Hello Redis,我有7個問題想請教你!
原創【51CTO.com原創稿件】Hello,Redis!我們相處已經很多年了,從模糊的認識到現在我們已經深入結合,你的好我一直都知道也一直都記住,能否再讓我多問你的幾個問題,讓我更加深入的去了解你。
圖片來自包圖網
Redis 的通訊協議是什么

Redis 的通訊協議是文本協議,是的,Redis 服務器與客戶端通過 RESP(Redis Serialization Protocol)協議通信。
沒錯,文本協議確實是會浪費流量,不過它的優點在于直觀,非常的簡單,解析性能極其的好,我們不需要一個特殊的 Redis 客戶端僅靠 Telnet 或者是文本流就可以跟 Redis 進行通訊。
客戶端的命令格式:
- 簡單字符串 Simple Strings,以 "+"加號開頭。
- 錯誤 Errors,以"-"減號開頭。
- 整數型 Integer,以 ":" 冒號開頭。
- 大字符串類型 Bulk Strings,以 "$"美元符號開頭。
- 數組類型 Arrays,以 "*"星號開頭。
- set hello abc
- 一個簡單的文本流就可以是redis的客戶端
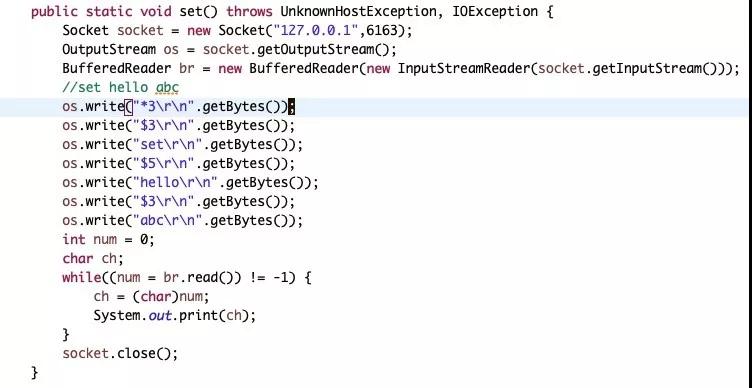
簡單總結:具體可以見 https://redis.io/topics/protocol ,Redis 文檔認為簡單的實現,快速的解析,直觀理解是采用 RESP 文本協議最重要的地方,有可能文本協議會造成一定量的流量浪費,但卻在性能上和操作上快速簡單,這中間也是一個權衡和協調的過程。
Redis 究竟有沒有 ACID 事務

要弄清楚 Redis 有沒有事務,其實很簡單,上 Rredis 的官網查看文檔,發現:
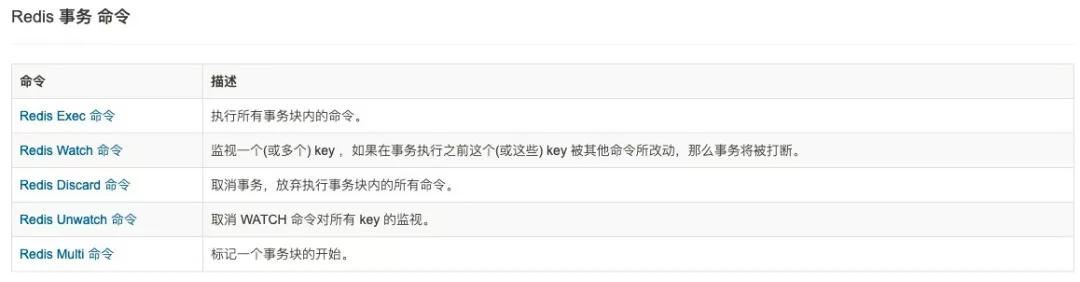
Redis 確實是有事務,不過按照傳統的事務定義 ACID 來看,Redis 是不是都具備了 ACID 的特性。
ACID 指的是:
- 原子性
- 一致性
- 隔離性
- 持久性
我們將使用以上 Redis 事務的命令來檢驗是否 Redis 都具備了 ACID 的各個特征。
原子性
事務具備原子性指的是,數據庫將事務中多個操作當作一個整體來執行,服務要么執行事務中所有的操作,要么一個操作也不會執行。
①事務隊列
首先弄清楚 Redis 開始事務 multi 命令后,Redis 會為這個事務生成一個隊列,每次操作的命令都會按照順序插入到這個隊列中。
這個隊列里面的命令不會被馬上執行,直到 exec 命令提交事務,所有隊列里面的命令會被一次性,并且排他的進行執行。
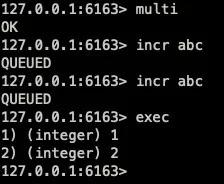
對應如下圖:
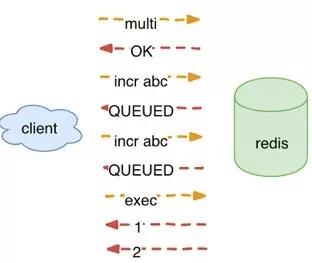
從上面的例子可以看出,當執行一個成功的事務,事務里面的命令都是按照隊列里面順序的并且排他的執行。
但原子性又一個特點就是要么全部成功,要么全部失敗,也就是我們傳統 DB 里面說的回滾。
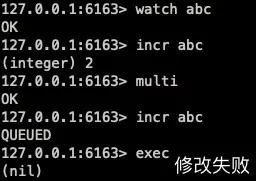
當我們執行一個失敗的事務:
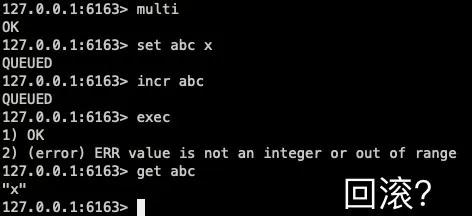
可以發現,就算中間出現了失敗,set abc x 這個操作也已經被執行了,并沒有進行回滾,從嚴格的意義上來說 Redis 并不具備原子性。
