為1GB,減少小文件塊數量。
深度清理:采集監控auit日志做HDFS文件系統的多維畫像。深入清理無用數據表,空文件,廢文件。
5、HDFS數據目錄權限管理混亂,經常造成數據誤刪或丟失。
由于下放的權限沒有及時回收,或者一些誤操作造成了數據的誤刪和丟失。
解決辦法:
業務劃分:明確梳理各個業務對應權限用戶,整改當前HDFS數據目錄結構,生產測試庫分離控制。
數據生命周期管理:
6、yarnJOB造成節點負載過高影響了其他job運行。
某些節點CPU負載很高影響了job任務的運行,發現有些節點的負載從9:30到現在一直很高,導致job任務執行了大概7個小時。
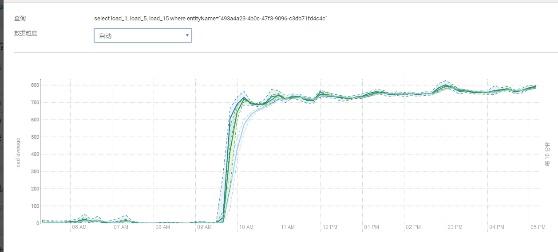
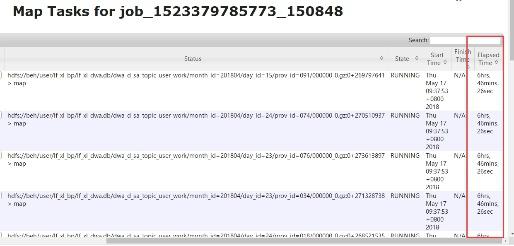
解決辦法:
找到耗時task執行的節點,確實發現負載很高,并找到了此任務對應的進程。
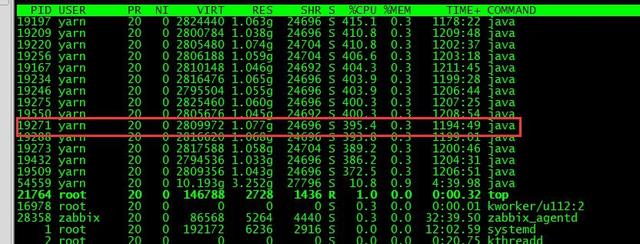
查看此進程的堆棧信息,發現Full GC次數很多,時長很長大概6個小時,頻繁的Full GC會使CPU使用率過高。

查看job進程詳情發現,java heap內存只有820M,task處理的記錄數為7400多萬,造成堆內存不足頻繁出發Full GC。
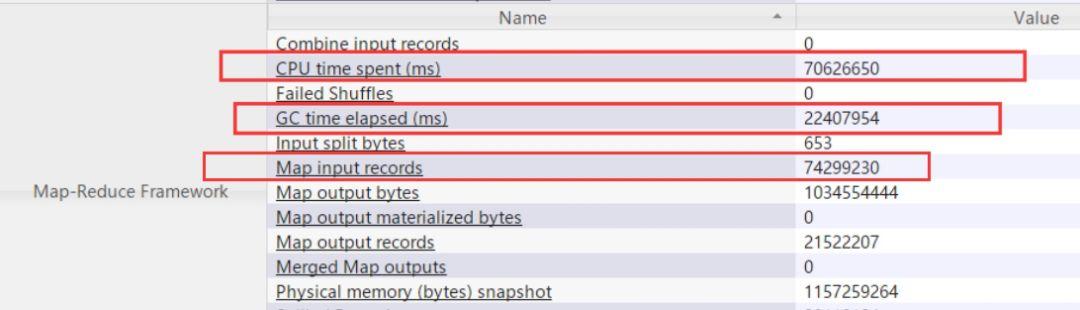
推薦下次執行任務時設置如下參數大小:
- hive> set mapreduce.map.memory.mb=4096;
- hive> set mapreduce.map.java.opts=-Xmx3686m;
7、NameNode切換后部分Hive表無法查詢。
小集群NameNode發生切換,并出現Hive某庫下的表和其有關聯的表無法使用的情況報錯如下:

截圖報錯,表明當前NameNode節點為stanby節點。經過排查發現,Hive的Metadata中有些partition列的屬性還保留之前配置的NameNode location。
解決辦法:
- 備份Hive所在的MySQL元數據庫 # mysqldump -uRoot -pPassword hive > hivedump.sql;
- 進入Hive所在的MySQL數據庫執行,修改Hive庫下SDS表下的location信息,涉及條數9739行。把指定IP的location替換成nameservice ;
UPDATE SDS SET LOCATION = REPLACE(LOCATION, 'hdfs://ip:8020', 'hdfs://nameservice1') where LOCATION like 'hdfs://ip%';
- 切換NameNode驗證所影響Hive表是否可用;
- 業務全方面驗證 ;
- 變更影響范圍:本次變更可以在線進行實施,避開業務繁忙段,對業務無影響;
- 回退方案:從備份的mysqldump文件中恢復mysql hive元數據庫 mysql -uUsername -pPassword hive < hivedump.sq。
8、Spark任務運行緩慢,且經常執行報錯。
產線集群提交作業執行報錯,個別Task執行耗時超過2h: ERROR server.TransportChannelHandler: Connection to ip:4376 has been quiet for 120000 ms while there are outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong.
