架構成長之路:分布式系統如何設計,看看Elasticsearch是怎么做的
分布式系統類型多,涉及面非常廣,不同類型的系統有不同的特點,批量計算和實時計算就差別非常大。這篇文章中,重點會討論下分布式數據系統的設計,比如分布式存儲系統,分布式搜索系統,分布式分析系統等。
我們先來簡單看下Elasticsearch的架構。
Elasticsearch 集群架構
Elasticsearch是一個非常著名的開源搜索和分析系統,目前被廣泛應用于互聯網多種領域中,尤其是以下三個領域特別突出。一是搜索領域,相對于solr,真正的后起之秀,成為很多搜索系統的不二之選。二是Json文檔數據庫,相對于MongoDB,讀寫性能更佳,而且支持更豐富的地理位置查詢以及數字、文本的混合查詢等。三是時序數據分析處理,目前是日志處理、監控數據的存儲、分析和可視化方面做得非常好,可以說是該領域的***者了。
Elasticsearch的詳細介紹可以到官網查看。我們先來看一下Elasticsearch中幾個關鍵概念:
- 節點(Node):物理概念,一個運行的Elasticearch實例,一般是一臺機器上的一個進程。
- 索引(Index),邏輯概念,包括配置信息mapping和倒排正排數據文件,一個索引的數據文件可能會分布于一臺機器,也有可能分布于多臺機器。索引的另外一層意思是倒排索引文件。
- 分片(Shard):為了支持更大量的數據,索引一般會按某個維度分成多個部分,每個部分就是一個分片,分片被節點(Node)管理。一個節點(Node)一般會管理多個分片,這些分片可能是屬于同一份索引,也有可能屬于不同索引,但是為了可靠性和可用性,同一個索引的分片盡量會分布在不同節點(Node)上。分片有兩種,主分片和副本分片。
- 副本(Replica):同一個分片(Shard)的備份數據,一個分片可能會有0個或多個副本,這些副本中的數據保證強一致或最終一致。
用圖形表示出來可能是這樣子的:
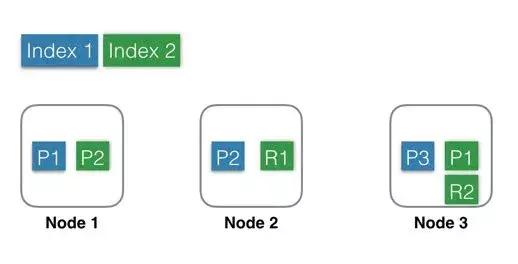
- Index 1:藍色部分,有3個shard,分別是P1,P2,P3,位于3個不同的Node中,這里沒有Replica。
- Index 2:綠色部分,有2個shard,分別是P1,P2,位于2個不同的Node中。并且每個shard有一個replica,分別是R1和R2。基于系統可用性的考慮,同一個shard的primary和replica不能位于同一個Node中。這里Shard1的P1和R1分別位于Node3和Node2中,如果某一刻Node2發生宕機,服務基本不會受影響,因為還有一個P1和R2都還是可用的。因為是主備架構,當主分片發生故障時,需要切換,這時候需要選舉一個副本作為新主,這里除了會耗費一點點時間外,也會有丟失數據的風險。
Index流程
建索引(Index)的時候,一個Doc先是經過路由規則定位到主Shard,發送這個doc到主Shard上建索引,成功后再發送這個Doc到這個Shard的副本上建索引,等副本上建索引成功后才返回成功。
在這種架構中,索引數據全部位于Shard中,主Shard和副本Shard各存儲一份。當某個副本Shard或者主Shard丟失(比如機器宕機,網絡中斷等)時,需要將丟失的Shard在其他Node中恢復回來,這時候就需要從其他副本(Replica)全量拷貝這個Shard的所有數據到新Node上構造新Shard。這個拷貝過程需要一段時間,這段時間內只能由剩余主副本來承載流量,在恢復完成之前,整個系統會處于一個比較危險的狀態,直到failover結束。
這里就體現了副本(Replica)存在的一個理由,避免數據丟失,提高數據可靠性。副本(Replica)存在的另一個理由是讀請求量很大的時候,一個Node無法承載所有流量,這個時候就需要一個副本來分流查詢壓力,目的就是擴展查詢能力。
角色部署方式
接下來再看看角色分工的兩種不同方式:
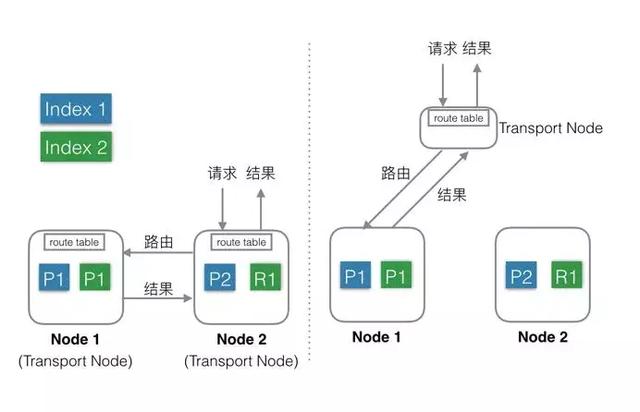
Elasticsearch支持上述兩種方式:
1.混合部署(左圖)
- 默認方式。
- 不考慮MasterNode的情況下,還有兩種Node,Data Node和Transport Node,這種部署模式下,這兩種不同類型Node角色都位于同一個Node中,相當于一個Node具備兩種功能:Data和Transport。