②為何 Redis 不支持回滾
這個其實跟 Redis 的定位和設計有關系,先看看為何我們的 MySQL 可以支持回滾,這個還是跟寫 Log 有關系,Redis 是完成操作之后才會進行 AOF 日志記錄,AOF 日志的定位只是記錄操作的指令記錄。
而 MySQL 有完善的 Redolog,并且是在事務進行 Commit 之前就會寫完成 Redolog,Binlog:

要知道 MySQL 為了能進行回滾是花了不少的代價,Redis 應用的場景更多是對抗高并發具備高性能,所以 Redis 選擇更簡單,更快速無回滾的方式處理事務也是符合場景。
一致性
事務具備一致性指的是,如果數據庫在執行事務之前是一致的,那么在事務執行之后,無論事務是否成功,數據庫也應該是一致的。
從 Redis 來說可以從 2 個層面看,一個是執行錯誤是否有確保一致性,另一個是宕機時,Redis 是否有確保一致性的機制。
①執行錯誤是否有確保一致性
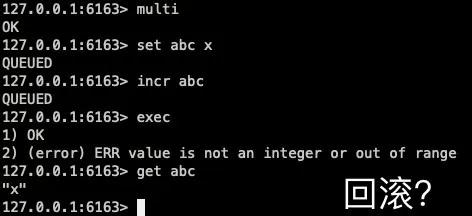
依然去執行一個錯誤的事務,在事務執行的過程中會識別出來并進行錯誤處理,這些錯誤并不會對數據庫作出修改,也不會對事務的一致性產生影響。
②宕機對一致性的影響
暫不考慮分布式高可用的 Redis 解決方案,先從單機看宕機恢復是否能滿意數據完整性約束。
無論是 RDB 還是 AOF 持久化方案,可以使用 RDB 文件或 AOF 文件進行恢復數據,從而將數據庫還原到一個一致的狀態。
③再議一致性
上面執行錯誤和宕機對一致性的影響的觀點摘自黃健宏 《Redis 設計與實現》。
當在讀這章的時候還是有一些存疑的點,歸根到底 Redis 并非關系型數據庫。
如果僅僅就 ACID 的表述上來說,一致性就是從 A 狀態經過事務到達 B 狀態沒有破壞各種約束性,僅就 Redis 而言不談實現的業務,那顯然就是滿意一致性。
但如果加上業務去談一致性,例如,A 轉賬給 B,A 減少 10 塊錢,B 增加 10 塊錢,因為 Redis 并不具備回滾,也就不具備傳統意義上的原子性,所以 Redis 也應該不具備傳統的一致性。
其實,這里只是簡單討論下 Redis 在傳統 ACID 上的概念怎么進行對接,或許,有可能是我想多了,用傳統關系型數據庫的 ACID 去審核 Redis 是沒有意義的,Redis 本來就沒有意愿去實現 ACID 的事務。
隔離性
隔離性指的是,數據庫中有多個事務并發的執行,各個事務之間不會相互影響,并且在并發狀態下執行的事務和串行執行的事務產生的結果是完全相同的。
Redis 因為是單線程操作,所以在隔離性上有天生的隔離機制,當 Redis 執行事務時,Redis 的服務端保證在執行事務期間不會對事務進行中斷,所以,Redis 事務總是以串行的方式運行,事務也具備隔離性。
持久性
事務的持久性指的是,當一個事務執行完畢,執行這個事務所得到的結果被保存在持久化的存儲中,即使服務器在事務執行完成后停機了,執行的事務的結果也不會被丟失。
Redis 是否具備持久化,這個取決于 Redis 的持久化模式:
- 純內存運行,不具備持久化,服務一旦停機,所有數據將丟失。
- RDB 模式,取決于 RDB 策略,只有在滿足策略才會執行 Bgsave,異步執行并不能保證 Redis 具備持久化。