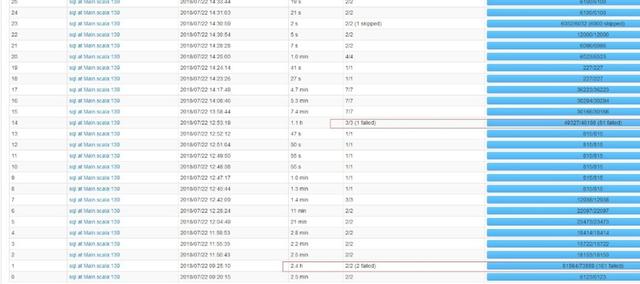
根因分析:
報錯表象為shuffle階段拉取數據操作連接超時。默認超時時間為120s。
深入了解Spark源碼:在shuffle階段會有read 和 write操作。
首先根據shuffle可使用內存對每一個task進行chcksum,校驗task處理數據量是否超出shuffle buffer 內存上限。該過程并不是做全量chcksum,而是采用抽樣的方式進行校驗。
其原理是抽取task TID ,與shuffle內存校驗,小于shuffle內存上限,則該區間的task都會獲取 task data 遍歷器進行數據遍歷load本地,即HDFS Spark中間過程目錄。
這樣會導致一些數據量過大的task成為漏網之魚,正常來說,數據量過大,如果被校驗器采樣到,會直接報OOM,實際情況是大數據量task沒有被檢測到,超出buffer過多,導致load時,一部分數據在內存中獲取不到,進而導致連接超時的報錯假象。
解決方案:
1)調優參數配置:
spark.shuffle.manager(sort),spark.shuffle.consolidateFiles (true),spark.network.timeout(600s)。報錯解決,運行耗時縮短一小時。
2)excutor分配內存從16g降為6g。內存占用節省三分之二,運行耗時增加一小時。
9、某HBase集群無法PUT入庫問題處理。
集群情況介紹:HDFS總存儲 20+PB,已使用 75+%,共 600+ 個 DN 節點,大部分數據為 2 副本(該集群經歷過 多次擴容,擴容前由于存儲緊張被迫降副本為 2),數據分布基本均衡。集群上只承載了HBase數據庫。
故障描述:因集群部分 DN 節點存儲使用率非常高(超過 95%),所以采取了下線主機然后再恢復 集群中這種辦法來減輕某些 DN 存儲壓力。
且集群大部分數據為 2 副本,所以在這個過程 中出現了丟塊現象。通過 fsck 看到已經徹底 miss,副本數為 0。
因此,在重啟 HBase 過程中,部分 region 因 為 block 的丟失而無法打開,形成了 RIT。
對此問題,我們通過 hadoop fsck –delete 命令清除了 miss 的 block。然后逐庫通過 hbase hbck –repair 命令來修復 hbase 在修復某個庫的時候在嘗試連接 ZK 環節長時間卡死(10 分鐘沒有任何輸出),被迫只能 中斷命令。
然后發現故障表只有 999 個 region,并且出現 RIT,手動 assign 無效后,嘗試了重啟庫及再次 repair 修 復,均無效。
目前在 HDFS 上查看該表 region 目錄總數為 1002 個,而 Hbase UI 上是 999 個,正常值為 1000 個。
問題處理:后續檢查發現在整個集群的每張 HBase 表都有 region un-assignment 及 rowkey 存在 hole 問題(不是單張表存在問題)。
運行 hbase hbck -details -checkCorruptHFiles 做集群狀態檢查,檢查結果如下:
… ERROR: Region { meta => index_natip201712,#\\xA0,1512009553152.00d96f6b2de55b56453e7060328b7930., hdfs => hdfs://ns1/hbase_ipsource3/data/default/index_natip201712/00d96f6b2de55b56453e7060328b7930, deployed => } not deployed on any region server. ERROR: Region { meta => index_natip201711,Y`,1509436894266.00e2784a250af945c66fb70370344f2f., hdfs => hdfs://ns1/hbase_ipsource3/data/default/index_natip201711/00e2784a250af945c66fb70370344f2f, deployed => } not deployed on any region server. … ERROR: There is a hole in the region chain between \\x02 and \\x02@. You need to create a new .regioninfo and region dir in hdfs to plug the hole. ERROR: There is a hole in the region chain between \\x04 and \\x04@. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
每張表可用(online)的 region 數都少于 1000,共存在 391 個 inconsistency,整個集群基本不可用。
因為每張表都不可用,所以通過新建表并將原表的 HFile 文件 BulkLoad 入新表的方案基本不可行。
第一、這種方案耗時太長;第二、做過一個基本測試,如果按照原表預 分區的方式新建表,在 BulkLoad 操作后,無法在新表上查詢數據(get 及 scan 操作均 阻塞,原因未知,初步估計和預分區方式有關)。
基于以上分析,決定采用 hbck 直接修復原表的方案進行,不再采用 BulkLoad 方案。
運行命令 hbae hbck -repair -fixAssignments -fixMeta,報Repair 過程阻塞異常。
查 HMaster 后臺日志,發現是某個 RegionServer(DSJ-signal-4T-147/10.162.0.175)的連接數超多造成連接超時。重啟該 RegionServer 后再次運行 hbck -repair -fixAssignments -fixMeta 順序結束,并成功修復了所有表的 region un-assignment、hole 及 HBase:meta 問題。
應用層測試整個集群入庫正常,問題處理完成。
10、Kafka集群頻頻到達性能瓶頸,造成上下游數據傳輸積壓。
Kafka集群節點數50+,集群使用普通SATA盤,存儲能力2000TB,千億級日流量,經常會出現個別磁盤IO打滿,導致生產斷傳,消費延遲,繼而引發消費offset越界,單個節點topic配置記錄過期等問題。
1)降低topic副本:
建議如果能降低大部分topic的副本,這個方法是簡單有效的。
降副本之后再把集群的拷貝副本所用的cpu核數降低,可以由num.replica.fetchers=6降低為num.replica.fetchers=3。磁盤IO使用的num.io.threads=14升為num.io.threads=16。num.network.threads=8升為num.network.threads=9。此參數只是暫時壓榨機器性能,當數據量遞增時仍會發生故障。
2)設定topic創建規則,針對磁盤性能瓶頸做分區指定磁盤遷移:
如果降低副本收效甚微,考慮到目前集群瓶頸主要在個別磁盤讀寫IO達到峰值,是因磁盤的topic分區分配不合理導致,建議首先做好針對topic分區級別IO速率的監控,然后形成規范合理的topic創建分區規則(數據量,流量大的topic先創建;分區數*副本數是磁盤總數的整數倍),先做到磁盤存儲的均衡,再挑出來個別讀寫IO到達瓶頸的磁盤,根據監控找出讀寫異常大分區。
找出分區后再次進行針對topic的分區擴容或者針對問題分區進行指定磁盤的遷移。這樣集群的整體利用率和穩定性能得到一定的提升,能節省集群資源。
3)Kafka版本升級及cm納管:
將手工集群遷移至cm納管,并在線升級Kafka版本。
4)zk和broker節點分離:
進行zk和broker節點的分離工作,建議進行zk節點變化而不是broker節點變化,以此避免數據拷貝帶來的集群負荷,建議創建測試topic,由客戶端適當增加批大小和減少提交頻率進行測試,使集群性能達到優良。