- 當有index或者query請求的時候,請求隨機(自定義)發送給任何一個Node,這臺Node中會持有一個全局的路由表,通過路由表選擇合適的Node,將請求發送給這些Node,然后等所有請求都返回后,合并結果,然后返回給用戶。一個Node分飾兩種角色。
- 好處就是使用極其簡單,易上手,對推廣系統有很大價值。最簡單的場景下只需要啟動一個Node,就能完成所有的功能。
- 缺點就是多種類型的請求會相互影響,在大集群如果某一個Data Node出現熱點,那么就會影響途經這個Data Node的所有其他跨Node請求。如果發生故障,故障影響面會變大很多。
- Elasticsearch中每個Node都需要和其余的每一個Node都保持13個連接。這種情況下, - 每個Node都需要和其他所有Node保持連接,而一個系統的連接數是有上限的,這樣連接數就會限制集群規模。
- 還有就是不能支持集群的熱更新。
2.分層部署(右圖):
- 通過配置可以隔離開Node。
- 設置部分Node為Transport Node,專門用來做請求轉發和結果合并。
- 其他Node可以設置為DataNode,專門用來處理數據。
- 缺點是上手復雜,需要提前設置好Transport的數量,且數量和Data Node、流量等相關,否則要么資源閑置,要么機器被打爆。
- 好處就是角色相互獨立,不會相互影響,一般Transport Node的流量是平均分配的,很少出現單臺機器的CPU或流量被打滿的情況,而DataNode由于處理數據,很容易出現單機資源被占滿,比如CPU,網絡,磁盤等。獨立開后,DataNode如果出了故障只是影響單節點的數據處理,不會影響其他節點的請求,影響限制在最小的范圍內。
- 角色獨立后,只需要Transport Node連接所有的DataNode,而DataNode則不需要和其他DataNode有連接。一個集群中DataNode的數量遠大于Transport Node,這樣集群的規模可以更大。另外,還可以通過分組,使Transport Node只連接固定分組的DataNode,這樣Elasticsearch的連接數問題就徹底解決了。
- 可以支持熱更新:先一臺一臺的升級DataNode,升級完成后再升級Transport Node,整個過程中,可以做到讓用戶無感知。
上面介紹了Elasticsearch的部署層架構,不同的部署方式適合不同場景,需要根據自己的需求選擇適合的方式。
Elasticsearch 數據層架構
接下來我們看看當前Elasticsearch的數據層架構。
數據存儲
Elasticsearch的Index和meta,目前支持存儲在本地文件系統中,同時支持niofs,mmap,simplefs,smb等不同加載方式,性能***的是直接將索引LOCK進內存的MMap方式。默認,Elasticsearch會自動選擇加載方式,另外可以自己在配置文件中配置。這里有幾個細節,具體可以看官方文檔。
索引和meta數據都存在本地,會帶來一個問題:當某一臺機器宕機或者磁盤損壞的時候,數據就丟失了。為了解決這個問題,可以使用Replica(副本)功能。
副本(Replica)
可以為每一個Index設置一個配置項:副本(Replicda)數,如果設置副本數為2,那么就會有3個Shard,其中一個是PrimaryShard,其余兩個是ReplicaShard,這三個Shard會被Mater盡量調度到不同機器,甚至機架上,這三個Shard中的數據一樣,提供同樣的服務能力。
副本(Replica)的目的有三個:
- 保證服務可用性:當設置了多個Replica的時候,如果某一個Replica不可用的時候,那么請求流量可以繼續發往其他Replica,服務可以很快恢復開始服務。
- 保證數據可靠性:如果只有一個Primary,沒有Replica,那么當Primary的機器磁盤損壞的時候,那么這個Node中所有Shard的數據會丟失,只能reindex了。
- 提供更大的查詢能力:當Shard提供的查詢能力無法滿足業務需求的時候, 可以繼續加N個Replica,這樣查詢能力就能提高N倍,輕松增加系統的并發度。
問題
上面說了一些優勢,這種架構同樣在一些場景下會有些問題。
Elasticsearch采用的是基于本地文件系統,使用Replica保證數據可靠性的技術架構,這種架構一定程度上可以滿足大部分需求和場景,但是也存在一些遺憾:
- Replica帶來成本浪費。為了保證數據可靠性,必須使用Replica,但是當一個Shard就能滿足處理能力的時候,另一個Shard的計算能力就會浪費。
- Replica帶來寫性能和吞吐的下降。每次Index或者update的時候,需要先更新Primary Shard,更新成功后再并行去更新Replica,再加上長尾,寫入性能會有不少的下降。
- 當出現熱點或者需要緊急擴容的時候動態增加Replica慢。新Shard的數據需要完全從其他Shard拷貝,拷貝時間較長。
上面介紹了Elasticsearch數據層的架構,以及副本策略帶來的優勢和不足,下面簡單介紹了幾種不同形式的分布式數據系統架構。
分布式系統
***種:基于本地文件系統的分布式系統
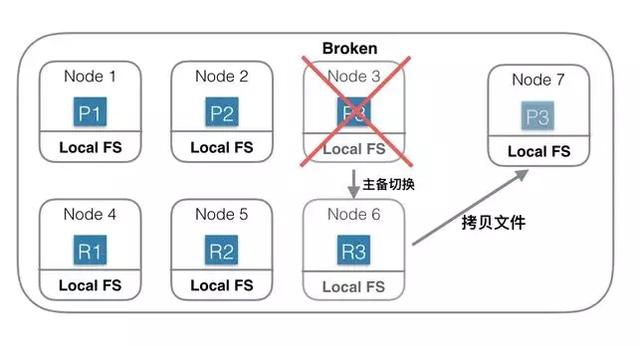
上圖中是一個基于本地磁盤存儲數據的分布式系統。Index一共有3個Shard,每個Shard除了Primary Shard外,還有一個Replica Shard。當Node 3機器宕機或磁盤損壞的時候,首先確認P3已經不可用,重新選舉R3位Primary Shard,此Shard發生主備切換。然后重新找一臺機器Node 7,在Node7 上重新啟動P3的新Replica。由于數據都會存在本地磁盤,此時需要將Shard 3的數據從Node 6上拷貝到Node7上。如果有200G數據,千兆網絡,拷貝完需要1600秒。如果沒有replica,則這1600秒內這些Shard就不能服務。
為了保證可靠性,就需要冗余Shard,會導致更多的物理資源消耗。
這種思想的另外一種表現形式是使用雙集群,集群級別做備份。
在這種架構中,如果你的數據是在其他存儲系統中生成的,比如HDFS/HBase,那么你還需要一個數據傳輸系統,將準備好的數據分發到相應的機器上。
這種架構中為了保證可用性和可靠性,需要雙集群或者Replica才能用于生產環境,優勢和副作用在上面介紹Elasticsearch的時候已經介紹過了,這里就就不贅述了。
Elasticsearch使用的就是這種架構方式。
第二種:基于分布式文件系統的分布式系統(共享存儲)
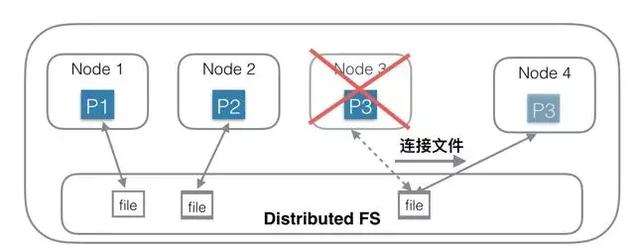
針對***種架構中的問題,另一種思路是:存儲和計算分離。
***種思路的問題根源是數據量大,拷貝數據耗時多,那么有沒有辦法可以不拷貝數據?為了實現這個目的,一種思路是底層存儲層使用共享存儲,每個Shard只需要連接到一個分布式文件系統中的一個目錄/文件即可,Shard中不含有數據,只含有計算部分。相當于每個Node中只負責計算部分,存儲部分放在底層的另一個分布式文件系統中,比如HDFS。
上圖中,Node 1 連接到***個文件;Node 2連接到第二個文件;Node3連接到第三個文件。當Node 3機器宕機后,只需要在Node 4機器上新建一個空的Shard,然后構造一個新連接,連接到底層分布式文件系統的第三個文件即可,創建連接的速度是很快的,總耗時會非常短。
這種是一種典型的存儲和計算分離的架構,優勢有以下幾個方面:
- 在這種架構下,資源可以更加彈性,當存儲不夠的時候只需要擴容存儲系統的容量;當計算不夠的時候,只需要擴容計算部分容量。
- 存儲和計算是獨立管理的,資源管理粒度更小,管理更加精細化,浪費更少,結果就是總體成本可以更低。
- 負載更加突出,抗熱點能力更強。一般熱點問題基本都出現在計算部分,對于存儲和計算分離系統,計算部分由于沒有綁定數據,可以實時的擴容、縮容和遷移,當出現熱點的時候,可以***時間將計算調度到新節點上。
這種架構同時也有一個不足:訪問分布式文件系統的性能可能不及訪問本地文件系統。在上一代分布式文件系統中,這是一個比較明顯的問題,但是目前使用了各種用戶態協議棧后,這個差距已經越來越小了。HBase使用的就是這種架構方式。
Solr也支持這種形式的架構。
總結
上述兩種架構,各有優勢和不足,對于某些架構中的不足或缺陷,思路不同,解決的方案也大相徑庭,但是思路跨度越大,收益一般也越大。
上面只是介紹了分布式數據(存儲/搜索/分析等等)系統在存儲層的兩種不同架構方式,希望能對大家有用。但是分布式系統架構設計所涉及的內容廣,細節多,權衡點眾,如果大家對某些領域或者方面有興趣,也可以留言,后面再探討。