- AOF 模式,只有將 appendfsync 設置為 always,程序才會在執行命令同步保存到磁盤,這個模式下,Redis 具備持久化。(將 appendfsync 設置為 always,只是在理論上持久化可行,但一般不會這么操作)
簡單總結:
- Redis 具備了一定的原子性,但不支持回滾。
- Redis 不具備 ACID 中一致性的概念。(或者說 Redis 在設計時就無視這點)
- Redis 具備隔離性。
- Redis 通過一定策略可以保證持久性。
Redis 和 ACID 純屬站在使用者的角度去思想,Redis 設計更多的是追求簡單與高性能,不會受制于傳統 ACID 的束縛。
Redis 的樂觀鎖 Watch 是怎么實現的
當我們一提到樂觀鎖就會想起 CAS(Compare And Set),CAS 操作包含三個操作數:
- 內存位置的值(V)
- 預期原值(A)
- 新值(B)
如果內存位置的值與預期原值相匹配,那么處理器會自動將該位置更新為新值。否則,處理器不做任何操作。
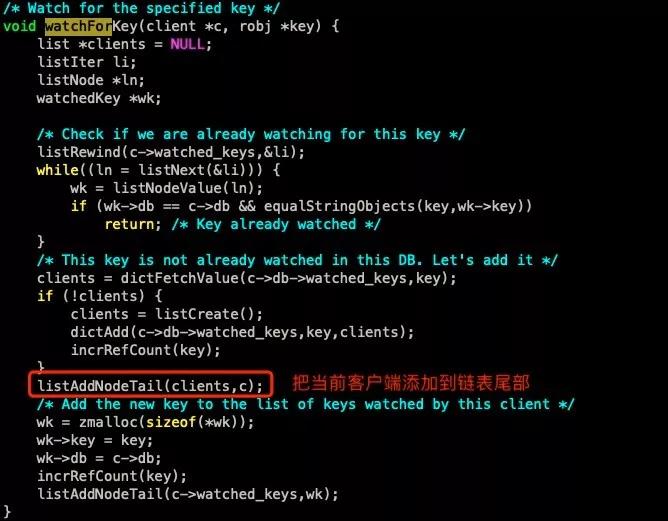
在 Redis 的事務中使用 Watch 實現,Watch 會在事務開始之前盯住 1 個或多個關鍵變量。
當事務執行時,也就是服務器收到了 exec 指令要順序執行緩存的事務隊列時, Redis 會檢查關鍵變量自 Watch 之后,是否被修改了。
①Java 的 AtomicXXX 的樂觀鎖機制
在 Java 中我們也經常的使用到一些樂觀鎖的參數,例如 AtomicXXX,這些機制的背后是怎么去實現的,是否 Redis 也跟 Java 的 CAS 實現機制一樣?
先來看看 Java 的 Atomic 類,我們追一下源碼,可以看到它的背后其實是 Unsafe_CompareAndSwapObject:
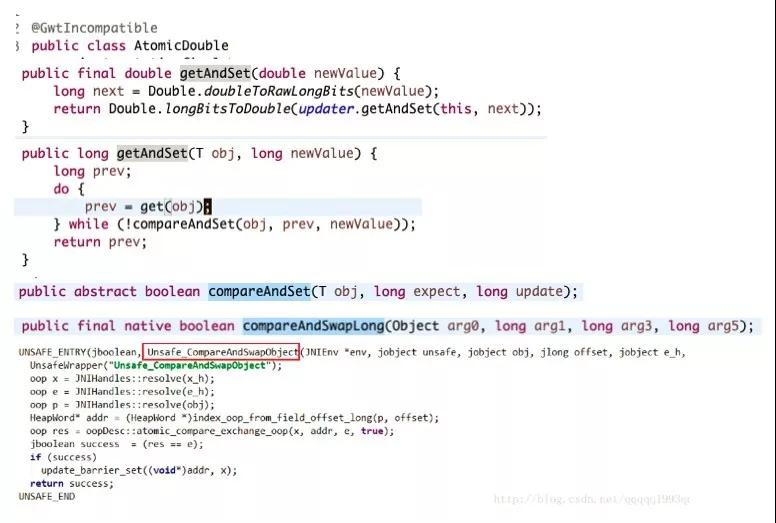
可以看見 compareAndSwapObject 是 Native 方法,需要在繼續追查,可以下載源碼或打開 :http://hg.openjdk.java.net/jdk8u/。
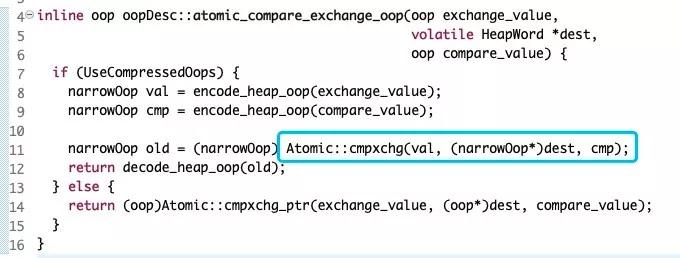
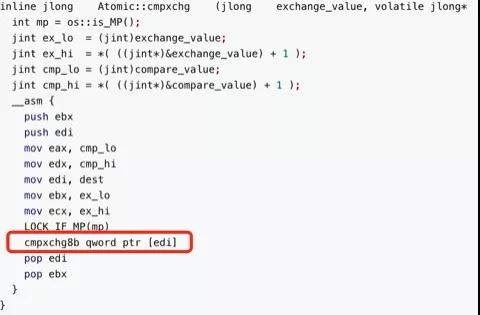
②Cmpxchg
可以發現追查到最終 CAS,“比較并修改”,本來是兩個語意,但是最終確實一條 CPU 指令 Cmpxchg 完成。
Cmpxchg 是一條 CPU 指令的命令而不是多條 CPU 指令,所以它不會被多線程的調度所打斷,所以能夠保證 CAS 的操作是一個原子操作。
當然 Cmpxchg 的機制其實存在 ABA 還有多次重試的問題,這個不在這里討論。
③Redis 的 Watch 機制
Redis 的 Watch 也是使用 Cmpxchg 嗎,兩者存在相似之處在用法上也有一些不同,Redis 的 Watch 不存在 ABA 問題,也沒有多次重試機制,其中有一個重大的不同是:Redis 事務執行其實是串行的。
簡單追一下源碼:摘錄出來的源碼可能有些凌亂,不過可以簡單總結出來數據結構圖和簡單的流程圖,之后再看源碼就會清晰很多。

存儲如下圖:
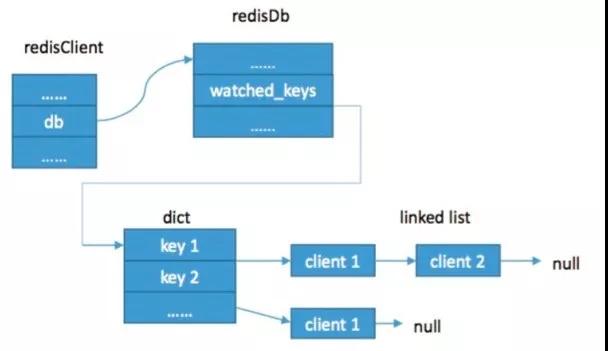
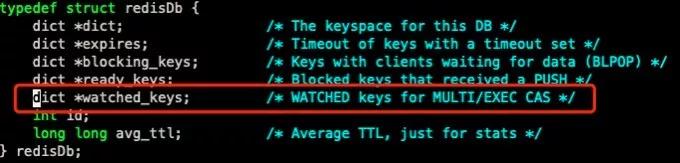
