性能優化,我們應該知道的更多一點
當我們談到性能優化,更多的同學可能想到的是系統層面的性能優化。比如在一個Web服務程序中,通過Redis或者其它緩存來提升網站訪問的速度等。對于程序代碼本身的優化卻比較少。這一方面是編譯器為我們做了很多優化工作,另外一方面是覺得系統層面的優化效果更明顯,也更高大上。實際上,除了系統層面的性能優化外,在程序代碼層面的性能優化效果也是非常好的。
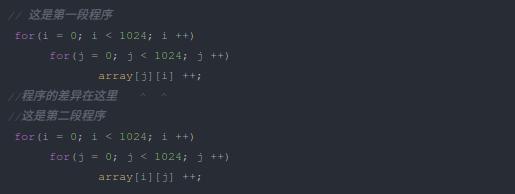
廢話不多說,我們以事實說話。大家看一下下面兩段程序,兩段程序的作用完全相同,就是將一個二維數組中的每一個元素做加1操作。大家看一下,覺得這兩段的程序是否會有性能差異?實際測試結果是兩者有近4倍的性能差異。
性能差異的原因分析
大家考慮一下,為什么有如此之大的性能差異?結合代碼,我們看到兩段代碼的差異在于對數組元素的訪問順序,前者是逐列訪問,而后者是逐行訪問。結合圖1可能會理解的更加清楚一些。然后,我們在結合C語言中二維數據數據在內存中的排布規則(可以在上述代碼中通過打印地址的方式驗證一下),可以知道前者是訪問連續的地址空間,而后者訪問的是跳躍的地址空間。
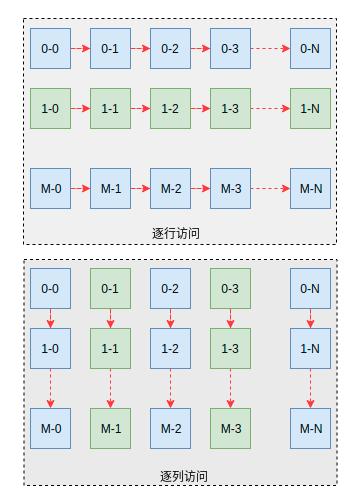
圖1 兩種訪問形式
以整形數組為例,也就是說,前者訪問的地址依次為X,X+4,X+8等等。而后者訪問的地址則依次為X,X+4096,X+8192。后者每次跳躍4KB的地址空間。
了解了上述差異后,大家有沒有想到性能差異的原因?我們知道CPU為了提升訪問內存的性能,在其和內存之間增加了緩存,現代CPU緩存通常為3級緩存,分別是L1、L2和L3,其中L1和L2是CPU核獨有的,而L3是同一顆CPU的多核共享的。其基本的架構如圖2所示。
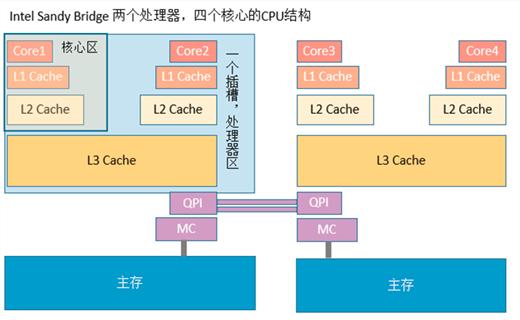
圖2 CPU緩存架構
由于緩存分布式的特點,在多個CPU之間需要保證其一致性。扯遠了,總之緩存需要切割為比較小的粒度進行管理,這個小粒度的管理單元稱為緩存行(可以類比頁緩存中的緩存頁)。由于緩存的容量遠遠小于內存的容量,因此緩存無法把內存中的內容都加載其中。緩存能夠其作用的最主要的原因是利用的常規業務訪問數據的兩個特性,也就是空間局部性和時間局部性。
- 空間局部性:對于剛被訪問的數據,其相鄰的數據在將來被訪問的概率高。
- 時間局部性:對于剛被訪問的數據,其本身在將來被訪問的概率高。
了解了上述原理,我們就知道,對于上面程序程序代碼,由于第二段程序依次跳躍的太遠,也就是不滿足空間局部性,從而導致緩存命中失敗。也就是說第二段程序其實無法訪問緩存中的數據,而是直接訪問的內存。而內存的訪問性能要遠遠低于緩存的訪問性能,因此就出現了文章一開始的近4倍的性能差異。
關于程序性能的其它考慮
我們程序的很微小的改動就有可能對性能產生非常大的影響。因此,我們在日常開發中應該處處注意代碼中是否有不恰當的代碼導致性能問題。下面我們在列舉一個關于性能相關的程序實例,以便大家在以后的開發中參考。