RedisDb 存放了一個 watched_keys 的 Dcit 結構,每個被 Watch 的 Key 的值是一個鏈表結構,存放的是一組 Redis 客戶端標志。
流程如下圖:
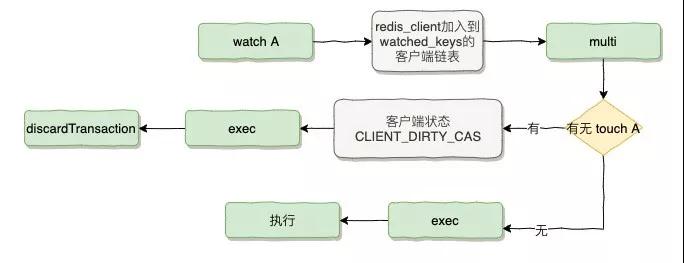
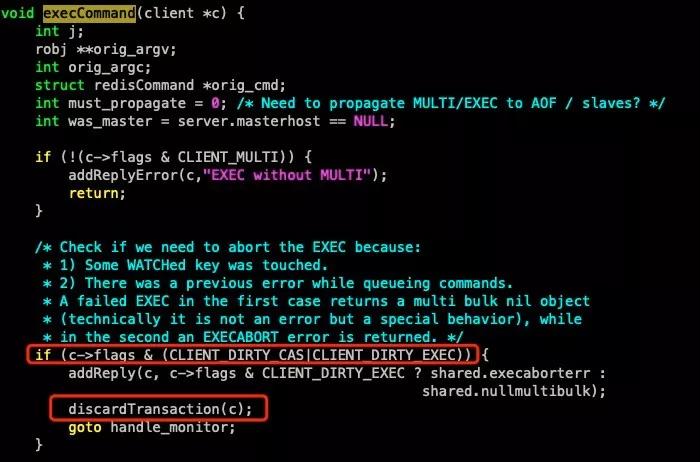
每一次 Watch,Multi,Exec 時都會去查詢這個 watched_keys 結構進行判斷,每次 Touch 到被 Watch 的 Key 時都會標志為 CLIENT_DIRTY_CAS。
因為在 Redis 中所有的事務都是串行的,假設有客戶端 A 和客戶端 B 都 Watch 同一個 Key。
當客戶端 A 進行 Touch 修改或者 A 率先執行完,會把客戶端 A 從這個 watched_keys 的這個 Key 的列表刪除,然后把這個列表所有的客戶端都設置成 CLIENT_DIRTY_CAS。
當后面的客戶端 B 開始執行時,判斷到自己的狀態是 CLIENT_DIRTY_CAS,便 discardTransaction 終止事務。
簡單總結:Cmpxchg 的實現主要是利用了 CPU 指令,看似兩個操作使用一條 CPU 指令完成,所以不會被多線程進行打斷。
而 Redis 的 Watch 機制,更多是利用了 Redis 本身單線程的機制,采用了 watched_keys 的數據結構和串行流程實現了樂觀鎖機制。
Redis 是如何持久化的

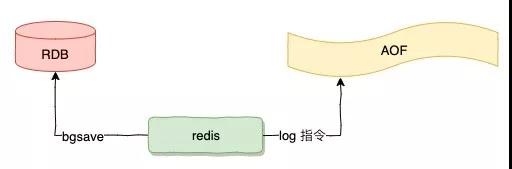
Redis 的持久化有兩種機制,一個是 RDB,也就是快照,快照就是一次全量的備份,會把所有 Redis 的內存數據進行二進制的序列化存儲到磁盤。
另一種是 AOF 日志,AOF 日志記錄的是數據操作修改的指令記錄日志,可以類比 MySQL 的 Binlog,AOF 日期隨著時間的推移只會***增量。
在對 Redis 進行恢復時,RDB 快照直接讀取磁盤即可恢復,而 AOF 需要對所有的操作指令進行重放進行恢復,這個過程有可能非常漫長。
RDB
Redis 在進行 RDB 的快照生成有兩種方法,一種是 Save,由于 Redis 是單進程單線程,直接使用 Save,Redis 會進行一個龐大的文件 IO 操作。
由于單進程單線程勢必會阻塞線上的業務,一般的話不會直接采用 Save,而是采用 Bgsave,之前一直說 Redis 是單進程單線程,其實不然。
在使用 Bgsave 的時候,Redis 會 Fork 一個子進程,快照的持久化就交給子進程去處理,而父進程繼續處理線上業務的請求。
①Fork 機制
想要弄清楚 RDB 快照的生成原理就必須弄清楚 Fork 機制,Fork 機制是 Linux 操作系統的一個進程機制。
當父進程 Fork 出來一個子進程,子進程和父進程擁有共同的內存數據結構,子進程剛剛產生時,它和父進程共享內存里面的代碼段和數據段。

一開始兩個進程都具備了相同的內存段,子進程在做數據持久化時,不會去修改現在的內存數據,而是會采用 COW(Copy On Write)的方式將數據段頁面進行分離。
當父進程修改了某一個數據段時,被共享的頁面就會復制一份分離出來,然后父進程再在新的數據段進行修改。

②分裂
這個過程也成為分裂的過程,本來父子進程都指向很多相同的內存塊,但是如果父進程對其中某個內存塊進行該修改,就會將其復制出來,進行分裂再在新的內存塊上面進行修改。
因為子進程在 Fork 的時候就可以固定內存,這個時間點的數據將不會產生變化。
所以我們可以安心的產生快照不用擔心快照的內容受到父進程業務請求的影響。
另外可以想象,如果在 Bgsave 的過程中,Redis 沒有任何操作,父進程沒有接收到任何業務請求也沒有任何的背后例如過期移除等操作,父進程和子進程將會使用相同的內存塊。
AOF
AOF 是 Redis 操作指令的日志存儲,類同于 MySQL 的 Binlog,假設 AOF 從 Redis 創建以來就一直執行,那么 AOF 就記錄了所有的 Redis 指令的記錄。
如果要恢復 Redis,可以對 AOF 進行指令重放,便可修復整個 Redis 實例。
不過 AOF 日志也有兩個比較大的問題:
- 一個是 AOF 的日志會隨著時間遞增,如果一個數據量大運行的時間久,AOF 日志量將變得異常龐大。
- 另一個問題是 AOF 在做數據恢復時,由于重放的量非常龐大,恢復的時間將會非常的長。
AOF 寫操作是在 Redis 處理完業務邏輯之后,按照一定的策略才會進行些 AOF 日志存盤,這點跟 MySQL 的 Redolog 和 Binlog 有很大的不同。
也因為此原因,Redis 因為處理邏輯在前而記錄操作日志在后,也是導致 Redis 無法進行回滾的一個原因。
bgrewriteaof:針對上述的問題,Redis 在 2.4 之后也使用了 bgrewriteaof 對 AOF 日志進行瘦身。
bgrewriteaof 命令用于異步執行一個 AOF 文件重寫操作。重寫會創建一個當前 AOF 文件的體積優化版本。
RDB 和 AOF 混合搭配模式
在對 Redis 進行恢復的時候,如果我們采用了 RDB 的方式,因為 Bgsave 的策略,可能會導致我們丟失大量的數據。
如果我們采用了 AOF 的模式,通過 AOF 操作日志重放恢復,重放 AOF 日志比 RDB 要長久很多。
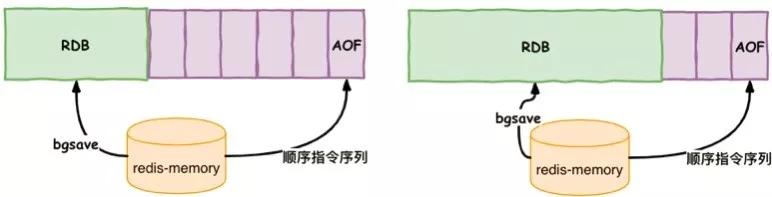
Redis 4.0 之后,為了解決這個問題,引入了新的持久化模式,混合持久化,將 RDB 的文件和局部增量的 AOF 文件相結合。
RDB 可以使用相隔較長的時間保存策略,AOF 不需要是全量日志,只需要保存前一次 RDB 存儲開始到這段時間增量 AOF 日志即可,一般來說,這個日志量是非常小的。
Redis 在內存使用上是如何開源節流

Redis 跟其他傳統數據庫不同,Redis 是一個純內存的數據庫,并且存儲了都是一些數據結構的數據,如果不對內存加以控制的話,Redis 很可能會因為數據量過大導致系統的奔潰。
Ziplist
- 127.0.0.1:6379> hset hash_test abc 1
- (integer) 1
- 127.0.0.1:6379> object encoding hash_test
- "ziplist"
- 127.0.0.1:6379> zadd z_test 10 key
- (integer) 1
- 127.0.0.1:6379> object encoding z_test
- "ziplist"
當最開始嘗試開啟一個小數據量的 Hash 結構和一個 Zset 結構時,發現他們在 Redis 里面的真正結構類型是一個 Ziplist。