1. 程序結構
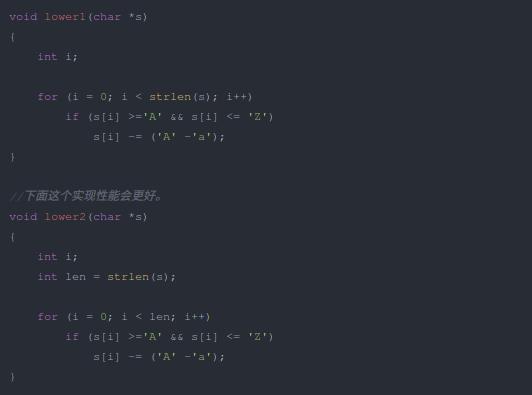
不合理的程序結構對性能的影響有的時候是災難性的。下面兩個函數的性能差異在字符串很長的情況下將非常巨大。函數lower1在每次循環中都計算一下字符串的長度,而這種計算并不是必要的。函數lower2則是在循環開始之前計算字符串長度,而后通過一個恒定的變量來進行條件判斷。問題的根源在于strlen函數,這個函數通過循環計算字符串的長度,如果字符串比較長,那這個函數將相當耗時。
2. 過程(函數)調用
我們知道在過程調用的時候會存在壓棧和出棧等操作,這些操作通常都是對內存的操作,且過程比較復雜。也就是說,函數的調用過程是比較耗時的操作,盡量減少函數調用。
值得慶幸的是現代的編譯器可以對函數調用做很多優化工作,簡單的函數調用通常可以被編譯器優化調。所謂優化調是只在機器語言(匯編語言)層面已經沒有高級語言的函數調用了。
我們通過一個具體的例子看一下,通過C語言實現一個簡單的函數調用,其中函數fun_1調用函數fun_2,而函數fun_2又調用了printf。這里fun_2并沒有做什么太多的工作,只是將兩個參數相加后傳給printf。
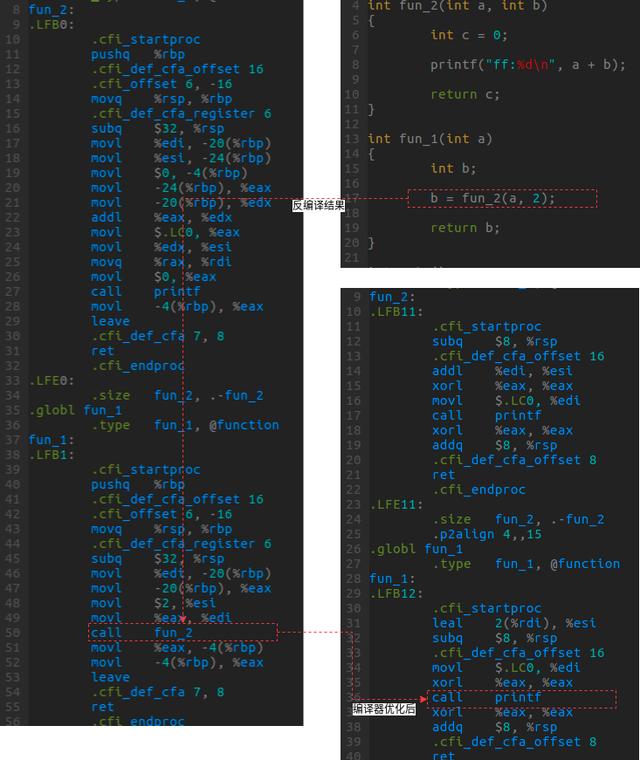
圖3 函數調用優化
如圖所示,在gcc不做任何優化的情況下,反匯編的代碼(圖3左下角)可以看出,整個邏輯非常清晰,只是按部就班的調用函數。但是,通過-O2優化后,匯編代碼變得非常簡潔了(圖3右下角),通過fun_1的匯編代碼可以看出它根本沒有調用fun_2,而是直接調用的printf函數。因此,在不影響其功能的情況下,編譯器是可以優化調函數調用的。但這不是絕對的,稍微復雜的函數調用編譯器可能就無能為力了,而此時就可能導致性能損耗。
3. 運算符差異
不同的運算的耗時差異也是非常巨大的,比如乘法的耗時是加法的兩三倍,而除法的耗時是加法的十倍以上。因此在訪問頻度比較高的邏輯中減少除法的使用將會明顯的提升。
在Java的HashMap實現中,通過位運算來計算哈希的Key,而不是通過模運算。因為模運算本身是除法運算,性能要比位運算差十倍以上。
- static final int hash(Object key) {
- int h;
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
更詳細的處理邏輯請參考JDK的源代碼,本文僅僅是拋個磚 。
4. 引用與拷貝
支持類的高級語言在傳遞對象參數的時候涉及拷貝的過程,對象的拷貝也是比較消耗性能的操作。當然,高級語言通過一種成為引用的機制實現了對象地址的傳遞,這樣就避免了拷貝的過程(這就是傳值與傳址的差異)。
在程序開發過程中關于性能的問題還很多,本文無法一一列舉出來。但,關鍵的問題是掌握技術的底層實現原理,任何其它高層的內容都可以通過底層原理解釋的,正所謂萬變不離其宗。