Ziplist 是一個緊湊的數據結構,每一個元素之間都是連續的內存,如果在 Redis 中,Redis 啟用的數據結構數據量很小時,Redis 就會切換到使用緊湊存儲的形式來進行壓縮存儲。
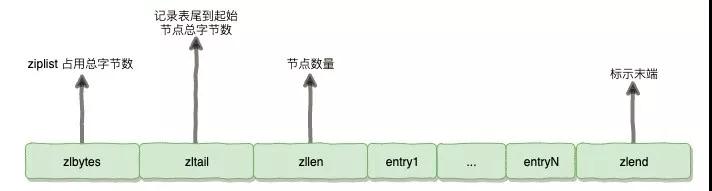
例如,上面的例子,我們采用了 Hash 結構進行存儲,Hash 結構是一個二維的結構,是一個典型的用空間換取時間的結構。
但是如果使用的數據量很小,使用二維結構反而浪費了空間,在時間的性能上也并沒有得到太大的提升,還不如直接使用一維結構進行存儲。
在查找的時候,雖然復雜度是 O(n),但是因為數據量少遍歷也非常快,增至比 Hash 結構本身的查詢更快。
如果當集合對象的元素不斷的增加,或者某個 Value 的值過大,這種小對象存儲也會升級生成標準的結構。
Redis 也可以在配置中進行定義緊湊結構和標準結構的轉換參數:
- hash-max-ziplist-entries 512 # hash的元素個數超過512就必須用標準結構存儲
- hash-max-ziplist-value 64 # hash的任意元素的key/value的長度超過 64 就必須用標準結構存儲
- list-max-ziplist-entries 512
- list-max-ziplist-value 64
- zset-max-ziplist-entries 128
- zset-max-ziplist-value 64
- set-max-intset-entries 512
Quicklist
- 127.0.0.1:6379> rpush key v1
- (integer) 1
- 127.0.0.1:6379> object encoding key
- "quicklist"
Quicklist 數據結構是 Redis 在 3.2 才引入的一個雙向鏈表的數據結構,確實來說是一個 Ziplist 的雙向鏈表。
Quicklist 的每一個數據節點是一個 Ziplist,Ziplist 本身就是一個緊湊列表。
假使,Quicklist 包含了 5 個 Ziplist 的節點,每個 Ziplist 列表又包含了 5 個數據,那么在外部看來,這個 Quicklist 就包含了 25 個數據項。
Quicklist 的結構設計簡單總結起來,是一個空間和時間的折中方案:
- 雙向鏈表可以在兩端進行 Push 和 Pop 操作,但是它在每一個節點除了保存自身的數據外,還要保存兩個指針,增加額外的內存開銷。
其次是由于每個節點都是獨立的,在內存地址上并不連續,節點多了容易產生內存碎片。
- Ziplist 本身是一塊連續的內存,存儲和查詢效率很高,但是,它不利于修改操作,每次數據變動時都會引發內存 Realloc,如果 Ziplist 長度很長時,一次 Realloc 會導致大批量數據拷貝。
所以,結合 Ziplist 和雙向鏈表的優點,Quciklist 就孕育而生。
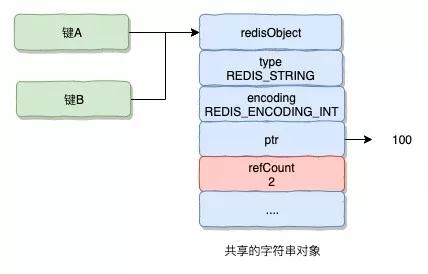
對象共享
Redis 在自己的對象系統中構建了一個引用計數方法,通過這個方法程序可以跟蹤對象的引用計數信息,除了可以在適當的時候進行對象釋放,還可以用來作為對象共享。
舉個例子,假使鍵 A 創建了一個整數值 100 的字符串作為值對象,這個時候鍵 B 也創建保存同樣整數值 100 的字符串對象作為值對象。

那么在 Redis 的操作時:
- 講數據庫鍵的指針指向一個現有的值對象。
- 講被共享的值對象引用計數加一。
假使,我們的數據庫中指向整數值 100 的鍵不止鍵 A 和鍵 B,而是有幾百個,那么 Redis 服務器中只需要一個字符串對象的內存就可以保存原本需要幾百個字符串對象的內存才能保存的數據。
Redis 是如何實現主從復制

幾個定義:
- runID:服務器運行的 ID。
- Offset:主服務器的復制偏移量和從服務器復制的偏移量。
- Replication backlog:主服務器的復制積壓緩沖區。
在 Redis 2.8 之后,使用 Psync 命令代替 Sync 命令來執行復制的同步操作。
Psync 命令具有完整重同步和部分重同步兩種模式:
- 完整同步用于處理初次復制情況:完整重同步的執行步驟和 Sync 命令執行步驟一致,都是通過讓主服務器創建并發送 RDB 文件,以及向從服務器發送保存在緩沖區的寫命令來進行同步。
- 部分重同步是用于處理斷線后重復制情況:當從服務器在斷線后重新連接主服務器時,主服務可以將主從服務器連接斷開期間執行的寫命令發送給從服務器,從服務器只要接收并執行這些寫命令,就可以將數據庫更新至主服務器當前所處的狀態。
完整重同步:
- Slave 發送 Psync 給 Master,由于是***次發送,不帶上 runID 和 Offset。
- Master 接收到請求,發送 Master 的 runID 和 Offset 給從節點。
- Master 生成保存 RDB 文件。
- Master 發送 RDB 文件給 Slave。
- 在發送 RDB 這個操作的同時,寫操作會復制到緩沖區 Replication Backlog Buffer 中,并從 Buffer 區發送到 Slave。
- Slave 將 RDB 文件的數據裝載,并更新自身數據。
如果網絡的抖動或者是短時間的斷鏈也需要進行完整同步就會導致大量的開銷,這些開銷包括了,Bgsave 的時間,RDB 文件傳輸的時間,Slave 重新加載 RDB 時間,如果 Slave 有 AOF,還會導致 AOF 重寫。
這些都是大量的開銷,所以在 Redis 2.8 之后也實現了部分重同步的機制。
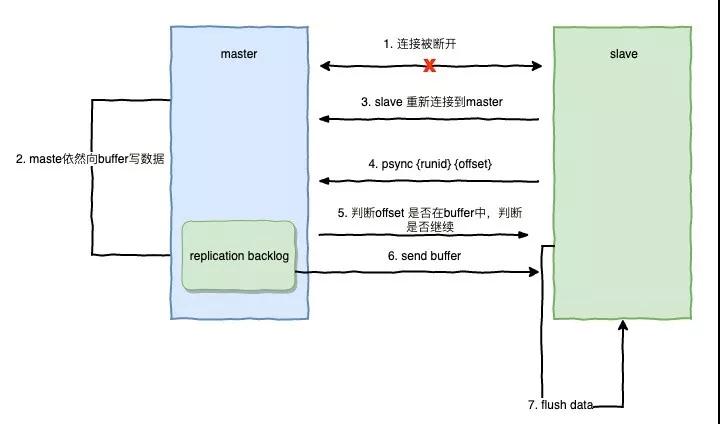
部分重同步:
- 網絡發生錯誤,Master 和 Slave 失去連接。
- Master 依然向 Buffer 緩沖區寫入數據。
- Slave 重新連接上 Master。
- Slave 向 Master 發送自己目前的 runID 和 Offset。
- Master 會判斷 Slave 發送給自己的 Offset 是否存在 Buffer 隊列中。
- 如果存在,則發送 Continue 給 Slave;如果不存在,意味著可能錯誤了太多的數據,緩沖區已經被清空,這個時候就需要重新進行全量的復制。
- Master 發送從 Offset 偏移后的緩沖區數據給 Slave。
- Slave 獲取數據更新自身數據。
Redis 是怎么制定過期刪除策略的
當一個鍵處于過期的狀態,其實在 Redis 中這個內存并不是實時就被從內存中進行摘除,而是 Redis 通過一定的機制去把一些處于過期鍵進行移除,進而達到內存的釋放,那么當一個鍵處于過期,Redis 會在什么時候去刪除?
幾時被刪除存在三種可能性,這三種可能性也代表了 Redis 的三種不同的刪除策略。
- 定時刪除:在設置鍵過去的時間同時,創建一個定時器,讓定時器在鍵過期時間來臨,立即執行對鍵的刪除操作。
- 惰性刪除:放任鍵過期不管,但是每次從鍵空間獲取鍵時,都會檢查該鍵是否過期,如果過期的話,就刪除該鍵。
- 定期刪除:每隔一段時間,程序都要對數據庫進行一次檢查,刪除里面的過期鍵,至于要刪除多少過期鍵,由算法而定。
①定時刪除
設置鍵的過期時間,創建定時器,一旦過期時間來臨,就立即對鍵進行操作。
這種對內存是友好的,但是對 CPU 的時間是最不友好的,特別是在業務繁忙,過期鍵很多的時候,刪除過期鍵這個操作就會占據很大一部分 CPU 的時間。
要知道 Redis 是單線程操作,在內存不緊張而 CPU 緊張的時候,將 CPU 的時間浪費在與業務無關的刪除過期鍵上面,會對 Redis 的服務器的響應時間和吞吐量造成影響。
另外,創建一個定時器需要用到 Redis 服務器中的時間事件,而當前時間事件的實現方式是無序鏈表,時間復雜度為 O(n),讓服務器大量創建定時器去實現定時刪除策略,會產生較大的性能影響,所以,定時刪除并不是一種好的刪除策略。
②惰性刪除
與定時刪除相反,惰性刪除策略對 CPU 來說是最友好的,程序只有在取出鍵的時候才會進行檢查,是一種被動的過程。
與此同時,惰性刪除對內存來說又是最不友好的,一個鍵過期,只要不再被取出,這個過期鍵就不會被刪除,它占用的內存也不會被釋放。
很明顯,惰性刪除也不是一個很好的策略,Redis 是非常依賴內存和較好內存的,如果一些長期鍵長期沒有被訪問,就會造成大量的內存垃圾,甚至會操成內存的泄漏。
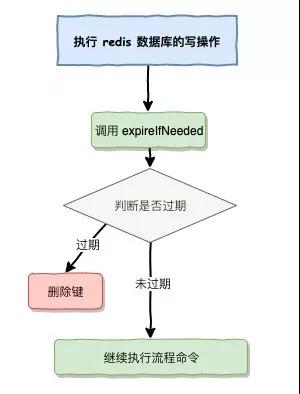
在對執行數據寫入時,通過 expireIfNeeded 函數對寫入的 Key 進行過期判斷。
其中 expireIfNeeded 在內部做了三件事情,分別是:
- 查看 Key 是否過期。
- 向 Slave 節點傳播執行過去 Key 的動作。
- 刪除過期 Key。
③定期刪除
上面兩種刪除策略,無論是定時刪除和惰性刪除,這兩種刪除方式在單一的使用上都存在明顯的缺陷,要么占用太多 CPU 時間,要么浪費太多內存。
定期刪除策略是前兩種策略的一個整合和折中:
- 定期刪除策略每隔一段時間執行一次刪除過期鍵操作,并通過限制刪除操作執行的時間和頻率來減少刪除操作對 CPU 時間的影響。
- 通過合理的刪除執行的時長和頻率,來達到合理的刪除過期鍵。
總結
Redis 可謂博大精深,簡單的七連問只是盲人摸象,這次只是摸到了一根象鼻子,還應該順著鼻子向下摸,下次可能摸到了一只象耳朵。
只要愿意往下深入去了解去摸索,而不只應用不思考,總有一天會把 Redis 這只大象給摸透了。
作者:陳于喆,注:部分章節參考和引用黃健宏 《Redis 設計與實現》
簡介:十余年的開發和架構經驗,國內較早一批微服務開發實施者。曾任職國內互聯網公司網易和唯品會高級研發工程師,后在創業公司擔任技術總監/架構師,目前在洋蔥集團任職技術研發副總監。負責技術部門研發體系建設,團建建設,人才培養,推動整個技術架構演進以及升級,帶領技術團隊構建微服務架構體系、平臺架構體系、自動化運維體系。

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】